深入理解hive基础学习
Hive 是什么?
1.Hive 是基于 Hadoop处理结构化数据的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类 SQL 查询功能。
2.Hive 利用 HDFS 存储数据,利用MapReduce 查询分析数据。本质是将 SQL 转换为 MapReduce 程序,比直接用 MapReduce 开发效率更高。 Hive通常是存储在关系数据库如 mysql/derby 中。 Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
3.Hive 与传统 DB 的区别?
3.1从本质上讲hive底层是依赖于HDFS和mapreduce,而传统的数据库是依赖于本地文件系统和本设备,这就决定了hive是用mapreduce操作的HDFS数据。
3.2hive不是关系式数据库,不适合OLTP在线事务处理是延迟性很高的操作,不适合实时查询和行级更新。存储数据在关系型数据库中,使用的语言是HQL
3.3传统数据库: OLTP-->面向事务(Transaction) 操作型处理 就是关系型数据库: mysql,oracle sqlserver db2 主要是支持业务,面向业务。
Hive: OLAP-->面向分析(Analytical)分析型处理 就是数据仓库 ,面对的是历史数据(历史数据中的一部分就来自于数据库) 开展分析
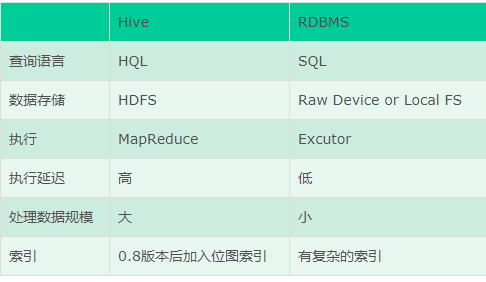
4.1传统数据库表的模式是写时模式,在加载数据时强制确定的,如果数据不符合模式,数据会被拒绝加载;而hive是读时模式,对数据的验证并不在加载数据时进行,而是在查询的时候进行,但是读时模式加载数据时非常迅速的。
hive体系机构:
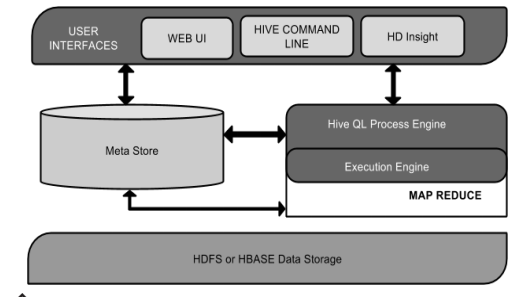
- CLI:命令行方式
- JDBC/ODBC:通过类似于MySQL接口的方式进行访问
- Web GUI:通过HTTP页面进行访问。
2.metastore是Hive元数据的集中存放地,metastore分为两个部分:服务和后台的数据存储
HIVE支持的数据类型
INT,TINYINT/SMALLINT/BIGINT,BOOLEAN,FLOAT,,DOUBLE,STRING ,BINARY,TIMESTAMP,ARRAY, MAP, STRUCT, UNION,DECIMAL
HIVE内部表和外部表
hive创建的表有两种,内部表和外部表,默认情况下是创建内部表,将表直接放入他自己的仓库目录,而这两种表的区别主要是在LOAD和DROP表的语义上面;
对于内部表的创建表并且加载数据表的操作HQL语句:
create table manage_table(id int,name string ,age int); //创建表
load data inpath '/user/centos/data.txt' into table manage_table ;//把hdfs://user/centos/data.txt 移动到hive 的 manae_tables表的仓库目录下面,即是hdfs://user/hive/warehouse/manage_table的目录下面
我们都知道,加载操作就是对文件系统中的文件进行移动或者重命名,因此速度回非常的快,即是是内部表,hive也不检查目录中的文件是否符合要加载的文件是否符合我们所声明的表的模式,如果有数据或者模式不匹配,我们只会在查询阶段进行检查。
对于内部表的删除表的操作HQL语句:
drop table manage_table,这个表包括他的元数据和数据会被一起进行删除,因此在这里要强调一点:对于内部表而言,load是移动操作,而drop是移动操作会使得数据彻底丢失。
对于外部表而言,创建表和加载数据:
create external table external_table(id int ,name string,age int); //创建外部表
load data inpath '/user/centos/data.txt' into table external table;
这个地方要强调一点:在加入了external关键字之后,hive知道数据并不是由自己来进行管理的,不会把数据移动到自己的仓库目录的下面,drop table manage_table,这个表的数据存储在外部,删除的时候数据不会被删除
hive分区和桶
1.(hive的优化手段之一)分区表:在hive表中,表的每一个分区对应一个目录,从,目录的层面上来控制数据的搜索范围
$hive>create table t3(id int ,name string,age int) partitioned by (year int ,month int) row format delimited fields terminated ',';//创建分区表
$hive>alter table t3 add partition(year=2014,month=11) partition(year=2014,mont=12);//在创建分区表之后要记住添加分区,分区表首先创建表,再添加分区,最后再加载数据
load data local inpath '/home/centos/customers.txt' into table t3;//在分区表中加载数据
$hive>show partitions t3 ;
2.桶表,对应的是文件,桶表的优点在于hash(),按照某一值进行hash分桶,桶是在存储文件的层面上进行过滤,然后在桶里进行搜索就可以很快找到对应的值了。
对于桶表的数量,我们首先应该评估数据量,保证每个桶的数量是blocksize大小的两倍
create table(id int,name string ,age int) clustered by (id) into 3 buckets row format delimited fields terminated by ',' stored as textfile; //创建桶表
load data local inpath '/home/centos/customers.txt' into table t4;//加载数据到桶表,按照hash来存储到不同的文件中,但是这个地方要注意,加载数据不会进行分桶的操作
insert into t4 select id,name,age from t3;//查询t3表的数据插入到表t4中去,这个地方分了3个桶,桶表的
hive常规操作
1.进入到hive命令行:$>hive;
2.创建表$hive>create table t(in int,name string,age int);
3.插入数据:insert into table(id int ,name string,age int) values(1,'tom',23);//这个插入操作会启用一个mr,在工作中,导入数据的方式一般是通过load data 的方式来进行
通过远程
4.使用jdbc的方式连接到hive数据仓库:
package com.it18zhang.hiveDemo;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement; /**
* 使用jdbc方式连接到hive数据仓库,数据仓库需要开启hiveserver2服务
*/
public class App {
public static void main(String[] args) throws Exception {
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection conn = DriverManager.getConnection("jdbc:hive2://192.168.49.200:10000/mydb1");
Statement st = conn.createStatement();
ResultSet rs = st.executeQuery("select id ,name,age from t");
while(rs.next()){
System.out.println(rs.getInt(1)+","+rs.getString(2));
}
rs.close();
st.close();
conn.close();
}
}
5.hive常用命令:
$hive>create table if not exists t2(id int,name string ,age int ) row format delimited fields terminated by ',' stored as txtfiles//建内部表
$hive>desc formatted t2//查看表
$hive>load data local inpath '/home/centos/customers.txt' into table t2;//从本地文件系统添加数据到表中,hive通过本地文件来加载,是把文件上传到hdfs文件系统中来,在hive表的目录下面
$hive>dfs -rmr /user/hive/warehouse/mydb2.db/t2/customers.txt; //从hdfs文件系统删除表,表在被删除之后,在hive中不再能查找出数据了
$hive>load data inpath '/user/centos/customers.txt' into table t2 ; //从hdfs文件系统移动文件道表中来
$hive>dfs -put /home/centos/customers.txt /user/centos/customers.txt //将本地文件系统的文件上传到hdf文件系统下面
$hive>create table t3 as select *from t2 ; //复制表操作,携带数据和表结构,经过mr
$hive>create table t4 like t2 ; //复制表操作,不带数据,只带表结构
$hive> select count(*) from t2;//聚集函数查询,需要转mr
$hive>select * from t2 order by id desc ; //这个操作需要先将表内的数据进行聚集,然后进行排序,需要转成mr
6.连接查询也需要开启mr
7.单词统计
$hive> select t.word,count(*) c from ((select explode(split(line, ' ')) as word from doc) as t) group by t.word order by c desc limit 2 ;
8.导出表的操作:$hive>export table customers '/user/centos/temp.txt' //导出数据和表结构
9.order是进行全排序,sort是进行map端的排序并且也是本地有序的
深入理解hive基础学习的更多相关文章
- Hive基础学习
Hive 学习记录Hive介绍:Hive 是起源于Facebook,使得Hadoop进行SQL查询成为可能,进而使得非程序员也可以进进行对其使用:它是一种数据仓库工具,将结构化的数据文件 映射为一张数 ...
- 零基础学习hadoop到上手工作线路指导初级篇:hive及mapreduce
此篇是在零基础学习hadoop到上手工作线路指导(初级篇)的基础,一个继续总结.五一假期:在写点内容,也算是总结.上面我们会了基本的编程,我们需要对hadoop有一个更深的理解:hadoop分为h ...
- 零基础学习hadoop到上手工作线路指导初级篇:hive及mapreduce(转)
零基础学习hadoop到上手工作线路指导初级篇:hive及mapreduce:http://www.aboutyun.com/thread-7567-1-1.html mapreduce学习目录总结 ...
- Vue – 基础学习(1):对生命周期和钩子函的理解
一.简介 先贴一下官网对生命周期/钩子函数的说明(先贴为敬):所有的生命周期钩子自动绑定 this 上下文到实例中,因此你可以访问数据,对属性和方法进行运算.这意味着你不能使用箭头函数来定义一个生命周 ...
- C#基础学习之事件的理解和应用
事件的使用和委托类似,也是分四步来实现:声明委托.定义事件.注册事件.调用事件 我们先看一下事件的定义 //定义委托 public delegate void PublishEventHandler( ...
- 【转】Hive 基础之:分区、桶、Sort Merge Bucket Join
Hive 已是目前业界最为通用.廉价的构建大数据时代数据仓库的解决方案了,虽然也有 Impala 等后起之秀,但目前从功能.稳定性等方面来说,Hive 的地位尚不可撼动. 其实这篇博文主要是想聊聊 S ...
- Hive深入学习--应用场景及架构原理
Hive背景介绍 Hive最初是Facebook为了满足对海量社交网络数据的管理和机器学习的需求而产生和发展的.互联网现在进入了大数据时代,大数据是现在互联网的趋势,而hadoop就是大数据时代里的核 ...
- 零基础学习hadoop到上手工作线路指导(中级篇)
此篇是在零基础学习hadoop到上手工作线路指导(初级篇)的基础,一个继续总结. 五一假期:在写点内容,也算是总结.上面我们会了基本的编程,我们需要对hadoop有一个更深的理解: hadoop分为h ...
- Hive基础讲解
一.Hive背景介绍 Hive最初是Facebook为了满足对海量社交网络数据的管理和机器学习的需求而产生和发展的.马云在退休的时候说互联网现在进入了大数据时代,大数据是现在互联网的趋势,而had ...
随机推荐
- Lasso回归总结
Ridge回归 由于直接套用线性回归可能产生过拟合,我们需要加入正则化项,如果加入的是L2正则化项,就是Ridge回归,有时也翻译为岭回归.它和一般线性回归的区别是在损失函数上增加了一个L2正则化的项 ...
- 尚学堂requireJs课程---1、作用域回顾
尚学堂requireJs课程---1.作用域回顾 一.总结 一句话总结: 尚学堂的课程的资料他的官网上面是有的 1.js作用域? ~ js中是函数作用域:局部变量的话要写var关键词 ~ 闭包可以解决 ...
- leetcode-hard-ListNode-23. Merge k Sorted Lists
mycode 91.2% # Definition for singly-linked list. # class ListNode(object): # def __init__(self, x ...
- ModuleNotFoundError: No module named '_sqlite3'的解决办法:pipenv的用法
export PIPENV_VENV_IN_PROJECT=1pipenv --venvpipenv --where pipenv install -r requirements.txtpipenv ...
- Java IO & Serialization
Java IO & Serialization 专为开卷考试准备,内容包括基本的文本文件和二进制文件的读写以及序列化反序列化操作 IO demo package helloworld; imp ...
- Python学习笔记:读取Excel的xlrd模块
一.安装xlrd 可以使用命令行安装也可使用pycharm进行安装 表示xlrd库已经安装成功,安装成功后,我们就可以导入使用了. 二.xlrd说明 (1.单元格常用的数据类型包括 0:empty(空 ...
- openstack部署keystone
环境: 免密钥,域名解析 cat /etc/hosts 192.168.42.120 controller 192.168.42.121 compute 192.168.42.122 storage ...
- AES256位加密
目录 1. 算法简介 2. 算法流程 2.1 扩展密钥 2.2 轮密钥加 2.3 字节代替 2.4 行位移 2.5 列混淆 3. 总结 附录A 运算示例 1.算法简介高级加密标准(英 ...
- Centos 在线安装 nginx
centos 在线安装 nginx 安装nginx 参考文档: http://nginx.org/en/linux_packages.html 中的RHEL/CentOS章节,按照步骤安装repo ...
- C基础知识(12):可变参数
该功能需要使用<stdarg.h>.函数的最后一个参数写成省略号,即三个点号(...),省略号之前的那个参数是int,代表了要传递的可变参数的总数.该文件提供了实现可变参数功能的函数和宏. ...