python操作kafka实践
1、先看最简单的场景,生产者生产消息,消费者接收消息,下面是生产者的简单代码。
--------------------------------------------------------------------------------
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import json
from kafka import KafkaProducer producer = KafkaProducer(bootstrap_servers='xxxx:x') msg_dict = {
"sleep_time": 10,
"db_config": {
"database": "test_1",
"host": "xxxx",
"user": "root",
"password": "root"
},
"table": "msg",
"msg": "Hello World"
}
msg = json.dumps(msg_dict)
producer.send('test_rhj', msg, partition=0)
producer.close()
--------------------------------------------------------------------------------
下面是消费者的简单代码:
from kafka import KafkaConsumer consumer = KafkaConsumer('test_rhj', bootstrap_servers=['xxxx:x'])
for msg in consumer:
recv = "%s:%d:%d: key=%s value=%s" % (msg.topic, msg.partition, msg.offset, msg.key, msg.value)
print recv --------------------------------------------------------------------------------
下面是结果:

2、如果想要完成负载均衡,就需要知道kafka的分区机制,同一个主题,可以为其分区,在生产者不指定分区的情况,kafka会将多个消息分发到不同的分区,消费者订阅时候如果不指定服务组,
会收到所有分区的消息,如果指定了服务组,则同一服务组的消费者会消费不同的分区,如果2个分区两个消费者的消费者组消费,则,每个消费者消费一个分区,如果有三个消费者的服务组,
则会出现一个消费者消费不到数据;如果想要消费同一分区,则需要用不同的服务组。以此为原理,我们对消费者做如下修改:
———————————————————————————————————
from kafka import KafkaConsumer consumer = KafkaConsumer('test_rhj', group_id='', bootstrap_servers=['10.43.35.25:4531'])
for msg in consumer:
recv = "%s:%d:%d: key=%s value=%s" % (msg.topic, msg.partition, msg.offset, msg.key, msg.value)
print recv
------------------------------------------------------------------------------------
然后我们开两个消费者进行消费,生产者分别往0分区和1分区发消息结果如下,可以看到,一个消费者只能消费0分区,另一个只能消费1分区:


3、kafka提供了偏移量的概念,允许消费者根据偏移量消费之前遗漏的内容,这基于kafka名义上的全量存储,可以保留大量的历史数据,历史保存时间是可配置的,一般是7天,如果偏移量定位到了已删除的位置那也会有问题,但是这种情况可能很小;每个保存的数据文件都是以偏移量命名的,当前要查的偏移量减去文件名就是数据在该文件的相对位置。要指定偏移量消费数据,需要指定该消费者要消费的分区,否则代码会找不到分区而无法消费,代码如下:
from kafka import KafkaConsumer
from kafka.structs import TopicPartition consumer = KafkaConsumer(group_id='', bootstrap_servers=['10.43.35.25:4531'])
consumer.assign([TopicPartition(topic='test_rhj', partition=0), TopicPartition(topic='test_rhj', partition=1)])
print consumer.partitions_for_topic("test_rhj") # 获取test主题的分区信息
print consumer.assignment()
print consumer.beginning_offsets(consumer.assignment())
consumer.seek(TopicPartition(topic='test_rhj', partition=0), 0)
for msg in consumer:
recv = "%s:%d:%d: key=%s value=%s" % (msg.topic, msg.partition, msg.offset, msg.key, msg.value)
print recv
-----------------------------------------------------------------------------------
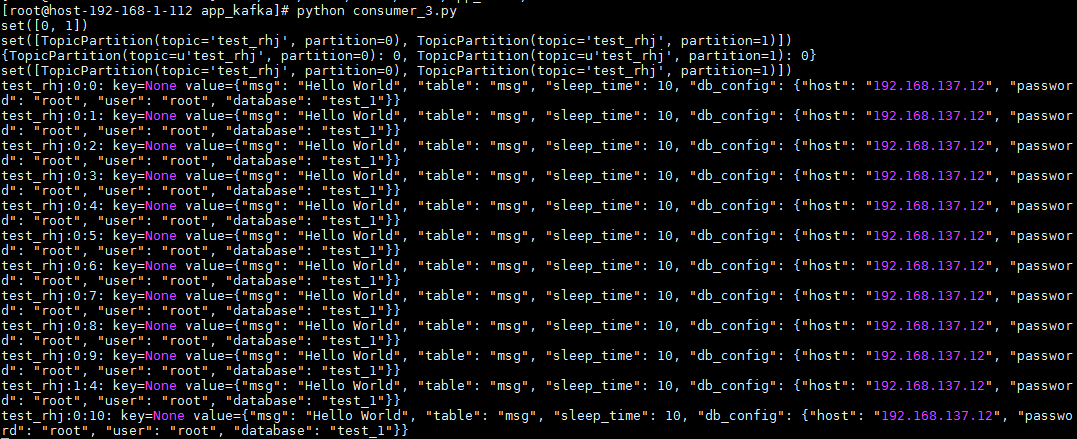
因为指定的便宜量为0,所以从一开始插入的数据都可以查到,而且因为指定了分区,指定的分区结果都可以消费,结果如下:
4、有时候,我们并不需要实时获取数据,因为这样可能会造成性能瓶颈,我们只需要定时去获取队列里的数据然后批量处理就可以,这种情况,我们可以选择主动拉取数据
from kafka import KafkaConsumer
import time consumer = KafkaConsumer(group_id='', bootstrap_servers=['10.43.35.25:4531'])
consumer.subscribe(topics=('test_rhj',))
index = 0
while True:
msg = consumer.poll(timeout_ms=5) # 从kafka获取消息
print msg
time.sleep(2)
index += 1
print '--------poll index is %s----------' % index
-----------------------------------------------------------------------------------
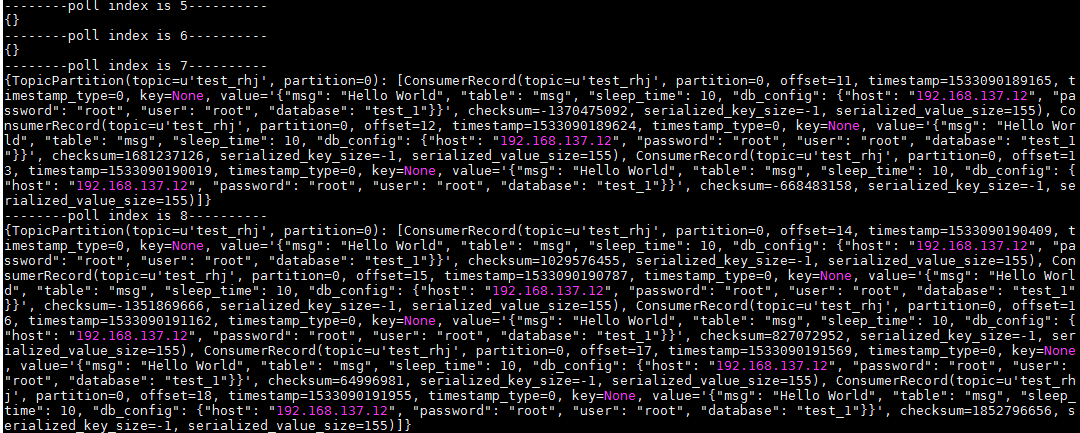
结果如下,可以看到,每次拉取到的都是前面生产的数据,可能是多条的列表,也可能没有数据,如果没有数据,则拉取到的为空:
python操作kafka实践的更多相关文章
- kfka学习笔记一:使用Python操作Kafka
1.准备工作 使用python操作kafka目前比较常用的库是kafka-python库,但是在安装这个库的时候需要依赖setuptools库和six库,下面就要分别来下载这几个库 https://p ...
- 使用python操作kafka
使用python操作kafka目前比较常用的库是kafka-python库 安装kafka-python pip3 install kafka-python 生产者 producer_test.py ...
- kafka实战教程(python操作kafka),kafka配置文件详解
kafka实战教程(python操作kafka),kafka配置文件详解 应用往Kafka写数据的原因有很多:用户行为分析.日志存储.异步通信等.多样化的使用场景带来了多样化的需求:消息是否能丢失?是 ...
- python操作kafka
python操作kafka 一.什么是kafka kafka特性: (1) 通过磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能. (2) 高吞吐量 :即使是 ...
- Python操作rabbitmq 实践笔记
发布/订阅 系统 1.基本用法 生产者 import pika import sys username = 'wt' #指定远程rabbitmq的用户名密码 pwd = ' user_pwd = p ...
- python操作kafka(confluent_kafka 生产)
#!/usr/bin/python # -*- coding:utf-8 -*- from confluent_kafka import Producer import json import tim ...
- kafka--通过python操作topic
修改 topic 的分区数 shiyanlou:bin/ $ ./kafka-topics.sh --zookeeper localhost:2181 --alter --topic mySendTo ...
- paip.复制文件 文件操作 api的设计uapi java python php 最佳实践
paip.复制文件 文件操作 api的设计uapi java python php 最佳实践 =====uapi copy() =====java的无,要自己写... ====php copy ...
- Redis的Python实践,以及四中常用应用场景详解——学习董伟明老师的《Python Web开发实践》
首先,简单介绍:Redis是一个基于内存的键值对存储系统,常用作数据库.缓存和消息代理. 支持:字符串,字典,列表,集合,有序集合,位图(bitmaps),地理位置,HyperLogLog等多种数据结 ...
随机推荐
- docker search 报错
docker 出现 Error response from daemon vim /etc/containers/registries.conf [registries.search]registri ...
- Unreal Engine* 4.19 的 CPU 功能检测
随着现代 CPU 内核数量的增加,可以拥有更多的游戏功能.但是,相比配备高端系统的玩家,内核数量较少的玩家可能会处于劣势.为了缩小这种差距,可以使用 C++ 和蓝图划分特性.这样可以实现最大的 CPU ...
- 关于lombok插件的使用,强大的简化代码工具
关于下载和安装lombok插件,过程特别简单,可以参考: https://blog.csdn.net/longloveqing/article/details/81539749 安装好后,下面介绍下l ...
- 多版本YUM仓库搭建
服务器:CentOS7 YUM源:阿里云 空间要求:CentOS6+CentOS7 50G,考虑后期更新预留,LVS空间100G 1.在服务器配置CentOS7的yum源和CentOS6的yum源 ...
- Books Exchange (easy version) CodeForces - 1249B2
The only difference between easy and hard versions is constraints. There are nn kids, each of them i ...
- 什么是时序时空数据库TSDB
时序时空数据库(Time Series & Spatial Temporal Database,简称 TSDB)是一种高性能.低成本.稳定可靠的在线时序时空数据库服务,提供高效读写.高压缩比存 ...
- 【LOJ】#3044. 「ZJOI2019」Minimax 搜索
LOJ#3044. 「ZJOI2019」Minimax 搜索 一个菜鸡的50pts暴力 设\(dp[u][j]\)表示\(u\)用\(j\)次操作能使得\(u\)的大小改变的方案数 设每个点的初始答案 ...
- MySQL各大存储引擎
MySQL各大存储引擎: 最好先看下你下的MySQL支持什么数据库引擎 存储引擎主要有: 1. MyIsam , 2. InnoDB, 3. Memory, 4. Blackhole, 5. CSV, ...
- spark内核篇-task数与并行度
每一个 spark job 根据 shuffle 划分 stage,每个 stage 形成一个或者多个 taskSet,了解了每个 stage 需要运行多少个 task,有助于我们优化 spark 运 ...
- Qt5.8.0编译QtMqtt库并使用该库连接有人云的例子
一 编译QtMqtt库Qt5.10才官方支持MQTT,但我用的Qt版本是5.8.0 Mingw_32BIT, 为了在Qt5.8.0上添加MQTT支持,需要自己编译源码 步骤: (1) git clon ...