使用Spring基于应用层实现读写分离(一)基础版
背景
我们一般应用对数据库而言都是“读多写少”,也就说对数据库读取数据的压力比较大,有一个思路就是说采用数据库集群的方案,
其中一个是主库,负责写入数据,我们称之为:写库;
其它都是从库,负责读取数据,我们称之为:读库;
那么,对我们的要求是:
1、 读库和写库的数据一致;
2、 写数据必须写到写库;
3、 读数据必须到读库;
方案
解决读写分离的方案有两种:应用层解决和中间件解决。
应用层解决

优点:
1、 多数据源切换方便,由程序自动完成;
2、 不需要引入中间件;
3、 理论上支持任何数据库;
缺点:
1、 由程序员完成,运维参与不到;
2、 不能做到动态增加数据源;
中间件解决

优点:
1、 源程序不需要做任何改动就可以实现读写分离;
2、 动态添加数据源不需要重启程序;
缺点:
1、 程序依赖于中间件,会导致切换数据库变得困难;
2、 由中间件做了中转代理,性能有所下降;
相关中间件产品使用:
mysql-proxy:http://hi.baidu.com/geshuai2008/item/0ded5389c685645f850fab07
Amoeba for MySQL:http://www.iteye.com/topic/188598和http://www.iteye.com/topic/1113437
使用Spring基于应用层实现
原理

在进入Service之前,使用AOP来做出判断,是使用写库还是读库,判断依据可以根据方法名判断,比如说以query、find、get等开头的就走读库,其他的走写库。
代码实现
DynamicDataSource
package com.song.facebook.readWriteSplit; import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
/**
* 定义动态数据源,实现通过集成Spring提供的AbstractRoutingDataSource,只需要实现determineCurrentLookupKey方法;
* 由于DynamicDataSource是单例的,线程不安全的,所以采用ThreadLocal保证线程安全,由DynamicDataSourceHolder完成;
* @author songzl
*
*/
public class DynamicDataSource extends AbstractRoutingDataSource{ @Override
protected Object determineCurrentLookupKey() {
//使用DynamicDataSourceHolder保证线程安全,并且得到当前线程中的数据源key
return DynamicDataSourceHolder.getDataSourceKey();
}
}
DynamicDataSourceHolder
package com.song.facebook.readWriteSplit; /**
* 使用ThreadLocal技术来记录当前线程中的数据源的key
* @author songzl
*
*/
public class DynamicDataSourceHolder {
//写库对应的数据源key
private static final String MASTER = "master"; //读库对应的数据源key
private static final String SLAVE = "slave"; //使用ThreadLocal记录当前线程的数据源key
private static final ThreadLocal<String> holder = new ThreadLocal<String>(); /**
* 设置数据源key
* @param key
*/
public static void putDataSourceKey(String key) {
holder.set(key);
} /**
* 获取数据源key
* @return
*/
public static String getDataSourceKey() {
return holder.get();
} /**
* 标记写库
*/
public static void markMaster(){
putDataSourceKey(MASTER);
} /**
* 标记读库
*/
public static void markSlave(){
putDataSourceKey(SLAVE);
}
}
DataSourceAspect
package com.song.facebook.readWriteSplit; import org.apache.commons.lang.StringUtils;
import org.aspectj.lang.JoinPoint; /**
* 定义数据源的AOP切面,通过该Service的方法名判断是应该走读库还是写库
* @author songzl
*
*/
public class DataSourceAspect { /**
* 在进入Service方法之前执行
* @param point 切面对象
*/
public void before(JoinPoint point) {
// 获取到当前执行的方法名
String methodName = point.getSignature().getName();
if (isSlave(methodName)) {
// 标记为读库
DynamicDataSourceHolder.markSlave();
} else {
// 标记为写库
DynamicDataSourceHolder.markMaster();
}
}
/**
* 判断是否为读库
* @param methodName
* @return
*/
private Boolean isSlave(String methodName) {
// 方法名以query、find、get开头的方法名走从库
String[] searchStrings = new String[]{"query","find","get"};
return StringUtils.startsWithAny(methodName, searchStrings);
}
}
配置实现:jdbc.properties配置2个数据源
##配置俩个数据源,实现读写分离
jdbc.master.driver=com.mysql.jdbc.Driver
jdbc.master.url=jdbc:mysql://127.0.0.1:3306/mybatis_1128?useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true
jdbc.master.username=root
jdbc.master.password=123456 jdbc.slave01.driver=com.mysql.jdbc.Driver
jdbc.slave01.url=jdbc:mysql://127.0.0.1:3307/mybatis_1128?useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true
jdbc.slave01.username=root
jdbc.slave01.password=123456
配置多个mysql实例:环境Windows7、mysql5.7
1.将下载的文件解压到自己要安装的目录,我这里解压到目录:E:\ProgramData\,并且拷贝俩份放到同目录下:
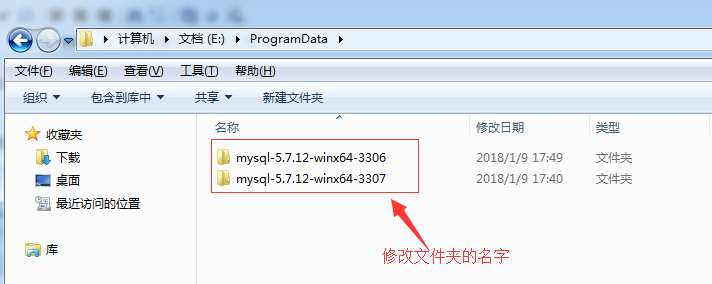
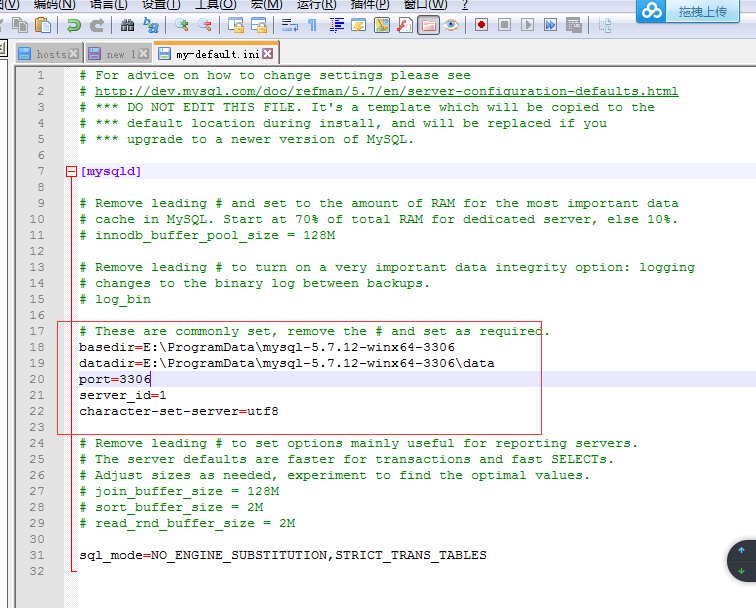
2、找到my-default.ini文件,修改此文件的内容:
basedir:mysql位置
datadir:数据存储位置
port:mysql使用的端口号
character-set-server:服务端所用编码配置
3、以管理员身份打开CMD,到mysql存放位置,我这里是[E:\ProgramData\mysql-5.7.12-winx64-3306\bin],进入mysql的bin位子,输入如下命令:
mysqld install mysql-master --defaults-file="E:\ProgramData\mysql-5.7.12-winx64-3306\my-default.ini"
注:–defaults-file后的内容为你自己的my-default.ini文件位置,切记一定要以管理员身份打开cmd不然无法创建成功;
4、执行后会看到输入:Service successfully installed. 如下:

6、这个时候,mysql已经安装完成了,现在我们来初始化它,输入如下命令(执行此命令需要几分钟):
mysqld.exe --defaults-file="E:\ProgramData\mysql-5.7.12-winx64-3306\my-default.ini" --initialize --explicit_defaults_for_timestamp
注:–defaults-file后的内容为你自己的my-default.ini文件位,执行后没有任何输出(有内容输出就错了)。

7、现在来启动它,输入命令:net start mysql-master,执行后输出:

这就这证明我们已将安装好了mysql,接下来我们来连上mysql服务,输入命令mysql -u root -P3306 -p,这个时候需要密码,打开mysql目录下的data文件夹下.err结尾的文件,搜索A temporary password is generated for root@localhost:,后面就是密码,输入密码,登录成功,自己可以根据自己的需要修改密码,修改密码的命令如下:
set password for root@localhost = password('123456');
这样我们就把密码改为了123456,重复安装3307即可,至此mysql安装和多实例已经完了。
定义连接池、DataSource、配置事务管理以及动态切换数据源切面:readWriteSplit.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.0.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-3.0.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-3.0.xsd">
<!-- 实现读写分离配置数据源 -->
<!-- 定义数据源,使用自己实现的数据源 -->
<bean id="readWriteDataSource" class="com.song.facebook.readWriteSplit.DynamicDataSource">
<!-- 设置多个数据源 -->
<property name="targetDataSources">
<map key-type="java.lang.String">
<!-- 这个key需要和程序中的key一致 -->
<entry key="master" value-ref="masterDataSource"/>
<entry key="slave" value-ref="slave01DataSource"/>
</map>
</property>
<!-- 设置默认的数据源,这里默认走写库 -->
<property name="defaultTargetDataSource" ref="masterDataSource"/>
</bean>
<!-- 实现读写分离的配置连接池 -->
<!-- 配置写库的连接池 -->
<bean id="masterDataSource" class="com.jolbox.bonecp.BoneCPDataSource"
destroy-method="close">
<!-- 数据库驱动 -->
<property name="driverClass" value="${jdbc.master.driver}" />
<!-- 相应驱动的jdbcUrl -->
<property name="jdbcUrl" value="${jdbc.master.url}" />
<!-- 数据库的用户名 -->
<property name="username" value="${jdbc.master.username}" />
<!-- 数据库的密码 -->
<property name="password" value="${jdbc.master.password}" />
<!-- 检查数据库连接池中空闲连接的间隔时间,单位是分,默认值:240,如果要取消则设置为0 -->
<property name="idleConnectionTestPeriod" value="60" />
<!-- 连接池中未使用的链接最大存活时间,单位是分,默认值:60,如果要永远存活设置为0 -->
<property name="idleMaxAge" value="30" />
<!-- 每个分区最大的连接数 -->
<property name="maxConnectionsPerPartition" value="150" />
<!-- 每个分区最小的连接数 -->
<property name="minConnectionsPerPartition" value="5" />
</bean>
<!-- 配置读库的连接池 -->
<bean id="slave01DataSource" class="com.jolbox.bonecp.BoneCPDataSource"
destroy-method="close">
<!-- 数据库驱动 -->
<property name="driverClass" value="${jdbc.slave01.driver}" />
<!-- 相应驱动的jdbcUrl -->
<property name="jdbcUrl" value="${jdbc.slave01.url}" />
<!-- 数据库的用户名 -->
<property name="username" value="${jdbc.slave01.username}" />
<!-- 数据库的密码 -->
<property name="password" value="${jdbc.slave01.password}" />
<!-- 检查数据库连接池中空闲连接的间隔时间,单位是分,默认值:240,如果要取消则设置为0 -->
<property name="idleConnectionTestPeriod" value="60" />
<!-- 连接池中未使用的链接最大存活时间,单位是分,默认值:60,如果要永远存活设置为0 -->
<property name="idleMaxAge" value="30" />
<!-- 每个分区最大的连接数 -->
<property name="maxConnectionsPerPartition" value="150" />
<!-- 每个分区最小的连接数 -->
<property name="minConnectionsPerPartition" value="5" />
</bean> <!-- 定义事务管理器 -->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<!-- 将id为readWriteDataSource的自定义的动态数据源注入 -->
<property name="dataSource" ref="readWriteDataSource" />
</bean> <!-- 定义事务策略 -->
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<!--定义查询方法都是只读的 -->
<tx:method name="query*" read-only="true" />
<tx:method name="find*" read-only="true" />
<tx:method name="get*" read-only="true" /> <!-- 主库执行操作,事务传播行为定义为默认行为 -->
<tx:method name="save*" propagation="REQUIRED" />
<tx:method name="update*" propagation="REQUIRED" />
<tx:method name="delete*" propagation="REQUIRED" /> <!--其他方法使用默认事务策略 -->
<tx:method name="*" />
</tx:attributes>
</tx:advice> <!-- 定义AOP切面处理器 -->
<bean id="dataSourceAspect" class="com.song.facebook.readWriteSplit.DataSourceAspect" />
<aop:config>
<!-- 定义切面,所有的service的所有方法 -->
<aop:pointcut id="txPointcut" expression="execution(* xx.xxx.xxxxxxx.service.*.*(..))" />
<!-- 应用事务策略到Service切面 -->
<aop:advisor advice-ref="txAdvice" pointcut-ref="txPointcut"/> <!-- 将切面应用到自定义的切面处理器上,-9999保证该切面优先级最高执行 -->
<aop:aspect ref="dataSourceAspect" order="-9999">
<aop:before method="before" pointcut-ref="txPointcut" />
</aop:aspect>
</aop:config>
</beans>
特别注意下:com.jolbox.bonecp.BoneCPDataSource的jar地址提供给大家,http://maven.outofmemory.cn/com.jolbox/bonecp/0.8.0.RELEASE/(原创未提供,找了半天才找到)
或者在pom.xml文件中添加这个也可:
<dependency>
<groupId>com.jolbox</groupId>
<artifactId>bonecp</artifactId>
<version>0.8.0.RELEASE</version>
</dependency>
到此为止,第一版构建完毕。
使用Spring基于应用层实现读写分离(一)基础版的更多相关文章
- 在应用层通过spring特性解决数据库读写分离
如何配置mysql数据库的主从? 单机配置mysql主从:http://my.oschina.net/god/blog/496 常见的解决数据库读写分离有两种方案 1.应用层 http://neore ...
- Spring AOP 实现数据库读写分离
背景 我们一般应用对数据库而言都是"读多写少",也就说对数据库读取数据的压力比较大,有一个思路就是说采用数据库集群的方案, 其中一个是主库,负责写入数据,我们称之为:写库: 其它都 ...
- Spring配置动态数据源-读写分离和多数据源
在现在互联网系统中,随着用户量的增长,单数据源通常无法满足系统的负载要求.因此为了解决用户量增长带来的压力,在数据库层面会采用读写分离技术和数据库拆分等技术.读写分离就是就是一个Master数据库,多 ...
- 搭建基于MySQL的读写分离工具Amoeba
搭建基于MySQL的读写分离工具Amoeba: Amoeba工具是实现MySQL数据库读写分离的一个工具,前提是基于MySQL主从复制来实现的: 实验环境(虚拟机): 主机 角色 10.10.10.2 ...
- 基于spring的aop实现读写分离与事务配置
项目开发中经常会遇到读写分离等多数据源配置的需求,在Java项目中可以通过Spring AOP来实现多数据源的切换. 一.Spring事务开启流程 Spring中通常通过@Transactional来 ...
- 基于Mycat实现读写分离
随着应用的访问量并发量的增加,应用读写分离是很有必要的.当然应用要实现读写分离,首先数据库层要先做到主从配置,本人前一篇文章介绍了mysql数据库的主从配置方式即:<mysql数据库主从配置&g ...
- Spring Boot+MyBatis+MySQL读写分离
读写分离要做的事情就是对于一条sql语句该选择去哪个数据库执行,至于谁来做选择数据库的事情,无非两个,1:中间件(比如MyCat):二:程序自己去做分离操作. 但是从程序成眠去做读写分离最大的弱点就是 ...
- 搭建基于springboot轻量级读写分离开发框架
何为读写分离 读写分离是指对资源的修改和读取进行分离,能解决很多数据库瓶颈,以及代码混乱难以维护等相关的问题,使系统有更好的扩展性,维护性和可用性. 一般会分三个步骤来实现: 一. 主从数据库搭建 信 ...
- 从零开始学 Java - Spring AOP 实现主从读写分离
深刻讨论为什么要读写分离? 为了服务器承载更多的用户?提升了网站的响应速度?分摊数据库服务器的压力?就是为了双机热备又不想浪费备份服务器?上面这些回答,我认为都不是错误的,但也都不是完全正确的.「读写 ...
随机推荐
- Android opengl 笔记
1. varying vec2 vTextureCoord; 不能用in vec2 ,varying 表示在vs 和 fs中都可见. 2. android 里面 0 和1 都要打小数点 比如0.0 1 ...
- MySQL自测测试
#建学生信息表student create table student ( sno varchar(20) not null primary key, sname varchar(20) not nu ...
- 07 Redis存储Session
django-redis-sessions 官方文档:https://pypi.org/project/django-redis-sessions/ dango-redis 官方文档:http://n ...
- 使用百度echarts仿雪球分时图(二)
上一章简单的介绍了一下分时图的构成,其实就是折线图跟柱状图的组成.本来这章打算是把分时图做完,然后再写一章来进行美化和总结,但是仔细观察了一下,发现其实东西还是有点多的.分时图的图表做完后,还要去美化 ...
- 页面加载完毕后调用js方法进行布局操控 已实验
页面加载完毕后调用js方法进行布局操控 已实验 $(function(){ var check1 = $("[id$=SMS]").is(':checked'); var bl=$ ...
- oracle索引查询
/*<br>* *查看目标表中已添加的索引 * */ --在数据库中查找表名 select * from user_tables where table_name like 'table ...
- Delphi 特性限定符
- STM32TIM定时器的影子寄存器
1.简介 在STM32基本定时器的PSC预分频寄存器和ARR自动装载寄存器都有影子寄存器. 我们可以看到基本定时器功能框图上对应的寄存器有影子~ 2.功能 影子寄存器的存在起到一个缓冲的作用. 设置影 ...
- 遍历二叉树 - 基于队列的BFS
之前学过利用递归实现BFS二叉树搜索(http://www.cnblogs.com/webor2006/p/7262773.html),这次学习利用队列(Queue)来实现,关于什么时BFS这里不多说 ...
- Redis入门(三)——主从服务器配置
当数据量变得庞大的时候,读写分离还是很有必要的.同时避免一个redis服务宕机,导致应用宕机的情况,我们启用sentinel(哨兵)服务,实现主从切换的功能.redis提供了一个master,多个sl ...