kafka简介&使用
架构
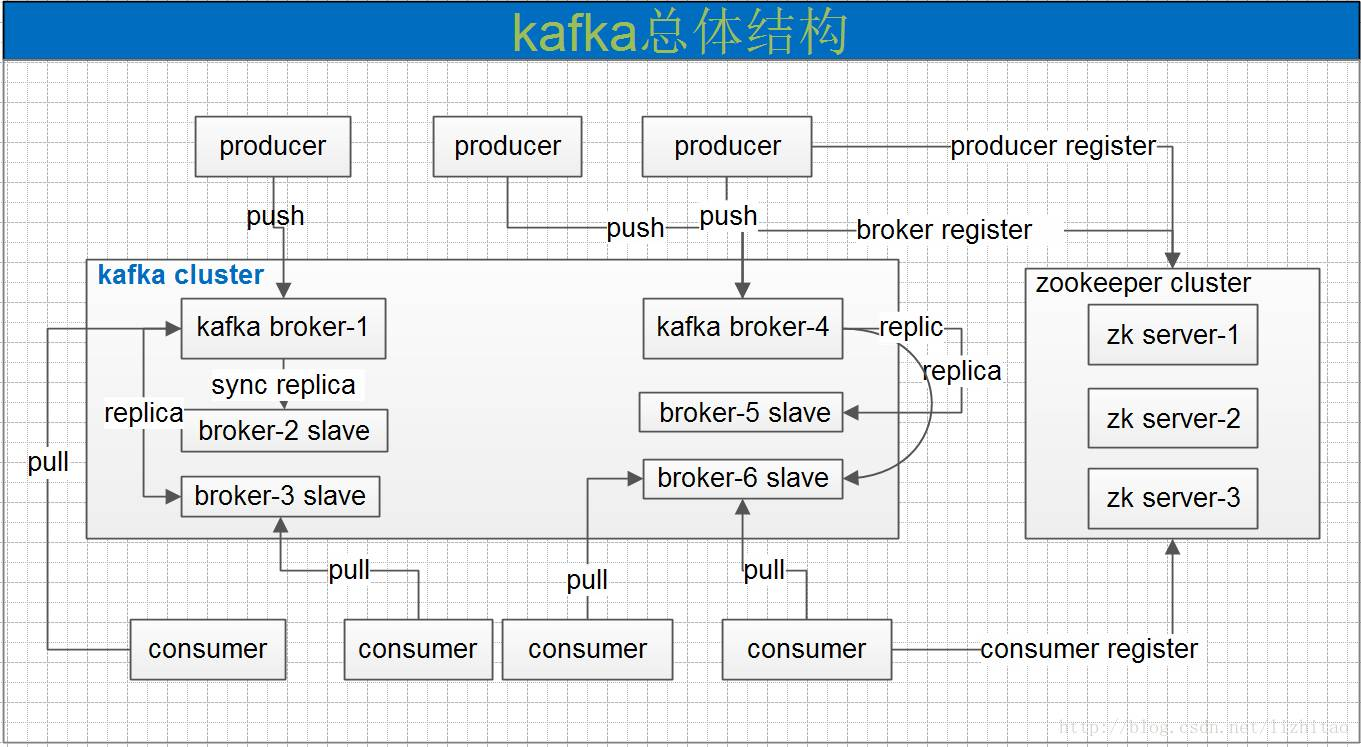
几个角色概念
- broker 缓存代理,Kafa集群中的一台或多台服务器统称为broker。kafka集群有多个kafka实例组成,每个实例(server)成为broker。每个类型的消息被定义为topic,同一topic内部的消息按照一定的key和算法被分区(partition)存储在不同的Broker上,消息生产者producer和消费者consumer可以在多个Broker上生产/消费topic

- topic 相当于数据库中的Table,行数据以log的形式存储,物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处
- partition Parition是物理上的概念,每个Topic包含一个或多个Partition,可以理解为一个Parition就是一个消息队列,每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它是唯一标记一条消息。它唯一的标记一条消息。kafka并没有提供其他额外的索引机制来存储offset,因为在kafka中几乎不允许对消息进行“随机读写”
- Producer:消息生产者,负责发布消息到Kafka broker
- Consumer:消息消费者,向Kafka broker读取消息的客户端。
消息发送的流程
- Producer根据指定的partition方法(round-robin、hash等),将消息发布到指定topic的partition里面
- kafka集群接收到Producer发过来的消息后,将其持久化到硬盘,并保留消息指定时长(可配置),而不关注消息是否被消费。
- Consumer从kafka集群pull数据,并控制获取消息的offset
注: 对于consumer而言,它需要保存消费消息的offset,对于offset的保存和使用,由consumer来控制;当consumer正常消费消息时,offset将会"线性"的向前驱动,即消息将依次顺序被消费.事实上consumer可以使用任意顺序消费消息,它只需要将offset重置为任意值
另外即使消息被消费,消息仍然不会被立即删除.日志文件将会根据broker中的配置要求,保留一定的时间之后删除;比如log文件保留2天,那么两天后,文件会被清除,无论其中的消息是否被消费.kafka通过这种简单的手段,来释放磁盘空间,以及减少消息消费之后对文件内容改动的磁盘IO开支
副本replication策略
kafka在0.8之前message是没有备份容错机制的,producer的工作模式是fire and forget,如果一个broker失效,那么相关topic分区的相关消息也就丢失了。这种设计的原因在于最初的应用模式,如日志/用户行为等消息的处理,对数据的健壮性方面要求不高,可以容忍部分数据的缺失。采用fire and forget 模式,不需要等待Broker ack,有利于提高producer的吞吐率
在0.8版本中,添加了数据replica的机制,一个消息分区的多个replica分布在不同的Broker上,由leader replica负责日常读写,通过zookeeper监督failover,不同的分区的leader replica均衡负载到不同的Broker上。在这种情况下,producer可以选择不等待leader replica的Ack,部分Ack,或者完全备份完毕后Ack等不同的ack机制。这三种机制,性能依次递减 (producer吞吐量降低1-3倍),数据健壮性则依次递增
引入Replication之后,同一个Partition可能会有多个Replica,而这时需要在这些Replication之间选出一个Leader,Producer和Consumer只与这个Leader交互,其它Replica作为Follower从Leader中复制数据
Kafka消息分组
同一Topic的一条消息只能被同一个Consumer Group内的一个Consumer消费,但多个Consumer Group可同时消费这一消息。这是Kafka用来实现一个Topic消息的广播(发给所有的Consumer)和单播(发给某一个Consumer)的手段。一个Topic可以对应多个Consumer Group。如果需要实现广播,只要每个Consumer有一个独立的Group就可以了。要实现单播只要所有的Consumer在同一个Group里。用Consumer Group还可以将Consumer进行自由的分组而不需要多次发送消息到不同的Topic
kafka使用
创建 topic
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
可以通过list命令查看创建的topic:
> bin/kafka-topics.sh --list --zookeeper localhost:2181
test
发送消息.
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
This is a messageThis is another message
启动consumer
Kafka also has a command line consumer that will dump out messages to standard output.
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
This is a message
This is another message
你在一个终端中运行consumer命令行,另一个终端中运行producer命令行,就可以在一个终端输入消息,另一个终端读取消息
搭建一个多个broker的集群
> cp config/server.properties config/server-2.properties
在拷贝出的新文件中添加以下参数:
config/server-1.properties:
broker.id=1
port=9093
log.dir=/tmp/kafka-logs-1 config/server-2.properties:
broker.id=2
port=9094
log.dir=/tmp/kafka-logs-2
> bin/kafka-server-start.sh config/server-1.properties &
...
> bin/kafka-server-start.sh config/server-2.properties &
...
创建一个拥有3个副本的topic:
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
下面解释一下这些输出。第一行是对所有分区的一个描述,然后每个分区都会对应一行,因为我们只有一个分区所以下面就只加了一行。
- leader:负责处理消息的读和写,leader是从所有节点中随机选择的.
- replicas:列出了所有的副本节点,不管节点是否在服务中.
- isr:是正在服务中的节点.
向topic发送消息:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic
...
my test message 1my test message 2^C
消费这些消息:
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic
...
my test message 1
my test message 2
^C
> ps | grep server-1.properties7564 ttys002 0:15.91 /System/Library/Frameworks/JavaVM.framework/Versions/1.6/Home/bin/java...
> kill -9 7564
> bin/kafka-topics.sh --describe --zookeeper localhost:218192 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 1,2,0 Isr: 2,0
虽然最初负责续写消息的leader down掉了,但之前的消息还是可以消费的:
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic
...
my test message 1
my test message 2
^C
kafka简介&使用的更多相关文章
- Kafka简介
Kafka简介 转载请注明出处:http://www.cnblogs.com/BYRans/ Apache Kafka发源于LinkedIn,于2011年成为Apache的孵化项目,随后于2012年成 ...
- Kafka简介及使用PHP处理Kafka消息
Kafka简介及使用PHP处理Kafka消息 Kafka 是一种高吞吐的分布式消息系统,能够替代传统的消息队列用于解耦合数据处理,缓存未处理消息等,同时具有更高的吞吐率,支持分区.多副本.冗余,因此被 ...
- Kafka记录-Kafka简介与单机部署测试
1.Kafka简介 kafka-分布式发布-订阅消息系统,开发语言-Scala,协议-仿AMQP,不支持事务,支持集群,支持负载均衡,支持zk动态扩容 2.Kafka的架构组件 1.话题(Topic) ...
- Kafka简介、安装
一.Kafka简介 Kafka是一个分布式.可分区的.可复制的消息系统.几个基本的消息系统术语:1.消费者(Consumer):从消息队列(Kafka)中请求消息的客户端应用程序.2.生产者(Prod ...
- 【Apache Kafka】一、Kafka简介及其基本原理
对于大数据,我们要考虑的问题有很多,首先海量数据如何收集(如Flume),然后对于收集到的数据如何存储(典型的分布式文件系统HDFS.分布式数据库HBase.NoSQL数据库Redis),其次存储 ...
- KafKa简介和利用docker配置kafka集群及开发环境
KafKa的基本认识,写的很好的一篇博客:https://www.cnblogs.com/sujing/p/10960832.html 问题:1.kafka是什么?Kafka是一种高吞吐量的分布式发布 ...
- Apache Kafka简介与安装(二)
Kafka在Windows环境上安装与运行 简介 Apache kafka 是一个分布式的基于push-subscribe的消息系统,它具备快速.可扩展.可持久化的特点.它现在是Apache旗下的一个 ...
- Kafka简介、基本原理、执行流程与使用场景
一.简介 Apache Kafka是分布式发布-订阅消息系统,在 kafka官网上对 kafka 的定义:一个分布式发布-订阅消息传递系统. 它最初由LinkedIn公司开发,Linkedin于201 ...
- Kafka 学习之路(一)—— Kafka简介
一.简介 Apache Kafka是一个分布式的流处理平台.它具有以下特点: 支持消息的发布和订阅,类似于RabbtMQ.ActiveMQ等消息队列: 支持数据实时处理: 能保证消息的可靠性投递: 支 ...
- Kafka 系列(一)—— Kafka 简介
一.简介 ApacheKafka 是一个分布式的流处理平台.它具有以下特点: 支持消息的发布和订阅,类似于 RabbtMQ.ActiveMQ 等消息队列: 支持数据实时处理: 能保证消息的可靠性投递: ...
随机推荐
- 关于MQ的几件小事(三)如何保证消息不重复消费
1.幂等性 幂等(idempotent.idempotence)是一个数学与计算机学概念,常见于抽象代数中. 在编程中一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同.幂等函数,或 ...
- npm查看包版本
点击跳转 ~ 会匹配最近的小版本依赖包,比如~1.2.3会匹配所有1.2.x版本,但是不包括1.3.0 ^ 会匹配最新的大版本依赖包,比如^1.2.3会匹配所有1.x.x的包,包括1.3.0,但是不包 ...
- python识别文字tesseract
Ubuntu版本: .tesseract-ocr安装 sudo apt-get install tesseract-ocr .pytesseract安装 sudo pip install pytess ...
- 重构drf后的环境变量配置
目录 环境变量 配置media 封装logger 封装项目异常处理 二次封装Response模块 环境变量 dev.py # 环境变量操作:小luffyapiBASE_DIR与apps文件夹都要添加到 ...
- Java【tomcat】配置文件
Tomcat(二):tomcat配置文件server.xml详解和部署简介 分类: 网站架构 本文原创地址在博客园:https://www.cnblogs.com/f-ck-need-u/p/ ...
- 负载均衡集群(LBC)
一.LVS简介及工作模式1. LVS简介Linux Virtual Server,该软件的功能是实现LB(load balance) 2.LVS的三种工作模式 1)NAT模式(NAT) LVS 服务器 ...
- super关键字小结(构造方法的执行是不是一定会创建对象?)
1.父类 public class Person { private String name = "李四"; private int age; public Person() { ...
- VS2010 insert Oracle数据库
背景:批量插入上万条数据到Oracle数据库的一张表里. 工具:VS2010. 因为是访问远程数据库,所以需要先装一个oracle client. 使用oracle客户端的方式访问数据库,需要添加对其 ...
- BZOJ4543 Hotel加强版(长链剖分)
题意 求一棵树上,两两距离相等的三个点的三元组(无序)的个数. 题解 转自 CaptainHarryChen 的博客 CODE 代码中的f,gf,gf,g对应题解中的num,waynum,waynum ...
- 使用tippecanoe把GeoJSON制作成供mapbox展示的矢量切片vectortile
本文记录一下把geojson格式的数据制作成本地的矢量切片,并在mapbox中展示的过程. 1.切片 1.1 矢量数据需要先转换为geojson,如果是shp格式可以使用QGIS或者下载shp2gwo ...