使用Keras训练神经网络备忘录
文章太长,放个目录:
1.优化函数的选择
先写结论,后面再补上每个优化函数的详细解释:
- 如果你的数据很稀疏,那应该选择有自适应性的优化函数。并且你还可以减少调参的时间,用默认参数取得好的结果。
- RMSprop是adagrad的一个拓展,旨在解决它提前结束的问题。
- 而RMSprop和Adadelta类似,只是adadelta采用了RMS的方法更新参数。
- 在RMSprop基础上增加了偏差校正和momentum,形成了Adam。
- 综上,RMSprop、Adadelta、Adam都是类似的。
- Kingma【Kingma, D. P., & Ba, J. L. (2015). Adam: a Method for Stochastic Optimization. International Conference on Learning Representations, 1–13.】的实验表示,偏差校正使得Adam在优化到后面梯度变的稀疏的时候使得其优化性能最好。
- 所以,可能Adam是最好的优化函数。
- 所以,如果你希望你的训练能变的更快,或者你要训练的是一个复杂的深度的网络,尽量选择自适应的优化函数。
摘自:深度学习各种优化函数详解
2.损失函数的选择
编译模型必须的两个参数之一:
model.compile(loss='mean_squared_error', optimizer='sgd')
- from keras import losses
- model.compile(loss=losses.mean_squared_error, optimizer='sgd')
2.2常用的损失函数
mean_squared_error或mse
mean_absolute_error或mae
mean_absolute_percentage_error或mape
mean_squared_logarithmic_error或msle
squared_hinge
hinge
categorical_hinge
logcosh
categorical_crossentropy:亦称作多类的对数损失,注意使用该目标函数时,需要将标签转化为形如(nb_samples, nb_classes)的二值序列
sparse_categorical_crossentropy:如上,但接受稀疏标签。注意,使用该函数时仍然需要你的标签与输出值的维度相同,你可能需要在标签数据上增加一个维度:np.expand_dims(y,-1)
binary_crossentropy:(亦称作对数损失,logloss)
kullback_leibler_divergence:从预测值概率分布Q到真值概率分布P的信息增益,用以度量两个分布的差异
poisson:即(predictions - targets * log(predictions))的均值
cosine_proximity:即预测值与真实标签的余弦距离平均值的相反数
注:当使用”categorical_crossentropy”作为目标函数时,标签应该为多类模式,即one-hot编码的向量,而不是单个数值. 可以使用工具中的to_categorical函数完成该转换.示例如下:
- from keras.utils.np_utils import to_categorical
- categorical_labels = to_categorical(int_labels, num_classes=None)
2.2自定义函数
keras的Losses部分的源码是这样的:

可以看出,每次计算loss时,会传给损失函数两个值,一个是正确的标签(y_true),一是模型预测的标签(y_pred),这两个值是shape相同的Theano/TensorFlow张量,根据这一规则,可以设计自己的损失函数.
2.1实践
(1)基本用法
自定义一个,对真实和预测的差距求4次方的损失函数:
- #自定义损失函数
- def myloss(pred,true):
- result = np.power(pred-true,4)
- return result.mean()
- #编译模型
- model.compile(optimizer='adam',loss=myloss)
(2)实际例子
使用one hot分类时,拟合one hot分布的同时,还你拟合均匀分布
自定义的函数是:
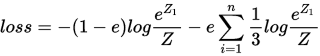
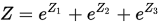
实际用keras是这样的:
- #自定义损失函数
- def mycrossentropy(y_true, y_pred, e=0.1):
- return (1-e)*K.categorical_crossentropy(y_pred,y_true) + e*K.categorical_crossentropy(y_pred, K.ones_like(y_pred)/nb_classes)
- #编译模型
- model.compile(optimizer='adam', loss=mycrossentropy)
2.2将损失函数自定义为网络层
使用均方差和KL散度定义损失函数
- class CustomVariationalLayer(Layer):
- def __init__(self, **kwargs):
- self.is_placeholder = True
- super(CustomVariationalLayer, self).__init__(**kwargs)
- def vae_loss(self, x, x_decoded_mean):
- xent_loss = original_dim * metrics.binary_crossentropy(x, x_decoded_mean)#Square Loss
- kl_loss = - 0.5 * K.sum(1 + z_log_var - K.square(z_mean) - K.exp(z_log_var), axis=-1)# KL-Divergence Loss
- return K.mean(xent_loss + kl_loss)
- def call(self, inputs):
- x = inputs[0]
- x_decoded_mean = inputs[1]
- loss = self.vae_loss(x, x_decoded_mean)
- self.add_loss(loss, inputs=inputs)
- # We won't actually use the output.
- return x
- y = CustomVariationalLayer()([x, x_decoded_mean])
- vae = Model(x, y)
- vae.compile(optimizer='rmsprop', loss=None)
例子来源Keras自定义Loss函数
3.模型的保存
3.1同时保存结构和权重
官方保持模型的API是这样的:
def save_model(model, filepath, overwrite=True, include_optimizer=True)
调用这个函数保持的内容包括:
- 模型的结构
- 模型的权重
- 优化器的状态(即保存时优化器的状态,一遍后面从该状态出发继续训练)
- from keras.models import load_model
- #保持模型
- model.save('my_model.h5')
- #载入模型
- model = load_model('my_model.h5')
3.2模型结构的保存
如果只希望保持模型结构,可以使用以下方法保存和重建.
- # save as JSON
- json_string = model.to_json()
- # save as YAML
- yaml_string = model.to_yaml()
- # model reconstruction from JSON:
- from keras.models import model_from_json
- model = model_from_json(json_string)
- # model reconstruction from YAML
- model = model_from_yaml(yaml_string)
3.3模型权重的保存
如果只希望保持权重,可以使用以下方法保持和载入.
- model.save_weights('my_model_weights.h5')
- model.load_weights('my_model_weights.h5')
3.5选择网络层载入
- """
- 假如原模型为:
- model = Sequential()
- model.add(Dense(2, input_dim=3, name="dense_1"))
- model.add(Dense(3, name="dense_2"))
- ...
- model.save_weights(fname)
- """
- # new model
- model = Sequential()
- model.add(Dense(2, input_dim=3, name="dense_1")) # will be loaded
- model.add(Dense(10, name="new_dense")) # will not be loaded
- # load weights from first model; will only affect the first layer, dense_1.
- model.load_weights(fname, by_name=True)
摘自:如何保存Keras模型
4.训练历史的保存
4.1检测运行过程的参数
深度学习像炼丹一样,有时候看见出现了仙丹(非常好的训练结果),但是忘记保持了,之后再怎么训练也找不回曾经的那个 点.有没有有一种机制,检测训练过程中的参数,如果结果比前一次好,我就保存模型权重下来呢?
有的,官方提供回调函数检测训练参数.
定义好检测的参数和保存的格式,就可以将回调函数写到训练函数的callbacks即可:
- Checkpoint = keras.callbacks.ModelCheckpoint(
- 'Train_record/{epoch:02d}.{val_acc:.2f}.V0.hdf5',
- monitor='val_loss',
- verbose=1,
- save_best_only=True,
- save_weights_only=False,
- mode='auto',
- period=1)
- history = model.fit([train_X_lstm,train_X_resnet],train_y,verbose=1,epochs=150,batch_size=256,validation_data=([vali_X_lstm,vali_X_resnet],vali_y),shuffle=True,callbacks=[Checkpoint])
回调函数Checkpoint设置:
filepath:保存模型的路径,你可以按照上面的方式自定义你的文件名,很直观
monitor: 被监测的数据,训练历史必须包含改值,比如:如果你的训练过程没有设置验证集,就无法检测val_acc
save_best_only:每次是否保存当前的最佳模型
mode:auto, min, max} 的其中之一。 如果 save_best_only=True,那么是否覆盖保存文件的决定就取决于被监测数据的最大或者最小值。 对于 val_acc,模式就会是 max,而对于 val_loss,模式就需要是 min.
save_weights_only: 如果 True,那么只有模型的权重会被保存 (model.save_weights(filepath)), 否则的话,整个模型会被保存 (model.save(filepath))。
period: 每个检查点之间的间隔(训练轮数
4.2保持训练过程得到的所有数据
这里的所有数据是指model.fit()返回的所有数据,包括acc(训练准确度),loss(训练损失),如果指定了验证集,还会有val_acc(验证集准确度),val_loss(训练集损失).保持方法是在训练完成后写入到文件中:
- history=model.fit(train_set_x,train_set_y,batch_size=256,shuffle=True,nb_epoch=nb_epoch,validation_split=0.1)
- with open('train_history.txt','w') as f:
- f.write(str(history.history))
5.陷阱:validation_split与shuffle
模型训练时,有一个参数可以从训练集抽取一定比例的数据做验证,这个参数是validation_split.
训练过程抽取训练数据的10%作验证
history = model.fit([train_X_lstm,train_X_resnet],train_y,verbose=1,epochs=150,batch_size=256,validation_split=0.1,shuffle=True,callbacks=[Checkpoint])
但是使用这个参数时,必须注意先对数据Shuffle,据说是因为validation_split只抽取训练集的后面10%数据作验证,如果你前面的数据没有打乱,这样抽取是可能只抽取到一个类别的样本,这样的验证集将没有意义.
所以,使用这个参数前,先将训练数据(标签同步)打乱.
例外需要关注的是:validation_split划分出来的验证集是固定的,不随每次epoch变化
使用Keras训练神经网络备忘录的更多相关文章
- 使用Keras开发神经网络
一.使用pip安装好tensorflow 二.使用pip安装好Keras 三.构建过程: 1 导入数据 2 定义模型 3 编译模型 4 训练模型 5 测试模型 6 写出程序 1.导入数据 使用皮马人糖 ...
- 使用Google Colab训练神经网络(二)
Colaboratory 是一个 Google 研究项目,旨在帮助传播机器学习培训和研究成果.它是一个 Jupyter 笔记本环境,不需要进行任何设置就可以使用,并且完全在云端运行.Colaborat ...
- 用Keras搭建神经网络 简单模版(六)——Autoencoder 自编码
import numpy as np np.random.seed(1337) from keras.datasets import mnist from keras.models import Mo ...
- keras人工神经网络构建入门
//2019.07.29-301.Keras 是提供一些高度可用神经网络框架的 Python API ,能帮助你快速的构建和训练自己的深度学习模型,它的后端是 TensorFlow 或者 Theano ...
- stanford coursera 机器学习编程作业 exercise4--使用BP算法训练神经网络以识别阿拉伯数字(0-9)
在这篇文章中,会实现一个BP(backpropagation)算法,并将之应用到手写的阿拉伯数字(0-9)的自动识别上. 训练数据集(training set)如下:一共有5000个训练实例(trai ...
- 机器学习入门15 - 训练神经网络 (Training Neural Networks)
原文链接:https://developers.google.com/machine-learning/crash-course/training-neural-networks/ 反向传播算法是最常 ...
- keras训练cnn模型时loss为nan
keras训练cnn模型时loss为nan 1.首先记下来如何解决这个问题的:由于我代码中 model.compile(loss='categorical_crossentropy', optimiz ...
- 怎么选取训练神经网络时的Batch size?
怎么选取训练神经网络时的Batch size? - 知乎 https://www.zhihu.com/question/61607442 深度学习中的batch的大小对学习效果有何影响? - 知乎 h ...
- pytorch1.0批训练神经网络
pytorch1.0批训练神经网络 import torch import torch.utils.data as Data # Torch 中提供了一种帮助整理数据结构的工具, 叫做 DataLoa ...
随机推荐
- Mybatis动态sql及分页、特殊符号
目的: mybatis动态sql(案例:万能查询) 查询返回结果集的处理 mybatis的分页运用 mybatis的特殊符号 mybatis动态sql(案例:万能查询) 根据id查询 模糊查询 (参数 ...
- io.lettuce.core.protocol.ConnectionWatchdog - Reconnecting, last destination was ***
一.问题 redis起来后一直有重连的日志,如下图: 二.分析 参考lettuce-core的github上Issues解答https://github.com/lettuce-io/lettuce- ...
- k8s安装ingress
1. 环境准备 安装nginx-ingress-controller和backend cd /etc/yum.repos.d/mainfests 下载镜像的脚本 vi ingressnginx.sh ...
- 13 个 JS 数组精简技巧
来自 https://juejin.im/post/5db62f1bf265da4d560906ab 侵删 数组是 JS 最常见的一种数据结构,咱们在开发中也经常用到,在这篇文章中,提供一些小技巧,帮 ...
- MySql数据库操作之数据约束
首先数据库的外键是数据库提供的一种完整性约束.在许多数据库的书上也会介绍到,然而对于外键这个完整性性约束究竟应该在数据库端实现,还是在项目业务端实现很多人有着不同的意见. 个人开发(小型应用).数据库 ...
- stm32和sd卡
SD卡从容量上讲分两种:标准容量和大容量,最小的是标准容量,小于等于2G 其中的访问关系如下: SD卡分为两种模式:认证模式和传输模式,每一个模式包含着不同的状态,如下 以下主要讲其初始化过程: SD ...
- 什么是软件工具开发包(SDK)
开发一个软件,需要经过编辑.编译.调试.运行几个过程. 编辑:使用编程语言编写程序代码的过程. 编译:将编写的程序进行翻译. 调试:程序不可能一次性编写成功,编写过程中难免会出现语法.语义上的错误,调 ...
- 18C 新的发行版和补丁模型
18C 新的发行版和补丁模型 以后不再会有第一和第二个发行版,如12.1,12.2,以后只有18C,19C,20C 这样的发行版. 更少的One-Off 补丁 澄清1:版本家族 从生命周期支持上来说1 ...
- git命令——git status、git diff
前言 当对项目做了更改时,我们通常需要知道具体改了哪些文件,哪些文件更改了没有暂存,哪些文件改了并且已加入到暂存区等待下次commit.上述任务使用git status都可以帮我们解决.但是想要知道文 ...
- 剖析可执行文件ELF组成
对比参考:剖析.o文件ELF组成 相比.o的ELF格式,有哪些变化? .rel.text和.rel.data消失了 为什么这两个节会消失? 链接器将各.o中同名的.text和.data节整合到一起时, ...