kettle使用
Kettle的安装及简单使用
一、kettle概述
1、什么是kettle
Kettle是一款开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
2、Kettle工程存储方式
(1)以XML形式存储
(2)以资源库方式存储(数据库资源库和文件资源库)
3、Kettle的两种设计
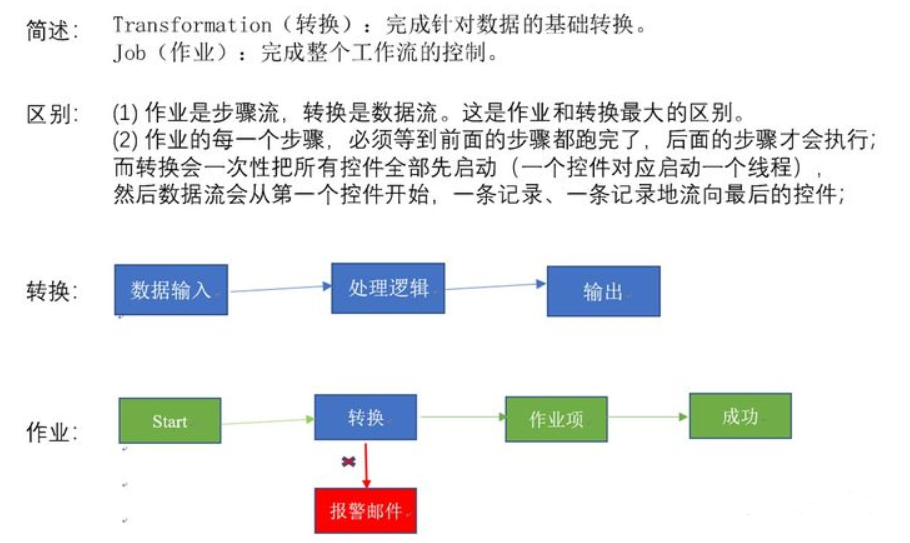
4、Kettle的组成

5、kettle特点

二、kettle安装部署和使用
Windows下安装
(1)概述
在实际企业开发中,都是在本地环境下进行kettle的job和Transformation开发的,可以在本地运行,也可以连接远程机器运行
(2)安装步骤
1、安装jdk
2、下载kettle压缩包,因kettle为绿色软件,解压缩到任意本地路径即可
3、双击Spoon.bat,启动图形化界面工具,就可以直接使用了
案例1:MySQL to MySQL
把stu1的数据按id同步到stu2,stu2有相同id则更新数据
1、在mysql中创建testkettle数据库,并创建两张表
create database testkettle;
use testkettle;
create table stu1(id int,name varchar(20),age int);
create table stu2(id int,name varchar(20));
2、往两张表中插入一些数据
insert into stu1 values(1001,'zhangsan',20),(1002,'lisi',18), (1003,'wangwu',23);
insert into stu2 values(1001,'wukong');
3、把pdi-ce-8.2.0.0-342.zip文件拷贝到win环境中指定文件目录,解压后双击Spoon.bat,启动图形化界面工具,就可以使用了
主界面:
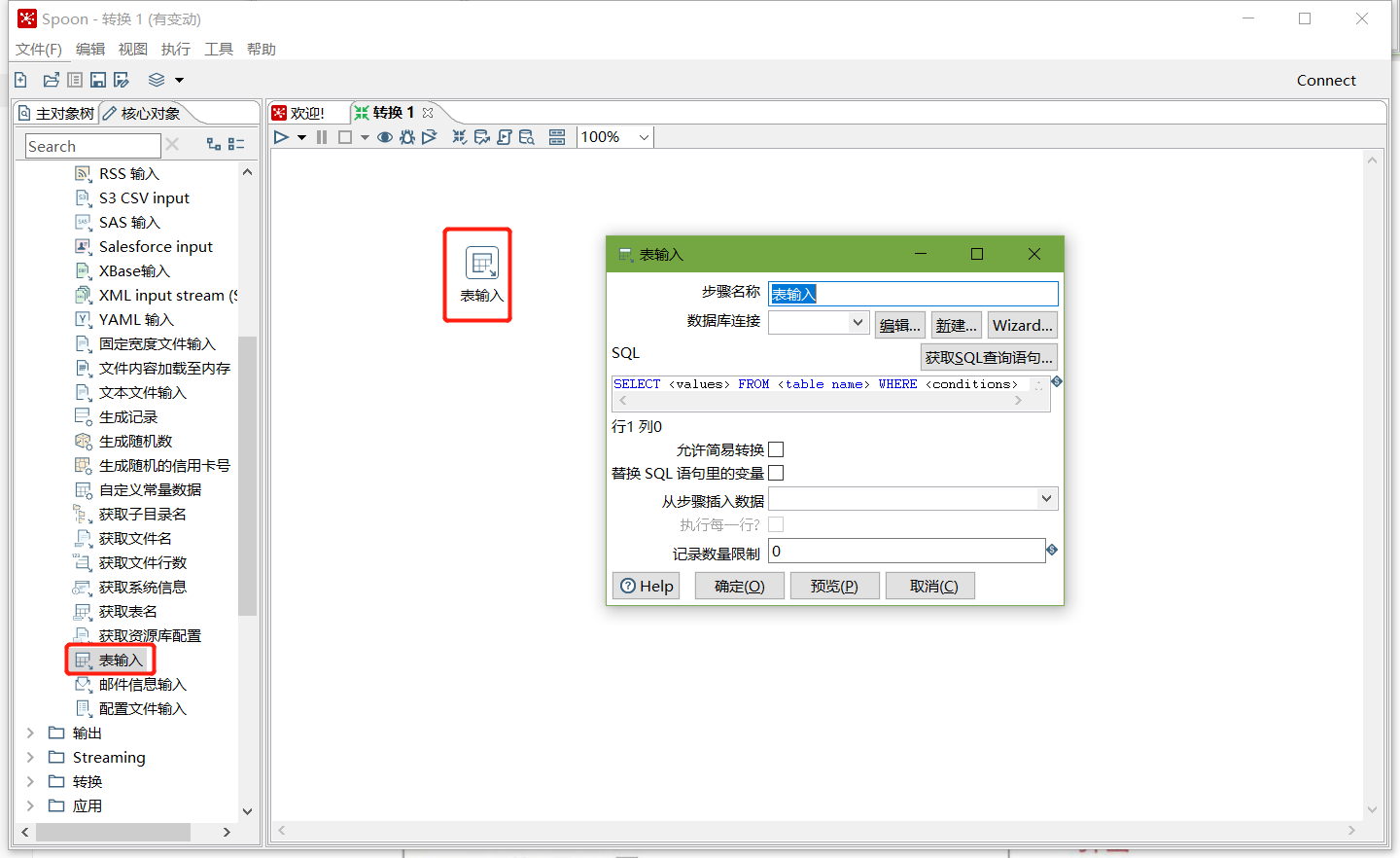
在kettle中新建转换--->输入--->表输入-->表输入双击
在data-integration\lib文件下添加mysql驱动
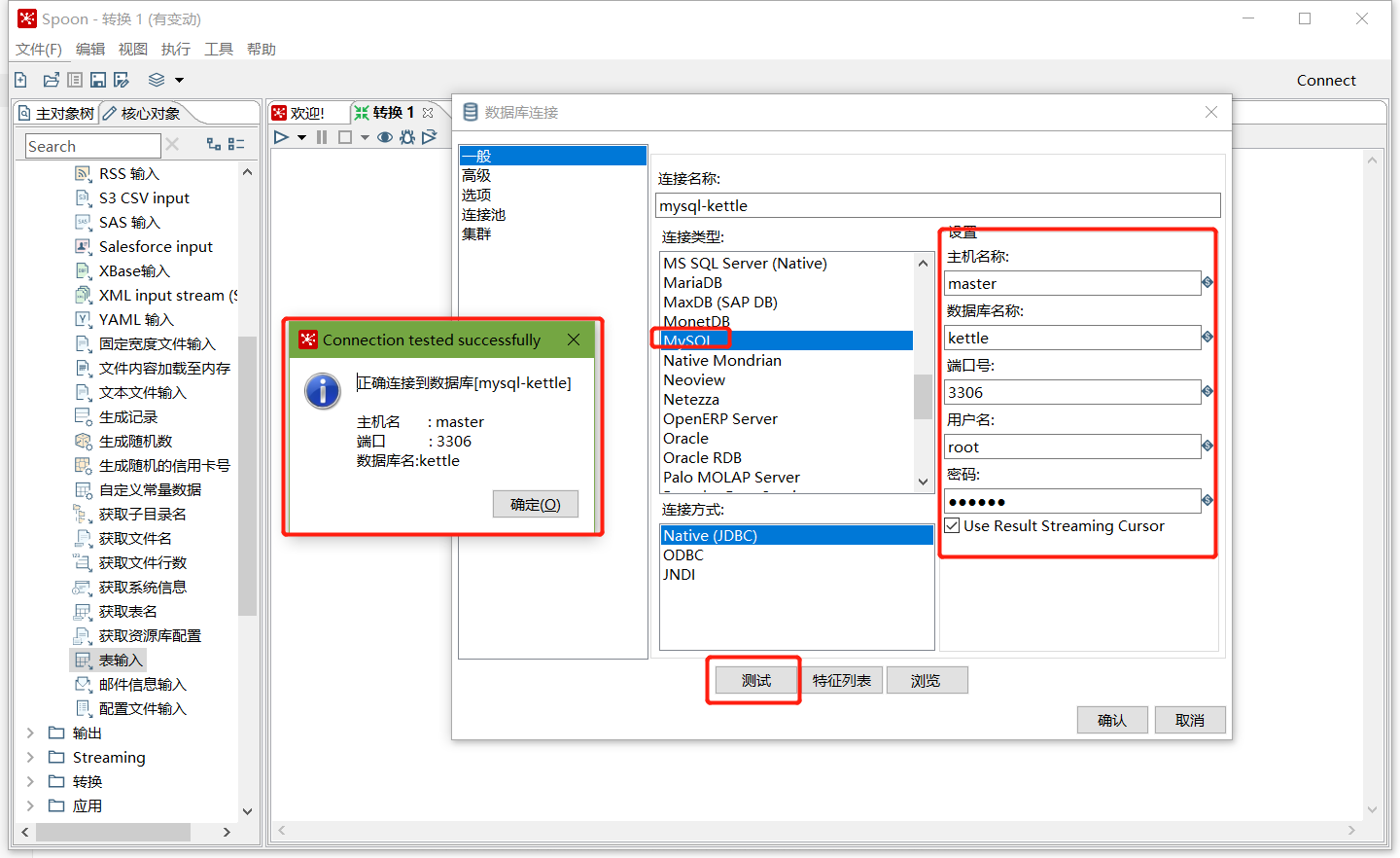
在数据库连接栏目点击新建,填入mysql相关配置,并测试连接
建立连接后,选择刚刚建好的连接,填入SQL,并预览数据:
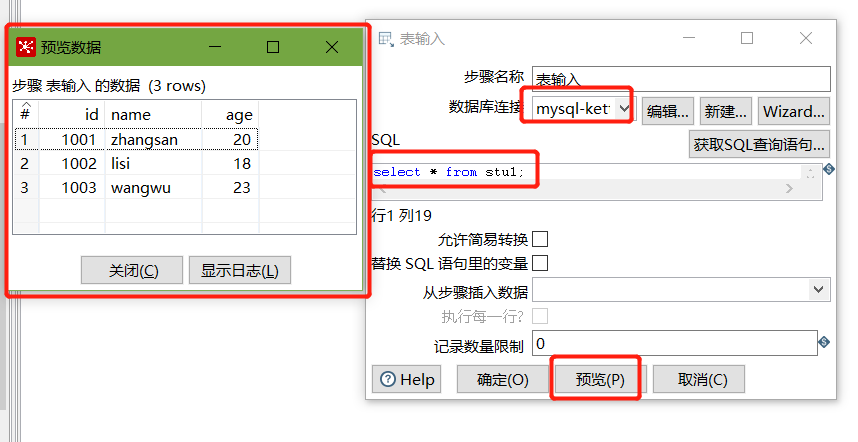
以上说明stu1的数据输入ok的,现在我们需要把输入stu1的数据同步到stu2输出的数据
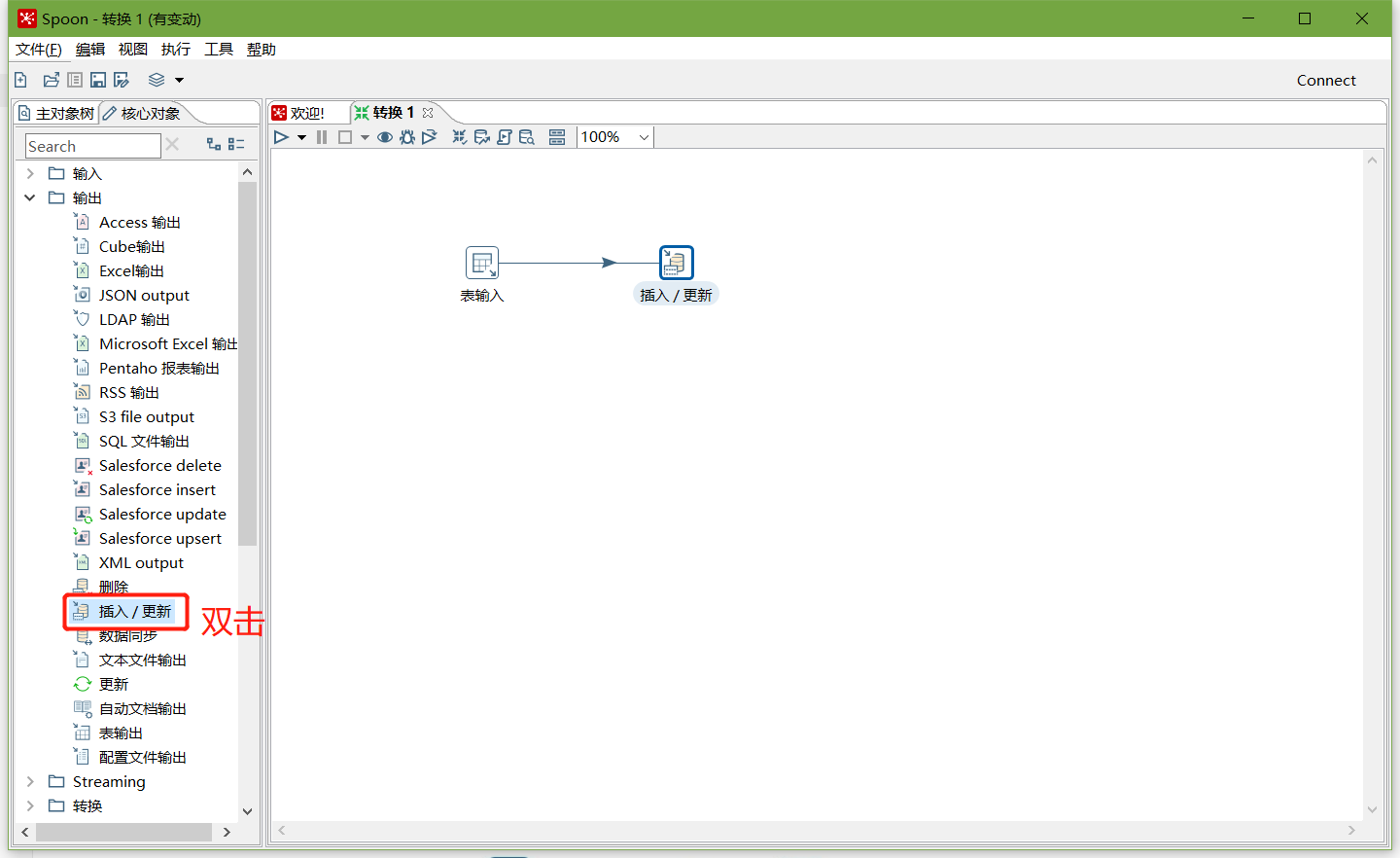
注意:拖出来的线条必须是深灰色才关联成功,若是浅灰色表示关联失败
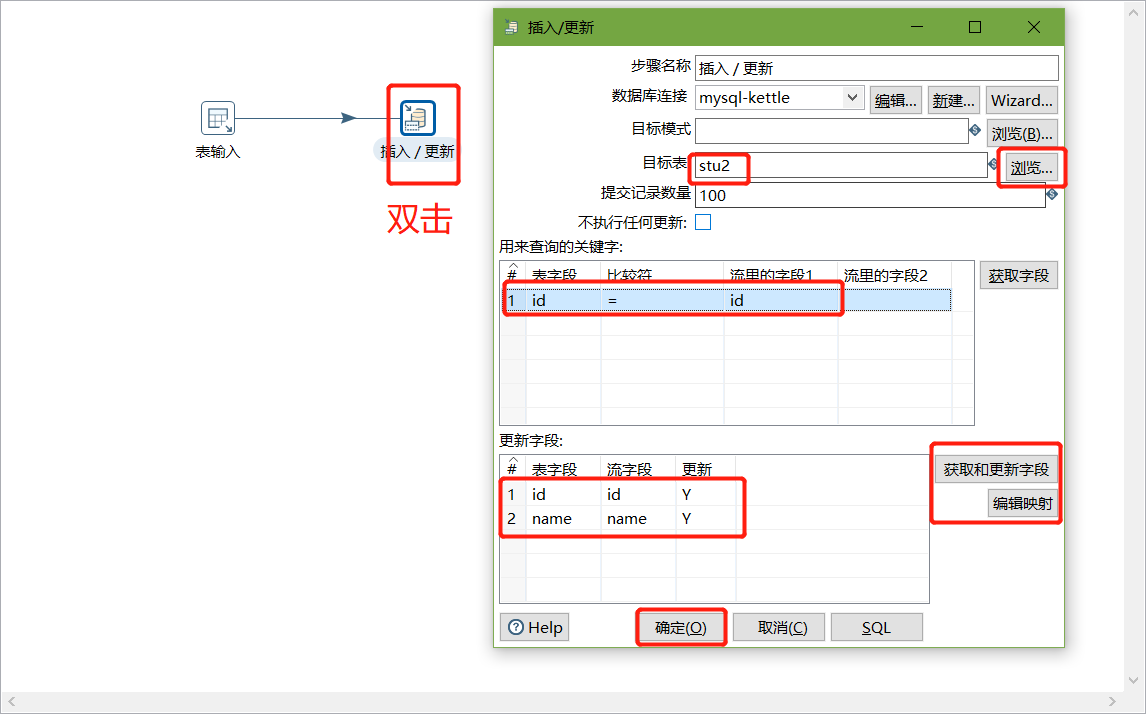
转换之前,需要做保存
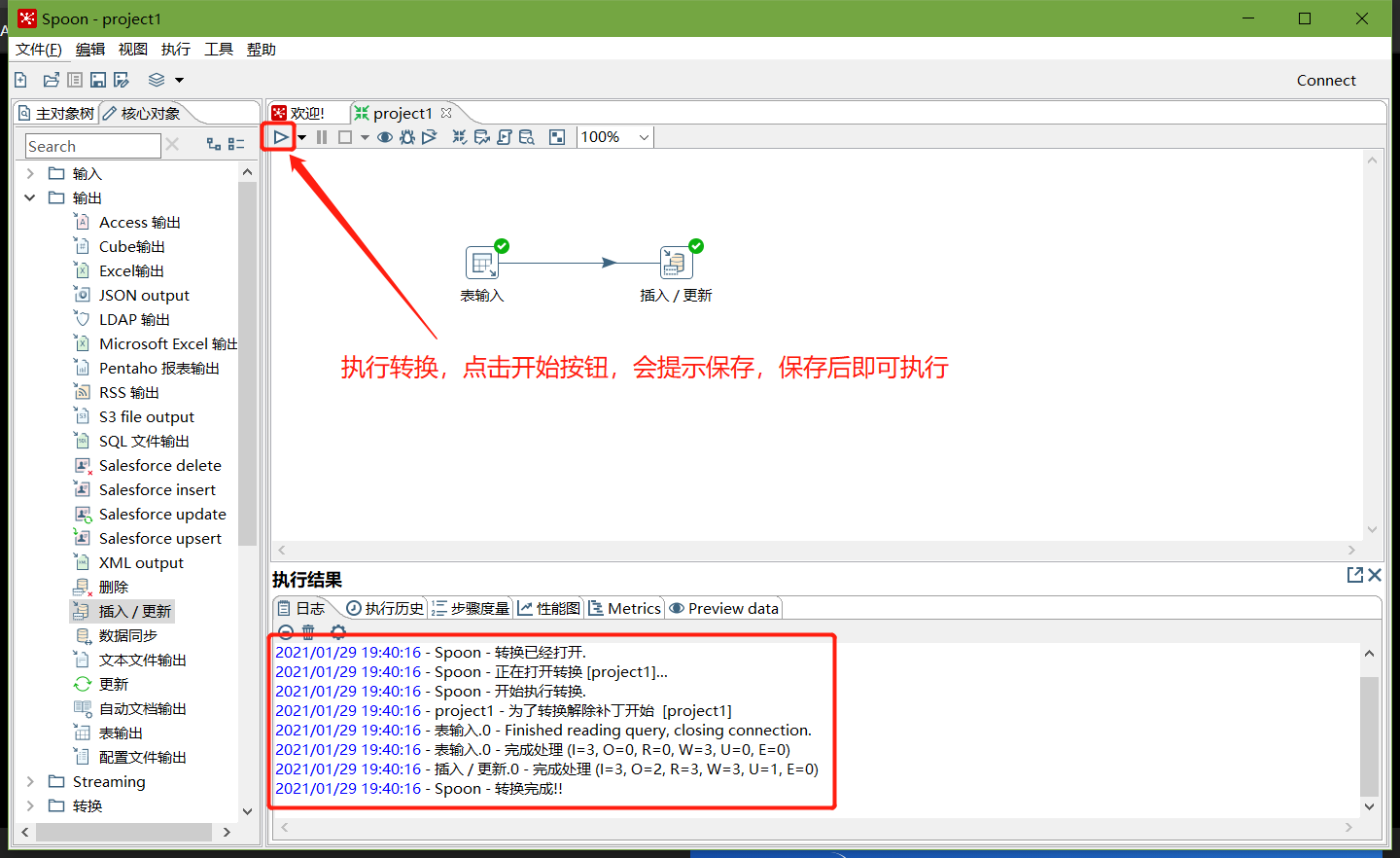
执行成功之后,可以在mysql查看,stu2的数据
mysql> select * from stu2;
+------+----------+
| id | name |
+------+----------+
| 1001 | zhangsan |
| 1002 | lisi |
| 1003 | wangwu |
+------+----------+
3 rows in set (0.00 sec)
案例2:使用作业执行上述转换,并且额外在表stu2中添加一条数据
1、新建一个作业
2、按图示拉取组件
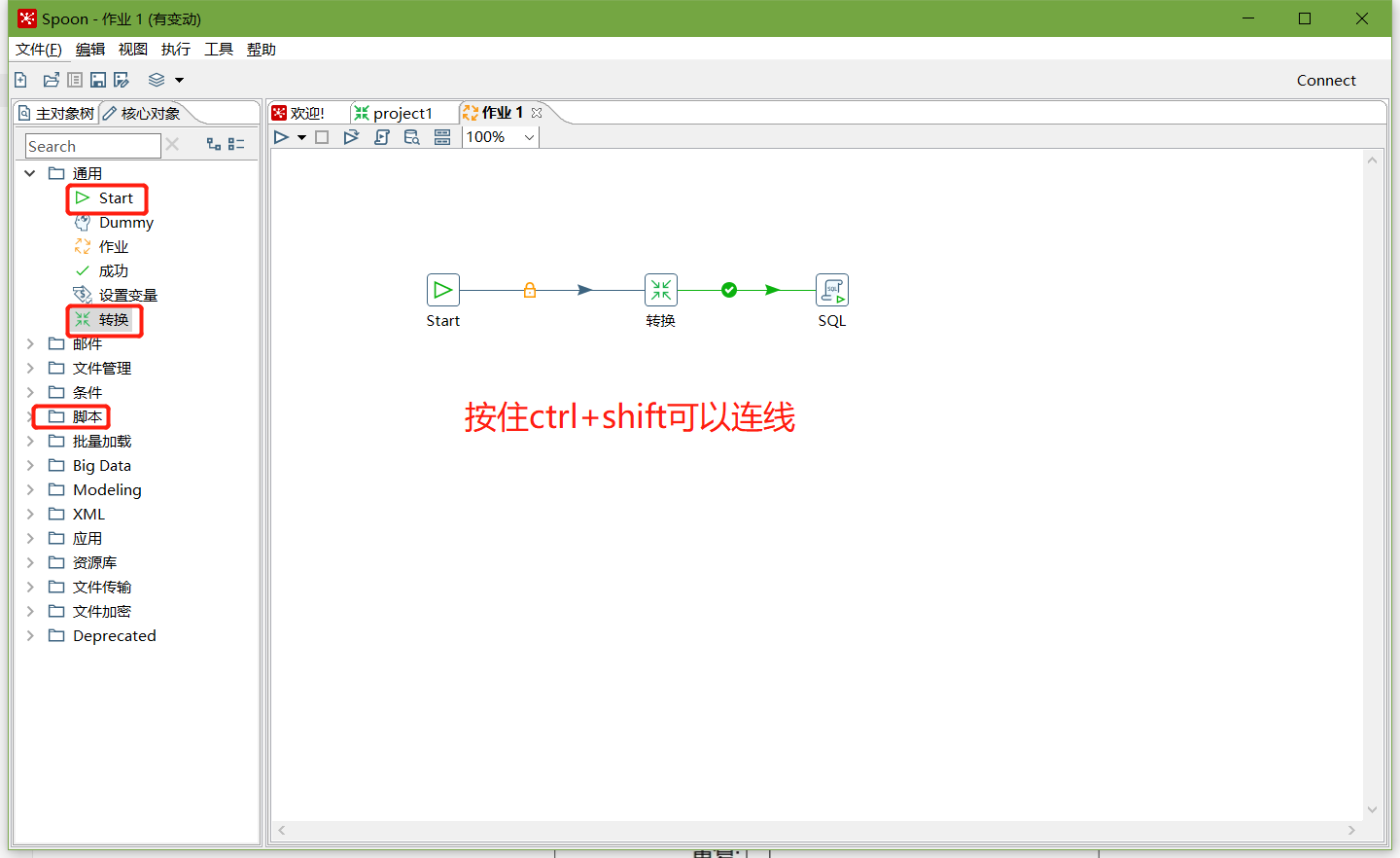
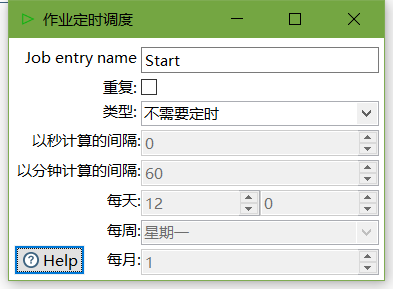
3、双击Start编辑Start
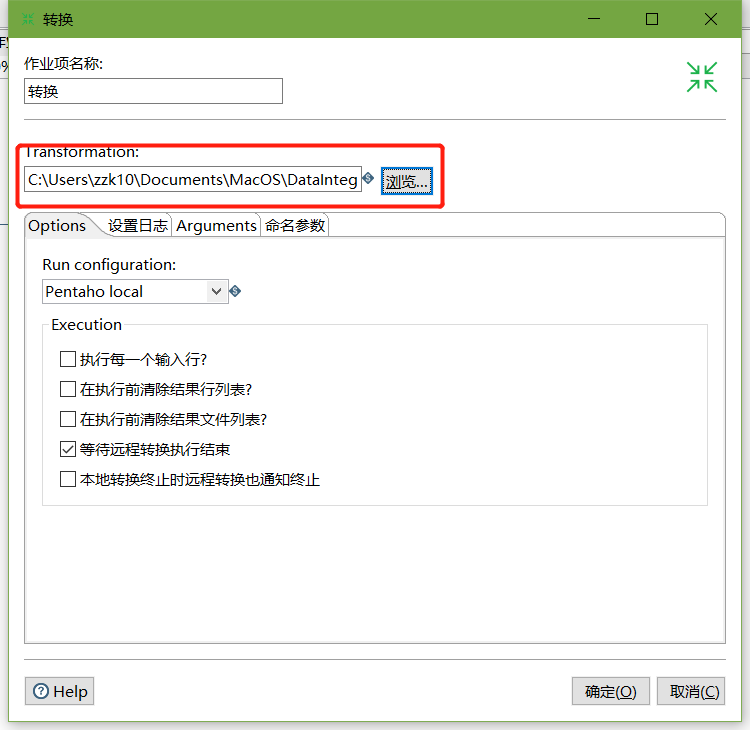
4、双击转换,选择案例1保存的文件
5、在mysql的stu1中插入一条数据,并将stu2中id=1001的name改为wukong
mysql> insert into stu1 values(1004,'stu1',22);
Query OK, 1 row affected (0.01 sec)
mysql> update stu2 set name = 'wukong' where id = 1001;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
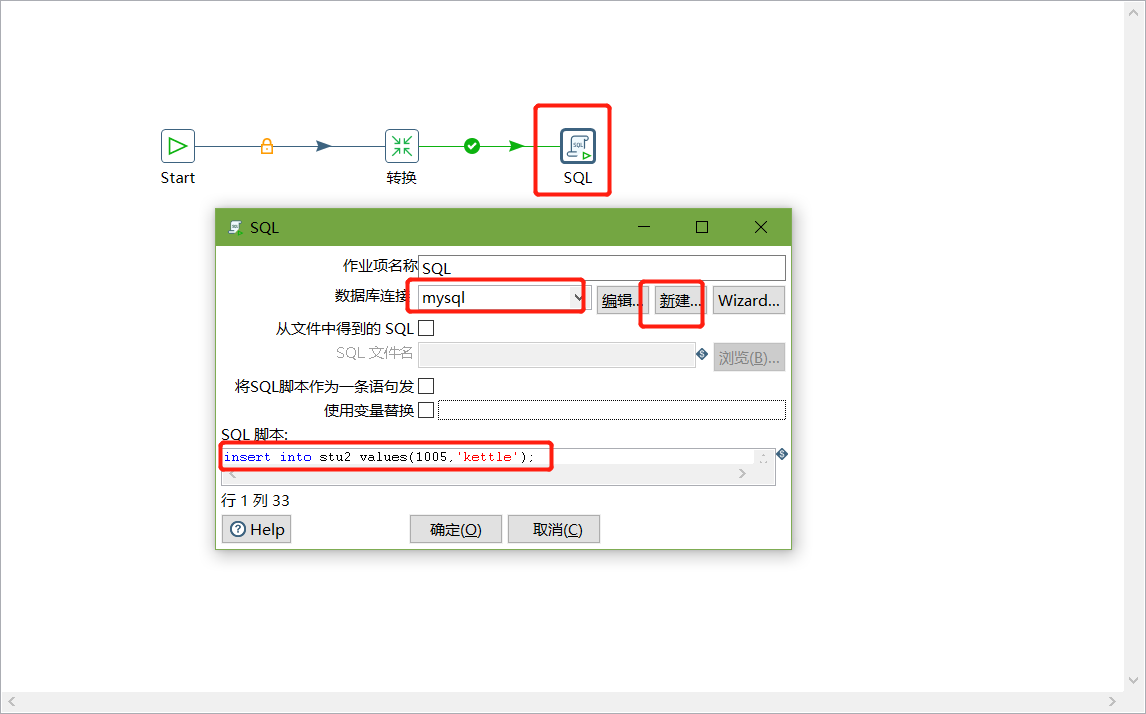
6、双击SQL脚本编辑
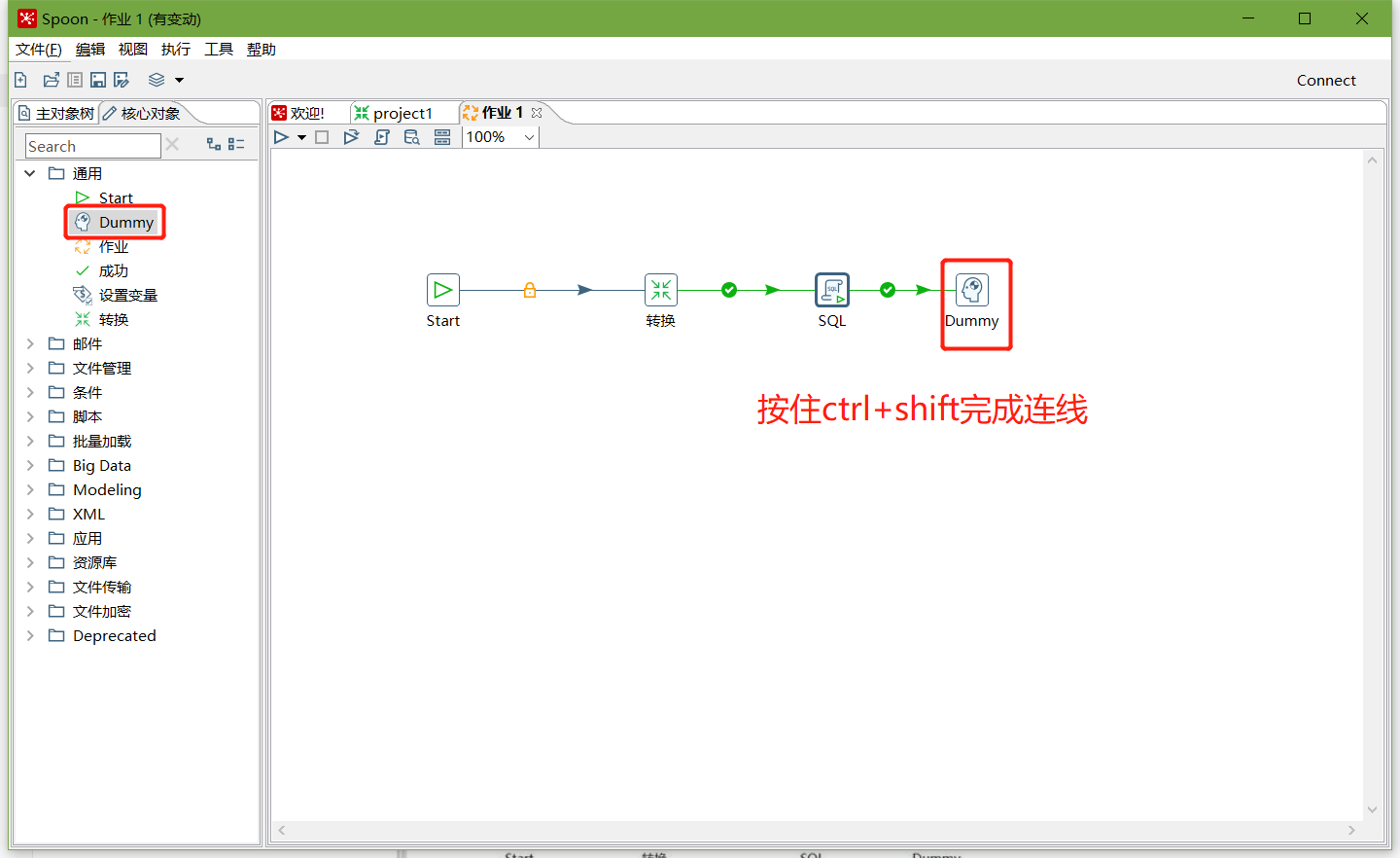
7、加上Dummy,如图所示:
8、保存并执行
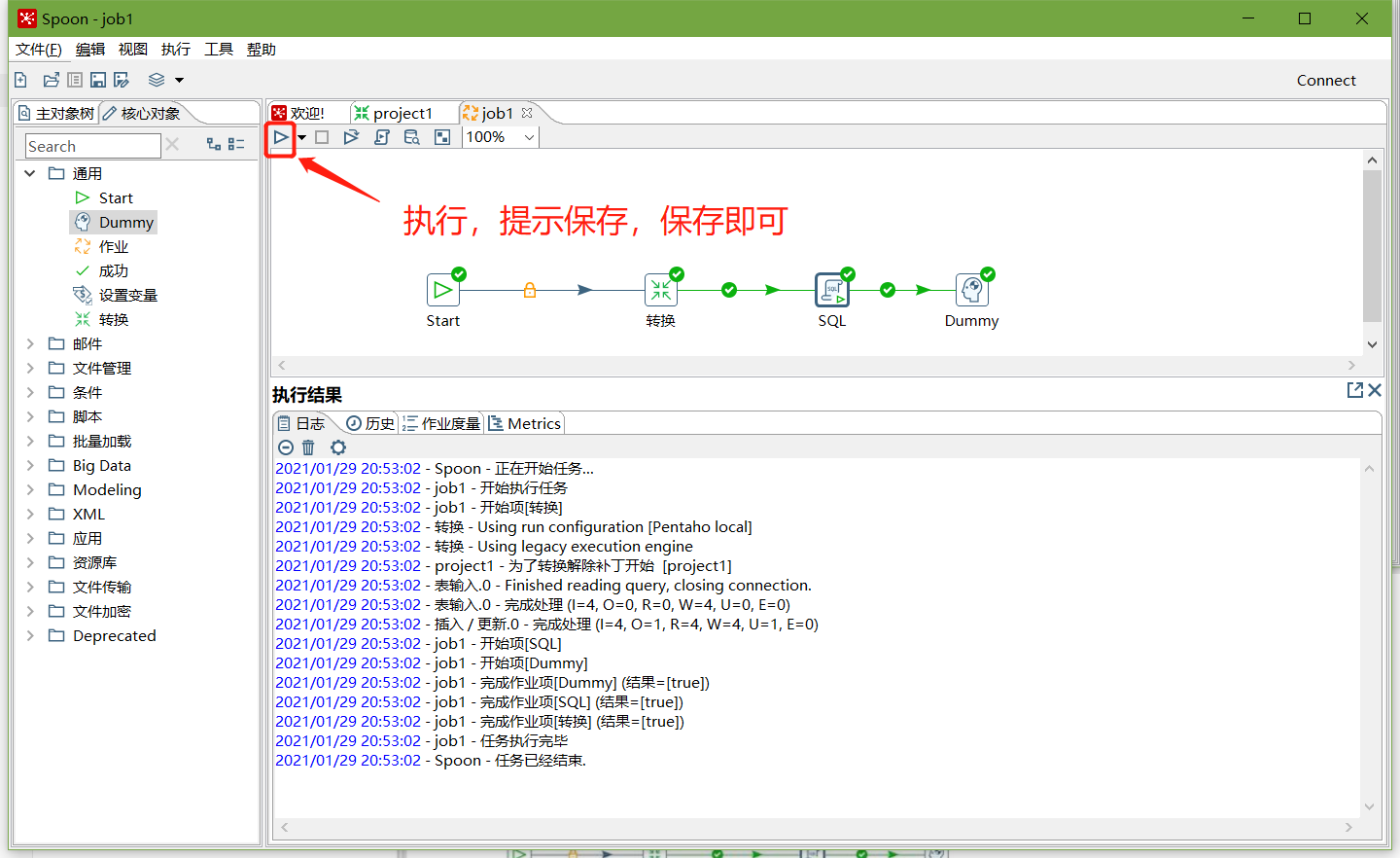
9、在mysql数据库查看stu2表的数据
mysql> select * from stu2;
+------+----------+
| id | name |
+------+----------+
| 1001 | zhangsan |
| 1002 | lisi |
| 1003 | wangwu |
| 1004 | stu1 |
| 1005 | kettle |
+------+----------+
5 rows in set (0.00 sec)
案例3:将hive表的数据输出到hdfs
1、因为涉及到hive和hbase(后续案例)的读写,需要修改相关配置文件
修改解压目录下的data-integration\plugins\pentaho-big-data-plugin下的plugin.properties,设置active.hadoop.configuration=hdp26,26是指用hdp26文件夹里面的配置,从我们的hadoop,hive,hbase中将这些配置拷贝到data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp26下
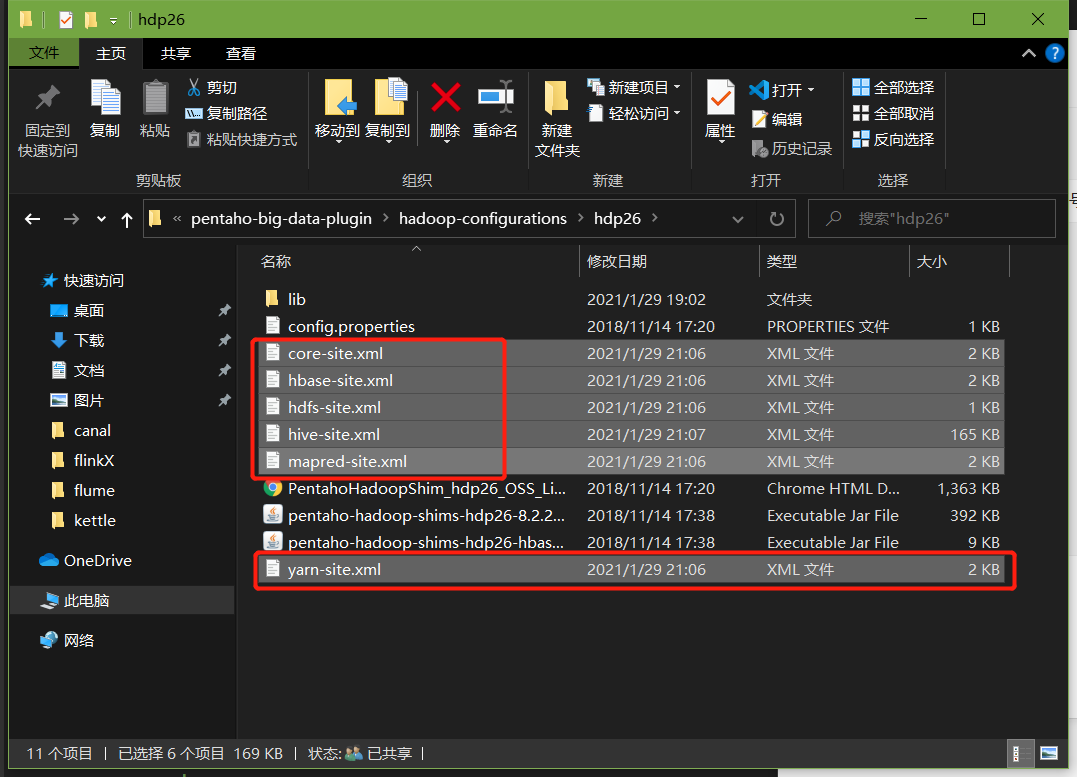
2、启动hadoop集群、hiveserver2服务
可以用来监控日志
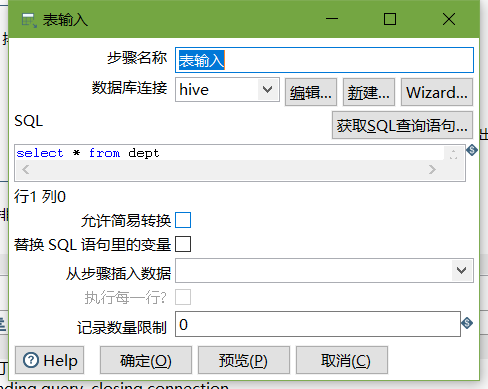
3、进入hive shell,创建kettle数据库,并创建dept、emp表
create database kettle;
use kettle;
CREATE TABLE dept(
deptno int,
dname string,
loc string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm int,
deptno int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
4、插入数据
insert into dept values(10,'accounting','NEW YORK'),(20,'RESEARCH','DALLAS'),(30,'SALES','CHICAGO'),(40,'OPERATIONS','BOSTON');
insert into emp values(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20),(7499,'ALLEN','SALESMAN',7698,'1980-12-17',1600,300,30),(7521,'WARD','SALESMAN',7698,'1980-12-17',1250,500,30),(7566,'JONES','MANAGER',7839,'1980-12-17',2975,NULL,20);
5、按下图建立流程图
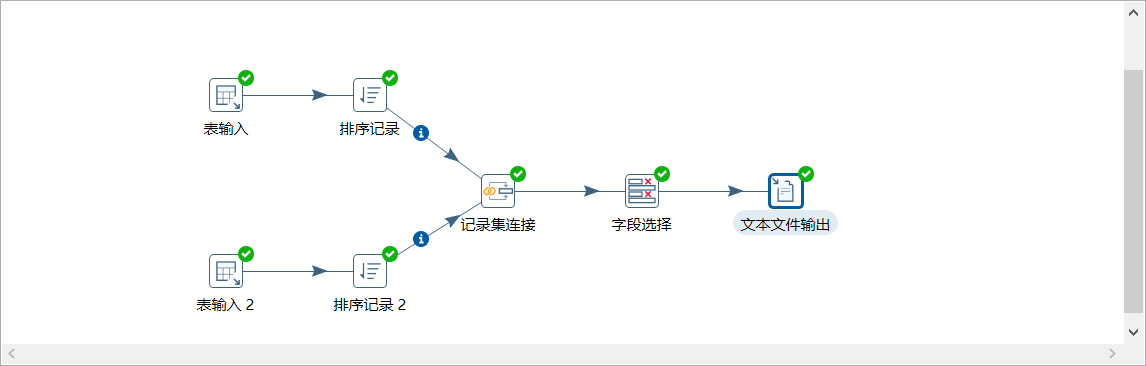
- 表输入
- 表输入2
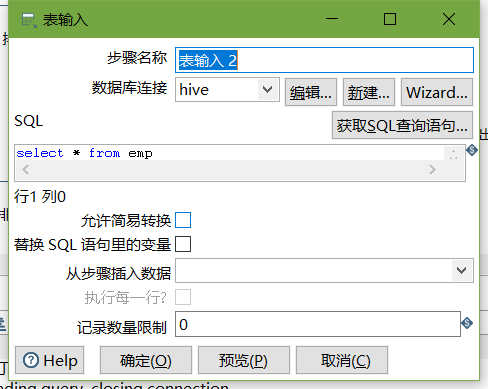
- 排序记录
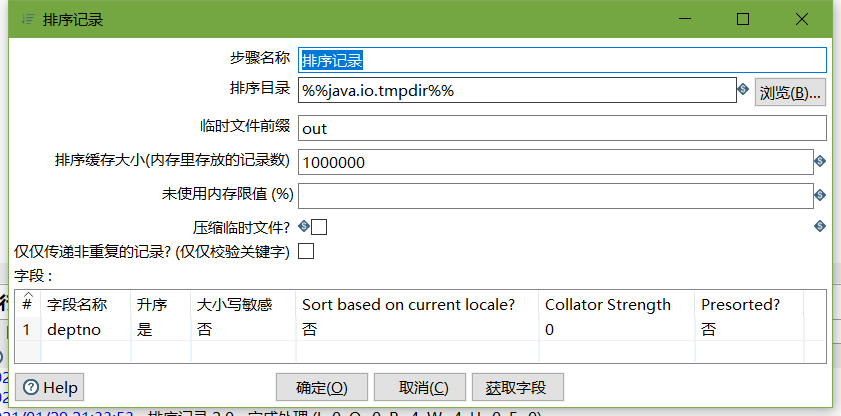
- 记录集连接
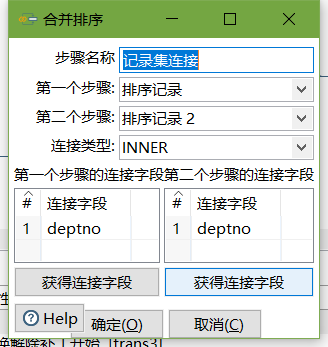
- 字段选择
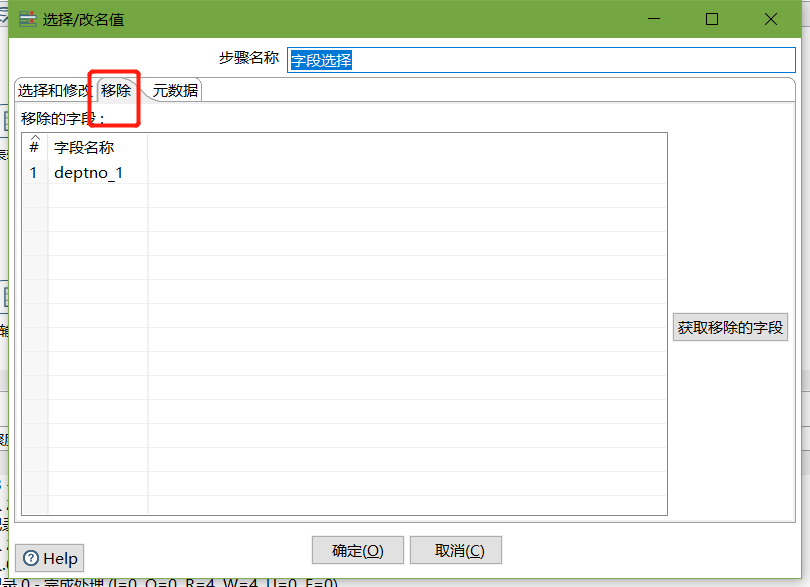
- 文本文件输出
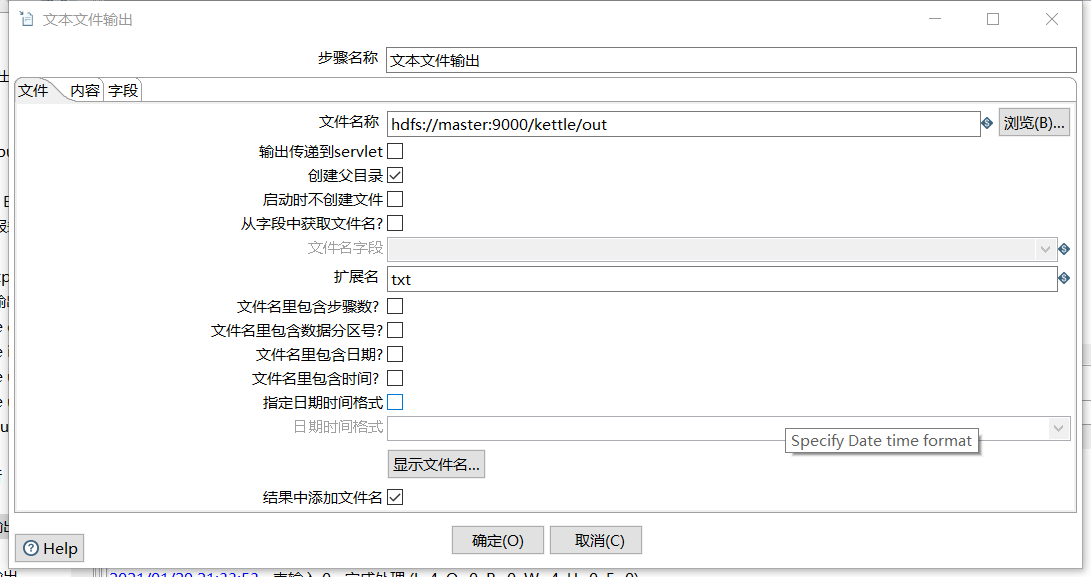
6、保存并运行查看hdfs
- 运行
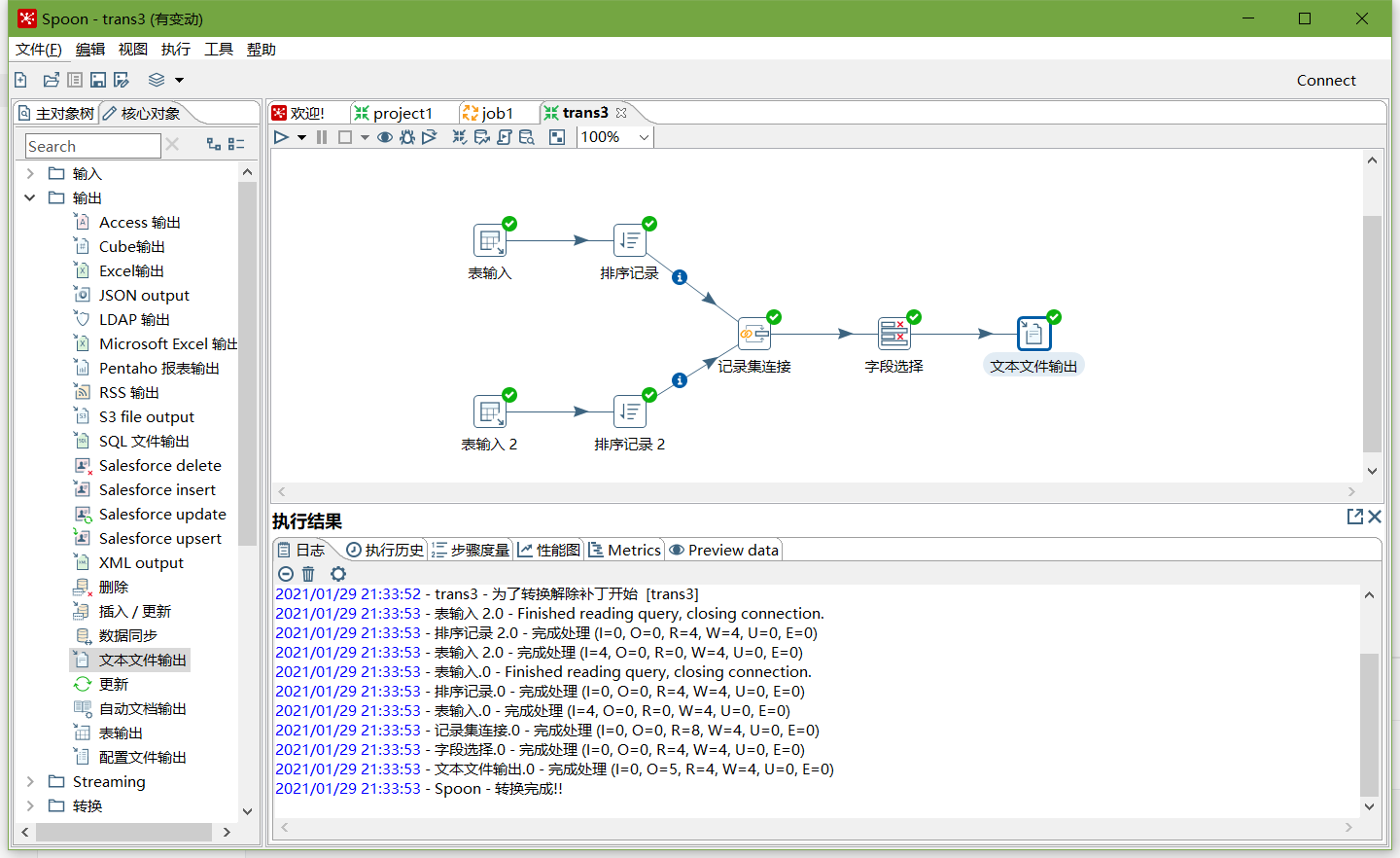
- 查看HDFS文件
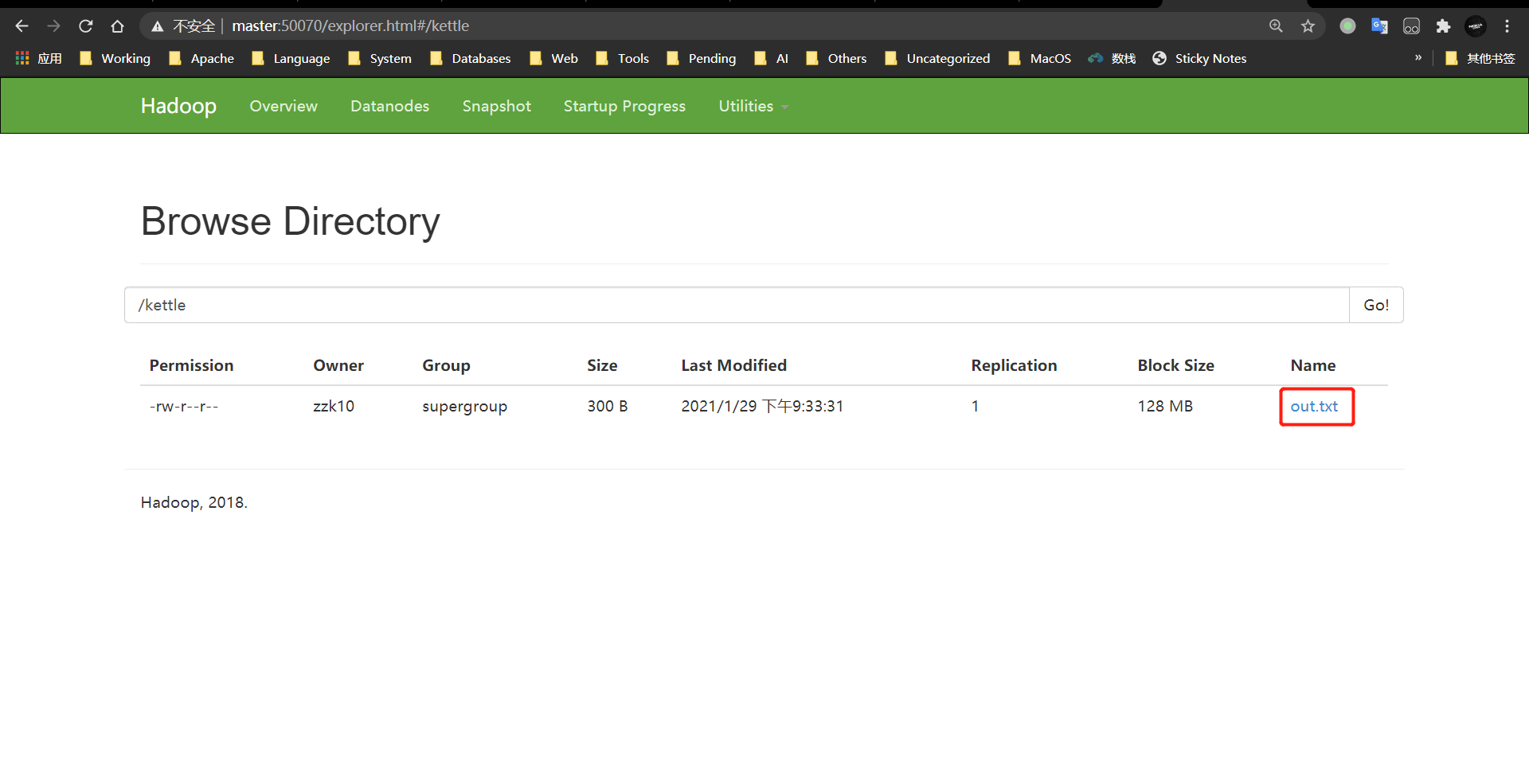
案例4:读取hdfs文件并将sal大于1000的数据保存到hbase中
1、在HBase中创建一张people表
hbase(main):004:0> create 'people','info'
2、按下图建立流程图
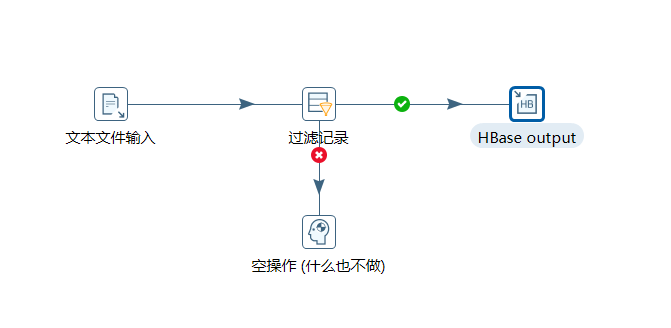
- 文本文件输入
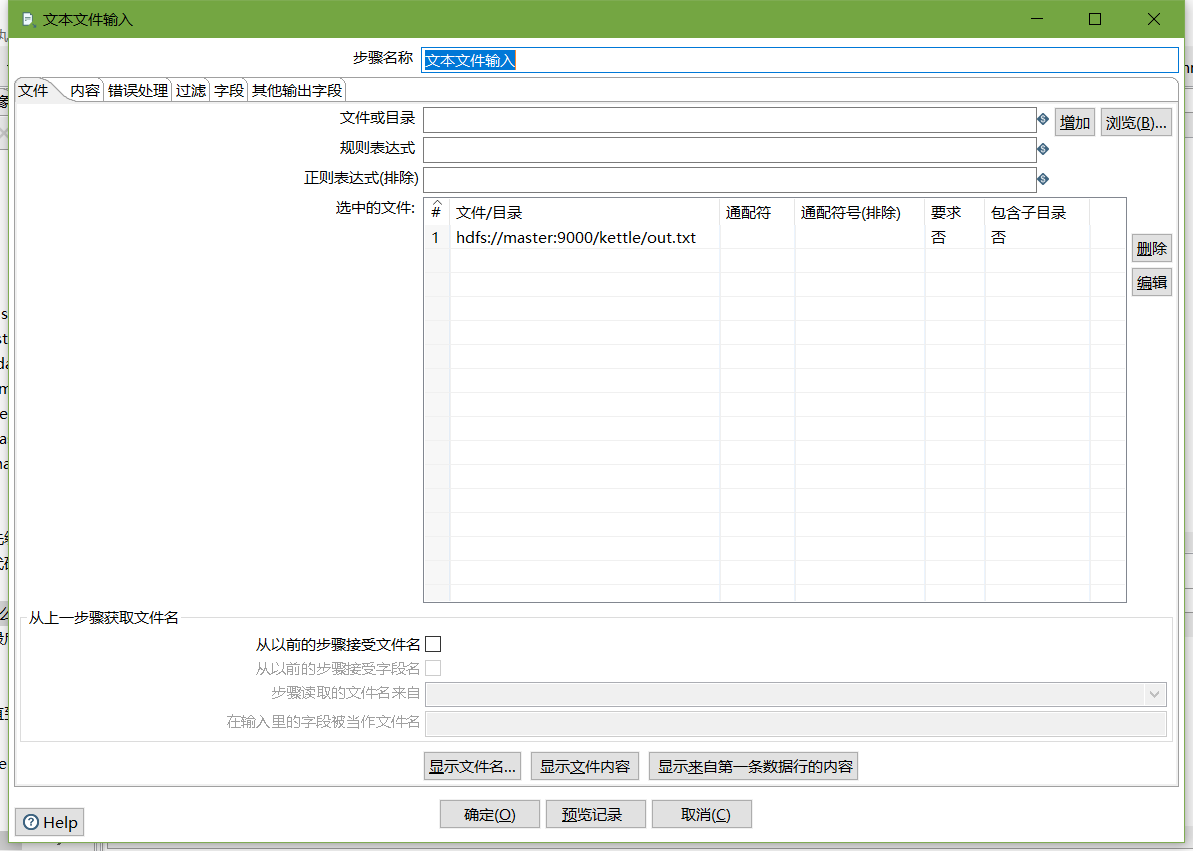
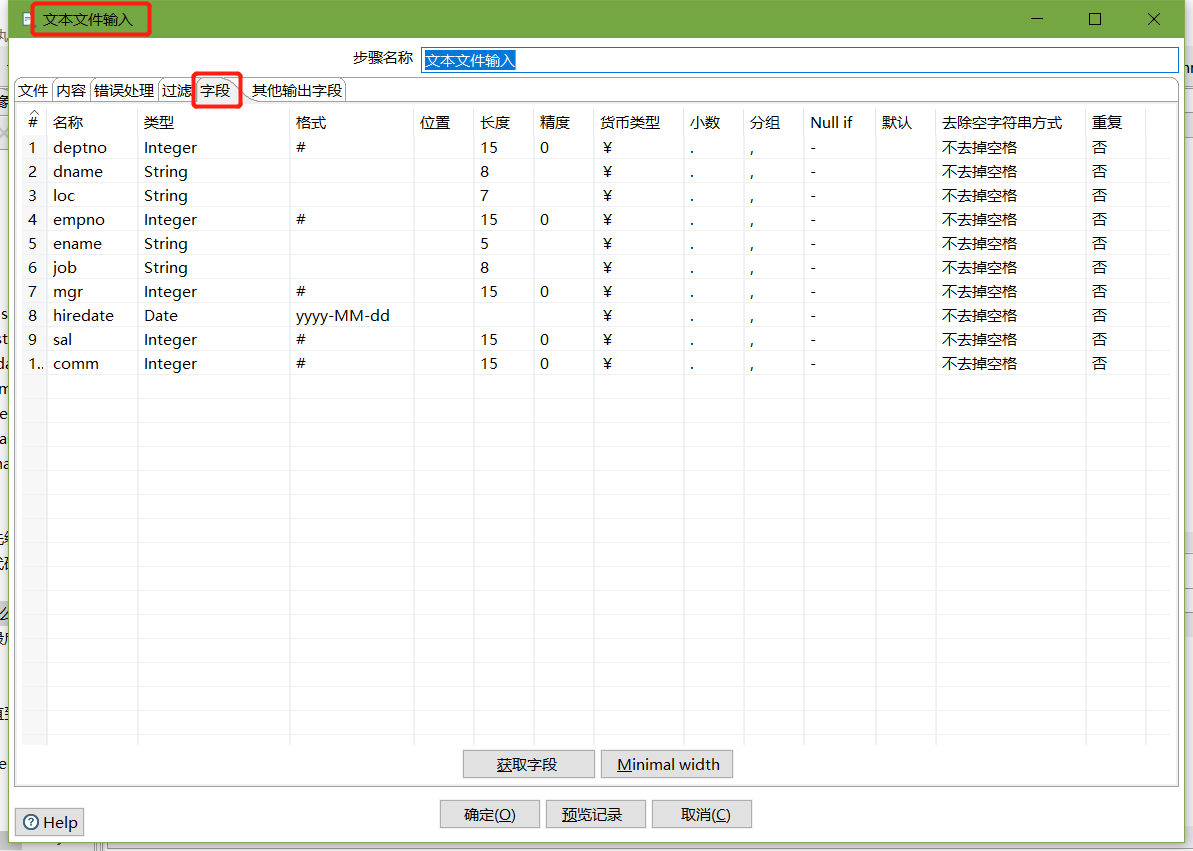
- 设置过滤记录
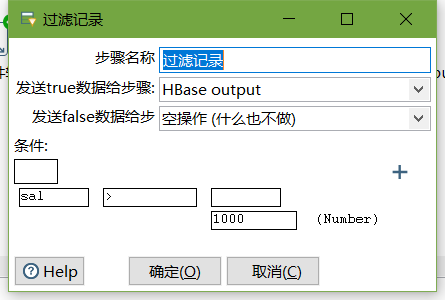
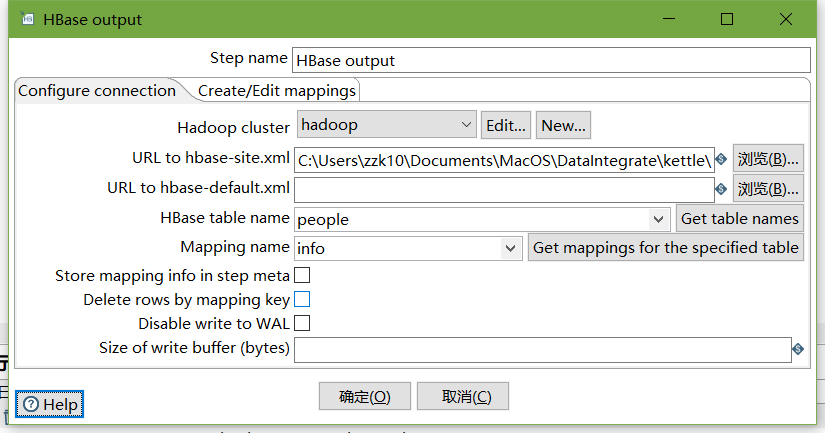
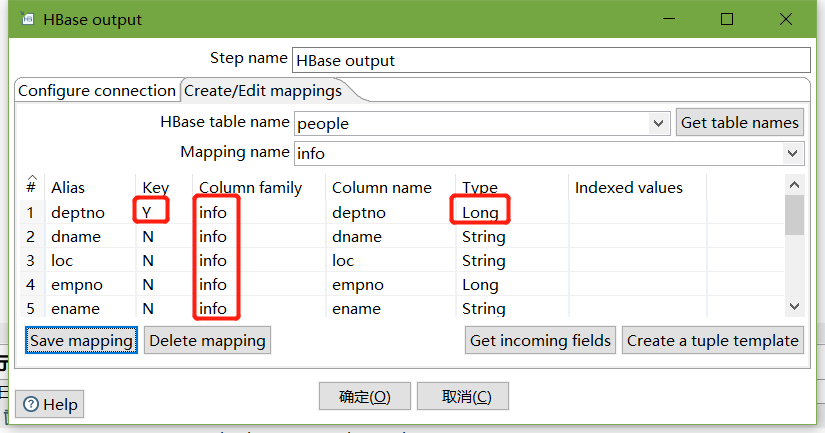
设置HBase output
编辑hadoop连接,并配置zookeeper地址
- 执行转换
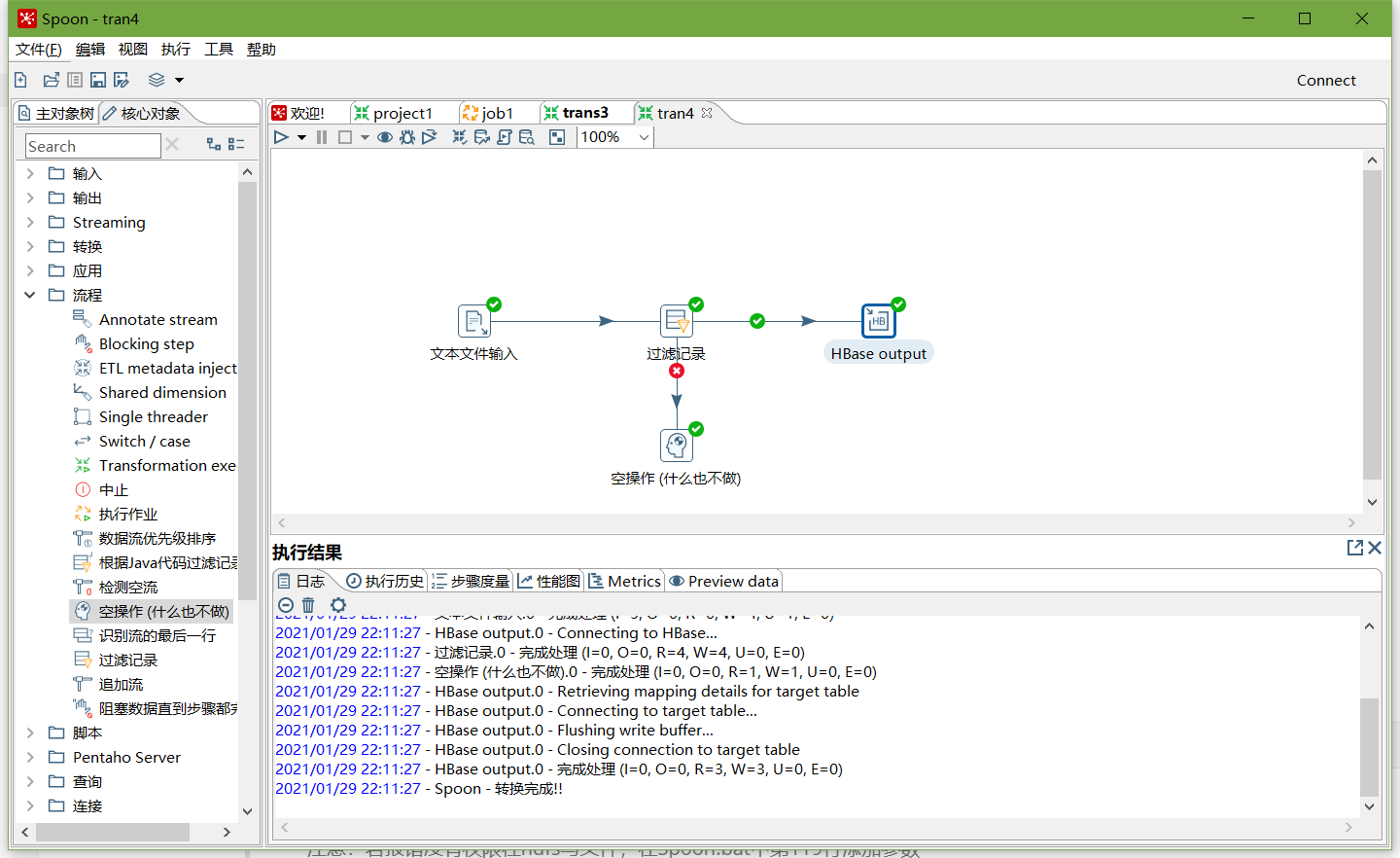
查看hbase people表的数据
scan 'people'
注意:若报错没有权限往hdfs写文件,在Spoon.bat中第119行添加参数
"-DHADOOP_USER_NAME=root" "-Dfile.encoding=UTF-8"
三、创建资源库
1、数据库资源库
数据库资源库是将作业和转换相关的信息存储在数据库中,执行的时候直接去数据库读取信息,方便跨平台使用
在MySQL中创建kettle数据库
mysql> create database kettle;
Query OK, 1 row affected (0.01 sec)
点击右上角connect,选择Other Resporitory
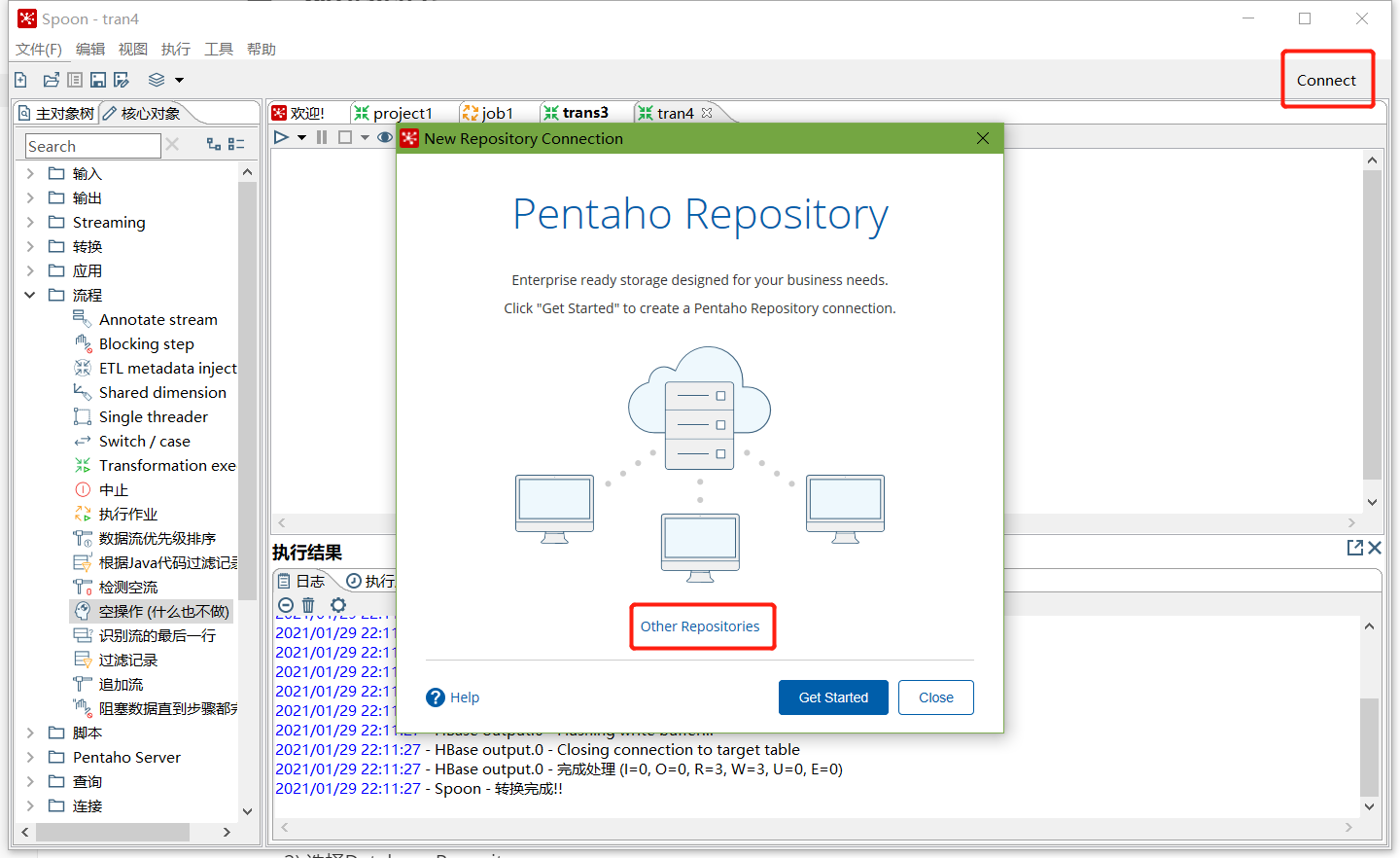
- 选择Database Repository
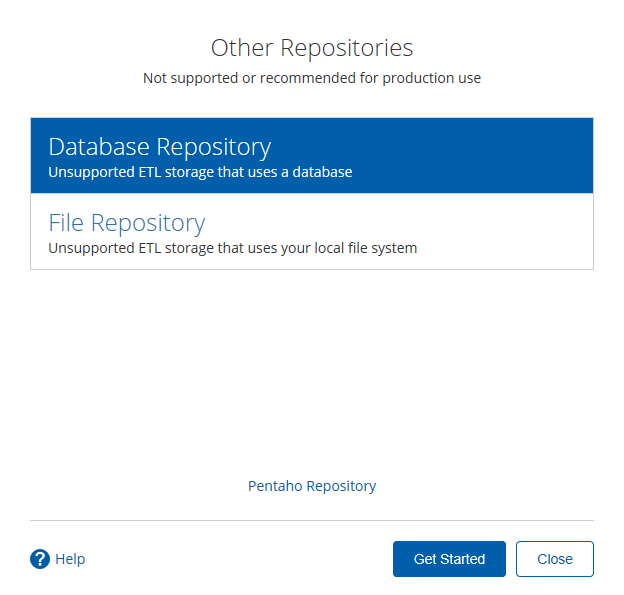
- 建立新连接
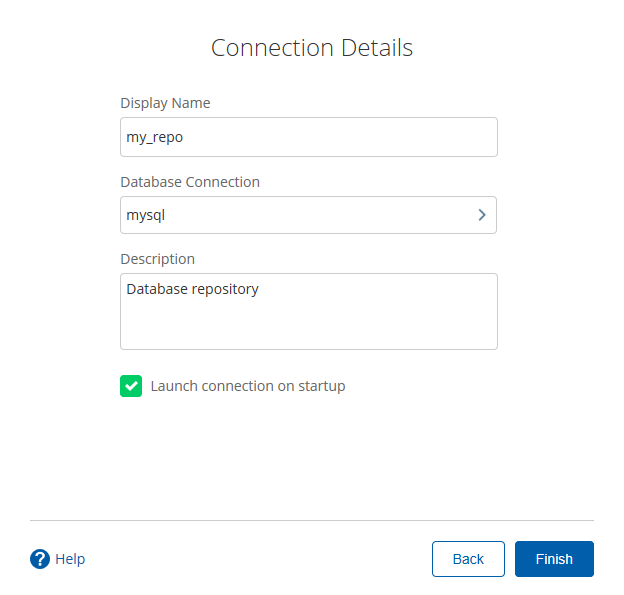
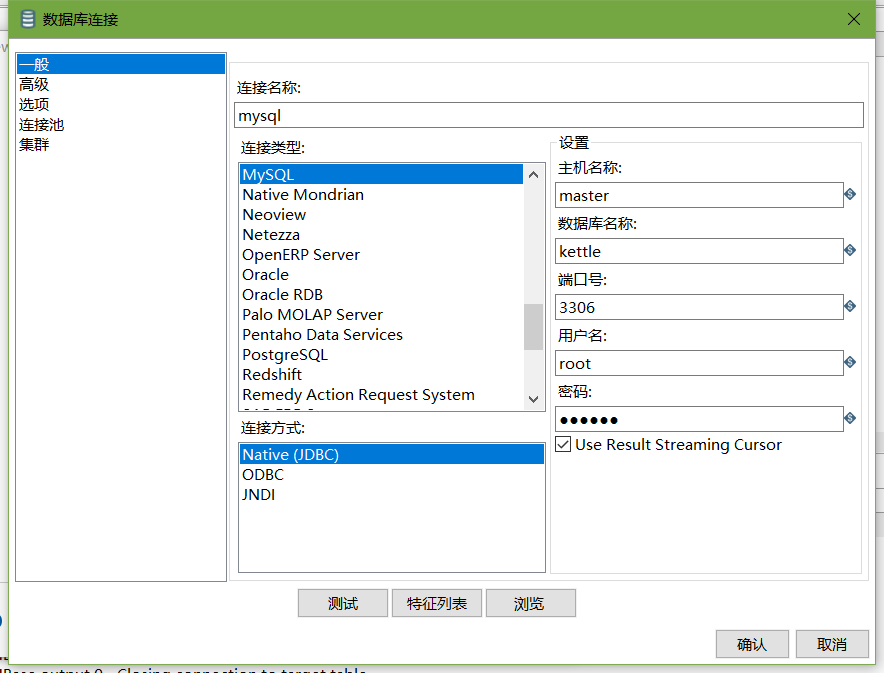
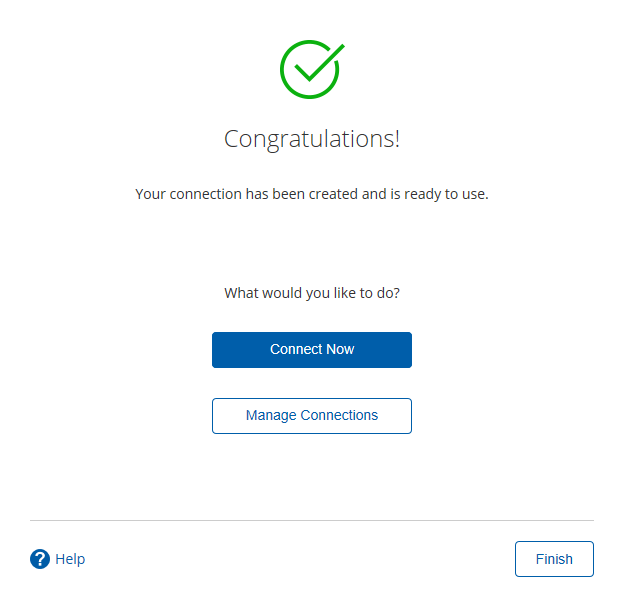
- 填好之后,点击finish,会在指定的库中创建很多表,至此数据库资源库创建完成
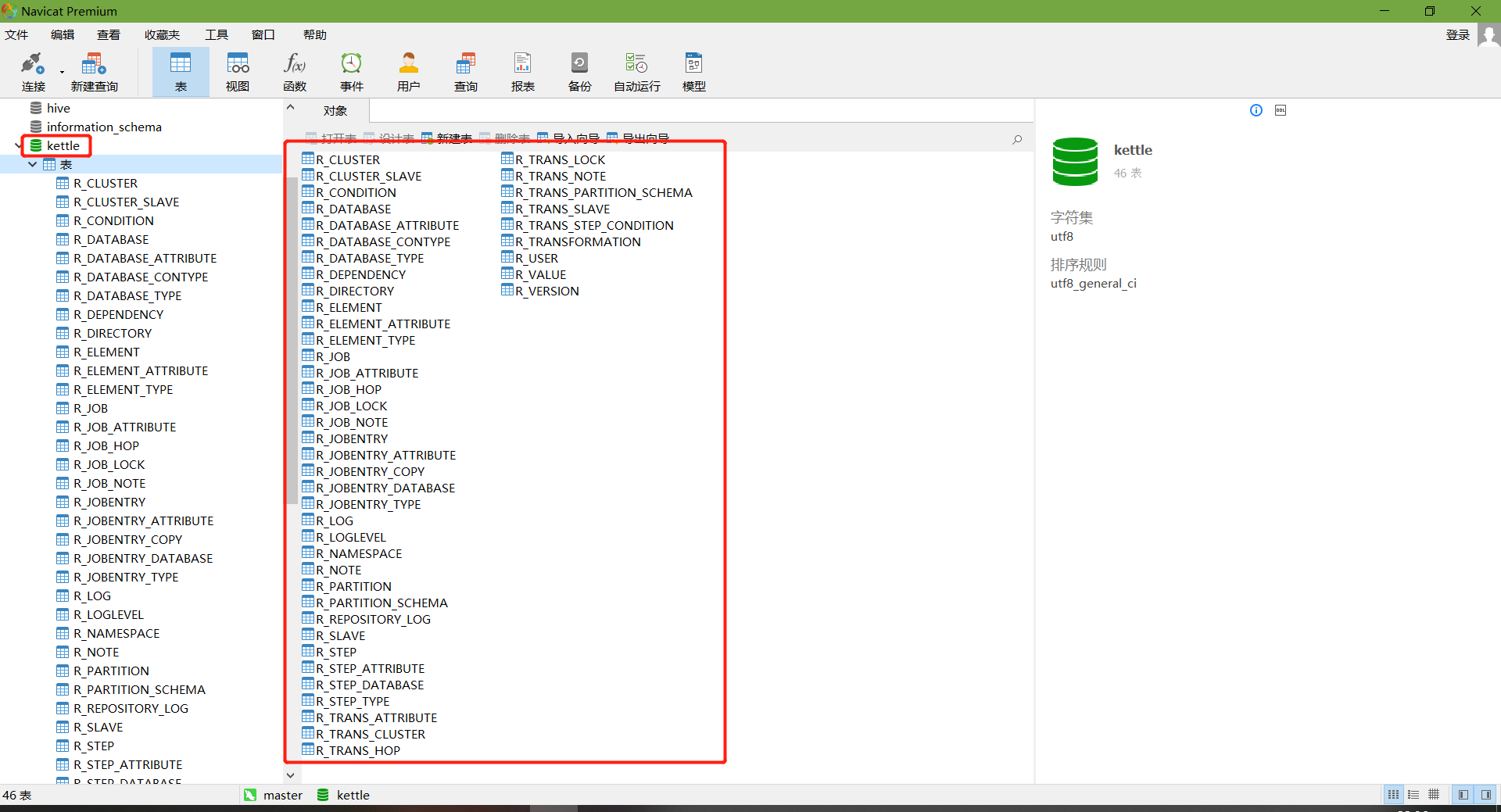
连接资源库
默认账号密码为admin
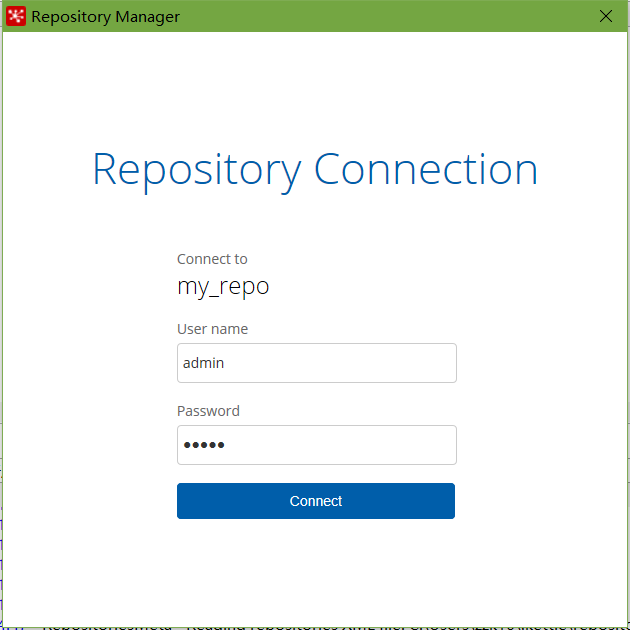
将之前做过的转换导入资源库
选择从xml文件导入
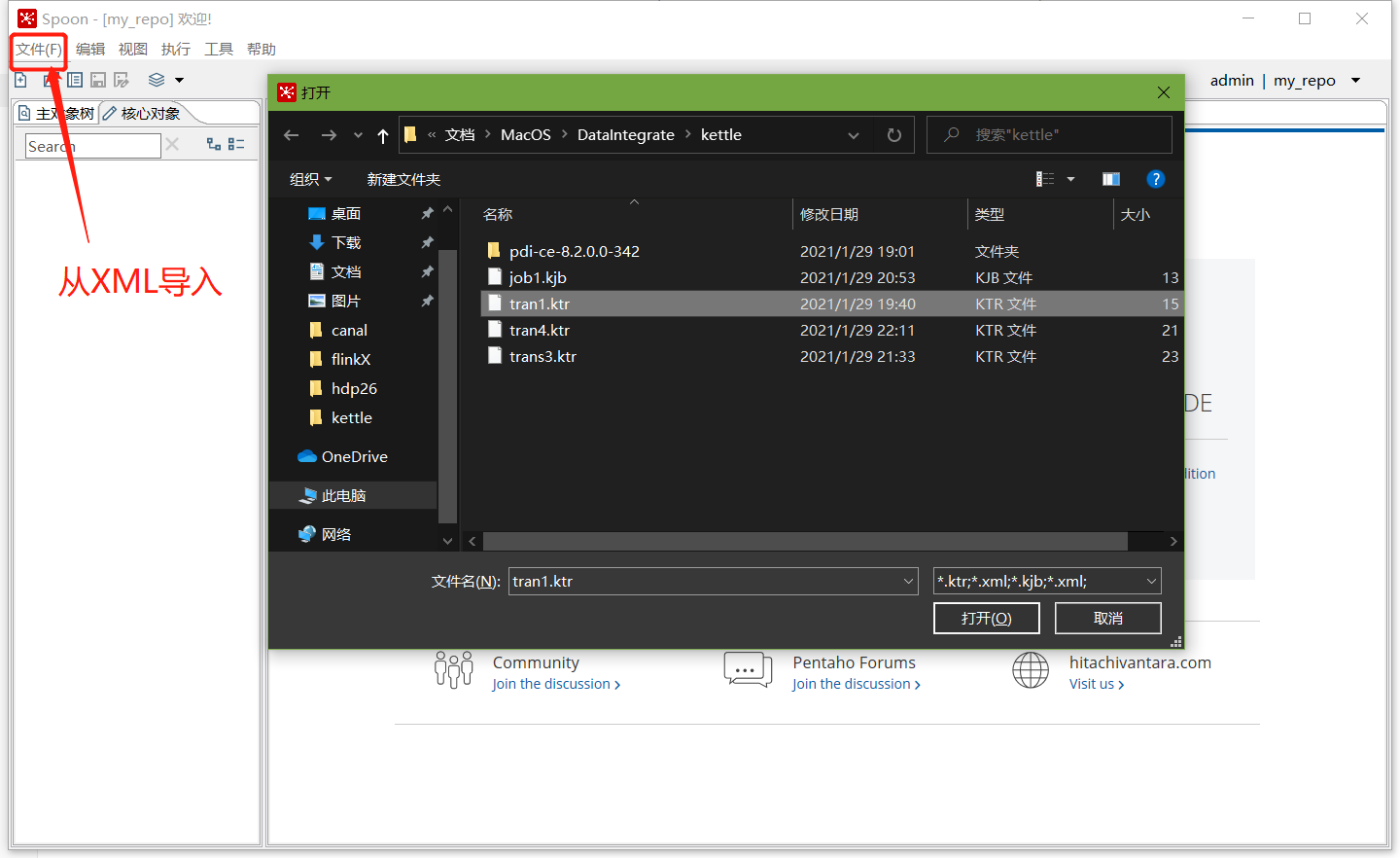
点击保存,选择存储位置及文件名
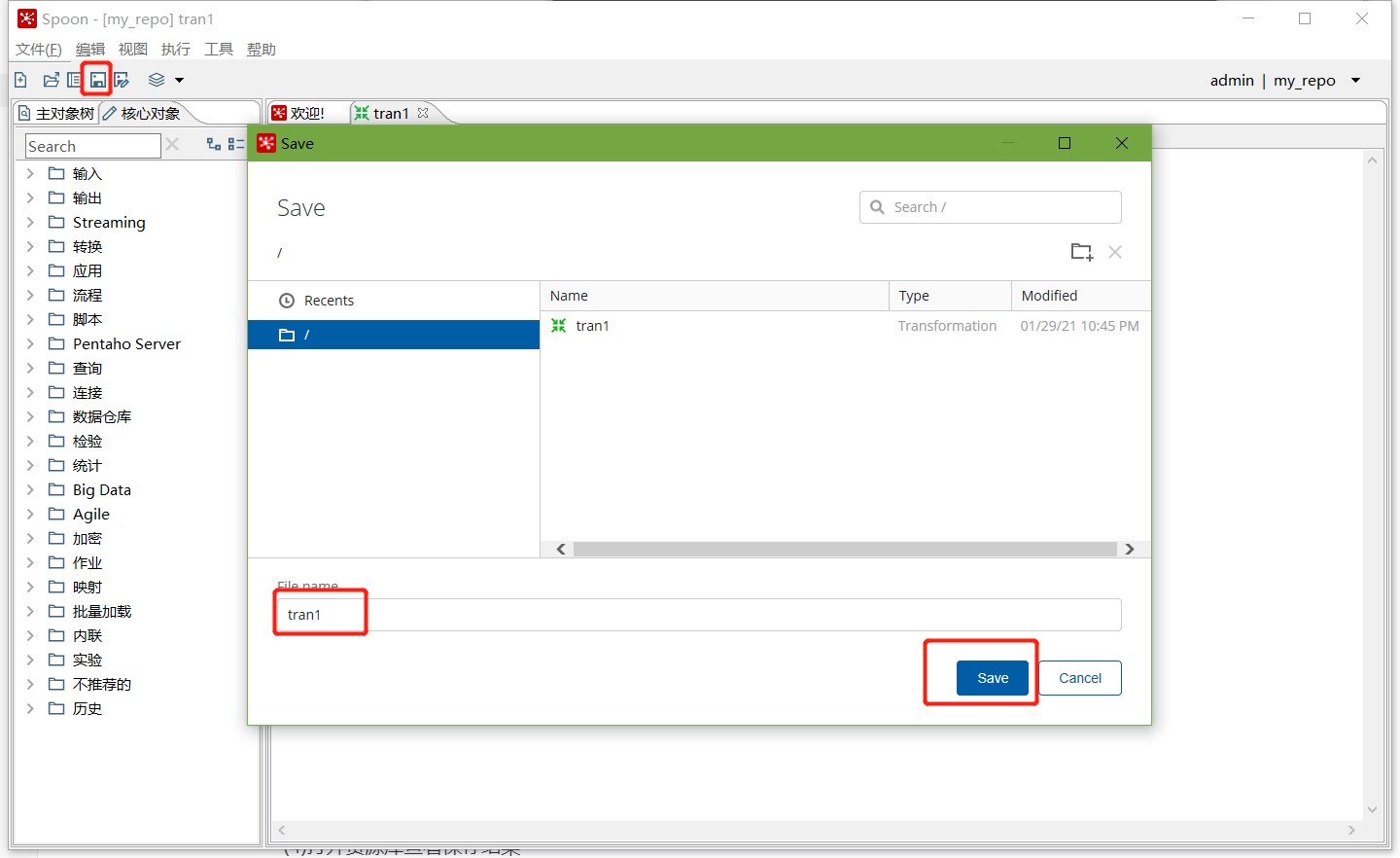
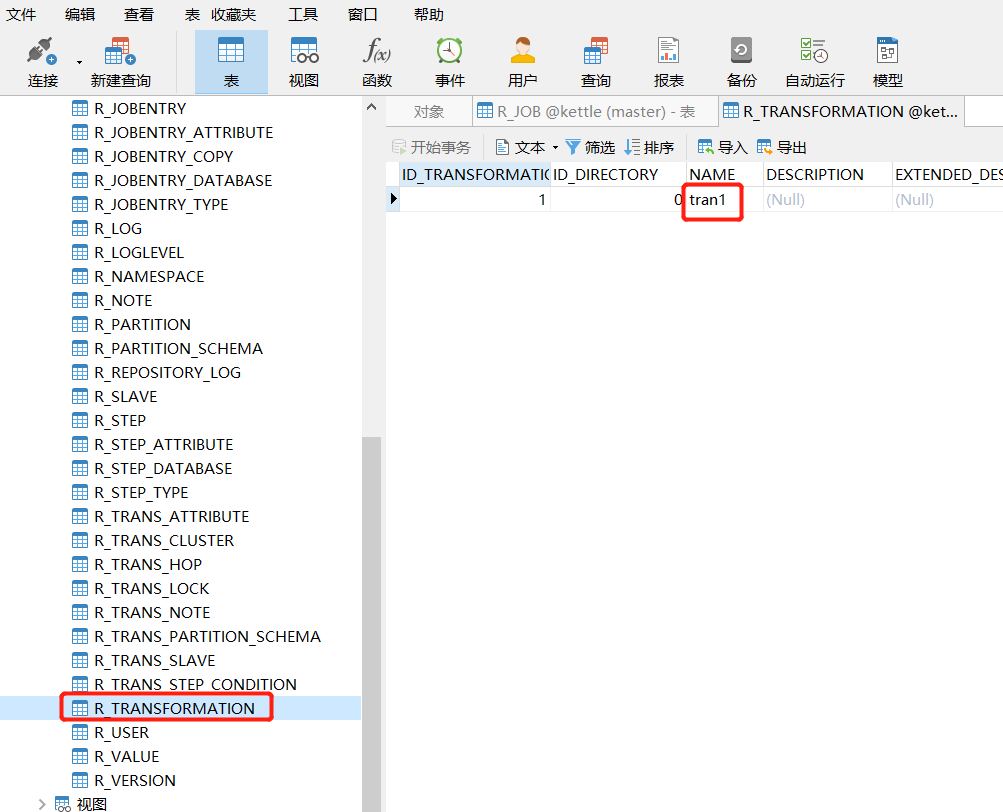
查看MySQL中kettle库中的R_TRANSFORMATION表,观察转换是否保存
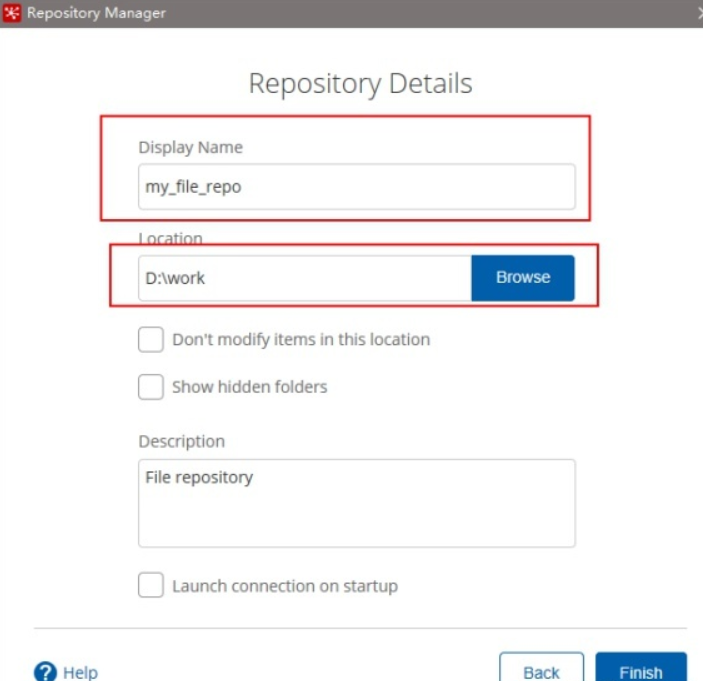
2、文件资源库
将作业和转换相关的信息存储在指定的目录中,其实和XML的方式一样
创建方式跟创建数据库资源库步骤类似,只是不需要用户密码就可以访问,跨
平台使用比较麻烦
选择connect
点击add后点击Other Repositories
选择File Repository
填写信息
四、 Linux下安装使用
1、单机
jdk安装
安装包上传到服务器,并解压
注意:
把mysql驱动拷贝到lib目录下
将windows本地用户家目录下的隐藏目录C:\Users\自己用户名\.kettle 目录,
整个上传到linux的用户的家目录下,root用户的家目录为/root/
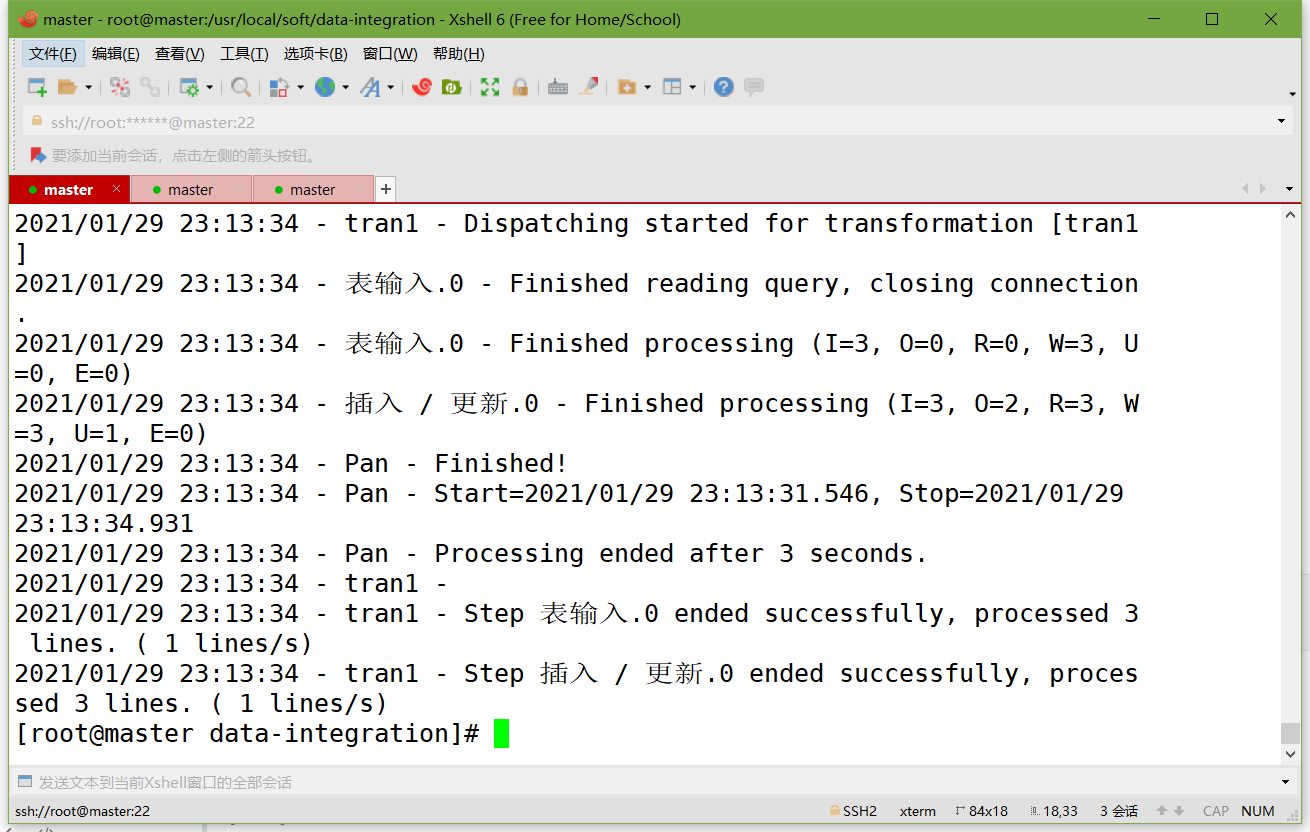
运行数据库资源库中的转换:
cd /usr/local/soft/data-integration
./pan.sh -rep=my_repo -user=admin -pass=admin -trans=tran1
参数说明:
-rep 资源库名称
-user 资源库用户名
-pass 资源库密码
-trans 要启动的转换名称
-dir 目录(不要忘了前缀 /)(如果是以ktr文件运行时,需要指定ktr文件的路径)
运行资源库里的作业:
记得把作业里的转换变成资源库中的资源
记得把作业也变成资源库中的资源
cd /usr/local/soft/data-integration
mkdir logs
./kitchen.sh -rep=my_repo -user=admin -pass=admin -job=job1 -logfile=./logs/log.txt
参数说明:
-rep - 资源库名
-user - 资源库用户名
-pass – 资源库密码
-job – job名
-dir – job路径(当直接运行kjb文件的时候需要指定)
-logfile – 日志目录
2、 集群模式
准备三台服务器
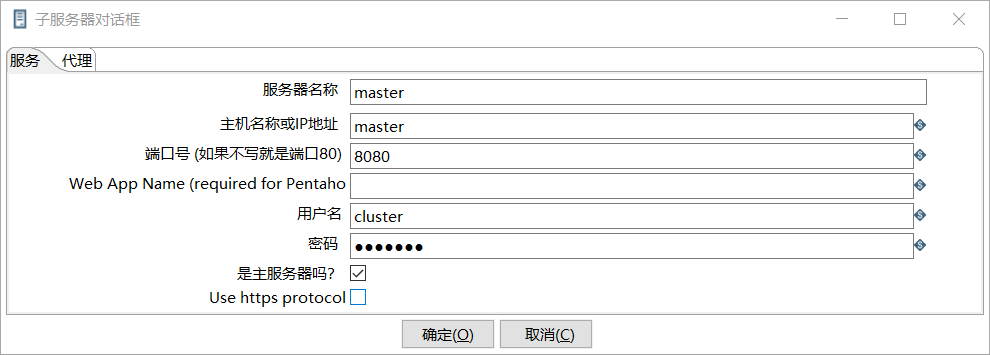
master作为Kettle主服务器,服务器端口号为8080,
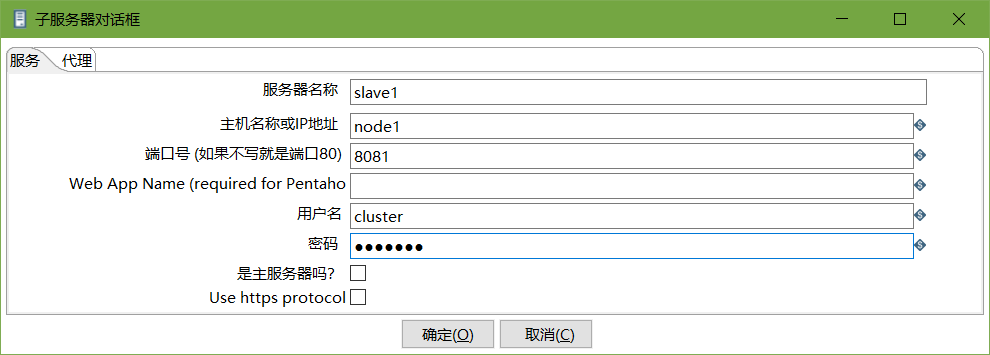
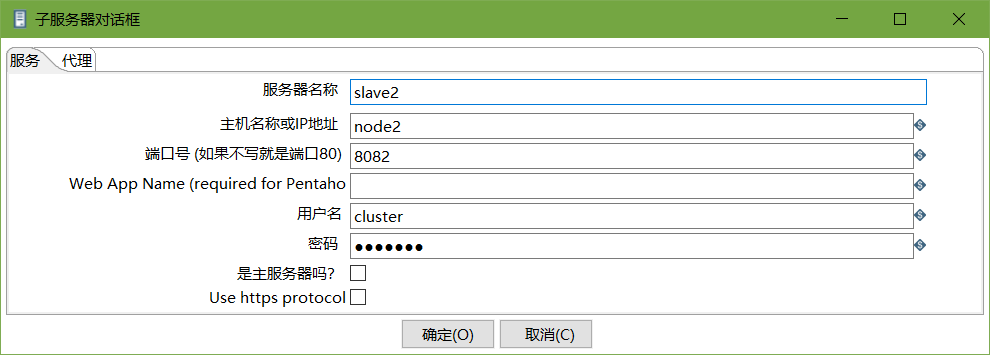
node1和node2作为两个子服务器,端口号分别为8081和8082。
安装部署jdk
hadoop完全分布式环境搭建
上传并解压kettle的安装包至
/usr/local/soft/目录下进到/usr/local/soft/data-integration/pwd目录,修改配置文件
修改主服务器配置文件carte-config-master-8080.xml
<slaveserver>
<name>master</name>
<hostname>master</hostname>
<port>8080</port>
<master>Y</master>
<username>cluster</username>
<password>cluster</password>
</slaveserver>
修改从服务器配置文件carte-config-8081.xml
<masters>
<slaveserver>
<name>master</name>
<hostname>master</hostname>
<port>8080</port>
<username>cluster</username>
<password>cluster</password>
<master>Y</master>
</slaveserver>
</masters>
<report_to_masters>Y</report_to_masters>
<slaveserver>
<name>slave1</name>
<hostname>node1</hostname>
<port>8081</port>
<username>cluster</username>
<password>cluster</password>
<master>N</master>
</slaveserver>
修改从配置文件carte-config-8082.xml
<masters>
<slaveserver>
<name>master</name>
<hostname>master</hostname>
<port>8080</port>
<username>cluster</username>
<password>cluster</password>
<master>Y</master>
</slaveserver>
</masters>
<report_to_masters>Y</report_to_masters>
<slaveserver>
<name>slave2</name>
<hostname>node2</hostname>
<port>8082</port>
<username>cluster</username>
<password>cluster</password>
<master>N</master>
</slaveserver>
分发整个kettle的安装目录,通过scp命令
分发/root/.kettle目录到node1、node2
启动相关进程,在master,node1,node2上分别执行
[root@master]# ./carte.sh master 8080
[root@node1]# ./carte.sh node1 8081
[root@node2]# ./carte.sh node2 8082
- 访问web页面
案例:读取hive中的emp表,根据id进行排序,并将结果输出到hdfs上
注意:因为涉及到hive和hbase的读写,需要修改相关配置文件。
修改解压目录下的data-integration\plugins\pentaho-big-data-plugin下的plugin.properties,设置active.hadoop.configuration=hdp26,并将如下配置文件拷贝到data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp26下
创建转换,编辑步骤,填好相关配置
直接使用trans1
创建子服务器,填写相关配置,跟集群上的配置相同
创建集群schema,选中上一步的几个服务器
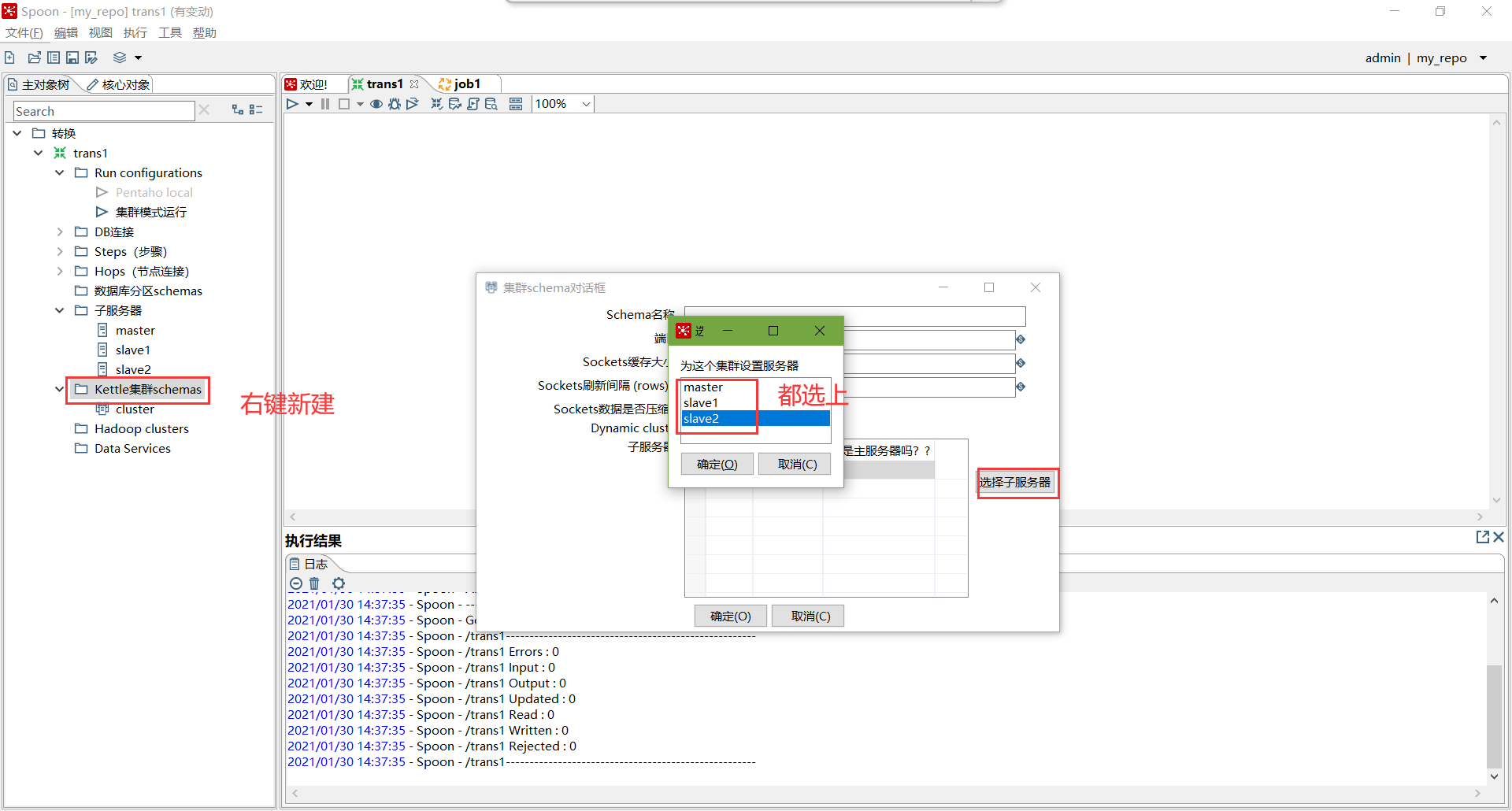
对于要在集群上执行的步骤,右键选择集群,选中上一步创建的集群schema
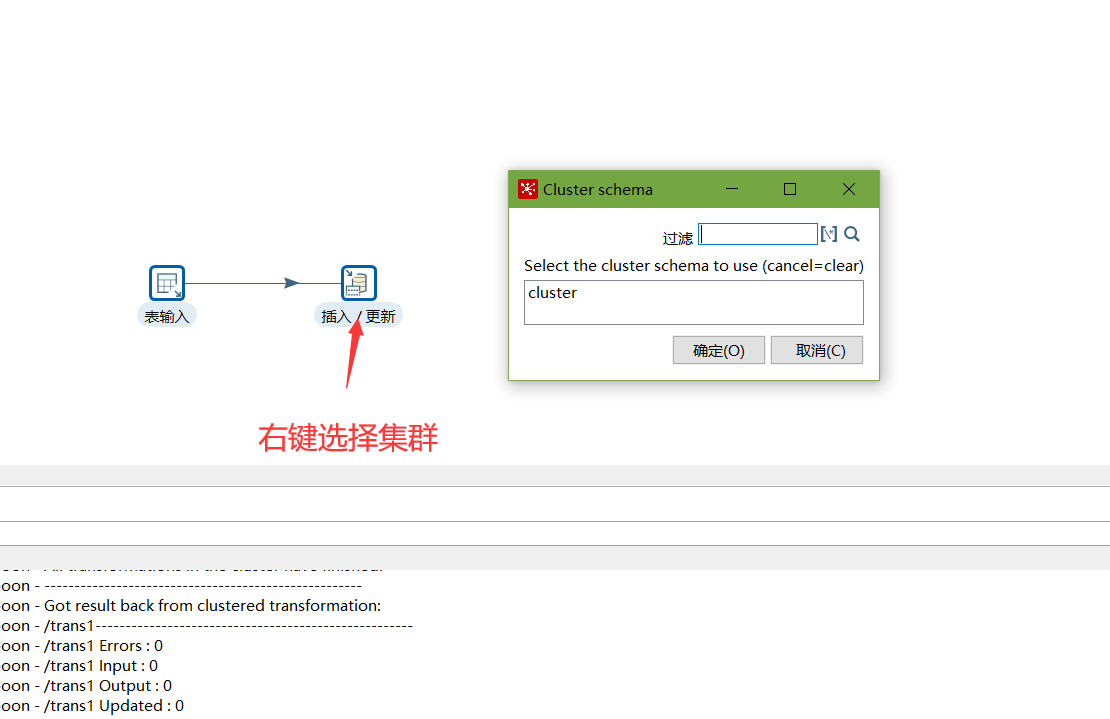
创建Run Configuration,选择集群模式
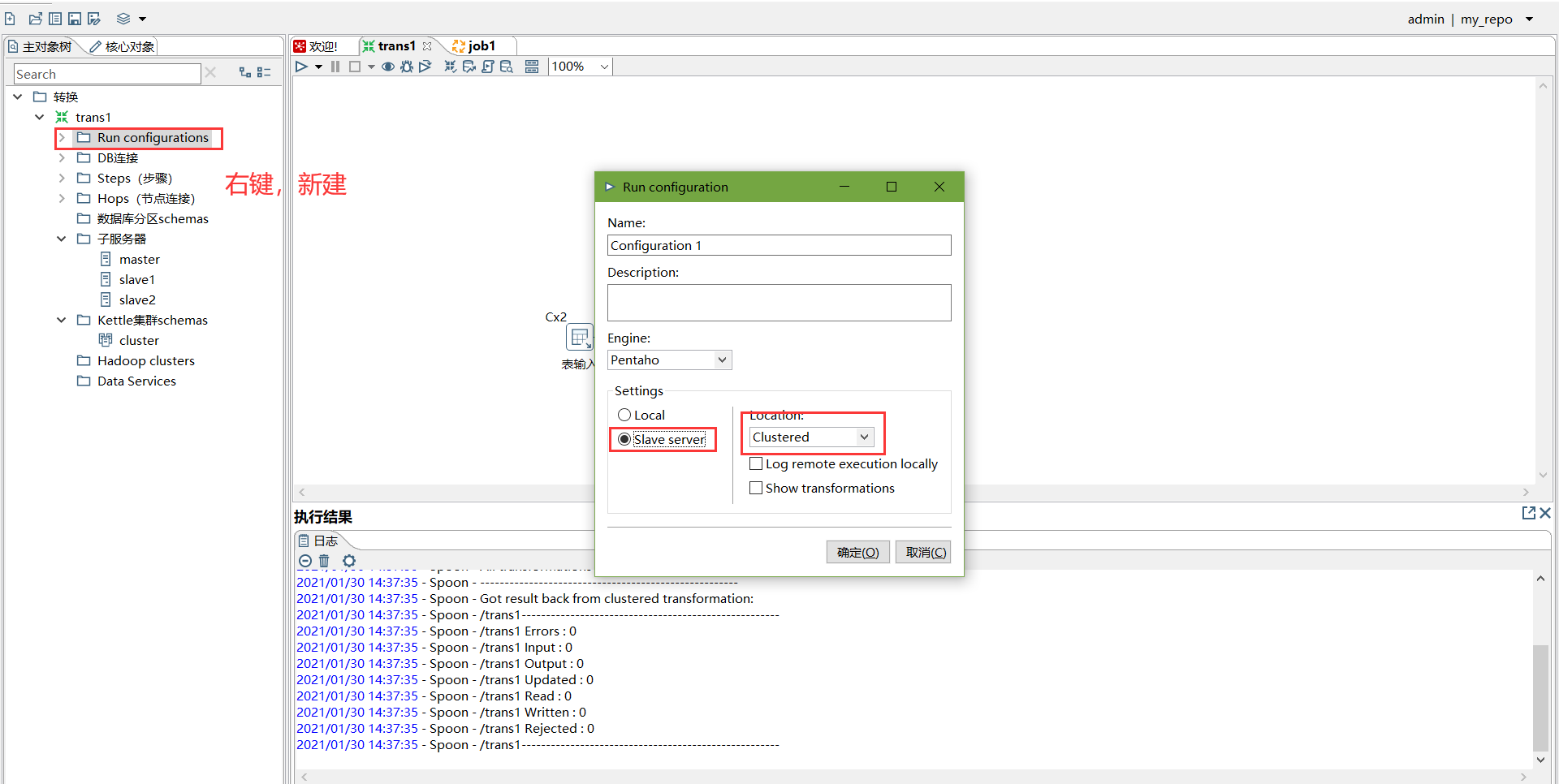
直接运行,选择集群模式运行
五、调优
1、调整JVM大小进行性能优化,修改Kettle根目录下的Spoon脚本。

参数参考:
-Xmx2048m:设置JVM最大可用内存为2048M。
-Xms1024m:设置JVM促使内存为1024m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmn2g:设置年轻代大小为2G。整个JVM内存大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
2、 调整提交(Commit)记录数大小进行优化,Kettle默认Commit数量为:1000,可以根据数据量大小来设置Commitsize:1000~50000
3、尽量使用数据库连接池;
4、尽量提高批处理的commit size;
5、尽量使用缓存,缓存尽量大一些(主要是文本文件和数据流);
6、Kettle是Java做的,尽量用大一点的内存参数启动Kettle;
7、可以使用sql来做的一些操作尽量用sql;
Group , merge , stream lookup,split field这些操作都是比较慢的,想办法避免他们.,能用sql就用sql;
8、插入大量数据的时候尽量把索引删掉;
9、尽量避免使用update , delete操作,尤其是update,如果可以把update变成先delete, 后insert;
10、能使用truncate table的时候,就不要使用deleteall row这种类似sql合理的分区,如果删除操作是基于某一个分区的,就不要使用delete row这种方式(不管是deletesql还是delete步骤),直接把分区drop掉,再重新创建;
11、尽量缩小输入的数据集的大小(增量更新也是为了这个目的);
12、尽量使用数据库原生的方式装载文本文件(Oracle的sqlloader, mysql的bulk loader步骤)。
kettle使用的更多相关文章
- 大量数据快速导出的解决方案-Kettle
1.开发背景 在web项目中,经常会需要查询数据导出excel,以前比较常见的就是用poi.使用poi的时候也有两种方式,一种就是直接将集合一次性导出为excel,还有一种是分批次追加的方式适合数据量 ...
- 数据仓库开发——Kettle使用示例
Kettle是一个开园ETL工具,做数据仓库用Spoon. 工具:下载Spoon,解压即可用 1.认识常用组件: 表输入 插入\更新 数据同步 文本文件输出 ...
- kettle中含有参数传递的定时任务
(1)新建一个作业(新建->作业),并在控制面板右键: (2)设置一个命令参数: (3)把作业的参数传递给转换: (4)在转换中右键设置转换属性: (5)接收作业中设置的传递参数: (6)参数的 ...
- kettle中全局变量的设置
设置全局变量. 找到.properties文件: 在文件中设置值: 在kettle中新建一个job(不用做任何设置): 转换中获取便元的设置: 重启kettle的执行结果:
- kettle中变量的设置和使用介绍
有没有能统一管理一个参数,然后让所有的transformation和job都可以读到呢? 答案是有 1.首先,打开.kettle\kettle.properties(个人主机是:C:\Users\fo ...
- kettle将Excel数据导入oracle
导读 Excel数据导入Oracle数据库的方法: 1.使用PL SQL 工具附带的功能,效率比较低 可参考这篇文章的介绍:http://www.2cto.com/database/201212/17 ...
- kettle转换和作业插件开发及调试
这是一篇几年前写下的文档,最近打算根据这篇文档重写一下kettle插件的教程.结果各种理由,一推再推.今天索性将这篇文档发布出来,分享给大家,例子等有空再补上.这是一篇基于kettle3.2基础上完成 ...
- kettle系列-[KettleUtil]kettle插件,类似kettle的自定义java类控件
该kettle插件功能类似kettle现有的定义java类插件,自定java类插件主要是支持在kettle中直接编写java代码实现自定特殊功能,而本控件主要是将自定义代码转移到jar包,就是说自定义 ...
- kettle系列-kettle管理平台部署说明
本介绍我的开源项目[kettle-manager]kettle管理平台如何获取并部署使用,该项目介绍请参看另一篇博文:http://www.cnblogs.com/majinju/p/5739820. ...
- kettle系列-我的开源kettle管理平台[kettle-manager]介绍
kettle管理工具 专门为kettle这款优秀的ETL工具开发的web端管理工具. 项目简介 kettle作为非常优秀的开源ETL工具得到了非常广泛的使用,一般的使用的都是使用客户端操作管理,但问题 ...
随机推荐
- Appium问题解决方案(7)- Could not find 'adb.exe' in PATH. Please set the ANDROID_HOME environment variable with the Android SDK root directory path
背景:运行代码提示找不到ADB An unknown server-side error occurred while processing the command. Original error: ...
- Linux常用命令 - rm命令详解
21篇测试必备的Linux常用命令,每天敲一篇,每次敲三遍,每月一循环,全都可记住!! https://www.cnblogs.com/poloyy/category/1672457.html 删除/ ...
- LeetCode刷题模板(1):《我要打10个》之二分法
Author : 叨陪鲤 Email : vip_13031075266@163.com Date : 2021.01.23 Copyright : 未 ...
- Vue设置全局js/css样式
''' 配置全局js mian.js: import settings from '@/assets/js/settings' Vue.prototype.$settings = settings; ...
- 使用Redis Stream来做消息队列和在Asp.Net Core中的实现
写在前面 我一直以来使用redis的时候,很多低烈度需求(并发要求不是很高)需要用到消息队列的时候,在项目本身已经使用了Redis的情况下都想直接用Redis来做消息队列,而不想引入新的服务,kafk ...
- 编译执行 VS 解释执行
一般编译程序从对源程序执行途径的角度不同,可分为解释执行和编译执行. 所谓解释执行是借助于解释程序完成,即按源程序语句运行时的动态结构,直接逐句地边分析边翻译并执行.像自然语言翻译中的口译,随时进行翻 ...
- docker学习笔记(二)--配置镜像加速器
前提:docker已经安装好 配置过程 进入至阿里云开发中心,https://dev.aliyun.com/,点击管理中心 管理中心中,点击左侧镜像加速器. 修改配置文件,使用加速器,根据我们目前Do ...
- HCNP Routing&Switching之IS-IS路由渗透和开销
前文我们了解了IS-IS邻居建立过程.LSDB同步.拓扑计算和路由的形成:回顾请参考https://www.cnblogs.com/qiuhom-1874/p/15265698.html:今天我们来聊 ...
- 【简单数据结构】并查集--洛谷 P1111
题目背景 AA地区在地震过后,连接所有村庄的公路都造成了损坏而无法通车.政府派人修复这些公路. 题目描述 给出A地区的村庄数NN,和公路数MM,公路是双向的.并告诉你每条公路的连着哪两个村庄,并告诉你 ...
- 学习PHP中的任意精度扩展函数
今天来学习的是关于数学方面的第一个扩展.对于数学操作来说,无非就是那些各种各样的数学运算,当然,整个程序软件的开发过程中,数学运算也是最基础最根本的东西之一.不管你是学得什么专业,到最后基本上都会要学 ...