Centos7.0配置Hadoop2.7.0伪分布式
一、ssh免密登录
1.命令ssh-keygen、
overwrite输入y一路回车
2.将生成的密钥发送到本机
ssh-copy-id localhost中间会询问是否继续输入“yes”
3.测试免密登录是否成功
ssh localhost
二、Java配置
新建一个文件夹存放java和hadoop这里我在~目录下新建了一个app文件夹下面。

命令行移动文件到新建的app文件夹下。
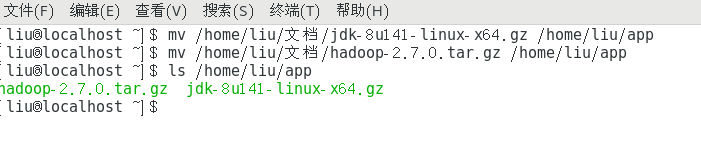
解压jdk压缩包。

创建软连接或重命名已解压文件夹。

配置jdk环境变量。切换到root用户(输入su命令 切换root用户接着输入root用户密码),然后通过
vi /etc/profile
编辑、etc/profile文件配置环境变量。
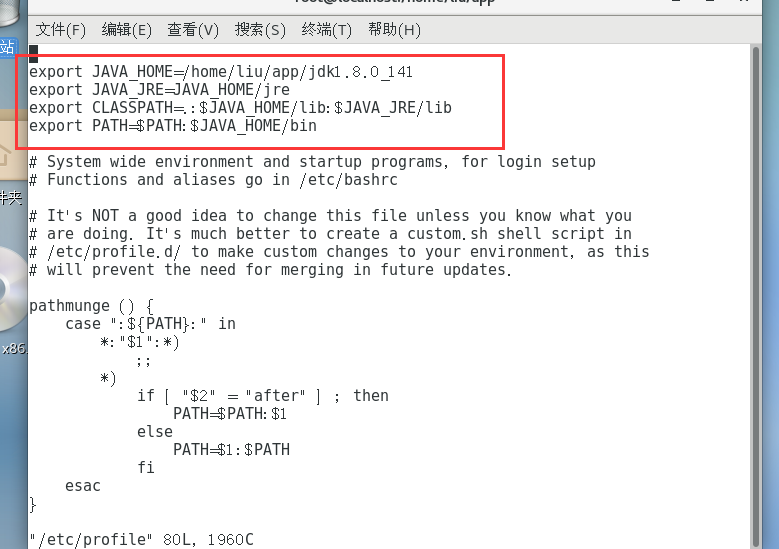
编辑好后Esc键接着“:”在输入wq保存并且退出编辑。
使/etc/profile生效,并检测是否配置成功。
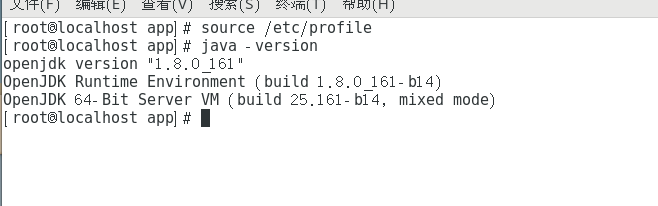
配置成功。
三、Hadoop配置
由root用户切换为普通用户,我这里用户名是liu所以使用命令 su liu。
解压Hadoop然后创建软连接或者重命名。

验证单击模式Hadoop是否安装成功,hadoop/bin/hadoop version
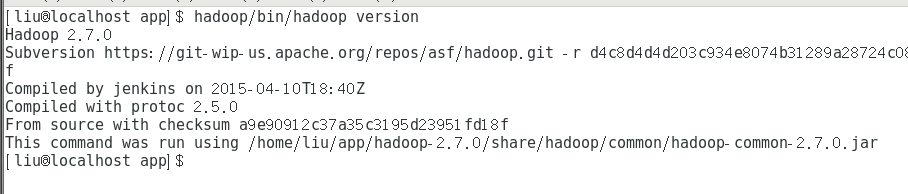
此时可以看到Hadoop版本2.7.0,安装成功。可以在hadoop目录下新建一个test.txt输入一下内容。
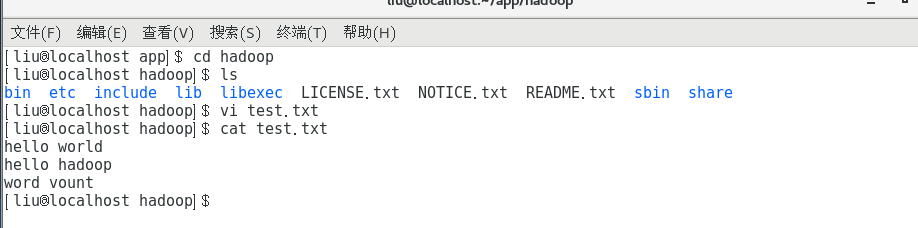
测试运行Hadoop自带的WordCount程序,统计单词个数。

查看结果文件夹output
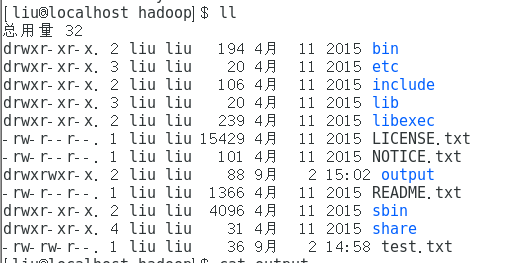
查看内容

四、Hadoop伪分布式配置
进入hadoop目录下的/etc/hadoop文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/data/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
修改core-site.xml文件
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
修改hdfs-site.xml文件
export JAVA_HOME=/home/liu/app/jdk1.8.0_141
修改hadoop-env.sh
<configuration>
<property>
<name>mapreduce.frameword.name</name>
<value>yarn</value>
</property>
</configuration>
修改mapred-site.xml.template
<configuration> <!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-servies</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改yarn-site.xml
配置hadoop环境在 ~/.bashrc文件下

保存退出后记得source ~/.bashrc是修改生效。
然后在~下创建配置文件中的目录,
mkdir -p data/p
mkdir -p /data/dfs/name
mkdir -p /data/dfs/data
第一次需要格式化namenode,进入hadoop目录下。
cd /home/liu/app/hadoop
格式化。
bin/hdfs namenode -format
启动hadoop
sbin/start-all.sh
启动完毕后输入jps查看。
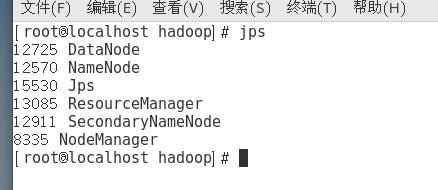
最重要的是NameNode和DataNode。这样就配置并且启动成功了。
需要注意的是如果jps后并没有则说明配置错误,请检查配置文件,若配置完环境变量后检测是否成功,提示失败并给出路径,很有可能是环境变量配置路径错误。
若第一次启动hadoop失败,后边重新启动的时候,请删除~下新建的data文件重新格式化NameNode。
Centos7.0配置Hadoop2.7.0伪分布式的更多相关文章
- Ubuntu14.04 安装配置Hadoop2.6.0
目前关于Hadoop的安装配置教程书上.官方教程.博客都有很多,但由于对Linux环境的不熟悉以及各种教程或多或少有这样那样的坑,很容易导致折腾许久都安装不成功(本人就是受害人之一).经过几天不断尝试 ...
- 在Linux(Centos7)系统上对进行Hadoop分布式配置以及运行Hadoop伪分布式实例
在Linux(Centos7)系统上对进行Hadoop分布式配置以及运行Hadoop伪分布式实例 ...
- Dockerfile完成Hadoop2.6的伪分布式搭建
在 <Docker中搭建Hadoop-2.6单机伪分布式集群>中在容器中操作来搭建伪分布式的Hadoop集群,这一节中将主要通过Dokcerfile 来完成这项工作. 1 获取一个简单的D ...
- hadoop2.6.0实践:002 检查伪分布式环境搭建
1.检查网络配置[root@hadoop-master ~]# cat /etc/sysconfig/networkNETWORKING=yesHOSTNAME=hadoop-masterGATEWA ...
- hadoop2.6.0实践:004 启动伪分布式hadoop的进程
[hadoop@LexiaofeiMaster hadoop-2.6.0]$ start-dfs.shStarting namenodes on [localhost]localhost: start ...
- 分布式配置hadoop2.5.0 2.6.x
1. sudo vim /etc/hostname 在master的机器上,改成 master 在slave上写 slave01,02,03...... 配置好后重启. 2. sudo vi ...
- 2-10 就业课(2.0)-oozie:10、伪分布式环境转换为HA集群环境
hadoop 的基础环境增强 HA模式 HA是为了保证我们的业务 系统 7 *24 的连续的高可用提出来的一种解决办法,现在hadoop当中的主节点,namenode以及resourceManager ...
- Hadoop - 操作练习之单机配置 - Hadoop2.8.0/Ubuntu16.04
系统版本 anliven@Ubuntu1604:~$ uname -a Linux Ubuntu1604 4.8.0-36-generic #36~16.04.1-Ubuntu SMP Sun Feb ...
- 在CentOS7下搭建Hadoop2.9.0集群
系统环境:CentOS 7 JDK版本:jdk-8u191-linux-x64 MYSQL版本:5.7.26 Hadoop版本:2.9.0 Hive版本:2.3.4 Host Name Ip User ...
随机推荐
- PHP全栈学习笔记27
数组概述,类型,声明,遍历,输出,获取数组中最后一个元素,删除重复数组,获取数组中指定元素的键值,排序,将数组中的元素合成字符串. 数组概述,数组是存储,管理和操作一组变量. 数组类型为一维数组,二维 ...
- CSS绘制三角形—border法
1. 实现一个简单的三角形 使用CSS盒模型中的border(边框)即可实现如下所示的三角形: CSS实现简单三角形 实现原理: 首先来看在为元素添加border时,border的样子:假设有如下 ...
- python3 各种编码转换
在做CTF密码题时很大的坑点就在编码,中间有一个弄错就出不来结果.正好python在这块比较坑,记录一下.以下是各种需求对应的输出: 1. 字符串转16进制ascii码串: txt='ABC' new ...
- bash常用的快捷键
bash常用快捷键 快捷键 作用 CTRL+A 把光标移动到命令行开头.如果我们输入的命令过长,则在想要把光标移动到命令行开头时使用 CTRL+E 光标移动到命令行行尾 CTRL+C 强制中止当前命令 ...
- REST和SOAP的区别
转自:https://www.cnblogs.com/MissQing/p/7240146.html REST似乎在一夜间兴起了,这可能引起一些争议,反对者可以说REST是WEB诞生之始甚而是HTTP ...
- Go -- this user requires mysql native password authentication 错误
this user requires mysql native password authentication 在连接mysql的url上加上?allowNativePasswords=true,这次 ...
- Flutter移动电商实战 --(51)购物车_Provide中添加商品
新加provide的cart.dart页面 引入三个文件.开始写provide类.provide需要用with 进行混入 从prefs里面获取到数据,判断有没有数据,如果有数据就返转正List< ...
- IO之Socket网络编程
一.Socket Socket不是Java中独有的概念,而是一个语言无关标准.任何可以实现网络编程的编程语言都有Socket. 1,Socket概念 网络上的两个程序通过一个双向的通信连接实现数据的交 ...
- python 中的 [-1::1] 啥意思
取倒数第一个
- [Java复习] 多线程 并发 JUC 补充
线程安全问题? 当多个线程共享同一个全局变量,做写的操作时,可能会受到其他线程的干扰.读不会发生线程安全问题. -- Java内存模型. 非静态同步方法使用什么锁? this锁 静态同步方法使用什么 ...