TF-IDF算法与余弦相似性
(注:本文转载自阮一峰老师的博文,原文地址:http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html)
今天,我们再来研究另一个相关的问题。有些时候,除了找到关键词,我们还希望找到与原文章相似的其他文章。比如,"Google新闻"在主新闻下方,还提供多条相似的新闻。

为了找出相似的文章,需要用到"余弦相似性"(cosine similiarity)。下面,我举一个例子来说明,什么是"余弦相似性"。
为了简单起见,我们先从句子着手。
句子A:我喜欢看电视,不喜欢看电影。
句子B:我不喜欢看电视,也不喜欢看电影。
请问怎样才能计算上面两句话的相似程度?
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
第一步,分词。
句子A:我/喜欢/看/电视,不/喜欢/看/电影。
句子B:我/不/喜欢/看/电视,也/不/喜欢/看/电影。
第二步,列出所有的词。
我,喜欢,看,电视,电影,不,也。
第三步,计算词频。
句子A:我 1,喜欢 2,看 2,电视 1,电影 1,不 1,也 0。
句子B:我 1,喜欢 2,看 2,电视 1,电影 1,不 2,也 1。
第四步,写出词频向量。
句子A:[1, 2, 2, 1, 1, 1, 0]
句子B:[1, 2, 2, 1, 1, 2, 1]
到这里,问题就变成了如何计算这两个向量的相似程度。
我们可以把它们想象成空间中的两条线段,都是从原点([0, 0, ...])出发,指向不同的方向。两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合;如果夹角为90度,意味着形成直角,方向完全不相似;如果夹角为180度,意味着方向正好相反。因此,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
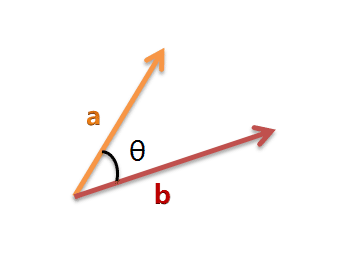
以二维空间为例,上图的a和b是两个向量,我们要计算它们的夹角θ。余弦定理告诉我们,可以用下面的公式求得:
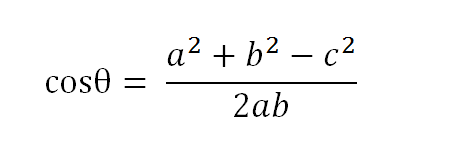
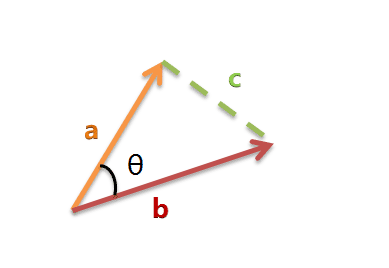
假定a向量是[x1, y1],b向量是[x2, y2],那么可以将余弦定理改写成下面的形式:
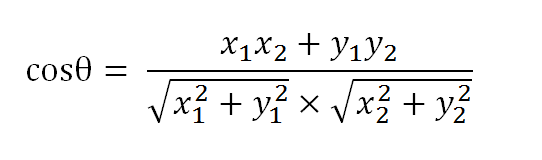
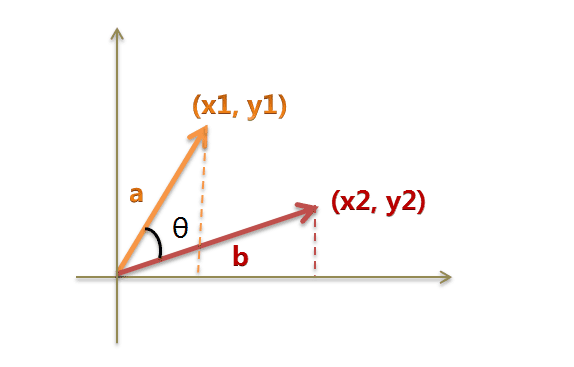
数学家已经证明,余弦的这种计算方法对n维向量也成立。假定A和B是两个n维向量,A是 [A1, A2, ..., An] ,B是 [B1, B2, ..., Bn] ,则A与B的夹角θ的余弦等于:
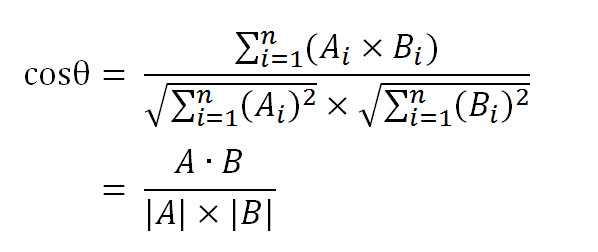
使用这个公式,我们就可以得到,句子A与句子B的夹角的余弦。
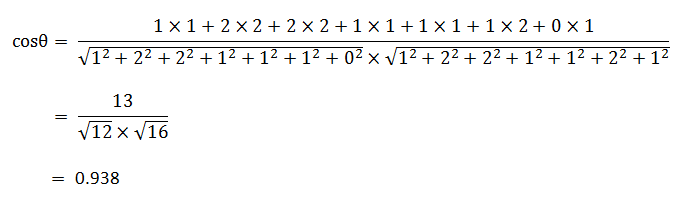
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。所以,上面的句子A和句子B是很相似的,事实上它们的夹角大约为20.3度。
由此,我们就得到了"找出相似文章"的一种算法:
(1)使用TF-IDF算法,找出两篇文章的关键词;
(2)每篇文章各取出若干个关键词(比如20个),合并成一个集合,计算每篇文章对于这个集合中的词的词频(为了避免文章长度的差异,可以使用相对词频);
(3)生成两篇文章各自的词频向量;
(4)计算两个向量的余弦相似度,值越大就表示越相似。
"余弦相似度"是一种非常有用的算法,只要是计算两个向量的相似程度,都可以采用它。
TF-IDF算法与余弦相似性的更多相关文章
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
- 55.TF/IDF算法
主要知识点: TF/IDF算法介绍 查看es计算_source的过程及各词条的分数 查看一个document是如何被匹配到的 一.算法介绍 relevance score算法,简单来说 ...
- Elasticsearch由浅入深(十)搜索引擎:相关度评分 TF&IDF算法、doc value正排索引、解密query、fetch phrase原理、Bouncing Results问题、基于scoll技术滚动搜索大量数据
相关度评分 TF&IDF算法 Elasticsearch的相关度评分(relevance score)算法采用的是term frequency/inverse document frequen ...
- tf–idf算法解释及其python代码
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- 25.TF&IDF算法以及向量空间模型算法
主要知识点: boolean model IF/IDF vector space model 一.boolean model 在es做各种搜索进行打分排序时,会先用boolean mo ...
- Elasticsearch学习之相关度评分TF&IDF
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度 Elasticsearch使用的是 term frequency/inverse doc ...
- 基于TF/IDF的聚类算法原理
一.TF/IDF描述单个term与特定document的相关性TF(Term Frequency): 表示一个term与某个document的相关性. 公式为这个term在document中出 ...
- 信息检索中的TF/IDF概念与算法的解释
https://blog.csdn.net/class_brick/article/details/79135909 概念 TF-IDF(term frequency–inverse document ...
随机推荐
- 34 | 到底可不可以使用join?
在实际生产中,关于 join 语句使用的问题,一般会集中在以下两类: 我们 DBA 不让使用 join,使用 join 有什么问题呢? 如果有两个大小不同的表做 join,应该用哪个表做驱动表呢? 今 ...
- MongoDB 副本集的常用操作及原理
本文是对MongoDB副本集常用操作的一个汇总,同时也穿插着介绍了操作背后的原理及注意点. 结合之前的文章:MongoDB副本集的搭建,大家可以在较短的时间内熟悉MongoDB的搭建和管理. 下面的操 ...
- Python学习之--基础语法
一.定义 Python 是一种解释型.面向对象.动态数据类型的高级程序设计语言. 二.Python变量的命名规则 1. 变量名只能包含字母.数字和下划线: 2. 变量名不能包含空格: 3. 不要将Py ...
- Turn Off Windows Firewall Using PowerShell and CMD
If you want to turn off the Windows Firewall, there are three methods. One is using the GUI which is ...
- dashucoding记录2019.6.8
WordPress网站 网址: https://cn.wordpress.org/ 阿里云市场 https://market.aliyun.com/products/53616009?spm=a2c4 ...
- 【解决方案】SpringCloud项目优雅发版、部署
背景 SpringCloud分布式项目,部署在多个节点上.一般的发版方式是,使用Kill -15 pid,逐一地关闭.部署.重启. 但中间涉及到一个问题,当执行kill命令时,服务虽然关闭,但Eure ...
- 【零基础】使用Tensorflow实现神经网络
一.序言 前面已经逐步从单神经元慢慢“爬”到了神经网络并把常见的优化都逐个解析了,再往前走就是一些实际应用问题,所以在开始实际应用之前还得把“框架”翻出来,因为后面要做的工作需要我们将精力集中在业务而 ...
- [RK3399] 虚拟按键栏显示不全或者方向不对
CPU:RK3399 系统:Android 7.1 同样的系统代码,换了一个小分辨率的屏,虚拟按键栏就出现显示不全,而且方向不对 出现这种问题的原因是显示密度和屏不匹配,需要适当的降低显示密度即可 d ...
- Fiddler自动响应AutoResponder正则匹配
AutoResponder-Add-Rule Editor 两个文本框,先说第一个: Mathes: 前缀为“EXACT:”表示完全匹配(大小写敏感) 无前缀表示基本搜索,表示搜索到字符串就匹配 前缀 ...
- MAC常用快捷键 基本常用的都整理在这里了
写在前面Mac系统中有几个比较特殊的功能键,和Win系统的区别也主要在这里比如在Win系统中我们常用的Ctrl键,在Mac系统中对应的不是长得比较像的Cnotrol,而是Command键,貌似也是Ma ...