Day06:迭代器,生成器,生成表达式,面向过程编程,包及常用模块
今日内容:
1.迭代器(****)
2.生成器(***)
3.生成器表达式(*****)
4.面向过程编程(*****)
5.包的使用(***)
6.常用模块
logging (*****)
re (*****)
一.迭代器
迭代器就是迭代取值的工具
迭代是一个重复的过程,但是每一次重复都是基于上一次的结果而进行的
2.为何要用迭代器
针对没有索引的数据类型,如:字典,集合,文件,要想迭代取出其中包含的一个个的值
python解释器必须提供一种能够不依赖于索引的迭代取值工具
3.如何用迭代器
x=1
y=1.3
#以下都是可迭代对象
str1='hello'
list1=['a','b','c']
t1=('a','b','c')
dic={'x':1,'y':2}
set1={'m','n'}
f=open('a.txt',mode='rt',encoding='utf-8')
#对于可迭代对象来说,调用可迭代对象.__iter__()方法,得到的就是其迭代器对象
1.内置有__iter__方法,调用迭代器对象__iter__方法得到的仍然是迭代器本身
ps:文件对象本身就是一个迭代器对象,即同时也内置有__next__方法
2.内置有__next__方法
迭代器优点:
1.提供一种能够不依赖索引的、通用的迭代取值方式
补充:for循环可以称之为迭代器循环
for item in list1:
print(item)
a.调用in后面那个对象的__iter__方法,拿到一个迭代器对象
b.调用迭代器对象的__next__方法,拿到一个返回值赋值给变量item
c.循环往复,直到抛出异常,for循环会自动捕捉异常结束循环
1.针对同一个迭代器对象只能取完一次,不如按照索引或key取值方式灵活
2.无法预测迭代器对象所包含值的个数
l=['alex','andy','lily']
count=0
while count<len(l):
print(l[count])
count+=1
输出:
alex
andy
lily
#对于可迭代对象来说,调用可迭代对象.__iter__()方法,得到的就是其迭代器对象
dic={'x':1,'y':2}
iter_dic=dic.__iter__() #iter_dic=iter(dic) 作用相同
print(iter_dic)
k1=iter_dic.__next__() #k1=next(iter_dic) 作用相同
print(k1,type(k1))
k2=iter_dic.__next__() #k2=next(iter_dic) 作用相同
print(k2,type(k2))
try:
next(iter_dic)
except StopIteration:
print('==========>')
输出:
<dict_keyiterator object at 0x0000021B9D9370E8>
x <class 'str'>
y <class 'str'>
==========>
dic={'x':1,'y':2}
iter_dic=iter(dic)
while True:
try:
k=next(iter_dic)
print(k)
except StopIteration:
break
输出:
x
y
list1=['a','b','c']
iter_list=iter(list1)
while True:
try:
k=next(iter_list)
print(k)
except StopIteration:
break
输出:
a
b
c
二.生成器
1.什么是生成器
在函数内但凡出现yield关键字,再调用函数就不会触发函数体代码的执行了
会得到一个返回值,该返回就是一个生成器对象
而生成器本身就是一个迭代器
2.为何要用生成器
生成器是自定义的迭代器
3.如何用生成器
1.提供一种自定义迭代器的方式
2.可以用于返回值
yield与return区别
相同点:都可以用于返回值,个数以及类型都没有限制
不同点:yield可以返回多次值,return只能返回一次值
3.函数暂停及继续执行的状态是由yield保存的
def foo():
print ('first')
yield 1
print ('second')
yield 2
print ('third')
yield 3
print ('fourth')
g=foo() #g是生成器=》就是迭代器
print (g.__next__()) #会触发g对应函数的函数体代码执行,直到碰到一个yield就暂停住,就该yield后的值当作本地__next__()的返回值
print (g.__next__())
print (g.__next__())
输出:
first
1
second
2
third
3
def my_range(start,stop,step=1):
while start < stop:
yield start
start+=step
for i in my_range(1,10,2):
print (i)
输出:
1
3
5
7
9
#yield关键字表达式形式的应用
#x=yield
def dog(name):
print('dog[%s]准备开吃' %name)
while True:
food=yield
print('dog[%s]吃了:%s' %(name,food))
dg1=dog('haha')
#强调:针对表达式形式的yield,在使用生成器时必先send(None),相当于先完成一个初始化操作
next(dg1)
#send有两个功能
#1.为当前暂停位置的yield赋值
#2.与next的效果一样,不传值默认传None
res=dg1.send('骨头')
print(res)
输出:
dog[haha]准备开吃
dog[haha]吃了:骨头
None
def dog(name):
print('dog[%s]准备开吃' %name)
food_list=[]
while True:
food=yield food_list
food_list.append(food)
print('dog[%s]吃了:%s' %(name,food))
dg1=dog('haha')
#强调:针对表达式形式的yield,在使用生成器时必先send(None),相当于先完成一个初始化操作
next(dg1)
#send有两个功能
#1.为当前暂停位置的yield赋值
#2.与next的效果一样,不传值默认传None
res=dg1.send('骨头')
print(res)
res=dg1.send('馒头')
print(res)
输出:
dog[haha]准备开吃
dog[haha]吃了:骨头
['骨头']
dog[haha]吃了:馒头
['骨头', '馒头']
查询/etc 下所有文中含‘python’的文件,迭代查询
grep -rl 'python' /etc
三.生成器表达式
#生成器表达式
l=[i**2 for i in range(1,11)]
print (l) names=['alex','andy','tom']
#l=[name.upper() for name in names if name != 'andy']
l=(name.upper() for name in names if name != 'andy')
#print(l)
print(next(l))
输出:
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
ALEX
四.面向过程编程
1.核心是过程二字,过程指的是解决问题的步骤,即先干什么再干什么
基于该思想编程写程序就好比在设计一条流水线,是一种机械式的思维方式
优点:复杂的问题流程化,进而简单化
缺点:牵一发而动全身,扩展性差
def communicate():
name=input('username>>').strip()
pwd=input('password>>').strip()
return (name,pwd)
def auth(name,pwd):
if name =='andy' and pwd =='':
return True
else:
return False
def index(res):
if res:
print('welcome')
else:
print('login fail')
def main():
user,pwd=communicate()
res=auth(user,pwd)
index(res)
五.包的使用
1.什么是包
包本质就是一个包含有__init__.py文件夹,文件夹是用来组织文件
强调,包以及包下所有的文件都是用来被导入使用的,没有一个文件时用来被直接运行
因为包其实时模块的一种形式而已
2.import p1
a.创建p1的名称空间
b.执行p1下的__init__.py文件的代码,将执行过程中产生的名字都丢到名称空间中
c.在当前执行文件中拿到一个名字p1, p1指向__init__.py的名称空间
3.包内模块的绝对导入与相对导入
绝对导入:每次导入都是以最顶级包为起始开始导入
相当导入:相对于当前所在的文件,.代表当前所在的文件,..代表上一级
强调:相对导入只能在被导入的模块中使用
在执行文件中不能用.或者..的导入方式
4.注意
但凡在点的左边必须时一个包
def f1():
pass
def f2():
pass
def f3():
pass
def f4():
pass
def f5():
pass
def f6():
pass
六.常用模块
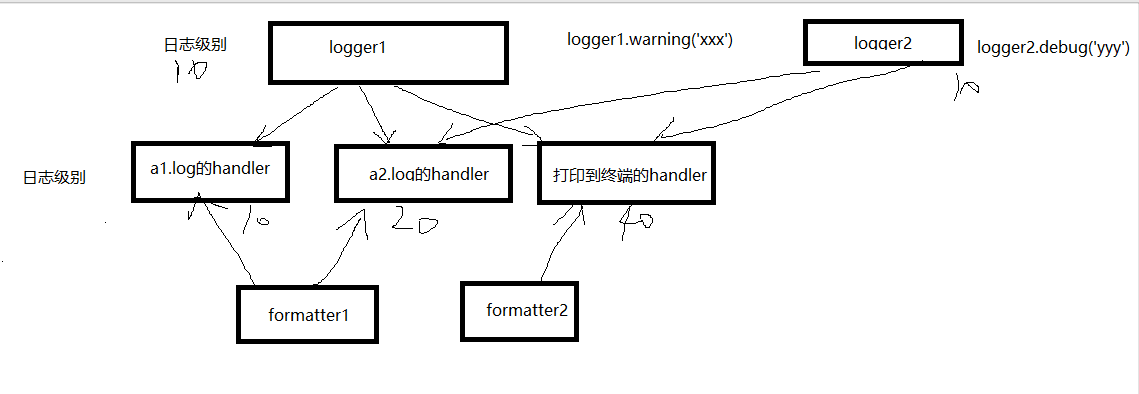
1.logging
logger1=logging.getLogger('交易日志')
2)filter过滤
3)handler对象需要与logger对绑定,用来接收logger对象传过来的日志,控制打印到不同的地方(不同的文件、终端)
fh1=logging.FileHandler(filename='a1.log',encoding='utf-8')
fh2=logging.FileHandler(filename='a2.log',encoding='utf-8')
sh=logging.StreamHandler()
4)formmter对象需要与handler对象绑定,用于控制handler对象的日志格式
formmater1=logging.Formatter(
fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p'
)
formmater2=logging.Formatter(
fmt='%(asctime)s - %(levelname)s : %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p'
)
# 设置日志级别:logger与handler两层关卡都放行,日志最终才放行
logger1.setLevel(10)
fh1.setLevel(10)
fh2.setLevel(40)
sh.setLevel(10)
# 建立logger对象与handler对象的绑定关系
logger1.addHandler(fh1)
logger1.addHandler(fh2)
logger1.addHandler(sh)
# 建立handler对象与formmater对象的绑定关系
fh1.setFormatter(formmater1)
fh2.setFormatter(formmater1)
sh.setFormatter(formmater2)
# 使用logger1对象产生日志,打印到不同的位置
# logger1.debug('alex给egon转账1亿')
logger1.warning('alex可能要赔一个亿')
import logging
logging.debug('调试debug')
logging.info('消息info')
logging.warning('警告warn')
logging.error('错误error')
logging.critical('严重critical')
'''
WARNING:root:警告warn
ERROR:root:错误error
CRITICAL:root:严重critical
'''
输出:
WARNING:root:警告warn
ERROR:root:错误error
CRITICAL:root:严重critical
完整的日志内容:
1.时间
2.级别
3.类型
2.re模块
import re
print(re.findall('\w','hello123 -_*()')) #匹配字母数字下划线
print(re.findall('\W','hello123 -_*()')) #匹配非字母数字下划线
print(re.findall('andy','helloandy123 -_andy*()')) #匹配andy
print(re.findall('^andy','helloandy123 -_andy*()')) #匹配andy开头
print(re.findall('andy$','helloandy123 -_andy')) #匹配andy结尾
print(re.findall('\s','h \tell\nlo')) #匹配任意空字符
print(re.findall('\t','h \tell\nlo')) #匹配制表符
print(re.findall('\n','h \tell\nlo')) #匹配换行符
print(re.findall('\S','h \tell\nlo')) #匹配任意非空字符
print(re.findall('\d','hello123 -_*()'))#匹配数字
#.代表匹配除了换行符意外的任意单个字符
print(re.findall('a.c','abc a*c a1c a\nc aaaaac a c hello123 -_*()'))#.匹配除了换行符以外的任意单个字符
print(re.findall('a.c','abc a*c a1c a\nc aaaaac a c hello123 -_*()',re.DOTALL))#.匹配任意单个字符
#[]代表匹配我们自定范围的任意一个字符,[]减号必须放在最后
print(re.findall('\d[+*/-]\d','1+3 a1!3sdf 2*3 1/4 2-3 a\nc aaaaac a c hello123 -_*()'))#.匹配除了换行符以外的任意单个字符
print(re.findall('a[0-9]c','a1c a2c a11c abc a*c a9c hello123 -_*()'))#.匹配除了换行符以外的任意单个字符
print(re.findall('a[A-Za-z]c','a1c a2c a11c abc a*c a9c hello123 -_*()'))#.匹配除了换行符以外的任意单个字符
输出:
['h', 'e', 'l', 'l', 'o', '1', '2', '3', '_']
[' ', '-', '*', '(', ')']
['andy', 'andy']
[]
['andy']
[' ', '\t', '\n']
['\t']
['\n']
['h', 'e', 'l', 'l', 'l', 'o']
['1', '2', '3']
['abc', 'a*c', 'a1c', 'aac', 'a c']
['abc', 'a*c', 'a1c', 'a\nc', 'aac', 'a c']
['1+3', '2*3', '1/4', '2-3']
['a1c', 'a2c', 'a9c']
['abc']
#重复匹配
#? :代表左边那一个字符出现0次或1次
print(re.findall('ab?','b ab abb abbb bbbba'))
print(re.findall('ab{0,1}','b ab abb abbb bbbba')) #* :代表左边那一个自处出现0次或无穷次,如果没有可以凑活,但如果>1个,有多少就必须拿多少
print(re.findall('ab*','b ab abb abbb bbbba'))
print(re.findall('ab{0,}','b ab abb abbb bbbba')) #+ :代表左边那一个字符出现1次或无穷次,至少要有一个,但如果有>1个,有多少就必须拿多少
print(re.findall('ab+','b ab abb abbb bbbba'))
print(re.findall('ab{1,}','b ab abb abbb bbbba')) #{n,m}:代表左边那一个字符出现n次到m次,至少要有n个,但如果有>n个,就拿<=m个
print(re.findall('ab{2,5}','b ab abbbbbbbbbbb abb abbbbb bbbbbba')) #.* :匹配任意0个或无穷个任意字符,默认贪是婪匹配,找离a最远的c
print(re.findall('a.*c','hello a123124cqweqwec+')) #.*? :匹配任意0个或无穷个任意字符,默认是非贪婪匹配,找离a最近的c
print(re.findall('a.*?c','hello a123124cqweqwec+aasdasdc')) print(re.findall('href="(.*?)"','<div class="div1"><a href="https://www.baidu.com">"点我啊"</a></dic><div class="div1"><a href="https://www.baidu.com">"点我啊"</a></dic><div class="div1"><a href="https://www.python.com">"点我啊"</a></dic>'))
# ?:
print(re.findall('compan(ies|y)','Too many companies have gone bankrupt, and the nnext one is my company'))
print(re.findall('compan(?:ies|y)','Too many companies have gone bankrupt, and the nnext one is my company')) #[]内^代表取反
print(re.findall('a[^0-9]c','hello a1c abc a123124cqweqwec+')) print(re.findall('a\\\c','a\c a1c abc aac'))
print(re.findall(r'a\\c','a\c a1c abc aac'))
输出:
['ab', 'ab', 'ab', 'a']
['ab', 'ab', 'ab', 'a']
['ab', 'abb', 'abbb', 'a']
['ab', 'abb', 'abbb', 'a']
['ab', 'abb', 'abbb']
['ab', 'abb', 'abbb']
['abbbbb', 'abb', 'abbbbb']
['a123124cqweqwec']
['a123124c', 'aasdasdc']
['https://www.baidu.com', 'https://www.baidu.com', 'https://www.python.com']
['ies', 'y']
['companies', 'company']
['abc']
['a\\c']
['a\\c']
print(re.findall(r'andy','a\c andy a1c abc aac andy '))
#re.search从左往右匹配,成功一个就结束,不成功最后返回None
print(re.search(r'andy','a\c andy a1c abc aac andy '))
print(re.search(r'andy','a\c andy a1c abc aac andy ').group())
obj=re.search('href="(.*?)"','<div class="div1"><a href="https://www.baidu.com">"点我啊"</a></dic><div class="div1"><a href="https://www.baidu.com">"点我啊"</a></dic><div class="div1"><a href="https://www.python.com">"点我啊"</a></dic>')
print(obj.group())
#以下同等作用
print(re.search(r'^andy','a\c andy a1c abc aac andy '))
print(re.match(r'andy','a\c andy a1c abc aac andy '))
#切分
msg='root:x:0:0::/root:/bin/bash'
print(re.split('[:/]',msg))
#替换
print(re.sub('andy','haha','andy hello andy'))
print(re.sub('^andy','haha','andy hello andy'))
print(re.sub('andy$','haha','andy hello andy'))
输出:
['andy', 'andy']
<_sre.SRE_Match object; span=(4, 8), match='andy'>
andy
href="https://www.baidu.com"
None
None
['root', 'x', '0', '0', '', '', 'root', '', 'bin', 'bash']
haha hello haha
haha hello andy
andy hello haha
obj=re.compile('href="(.*?)"')
msg1='<div class="div1"><a href="https://www.baidu.com">点我啊</a></div><div class="div1"><a href="https://www.python.org">点我啊</a></div>'
# print(re.findall('href="(.*?)"',msg1))
print(obj.findall(msg1))
msg2='<div class="div1"><a href="https://www.sina.com.cn">点我啊</a></div><div class="div1"><a href="https://www.tmall.com">点我啊</a></div>'
# print(re.search('href="(.*?)"',msg2).group(1))
print(obj.search(msg2).group(1))
输出:
['https://www.baidu.com', 'https://www.python.org']
https://www.sina.com.cn
Day06:迭代器,生成器,生成表达式,面向过程编程,包及常用模块的更多相关文章
- Python 迭代器-生成器-面向过程编程
上节课复习:1. 函数的递归调用 在调用一个函数的过程中又直接或者间接地调用了函数本身称之为函数的递归 函数的递归调用有两个明确的阶段: 1. 回溯 一层一层地调用本身 注意: 1.每一次调用问题的规 ...
- day22 yield的表达式的应用,面向过程编程,内置函数前几个
Python之路,Day10 = Python基础10 生成器表达式: (i for i in range(10) if i > 5)os.walk(r'文件路径')返回一个迭代器, 第一次ne ...
- 匿名函数 python内置方法(max/min/filter/map/sorted/reduce)面向过程编程
目录 函数进阶三 1. 匿名函数 1. 什么是匿名函数 2. 匿名函数的语法 3. 能和匿名函数联用的一些方法 2. python解释器内置方法 3. 异常处理 面向过程编程 函数进阶三 1. 匿名函 ...
- PYTHON-匿名函数,递归与二分法,面向过程编程
"""匿名函数1 什么是匿名函数 def定义的是有名函数:特点是可以通过名字重复调用 def func(): #func=函数的内存地址 pass 匿名函数就是没有名字的 ...
- python函数:匿名函数、函数递归与二分法、面向过程编程
今天主要讲三大部分内容: 一.匿名函数二.函数递归与二分法三.面向过程编程 一.匿名函数: """ 1. 什么时匿名函数 def定义的是有名函数:特点是可以通过名字重复调 ...
- Python之路【第六篇】:Python迭代器、生成器、面向过程编程
阅读目录 一.迭代器 1.迭代的概念 #迭代器即迭代的工具,那什么是迭代呢? #迭代是一个重复的过程,每次重复即一次迭代,并且每次迭代的结果都是下一次迭代的初始值 代码如下: while True: ...
- python之迭代器、生成器、面向过程编程
一 迭代器 一 迭代的概念 #迭代器即迭代的工具,那什么是迭代呢?#迭代是一个重复的过程,每次重复即一次迭代,并且每次迭代的结果都是下一次迭代的初始值 while True: #只是单纯地重复,因而不 ...
- python之旅:迭代器、生成器、面向过程编程
1.什么是迭代器? 1.什么是迭代器 迭代的工具 什么是迭代? 迭代是一个重复的过程,每一次重复都是基于上一次结果而进行的 # 单纯的重复并不是迭代 while True: print('=====& ...
- python全栈开发-Day11 迭代器、生成器、面向过程编程
一. 迭代器 一 .迭代的概念 迭代器即迭代的工具,那什么是迭代呢? 迭代是一个重复的过程,每次重复即一次迭代,并且每次迭代的结果都是下一次迭代的初始值 while True: #只是单纯地重复,因而 ...
随机推荐
- vue 流程设计器
github地址:https://github.com/280780363/gucflow.designer demo地址:https://280780363.github.io/gucflow.de ...
- 【BZOJ3251】树上三角形 暴力
[BZOJ3251]树上三角形 Description 给定一大小为n的有点权树,每次询问一对点(u,v),问是否能在u到v的简单路径上取三个点权,以这三个权值为边长构成一个三角形.同时还支持单点修改 ...
- 【BZOJ1835】[ZJOI2010]base 基站选址 线段树+DP
[BZOJ1835][ZJOI2010]base 基站选址 Description 有N个村庄坐落在一条直线上,第i(i>1)个村庄距离第1个村庄的距离为Di.需要在这些村庄中建立不超过K个通讯 ...
- React-Native开源项目学习
https://github.com/liuhongjun719/react-native-DaidaiHelperNew 借贷助手https://github.com/liuhongjun719/r ...
- 【网络与系统安全】利用burpsuite进行重放攻击
重放攻击的定义 所谓重放攻击就是攻击者发送一个目的主机已接收过的包,来达到欺骗系统的目的,主要用于身份认证过程. 原理 重放攻击的基本原理就是把以前窃听到的数据原封不动地重新发送给接收方.如果攻击者知 ...
- Webpack探索【8】--- 模块热替换详解
本文主要讲模块热替换相关内容.
- Struts2问题总结
1 如何搭建Struts2开发环境? Struts2 获取 http://struts.apache.org/download.cgi Struts-2.3.16.3-all.zip 创建Web项 ...
- HDUJ 2052 Picture 模拟
Picture Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Su ...
- Drupal 安装过程
php.ini 文件 https://drupal.stackexchange.com/questions/164172/problem-installing-in-local-the-transla ...
- Pandas一些小技巧
Pandas有一些不频繁使用容易忘记的小技巧 1.将不同Dataframe写在一个Excel的不同Sheet,或添加到已有Excel的不同Sheet(同名Sheet会覆盖) from pandas i ...