python操作kafka实践
1、先看最简单的场景,生产者生产消息,消费者接收消息,下面是生产者的简单代码。
--------------------------------------------------------------------------------
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import json
from kafka import KafkaProducer producer = KafkaProducer(bootstrap_servers='xxxx:x') msg_dict = {
"sleep_time": 10,
"db_config": {
"database": "test_1",
"host": "xxxx",
"user": "root",
"password": "root"
},
"table": "msg",
"msg": "Hello World"
}
msg = json.dumps(msg_dict)
producer.send('test_rhj', msg, partition=0)
producer.close()
--------------------------------------------------------------------------------
下面是消费者的简单代码:
from kafka import KafkaConsumer consumer = KafkaConsumer('test_rhj', bootstrap_servers=['xxxx:x'])
for msg in consumer:
recv = "%s:%d:%d: key=%s value=%s" % (msg.topic, msg.partition, msg.offset, msg.key, msg.value)
print recv --------------------------------------------------------------------------------
下面是结果:

2、如果想要完成负载均衡,就需要知道kafka的分区机制,同一个主题,可以为其分区,在生产者不指定分区的情况,kafka会将多个消息分发到不同的分区,消费者订阅时候如果不指定服务组,
会收到所有分区的消息,如果指定了服务组,则同一服务组的消费者会消费不同的分区,如果2个分区两个消费者的消费者组消费,则,每个消费者消费一个分区,如果有三个消费者的服务组,
则会出现一个消费者消费不到数据;如果想要消费同一分区,则需要用不同的服务组。以此为原理,我们对消费者做如下修改:
———————————————————————————————————
from kafka import KafkaConsumer consumer = KafkaConsumer('test_rhj', group_id='', bootstrap_servers=['10.43.35.25:4531'])
for msg in consumer:
recv = "%s:%d:%d: key=%s value=%s" % (msg.topic, msg.partition, msg.offset, msg.key, msg.value)
print recv
------------------------------------------------------------------------------------
然后我们开两个消费者进行消费,生产者分别往0分区和1分区发消息结果如下,可以看到,一个消费者只能消费0分区,另一个只能消费1分区:


3、kafka提供了偏移量的概念,允许消费者根据偏移量消费之前遗漏的内容,这基于kafka名义上的全量存储,可以保留大量的历史数据,历史保存时间是可配置的,一般是7天,如果偏移量定位到了已删除的位置那也会有问题,但是这种情况可能很小;每个保存的数据文件都是以偏移量命名的,当前要查的偏移量减去文件名就是数据在该文件的相对位置。要指定偏移量消费数据,需要指定该消费者要消费的分区,否则代码会找不到分区而无法消费,代码如下:
from kafka import KafkaConsumer
from kafka.structs import TopicPartition consumer = KafkaConsumer(group_id='', bootstrap_servers=['10.43.35.25:4531'])
consumer.assign([TopicPartition(topic='test_rhj', partition=0), TopicPartition(topic='test_rhj', partition=1)])
print consumer.partitions_for_topic("test_rhj") # 获取test主题的分区信息
print consumer.assignment()
print consumer.beginning_offsets(consumer.assignment())
consumer.seek(TopicPartition(topic='test_rhj', partition=0), 0)
for msg in consumer:
recv = "%s:%d:%d: key=%s value=%s" % (msg.topic, msg.partition, msg.offset, msg.key, msg.value)
print recv
-----------------------------------------------------------------------------------
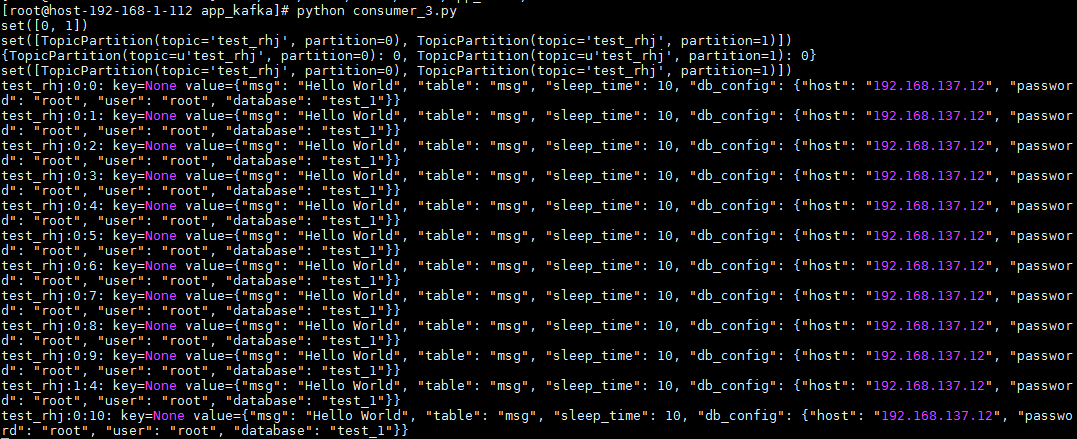
因为指定的便宜量为0,所以从一开始插入的数据都可以查到,而且因为指定了分区,指定的分区结果都可以消费,结果如下:
4、有时候,我们并不需要实时获取数据,因为这样可能会造成性能瓶颈,我们只需要定时去获取队列里的数据然后批量处理就可以,这种情况,我们可以选择主动拉取数据
from kafka import KafkaConsumer
import time consumer = KafkaConsumer(group_id='', bootstrap_servers=['10.43.35.25:4531'])
consumer.subscribe(topics=('test_rhj',))
index = 0
while True:
msg = consumer.poll(timeout_ms=5) # 从kafka获取消息
print msg
time.sleep(2)
index += 1
print '--------poll index is %s----------' % index
-----------------------------------------------------------------------------------
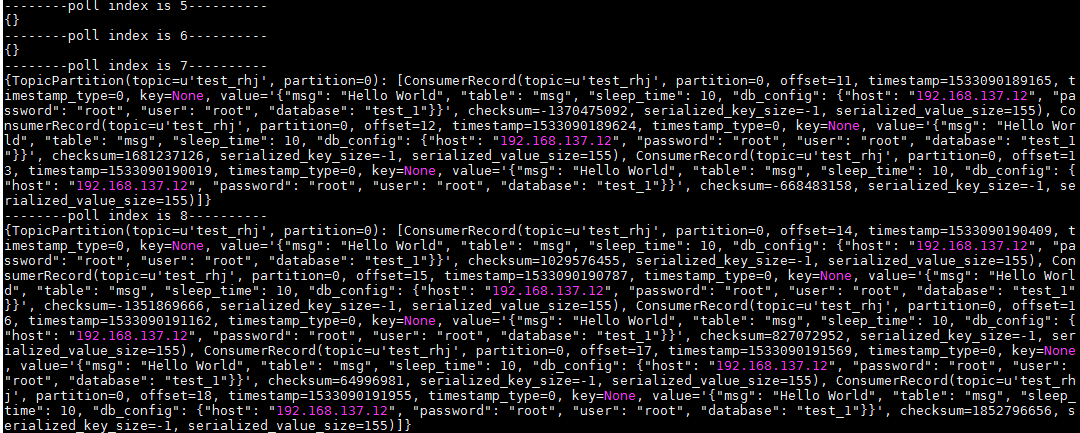
结果如下,可以看到,每次拉取到的都是前面生产的数据,可能是多条的列表,也可能没有数据,如果没有数据,则拉取到的为空:
python操作kafka实践的更多相关文章
- kfka学习笔记一:使用Python操作Kafka
1.准备工作 使用python操作kafka目前比较常用的库是kafka-python库,但是在安装这个库的时候需要依赖setuptools库和six库,下面就要分别来下载这几个库 https://p ...
- 使用python操作kafka
使用python操作kafka目前比较常用的库是kafka-python库 安装kafka-python pip3 install kafka-python 生产者 producer_test.py ...
- kafka实战教程(python操作kafka),kafka配置文件详解
kafka实战教程(python操作kafka),kafka配置文件详解 应用往Kafka写数据的原因有很多:用户行为分析.日志存储.异步通信等.多样化的使用场景带来了多样化的需求:消息是否能丢失?是 ...
- python操作kafka
python操作kafka 一.什么是kafka kafka特性: (1) 通过磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能. (2) 高吞吐量 :即使是 ...
- Python操作rabbitmq 实践笔记
发布/订阅 系统 1.基本用法 生产者 import pika import sys username = 'wt' #指定远程rabbitmq的用户名密码 pwd = ' user_pwd = p ...
- python操作kafka(confluent_kafka 生产)
#!/usr/bin/python # -*- coding:utf-8 -*- from confluent_kafka import Producer import json import tim ...
- kafka--通过python操作topic
修改 topic 的分区数 shiyanlou:bin/ $ ./kafka-topics.sh --zookeeper localhost:2181 --alter --topic mySendTo ...
- paip.复制文件 文件操作 api的设计uapi java python php 最佳实践
paip.复制文件 文件操作 api的设计uapi java python php 最佳实践 =====uapi copy() =====java的无,要自己写... ====php copy ...
- Redis的Python实践,以及四中常用应用场景详解——学习董伟明老师的《Python Web开发实践》
首先,简单介绍:Redis是一个基于内存的键值对存储系统,常用作数据库.缓存和消息代理. 支持:字符串,字典,列表,集合,有序集合,位图(bitmaps),地理位置,HyperLogLog等多种数据结 ...
随机推荐
- linux下配置maven并修改maven源
参考文章 <Linux下Maven的安装与使用> <aliyun阿里云Maven仓库镜像地址> <maven国内镜像配置(Ubuntu)> 下载maven,具体目录 ...
- 李宏毅 Tensorflow解决Fizz Buzz问题
提出问题 一个网友的博客,记录他在一次面试时,碰到面试官要求他在白板上用TensorFlow写一个简单的网络实现异或(XOR)功能.这个本身并不难,单层感知器不能解决异或问题是学习神经网络中的一个常识 ...
- @Transactional事务总结
一:加了注解@Transactional就能起作用的原理总结: 1:首先是由类:JdkDynamicAopProxy,在invoke方法里面创建动态代理类,同时由拦截类进行拦截,代码如下所示: Lis ...
- freeRTOS学习8-20
- 第一章 Scala基础篇
目录 一.Scala基础语法 (一) 变量.类型.操作符 1.变量申明 2.字符串 3.数据类型 4.操作符 (二)循环判断 1.块表达式 2.条件表达式 3.循环表达式 (三)方法和函数 1.方法 ...
- SpringBoot起飞系列-自定义starter(十)
一.前言 到现在,我们可以看出来,如果我们想用一些功能,基本上都是通过添加spring-boot-starter的方式来使用的,因为各种各样的功能都被封装成了starter,然后把相关服务注入到容器中 ...
- python中的类变量和对象变量,以及传值传引用的探究
http://www.cnblogs.com/gtarcoder/p/5005897.html http://www.cnblogs.com/mexh/p/9967811.html
- MySQL安装及初级增删改查一
学习MYsql 是参照这个维C果糖的总结,学习目录网址:https://blog.csdn.net/qq_35246620/article/details/70823903,谢谢大神的无私分享. 一. ...
- 搞懂Dubbo服务发布与服务注册
一.前言 本文讲服务发布与服务注册,服务提供者本地发布服务,然后向注册中心注册服务,将服务实现类以服务接口的形式提供出去,以便服务消费者从注册中心查阅并调用服务. 本文源码分析基于org.apache ...
- Scala学习七——包和引入
一.本章要点 包也可也可以像内部类那样嵌套 包路径不是绝对路径 包声明链x.y.z并不自动将中间包x和x.y变成可见 位于文件顶部不带花括号的包声明在整个文件范围内有效 包对象可以持有函数和变量 引入 ...