[CDH] Process data: integrate Spark with Spring Boot
Spark 数据处理
一、Spark 在线计算
可见,从Kafka传来的原始数据做一些“基本的处理后”,再存放如Redis中。
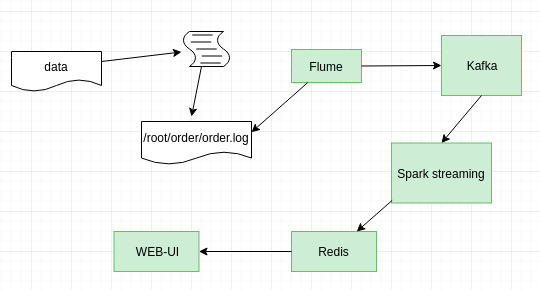
简单统计Kafka流后写入Redis。
/**
* 订单统计、乘车人数统计
*/ object OrderStreamingProcessor {
def main(args: Array[String]): Unit = {
import org.apache.spark._
import org.apache.spark.streaming._ /////////////////////////////////////
// 01.初始化 spark stream & kafka
/////////////////////////////////////
//设置Spark程序在控制台中的日志打印级别
Logger.getLogger("org").setLevel(Level.WARN)
//local[*]使用本地模式运行,*表示内部会自动计算CPU核数,也可以直接指定运行线程数比如2,就是local[2]
//表示使用两个线程来模拟spark集群
val conf = new SparkConf().setAppName("OrderMonitor").setMaster("local[1]")
//初始化Spark Streaming环境
val streamingContext = new StreamingContext(conf, Seconds(1))
//设置检查点
streamingContext.checkpoint("/sparkapp/tmp")
//-------------------------------------------------------------------------------------- val kafkaParams = Map[String, Object](
// "bootstrap.servers" -> "192.168.56.100:6667,192.168.56.110:6667,192.168.56.120:6667",
"bootstrap.servers" -> Constants.KAFKA_BOOTSTRAP_SERVERS,
"key.deserializer" -> classOf[StringDeserializer], //(k,v)
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "test0002",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
// 这里可不是只一个topic哦
val topics = Array(
TopicName.KO_ORDER_TOPIC.getTopicName,
TopicName.DU_ORDER_TOPIC.getTopicName,
TopicName.AN_ORDER_TOPIC.getTopicName
) topics.foreach(println(_))
println("topics:" + topics)
// Kafka创建topics
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
) stream.count().print(); /////////////////////////////////////
// 02.实时统计订单总数
/////////////////////////////////////
val ordersDs = stream.map(record => {
// 主题名称
val topicName = record.topic()
val orderInfo = record.value() // 订单信息解析器
var orderParser: OrderParser = null; // 不同主题的订单进行不同的处理
topicName match {
case "ko_order_topic" => {
orderParser = new HaiKouOrderParser();
}
case "du_order_topic" => {
orderParser = new ChengDuOrderParser()
}
case "an_order_topic" => {
orderParser = new XiAnOrderParser()
}
case _ => {
orderParser = null;
}
}
// 获得解析器 --> 使用其得到解析结果
println("orderParser:" + orderParser)
if (null != orderParser) {
val order= orderParser.parser(orderInfo)
println("parser order:" +order)
order
} else {
null
}
}) // 订单计数,对于每个订单出现一次计数1
val orderCountRest = ordersDs.map(order => {
if (null == order) {
("", 0)
} else if (order.getClass == classOf[ChengDuTravelOrder]) {
(Constants.CITY_CODE_CHENG_DU + "_" + order.createDay, 1)
} else if (order.getClass == classOf[XiAnTravelOrder]) {
(Constants.CITY_CODE_XI_AN + "_" + order.createDay, 1)
} else if (order.getClass == classOf[HaiKouTravelOrder]) {
(Constants.CITY_CODE_HAI_KOU + "_" + order.createDay, 1)
} else {
("", 0)
}
}).updateStateByKey((currValues: Seq[Int], state: Option[Int]) => {
var count = currValues.sum + state.getOrElse(0);
Some(count)
}) /**
* 乘车人数统计, 毕竟“每个订单对应的乘客的人数不同”。
* 如果是成都或者西安的订单,数据中没有乘车人数字段,所有按照默认一单一人的方式进行统计
* 海口的订单数据中有乘车人数字段,就按照具体数进行统计
*/
val passengerCountRest = ordersDs.map(order => {
if (null == order) {
("", 0)
} else if (order.getClass == classOf[ChengDuTravelOrder]) {
(Constants.CITY_CODE_CHENG_DU + "_" + order.createDay, 1)
} else if (order.getClass == classOf[XiAnTravelOrder]) {
(Constants.CITY_CODE_XI_AN + "_" + order.createDay, 1)
} else if (order.getClass == classOf[HaiKouTravelOrder]) {
var passengerCount = order.asInstanceOf[HaiKouTravelOrder].passengerCount.toInt
//scala不支持类似java中的三目运算符,可以使用下面的操作方式
passengerCount = if(passengerCount>0) passengerCount else 1
(Constants.CITY_CODE_HAI_KOU + "_" + order.createDay,passengerCount)
} else {
("", 0)
}
}).updateStateByKey((currValues: Seq[Int], state: Option[Int]) => {
var count = currValues.sum + state.getOrElse(0);
Some(count)
}) orderCountRest.foreachRDD(orderCountRDD=>{
import com.cartravel.util.JedisUtil
val jedisUtil = JedisUtil.getInstance()
val jedis = jedisUtil.getJedis
//从集群中收集统计结果,然后在driver
val orderCountRest = orderCountRDD.collect()
println("orderCountRest:"+orderCountRest)
orderCountRest.foreach(countrest=>{
println("countrest:"+countrest._1+","+countrest._2)
if(null!=countrest){
jedis.hset(Constants.ORDER_COUNT, countrest._1, countrest._2 + "")
}
})
jedisUtil.returnJedis(jedis)
}) passengerCountRest.foreachRDD(passengerCountRdd=>{
import com.cartravel.util.JedisUtil
val jedisUtil = JedisUtil.getInstance()
val jedis = jedisUtil.getJedis val passengerCountRest = passengerCountRdd.collect()
passengerCountRest.foreach(countrest=>{
jedis.hset(Constants.PASSENGER_COUNT, countrest._1, countrest._2 + "")
})
jedisUtil.returnJedis(jedis)
}) //启动sparkstreaming程序
streamingContext.start();
streamingContext.awaitTermination();
streamingContext.stop()
}
}
三、Spark 离线计算
既然是“离线”,数据就可以来源于HBase。
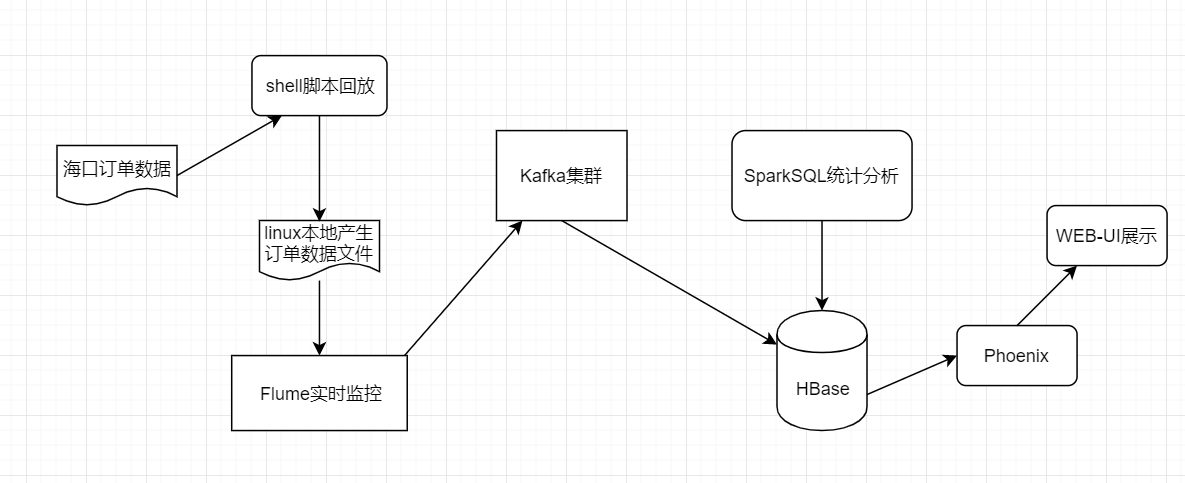
简单统计后挖掘出一些有用的信息,比如如何为“虚拟车站”选址。
/**
* 离线统计虚拟车站
*/
object VirtualStationsProcessor {
//1.创建h3实例
val h3 = H3Core.newInstance //2.经纬度转换成hash值
def locationToH3(lat: Double, lon: Double, res: Int): Long = {
h3.geoToH3(lat, lon, res)
} def main(args: Array[String]): Unit = {
val HTAB_HAIKOU_ORDER = "HTAB_HAIKOU_ORDER"
import org.apache.spark._
//设置Spark程序在控制台中的日志打印级别
Logger.getLogger("org").setLevel(Level.WARN)
//local[*]使用本地模式运行,*表示内部会自动计算CPU核数,也可以直接指定运行线程数比如2,就是local[2]
//表示使用两个线程来模拟spark集群
val conf = new SparkConf().setAppName("Virtual-stations").setMaster("local[1]") val sparkSession = SparkSession
.builder()
.config(conf)
.getOrCreate() //自定义方法
sparkSession.udf.register("locationToH3", locationToH3 _) val hbConf = HBaseConfiguration.create(sparkSession.sparkContext.hadoopConfiguration)
// hbConf.set("hbase.zookeeper.quorum", "10.20.3.177,10.20.3.178,10.20.3.179")
hbConf.set("hbase.zookeeper.quorum", "192.168.52.100,192.168.52.110,192.168.52.120")
hbConf.set("hbase.zookeeper.property.clientPort", "2181") val sqlContext = sparkSession.sqlContext val districtList = new java.util.ArrayList[com.cartravel.util.District]();
val districts: JSONArray = MapUtil.getDistricts("海口市", null);
MapUtil.parseDistrictInfo(districts, null, districtList); //行政区域广播变量(spark开发优化的一个点)
val districtsBroadcastVar = sparkSession.sparkContext.broadcast(districtList) //加载hbase 中的订单数据, 自己要实现HBaseLoader
val order = HBaseLoader.loadData(hbConf, sqlContext, HTAB_HAIKOU_ORDER)
println("订单表数据:")
//上线的时候把这样代码删除掉,影响性能
order.show() //注册临时视图
order.createOrReplaceTempView("order"); //没什么业务功能
val groupRdd = order.rdd.groupBy(row => {
row.getString(1)
}) //在sql语句中使用h3接口进行六边形栅格化
val gridDf = sparkSession.sql(
s"""
|select
|ORDER_ID,
|CITY_ID,
|STARTING_LNG,
|STARTING_LAT,
|locationToH3(STARTING_LAT,STARTING_LNG,12) as h3code
| from order
|""".stripMargin
) println("h3栅格化的数据:")
gridDf.show()
gridDf.createOrReplaceTempView("order_grid") //分组统计
val groupCountDf = gridDf.groupBy("h3code").count().filter("count>=10")
groupCountDf.show() //统计结果注册临时视图
groupCountDf.createOrReplaceTempView("groupcount") //使用sql进行join操作,升序取出最小精度,最小维度的点作为虚拟车站的经纬度位置信息
val groupJoinDf = sparkSession.sql(
s"""
|select
|ORDER_ID,
|CITY_ID,
|STARTING_LNG,
|STARTING_LAT,
|row_number() over(partition by order_grid.h3code order by STARTING_LNG,STARTING_LAT asc) rn
| from order_grid join groupcount on order_grid.h3code = groupcount.h3code
|having(rn=1)
|""".stripMargin) println("==============================================")
groupJoinDf.show() //判断经纬度在哪个行政区域,得到经纬度和行政区域名称的关联关系
val groupJoinRdd = groupJoinDf.rdd
val districtsRdd = groupJoinRdd.mapPartitions(rows => {
var tmpRows = new java.util.ArrayList[Row]()
import org.geotools.geometry.jts.JTSFactoryFinder
val geometryFactory = JTSFactoryFinder.getGeometryFactory(null)
var reader = new WKTReader(geometryFactory) //获取广播变量
val districtList = districtsBroadcastVar.value
// println("districtList:" + districtList)
val wktPolygons = districtList.map(district => {
val polygonStr = district.getPolygon
var wktPolygon = ""
if (!StringUtils.isEmpty(polygonStr)) {
wktPolygon = "POLYGON((" + polygonStr.replaceAll(",", " ").replaceAll(";", ",") + "))"
val polygon: Polygon = reader.read(wktPolygon).asInstanceOf[Polygon]
(district, polygon)
} else {
null
}
}).filter(null != _) while (rows.hasNext) {
val row: Row = rows.next() val lng = row.getAs[String]("STARTING_LNG")
val lat = row.getAs[String]("STARTING_LAT") val wktPoint = "POINT(" + lng + " " + lat + ")";
val point: Point = reader.read(wktPoint).asInstanceOf[Point];
wktPolygons.foreach(polygon => {
//判断经纬度点是否在行政区内
if (polygon._2.contains(point)) {
val fields = row.toSeq.toArray ++ Seq(polygon._1.getName)
tmpRows.add(Row.fromSeq(fields))
}
})
}
Iterator(tmpRows)
}).flatMap(rows => rows) //扁平化 //构造新的schema
var newSchema = groupJoinDf.schema
//schema中添加新的列
newSchema = newSchema.add("DISTRICT_NAME", "string")
//构造新的Df
val districtsDf = sparkSession.createDataFrame(districtsRdd, newSchema) println("虚拟车站数据:")
// districtsDf.show() districtsDf.show(5)
//保存统计数据
HBaseLoader.saveOrWriteData(hbConf, districtsDf, "VIRTUAL_STATIONS")
}
}
Spring Boot+Vue
在线时,数据保持在redis中, WEB如何从redis中读取数据?
离线时,保存虚拟车站的经纬度到hbase表VIRTUAL_STATIONS中,WEB如何从hbase中读取数据?
Spring Boot+Vue从零开始搭建系统(一):项目前端_Vuejs环境搭建
Spring Boot+Vue从零开始搭建系统(二):项目前端_Vuejs目录结构描述
Spring Boot+Vue从零开始搭建系统(三):项目前后端分离_实现简单登录demo
一、前后端分离
DEMO技术栈描述
1.前端技术栈:
.编程语言:html5、js、css
.开发工具:Visual Studio Code
.开发框架:vue + axios
.包管理工具:npm
.打包工具:webpack
2.后端技术栈:
.编程语言:java
.开发工具:Eclipse
.开发框架:spring boot
.包管理工具:gradle构建工具下的maven资源库
.打包工具:gradle
DEMO开发流程概要
1.前端开发流程
.安装nodejs并初始化Vue项目。
.在已初始化的Vue项目中的开发页面头、页面尾公共组件。
.开发登录页面组件。
.开发首页页面组件。
.支持跨域,请求路由,页面路由开发。
.单独运行Vue项目查看效果。
2.后端开发流程
.安装JDK10并配置好JAVA_HOME环境变量.
.初始化springboot项目。
.开发restful控制器。
.支持跨域。
.单独运行后端springboot项目查看效果。
3.运行项目流程
.使用webpack将Vue项目打包。
.将打包的Vue项目集成到springboot项目中。
.使用gradle将springboot打包成jar文件。
.使用jdk运行jar包来启动demo项目服务,请访问地址查看效果。
4.开发过程中注意点
.前端项目由于启用了eslint语法检测,所以有时候多个空格或者少个空格或者少个空行,都会运行不起来前端项目,对应提示信息改下即可。
.前端发送请求的数据格式需要与后端接收请求数据对象格式要约定一致。
.在前后端未集成的时候需要跨域支持。
[CDH] Process data: integrate Spark with Spring Boot的更多相关文章
- Spring Data JPA例子[基于Spring Boot、Mysql]
关于Spring Data Spring社区的一个顶级工程,主要用于简化数据(关系型&非关系型)访问,如果我们使用Spring Data来开发程序的话,那么可以省去很多低级别的数据访问操作,如 ...
- Spring Boot Document Part I
最近准备学习Spring Boot 随便翻一下官方的文档 Part I. Spring Boot Documentation Spirng Boot简短介绍,作为接下来内容的导航,可快速预览本章内容. ...
- spring boot(一):入门篇
构建微服务:Spring boot 入门篇 什么是spring boot Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程.该框 ...
- Spring Boot学习大全(入门)
Spring Boot学习(入门) 1.了解Spring boot Spring boot的官网(https://spring.io),我们需要的一些jar包,配置文件都可以在下载.添置书签后,我自己 ...
- Spring Boot Starters 列表
Spring Boot application starters 名称 描述 Pom spring-boot-starter 核心starter,包括自动配置支持,日志和YAML Pom spring ...
- Spring Boot 技术总结
Spring Boot(一):入门篇 Spring Boot(二):Web 综合开发 Spring Boot(三):Spring Boot 中 Redis 的使用 Spring Boot(四):Thy ...
- 最全spring boot视频系列,你值得拥有
================================== 从零开始学Spring Boot视频 ================================== àSpringBoot ...
- 1.spring boot起步之Hello World【从零开始学Spring Boot】
[视频&交流平台] àSpringBoot视频 http://study.163.com/course/introduction.htm?courseId=1004329008&utm ...
- 0. 前言【从零开始学Spring Boot】
[视频&交流平台] àSpringBoot视频 http://study.163.com/course/introduction.htm?courseId=1004329008&utm ...
随机推荐
- Linux date cal bc和一些快捷键学习
1 date 日期 2 cal 日历 具体每年日历 cal +年份 3 bc 计算器 如果有小数点需要scale命令,scale=数字 quit退出 4 [Tab]按键 :命令补全和档案补 ...
- java--mybatis的实现原理
动态代理? 需要调试下,看下源码,再研究下……
- bind9+dlz+mysql连接断开问题
前言 关于bind-dlz介绍:http://bind-dlz.sourceforge.net/ DLZ(Dynamically Loadable Zones)与传统的BIND9不同,BIND的不足之 ...
- CF827D Best Edge Weight[最小生成树+树剖/LCT/(可并堆/set启发式合并+倍增)]
题意:一张图求每条边边权最多改成多少可以让所有MST都包含这条边. 这题还是要考察Kruskal的贪心过程. 先跑一棵MST出来.然后考虑每条边. 如果他是非树边,要让他Kruskal的时候被选入,必 ...
- list去重的四种方式
L=[1,2,3,3,5,5,5,8,4,6,9,7,2,'a','s','a','e','s','z'] def DelDupli(L): L1=[] for i in L: ...
- python计算余弦复杂度
import numpy as np from sklearn.metrics.pairwise import cosine_similarity a = np.array([1, 2, 3, 4]) ...
- Microsoft.Practices.Unity使用配置文件总是报错The type name or alias could not be resolved.
Type name could not be resolved. Please check config file http://stackoverflow.com/questions/1493564 ...
- ec20 queclocator V1. 0 test
AT+QICSGP=1,1,"UNIWAP","","",1 AT+QIACT=1 AT+QLOCCFG="contextid&q ...
- 洛谷P4979 矿洞:坍塌
洛谷题目链接 珂朵莉树吼啊!!! 又是一道水题,美滋滋~~~ $A$操作完全模板区间赋值 $B$操作也是一个模板查询,具体看代码 注意:读入不要用$cin$,会$T$,如果你是大佬,会玄学东西当我没说 ...
- ubuntu 16.04安装gitlab,然后汉化
1 前期准备 电脑配置:windows7 ,内存8GB以上(因为有4GB左右要分配给虚拟机中的ubuntu) 虚拟机:VBOX Linux系统:ubuntu16.04 64bit 2 Gitlab的搭 ...