Jaeger的客户端采样配置(Java版)
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
关于采样(Sampling)
采样很好理解:使用Jaeger时,未必需要将所有请求都上报到Jaeger,有时候只要抽取其中一部分观察即可,这就是按照一定策略进行采样;
Jaeger SDK是支持多种采样配置的,在分布式系统中,他们遵循的原则是前置判定(consistent upfront 或者head-based),简单来说,假如consumer服务调用provider服务,那么某一次请求只要consumer决定不采样,那么provider在处理这个请求的时候也不会采样,也就是说对于一次完整的trace,只要最前面的服务不上报到jaeger,那么整个trace后面涉及的服务都不会上报到jaeger
Jaeger采样配置分为客户端和服务端两种配置,默认用的是服务端配置
本文咱们来了解如何在客户端(也就是接入Jaeger的应用)配置采样,并且动手验证效果,常用的客户端采样策略有以下三种:
- 固定:要么全部采样,要门全部不采样
- 比例:按照指定比例采样
- 限速:固定时间周期内采样固定数量,例如每秒一个
- 接下来,逐个配置和体验这三种采样的效果
关于实战用的工程
- 采样配置实战不涉及编码,只需要改一些配置,所以没必要大张旗鼓的新建工程写代码,用《Jaeger开发入门(java版)》一文中的两个maven子工程即可:服务提供方jaeger-service-provider和服务调用方jaeger-service-consumer,都做成docker镜像,用docker-compose启动,网络架构如下图:

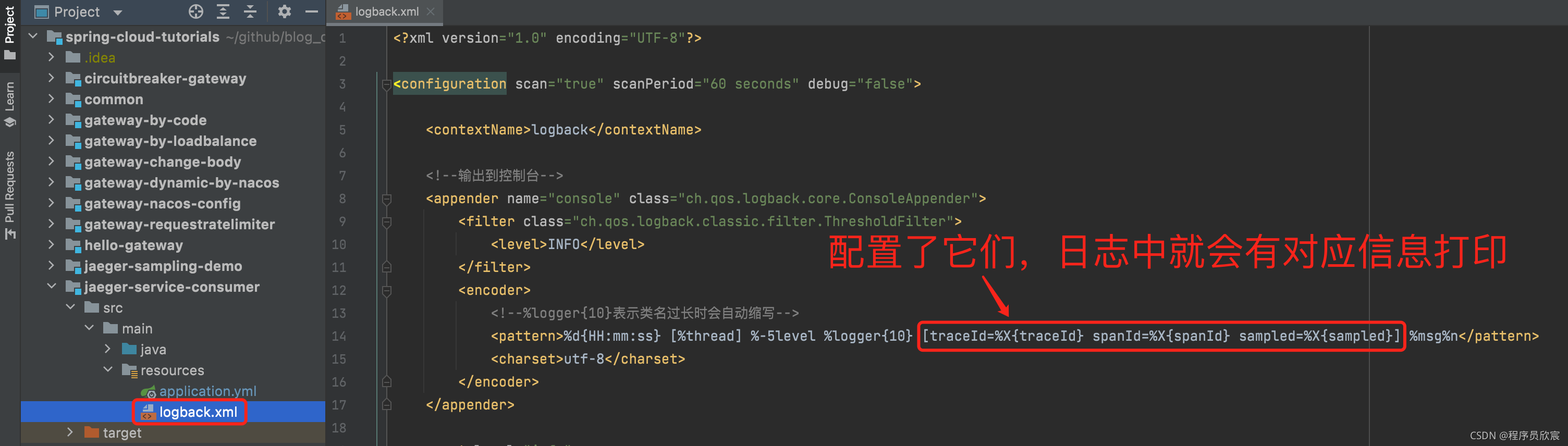
- 请确保项目的日志模板中已添加了traceId、spanId、sampled等变量,如下图红框所示,有了这些配置,咱们在日志中就能看到对应的trace是否被采样(这一步非常重要):
- 为了方便修改代码后重新部署启动,我写了个名为full.sh的shell脚本文件,运行即可将修改后的代码制作成最新的镜像并用docker-compose运行起来:
#!/bin/bash
echo "停止docker-compose"
cd jaeger-service-provider && docker-compose down && cd ..
echo "编译构建"
mvn clean package -U -DskipTests
echo “创建provider镜像”
cd jaeger-service-provider && docker build -t bolingcavalry/jaeger-service-provider:0.0.1 . && cd ..
echo “创建consumer镜像”
cd jaeger-service-consumer && docker build -t bolingcavalry/jaeger-service-consumer:0.0.1 . && cd ..
echo "清理无效资源"
docker system prune --volumes -f
echo "启动docker-compose"
cd jaeger-service-provider && docker-compose up -d && cd ..
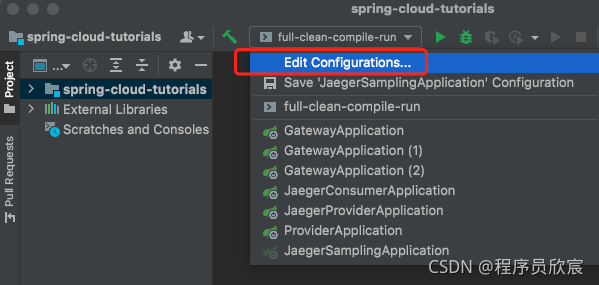
- 如果您用的是IDEA,在下图红框位置添加一个自定义命令,选中上述shell文件,就可以在IDEA中用run命令来编译构建部署了:
- 现在准备工作已经完成,开始实战吧,从最简单的固定采样开始;
固定采样
固定采样的逻辑很简单:要么全部上报,要么一个也不报
固定采样的配置方式如下图红框所示:
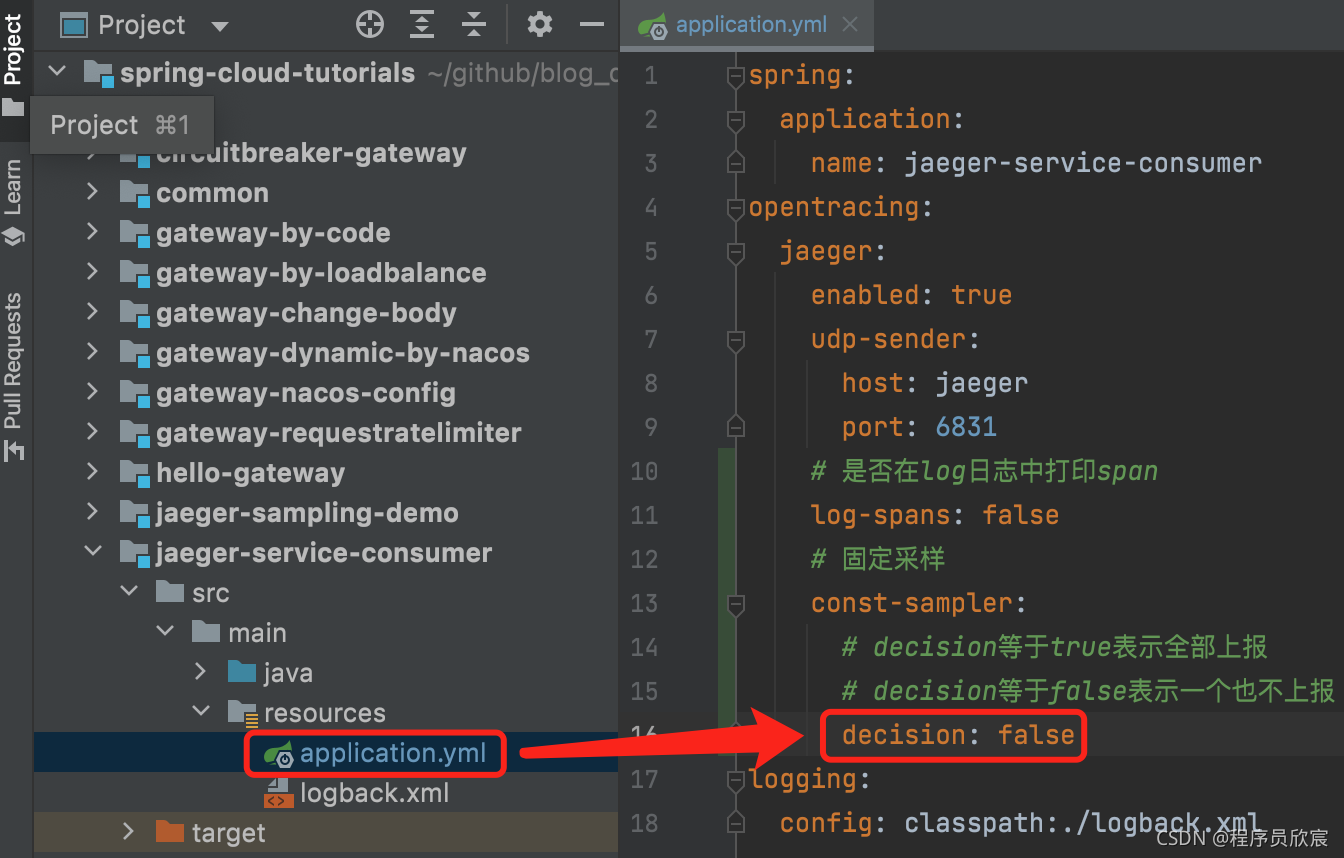
要注意的是:根据前置判定(consistent upfront 或者head-based)原则,只要将上述配置写入jaeger-service-consumer项目的配置文件即可,至于jaeger-service-provider维持原状不做任何改动
执行前面写的full.sh脚本,编译构建部署
浏览器访问http://localhost:18080/hello,产生一些web请求,多访问几次
看jaeger-service-consumer容器的日志,如下图,红框中的sampled=false表示未采样,三此请求的日志都是如此:

- 再看jaeger-service-provider容器的日志,如下图红框,也全部都没有采样,这证明Jaeger的前置判定原则(consistent upfront 或者head-based)是准确的,jaeger-service-consumer是一次trace的源头,被它关闭了采样的trace,在后续的服务中也会自动关闭采样:

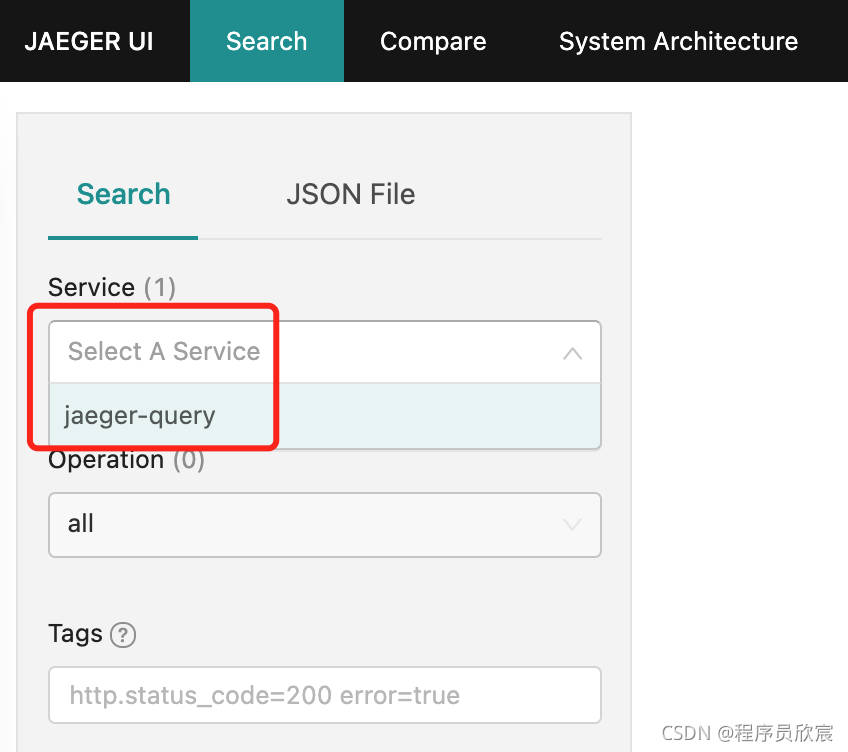
- 去Jaeger的web页面看看,空空如也,连服务列表中都没有jaeger-service-consumer和jaeger-service-provider:
- 试过了全部不采样,再来试试全部采样的配置,如下图红框:
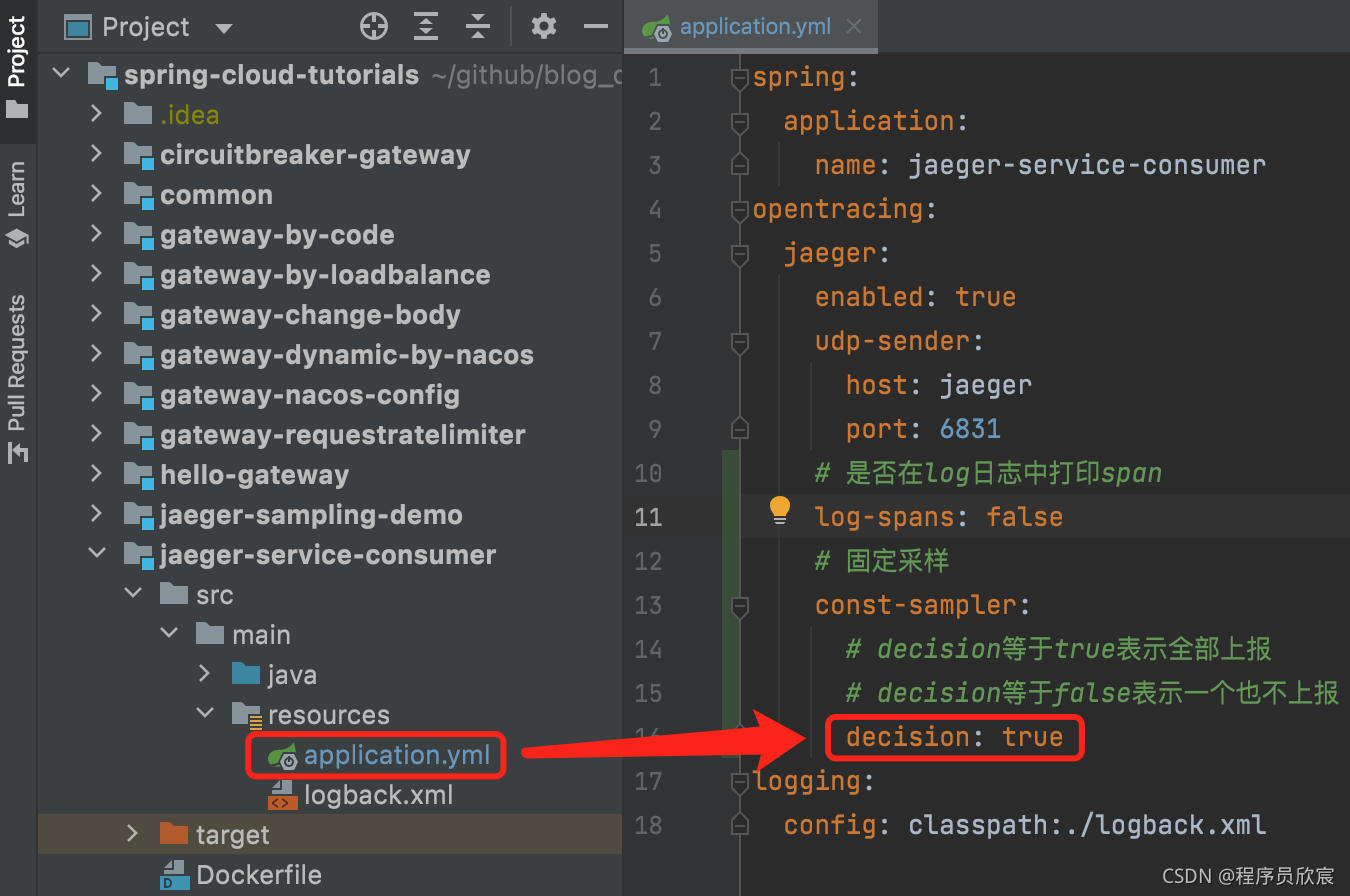
- 重新部署,再产生几次请求,去看jaeger-service-consumer容器的日志,如下图红框,全部都被采样了:

- 去看jaeger-service-provider容器的日志,也是如此,所有trace都被采样:

- 打开Jaeger的web页面,可见jaeger-service-consumer的三次请求对应的trace全部上报:
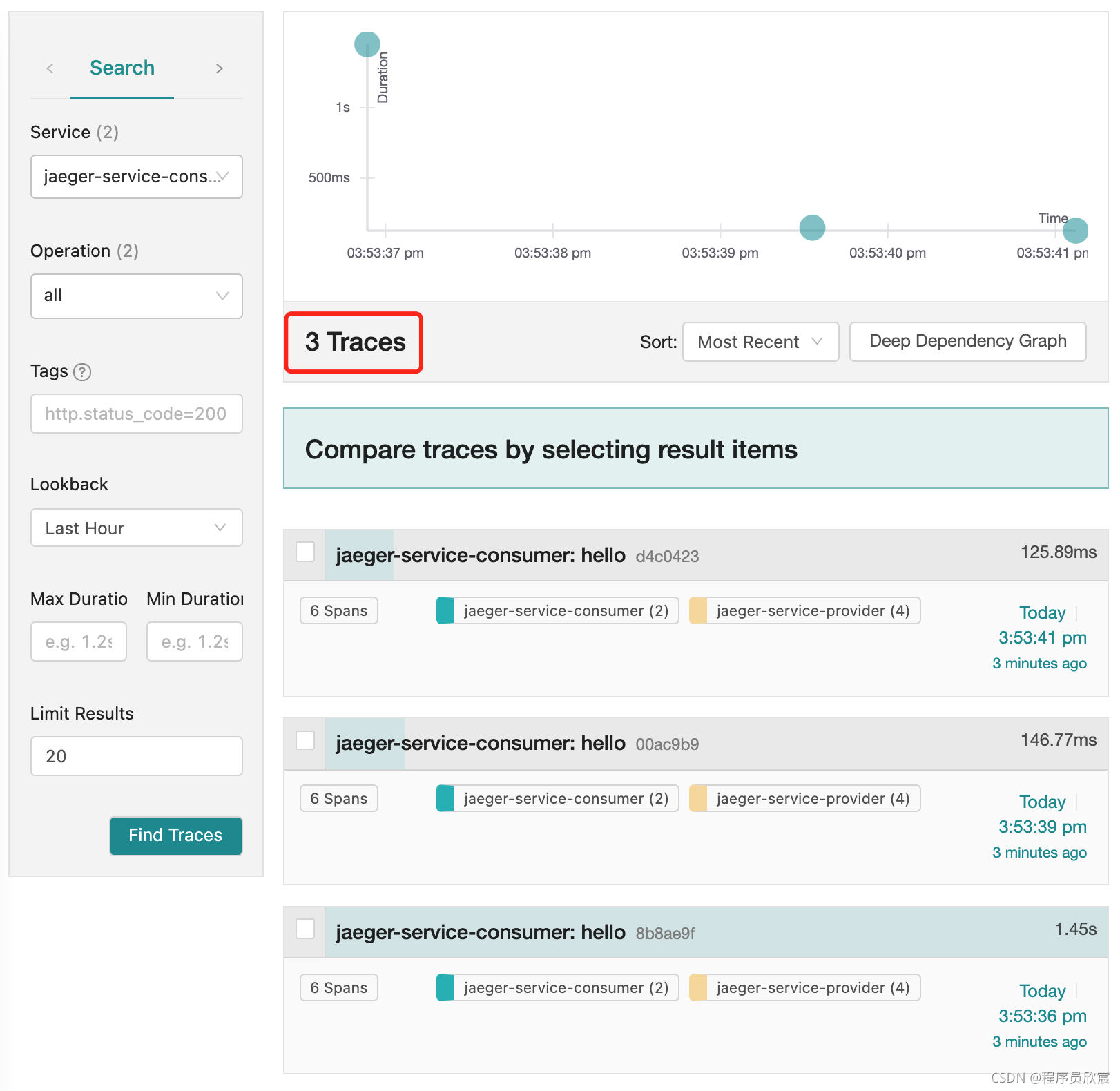
- 至此,最简单的固定采样已完成,来看看更实用的比例采样
比例采样
- 顾名思义,就是按照一定的百分比采样,配置如下图所示:
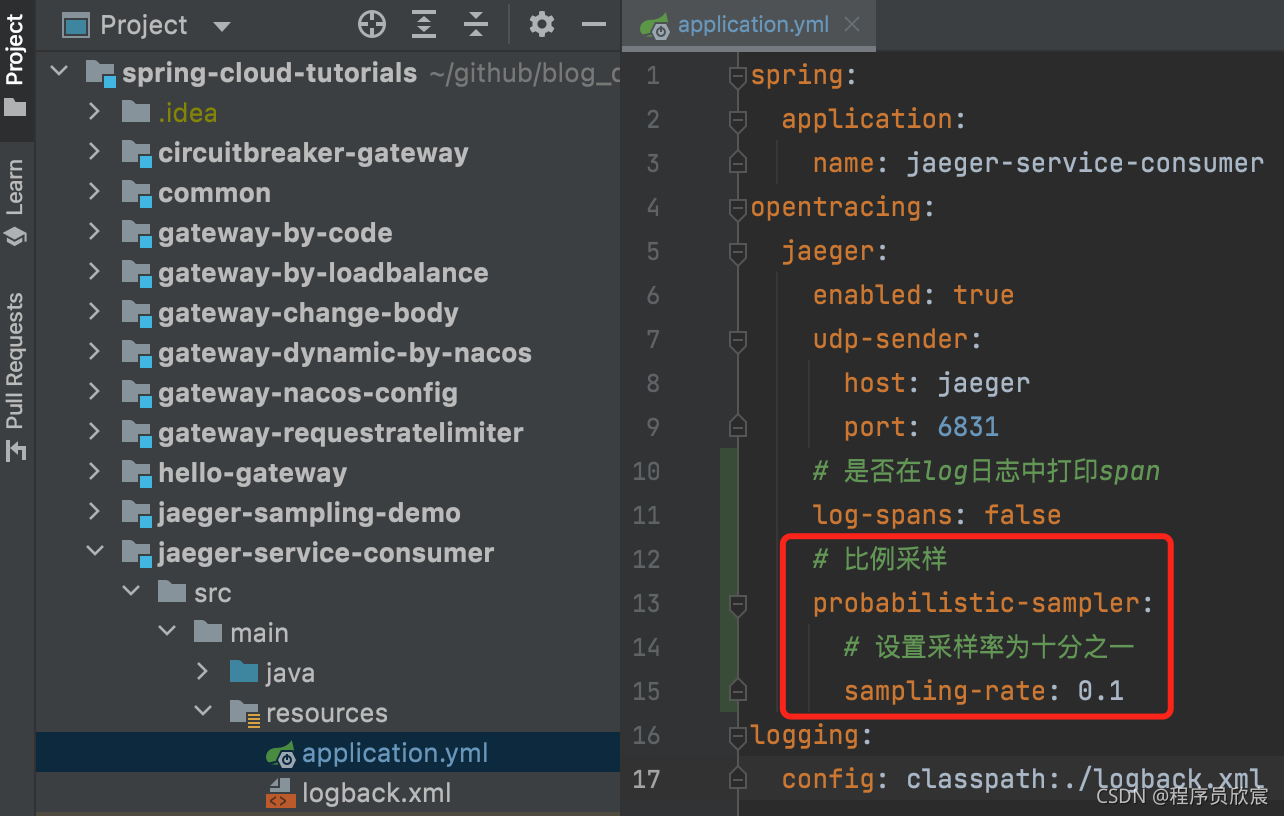
执行前面写的full.sh脚本,编译构建部署
测试比例采样的方法就是发多个请求,检查采样的trace是否是总数的十分之一,我这里用jmeter来执行多次请求,您可以选择自己擅长的工具,或者写代码写脚本,甚至手动访问多次
使用jmeter可以控制请求次数,用的是Loop Controller,如下图红框所示:
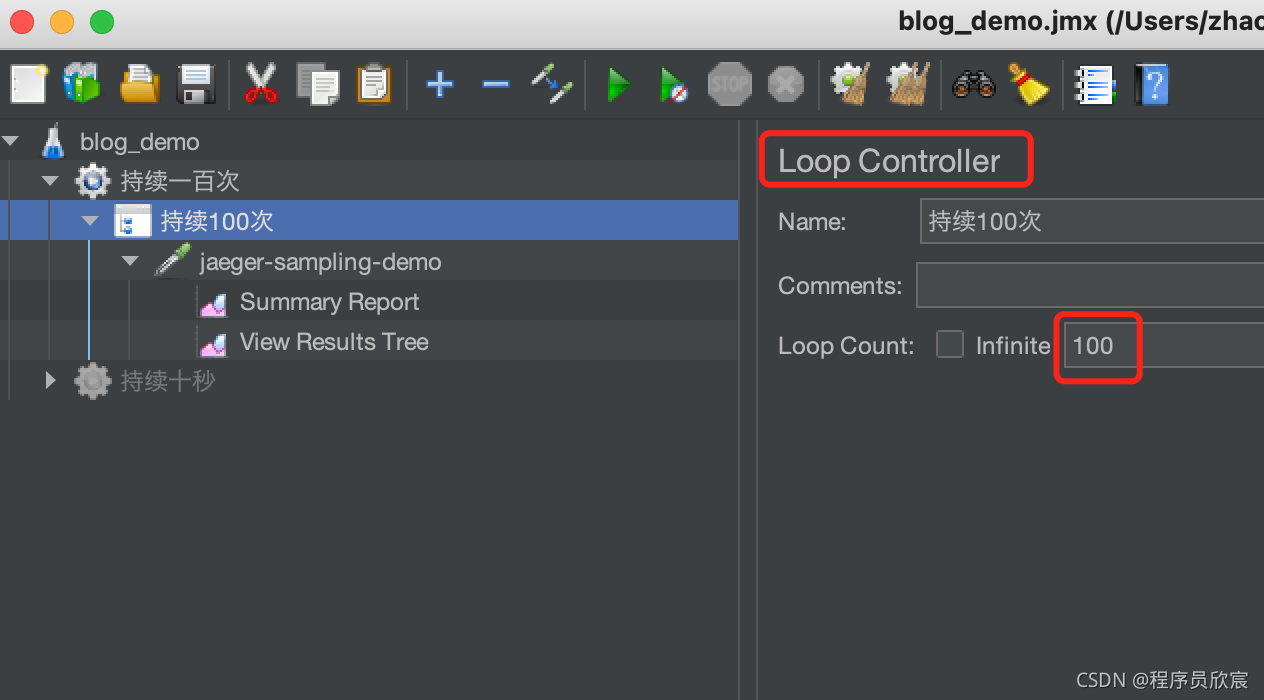
- 向jaeger-service-consumer的/hello接口发送完一百次请求后,可以从docker容器日志中检查采样情况,这里使用grep和wc命令的组合来统计日志中出现sampled=true和sampled=false的行数,完整的命令如下:
docker logs jaeger-service-consumer| grep 'sampled=true'|wc -l
- 100个请求,采样率百分之十,但是用上述命令得到的结果并不是精确值10,而是8,再统计未采样的日志行数(把true改成false),得到的结果是92,总数对得上,但是采样数并非精确的百分之十,如下图:

- 然后将请求总数增加到一千条,得到的采样比例接近百分之十,如下:

- 打开Jaeger的web页面,可见果然只有106个trace:
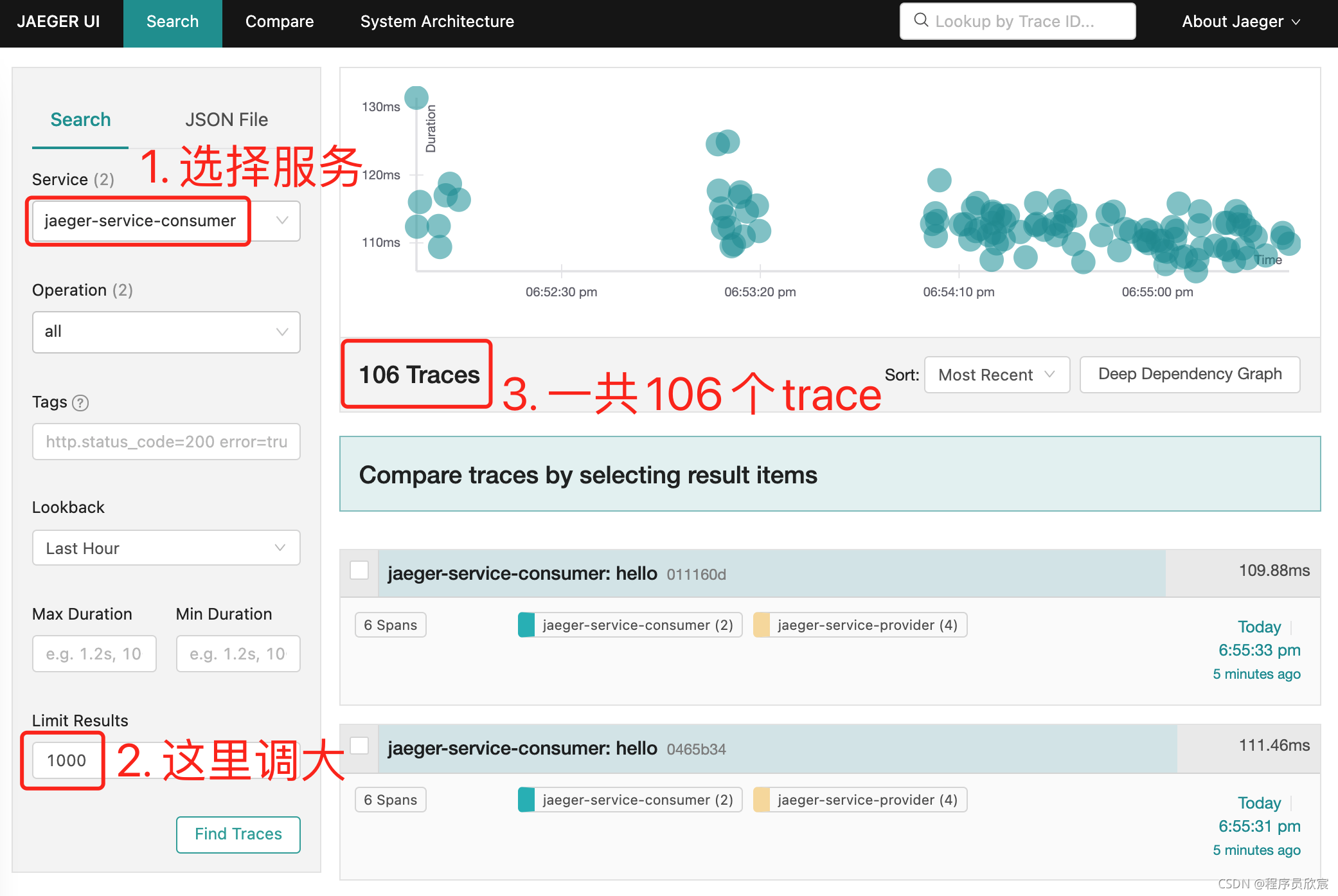
- 比例采样完成了,接下来是限速采样
限速采样
- 关于限速,似乎不够具体不便于理解,但是看看官方文档上的关键字leaky bucket,如下图红框,聪明的您一定想到了其中的关键,漏桶限流算法(注意,是漏桶,不是令牌桶,漏桶算法的峰值和桶大小有关):

- 配置如下图红框所示:
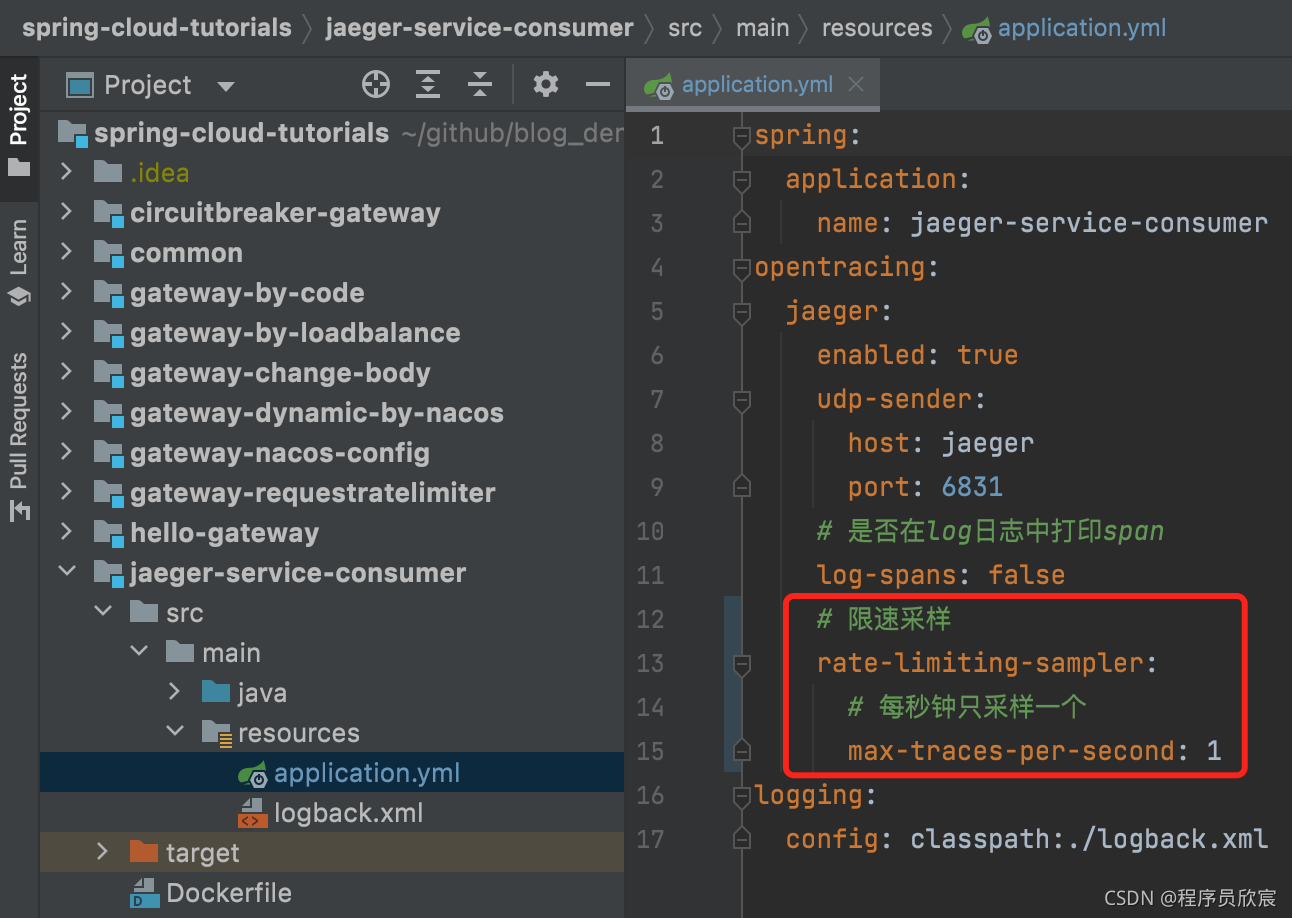
执行前面写的full.sh脚本,编译构建部署
咱们的配置是每秒钟一次采样,所以验证的时候要控制好发送请求的时长,我这里还是用jmeter来发请求的,如下图红框所示,jmeter有种Runtime Controller类型的控制器,可以控制持续请求的时长,我这里设置为10秒:
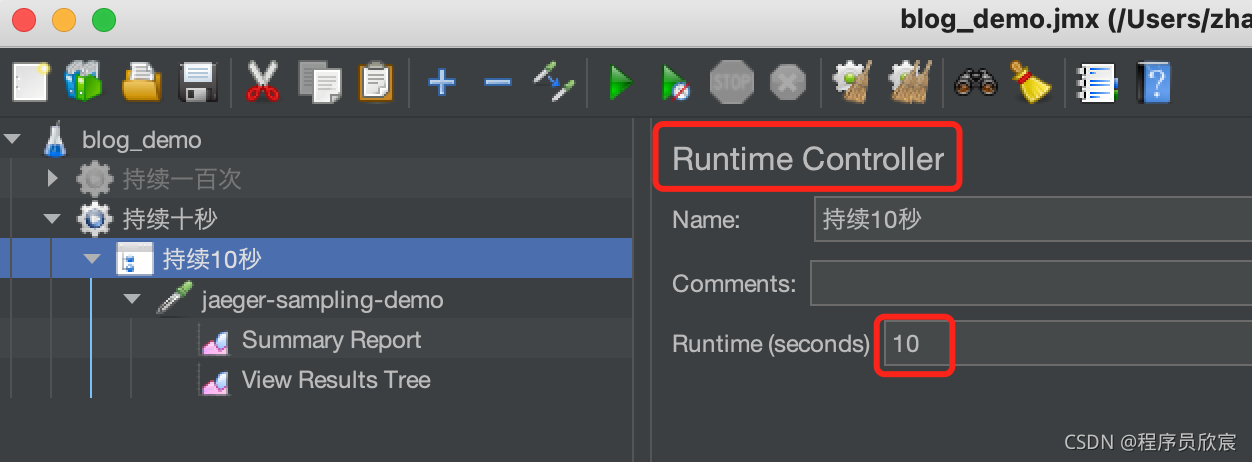
- 用jmeter持续发送10秒的请求,从jmeter的汇总报告中可见一共发了70个请求:
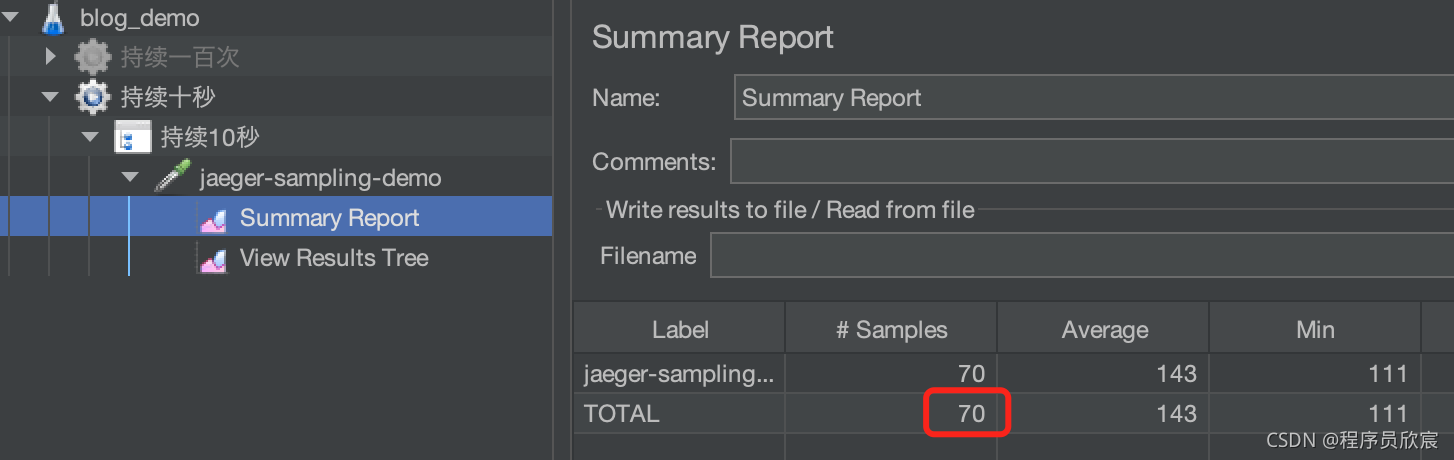
- 用命令docker logs jaeger-service-consumer| grep 'sampled=true'|wc -l查看采样总数,10秒的预期是10个,结果如下,并不精确,只是接近而已:

- 清掉所有数据,将时长改成100秒试试,一共发出次852请求:
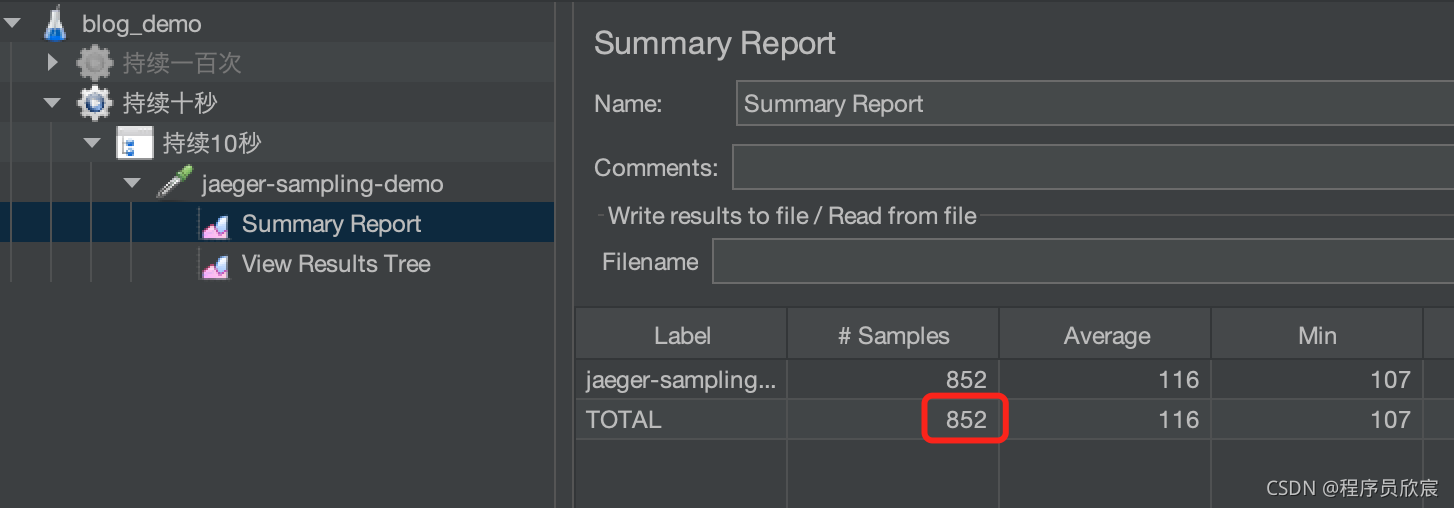
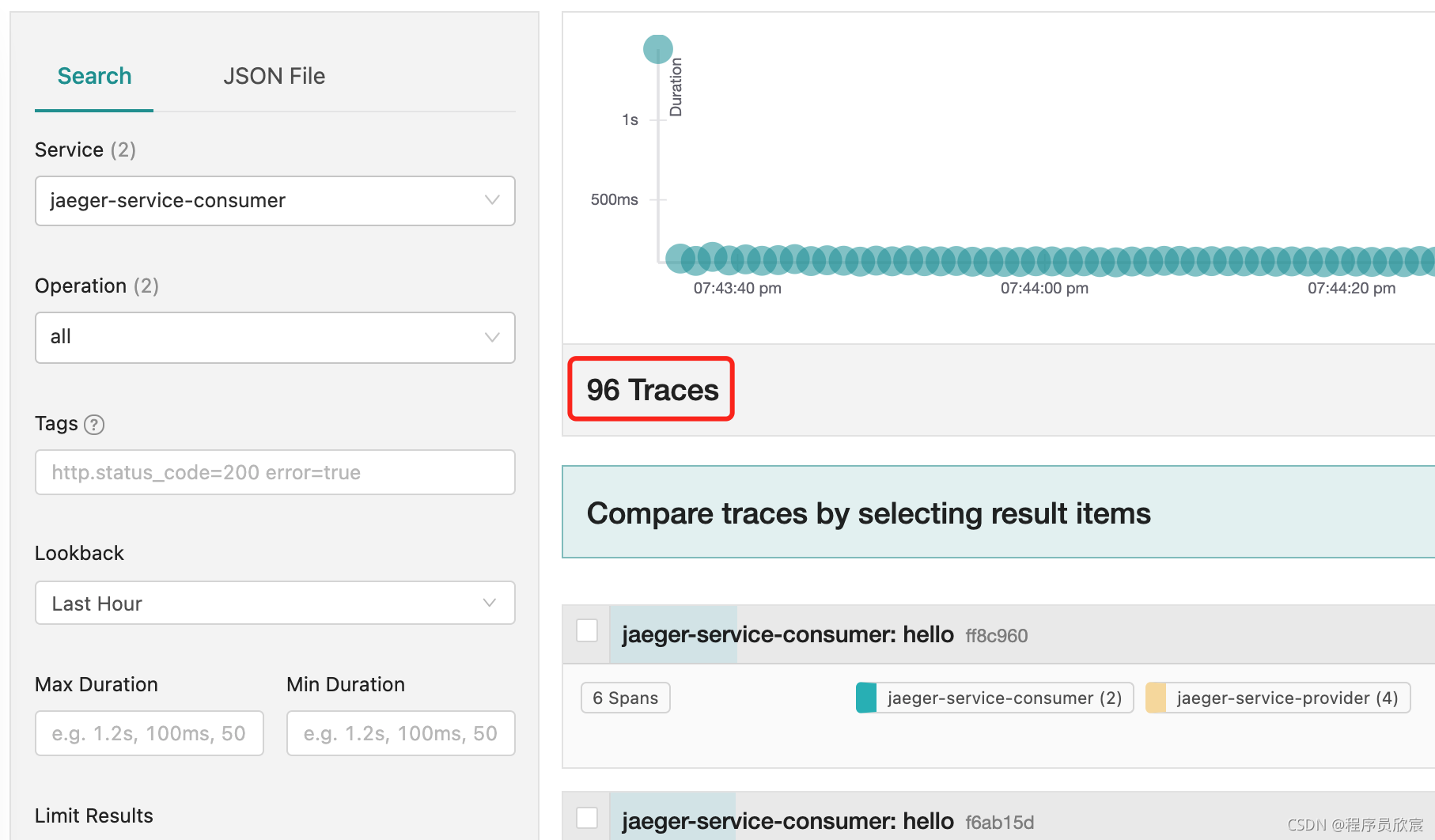
- 采样总数为96,接近预期:

- 打开Jaeger的web页面也是96次trace:
服务端配置一瞥
还记得《分布式调用链跟踪工具Jaeger?两分钟极速体验》、《Jaeger开发入门(java版)》等文章中的操作吗?那时咱们并没有添加任何与采样有关的配置,但是每次请求都能在Jaeger的web页面上查到对应的trace,也就是说所有请求全部被采样了,这是为啥?
如果配置文件中没有采样相关的内容,那么默认使用的就是远程配置,具体的信息就在jaeger的all-in-one容器中,执行下面这个命令,就能看到远程采样配置:
docker exec jaeger cat /etc/jaeger/sampling_strategies.json
- 上述命令可以看到sampling_strategies.json的内容如下,原来服务端的配置是比例采样,不过比例是百分之百,这就能解释为何所有请求都能在Jaeger的web页面查到trace信息了:
{
"default_strategy": {
"type": "probabilistic",
"param": 1
}
}
- 至此,采样配置实战已经完成,希望能给您提供一些参考,辅助您针对实际情况定制更加合适的采样策略
你不孤单,欣宸原创一路相伴
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
Jaeger的客户端采样配置(Java版)的更多相关文章
- java版gRPC实战之四:客户端流
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- java版gRPC实战之六:客户端动态获取服务端地址
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- ArcGIS Server 10 Java 版的Rest服务手动配置方法
Java版的Manager中发布的服务默认只发布了该服务的SOAP接口,而REST接口需要用户在信息服务器,如Tomcat. Apache.WebLogic等中手工配置.由于在Java版的Server ...
- 应用程序初次运行数据库配置小程序(Java版)
应用程序初始化数据库配置小程序 之前写过一个Java版的信息管理系统,但部署系统的时候还需要手动的去配置数据库和导入一些初始化的数据才能让系统运行起来,所以我在想是不是可以写一个小程序在系统初次运行的 ...
- APP自动化框架-ATX原理解析及JAVA版客户端
作为网易开源的ATX APP自动化测试框架,对比现有的macaca自动化框架/Appium自动化框架,最大的特别就是在于可远程进行自动化测试 先给大家看一张我自己梳理的框架架构图 框架巧妙点: 1. ...
- java版ftp简易客户端(可以获取文件的名称及文件大小)
java版ftp简易客户端(可以获取文件的名称及文件大小) package com.ccb.ftp; import java.io.IOException; import java.net.Socke ...
- Java版Kafka使用及配置解释
Java版Kafka使用及配置解释 一.Java示例 kafka是吞吐量巨大的一个消息系统,它是用scala写的,和普通的消息的生产消费还有所不同,写了个demo程序供大家参考.kafka的安装请参考 ...
- Jaeger开发入门(java版)
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Tomcat学习笔记 - 错误日志 - Tomcat安装版安装后第二次启动后闪退(转)-- javac不是内部或外部命令 -- 配置java环境教程
如果安装成功并且安装完成第一次启动是成功的,第二次就闪退的话,原因之一是没有配置java的环境.在网上找的配制方法有很多错误,测试javac命令时候会提示不是内部或外部命令,找到一个正确的教程.如下, ...
随机推荐
- 随笔:关于.net core单文件AOT编译
.Net Core单文件发布已经很流畅了(vs已支持图形化操作发布). 但类似Go或者Graalvm JDK的完全事前编译为本地机器码的红能功能,还未发布于.net 6特性中,还处于实验室中. 另外, ...
- 浅谈Java和JavaScript中变量和数据类型的区别
对于一门编程语言的学习,如果第一步是安装环境,那么第二步一定是学习这门语言的基本规则,变量和数据类型则首当其冲 JavaScipt作为一个蹭Java热度而命名的语言,在很多方面和Java也有一定的相似 ...
- NOIP2020 自爆记
Day -4 - 2459184 本学期第 14 周终于到来了,NOIP 只剩 5 周了. djq 进国集了,先以膜为敬. 晚上上 hb,hb 让我们记了几点要求: 认真读题,要一字一句读题,包括输入 ...
- Codeforces 1446D2 - Frequency Problem (Hard Version)(根分)
Codeforces 题面传送门 & 洛谷题面传送门 人菜结论题做不动/kk 首先考虑此题一个非常关键的结论:我们设整个数列的众数为 \(G\),那么在最优子段中,\(G\) 一定是该子段的众 ...
- Codeforces 1089I - Interval-Free Permutations(析合树计数)
Codeforces 题面传送门 & 洛谷题面传送门 首先题目中涉及排列的 interval,因此可以想到析合树.由于本蒟蒻太菜了以至于没有听过这种神仙黑科技,因此简单介绍一下这种数据结构:我 ...
- canvas 基本介绍
# canvas 基本功能介绍 - canvas 能做什么 1. 绘制简单图形线条 2. 裁剪图片 - 开始绘制画布 新建html文档添加 canvas标签 ```html <div style ...
- Bedtools如何比较两个参考基因组注释版本的基因?
目录 问题 思路 问题 原问题来自:How to calculate overlapping genes between two genome annotation versions? 其实可分为两个 ...
- 50. Plus One-Leetcode
Plus One My Submissions QuestionEditorial Solution Total Accepted: 98403 Total Submissions: 292594 D ...
- goto 的用法
#include <stdio.h> int main() { printf("go to cpy \n"); goto FLASH_CPY; printf(" ...
- java类加载、对象创建过程
类加载过程: 1, JVM会先去方法区中找有没有相应类的.class存在.如果有,就直接使用:如果没有,则把相关类的.class加载到方法区 2, 在.class加载到方法区时,会分为两部分加载:先加 ...