CentOS7安装CDH 第七章:CDH集群Hadoop的HA配置
相关文章链接
CentOS7安装CDH 第二章:CentOS7各个软件安装和启动
CentOS7安装CDH 第四章:CDH的版本选择和安装方式
CentOS7安装CDH 第五章:CDH的安装和部署-CDH5.7.0
CentOS7安装CDH 第六章:CDH的管理-CDH5.12
CentOS7安装CDH 第七章:CDH集群Hadoop的HA配置
CentOS7安装CDH 第八章:CDH中对服务和机器的添加与删除操作
1. HDFS的HA配置
1、在HDFS的的服务中点击启动High Availability
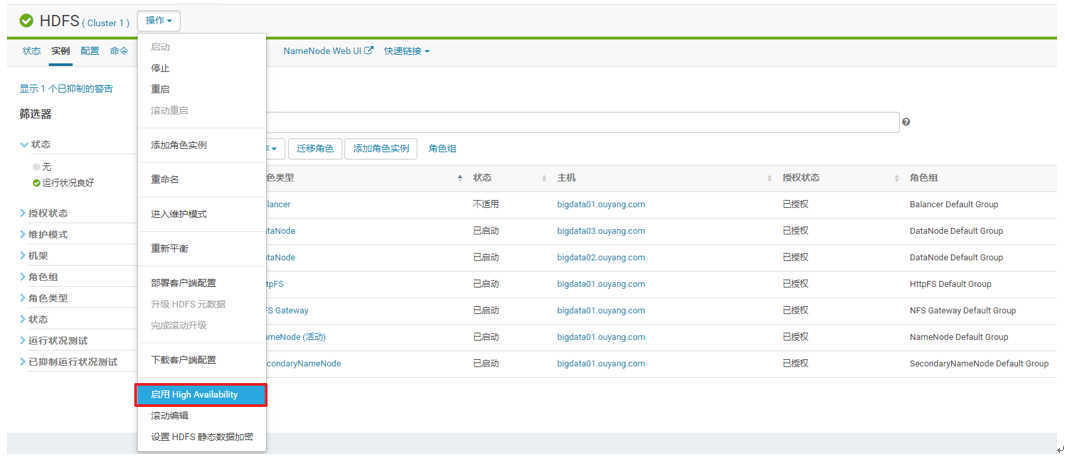
2、设置NameService的名称
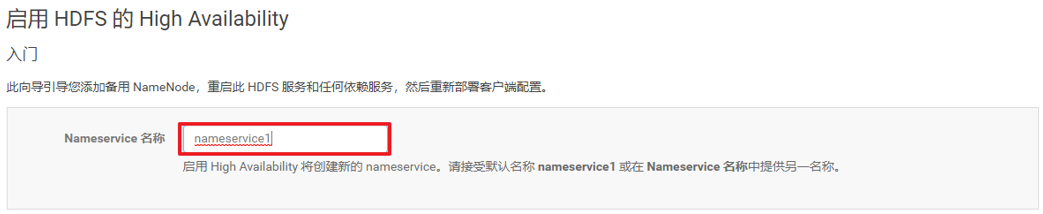
3、分配HDFS的HA所需要的角色
NameNode 主机:nn1 、nn2
JoumalNode 主机:nn1 、nn2 、dn1
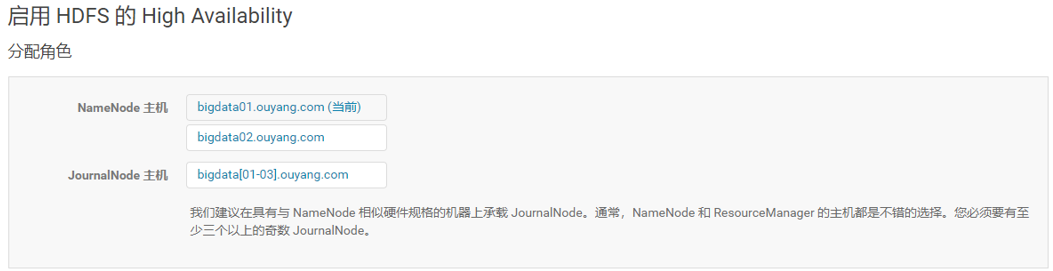
4、审核更改(JournalNode的编辑目录)
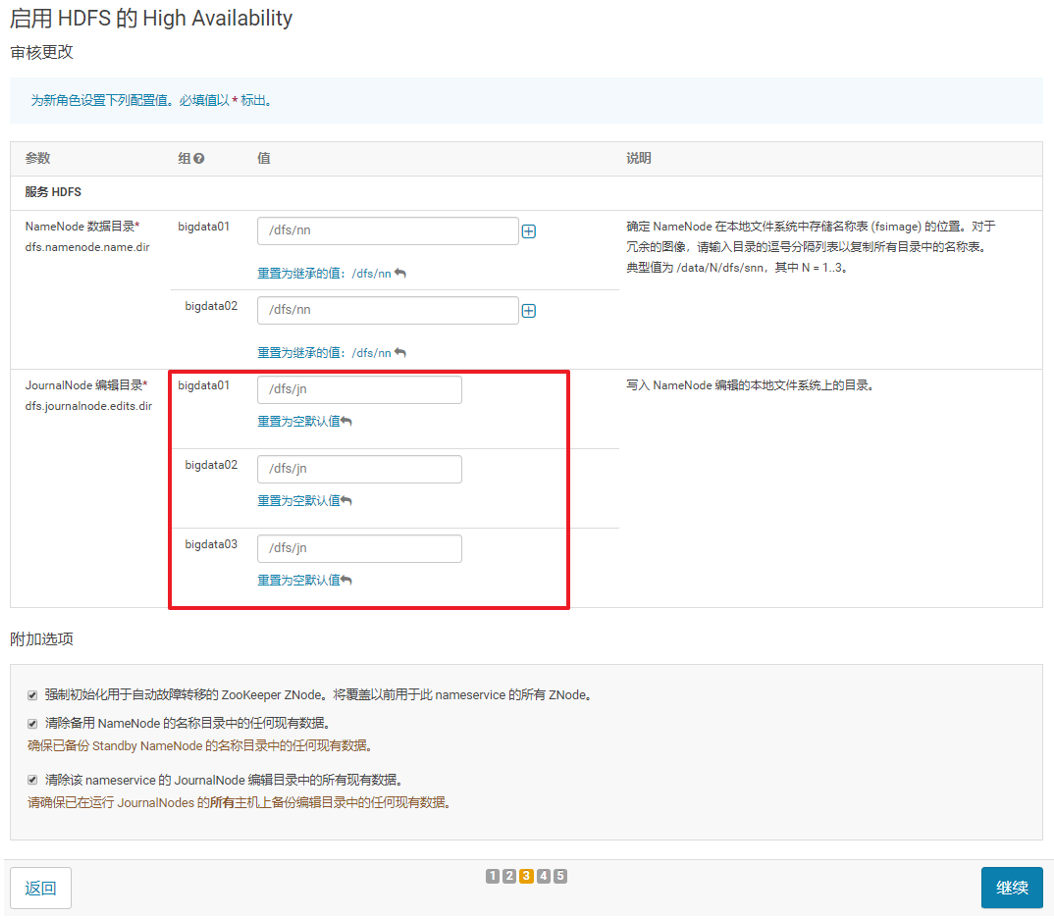
5、安装必要的服务
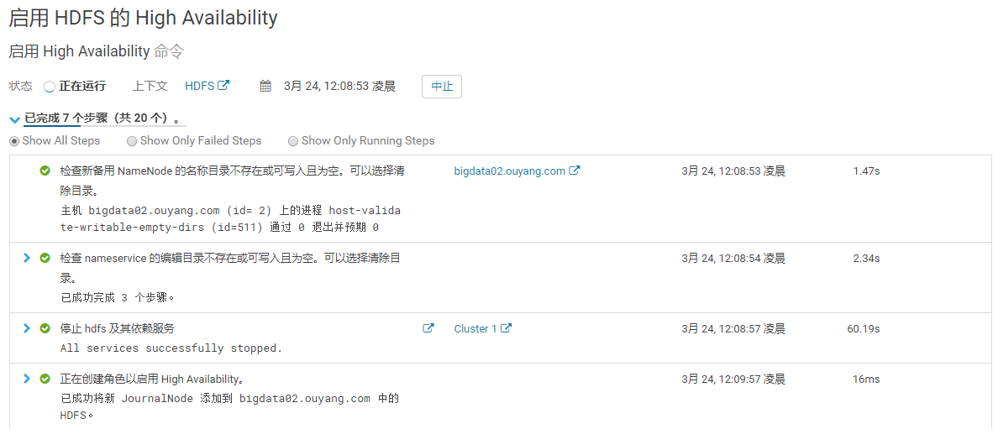
6、安装服务过程中的一个error

此为正常现象,先前那个单节点是有数据的,所以不会格式化,所以报错。
7、安装完成

2. HDFS中的2个常用命令
1、hdfs haadmin命令
[root@i-bsbhj3uw ~]# hdfs haadmin
Usage: DFSHAAdmin [-ns <nameserviceId>]
[-transitionToActive <serviceId> [--forceactive]]
[-transitionToStandby <serviceId>]
[-failover [--forcefence] [--forceactive] <serviceId> <serviceId>]
[-getServiceState <serviceId>]
[-checkHealth <serviceId>]
[-help <command>]
2、hdfs fsck命令
[hdfs@i-bsbhj3uw ~]$ hdfs fsck
Usage: DFSck <path> [-list-corruptfileblocks | [-move | -delete | -openforwrite] [-files [-blocks [-locations | -racks]]]]
<path> start checking from this path
-move move corrupted files to /lost+found
-delete delete corrupted files
-files print out files being checked
-openforwrite print out files opened for write
-includeSnapshots include snapshot data if the given path~
-list-corruptfileblocks print out list of missing blocks and files they belong to
-blocks print out block report
-locations print out locations for every block
-racks print out network topology for data-node locations
-blockId print out which file this blockId belongs to, locations (nodes, racks) ~
应用场景:当在上传文件到HDFS中时,碰到突然断电等突发操作,服务器重启后会发现hdfs启动不了,可以使用hdfs fsck命令查找到其中腐败的块。
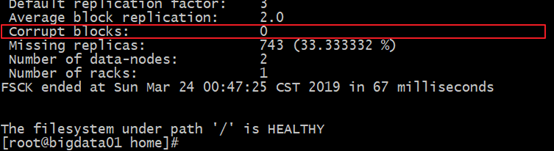
然后使用hdfs fsck -delete /腐败的块的位置将该块删除,就可以重启HDFS了。
3. Yarn的HA配置
1、在HDFS的的服务中点击启动High Availability
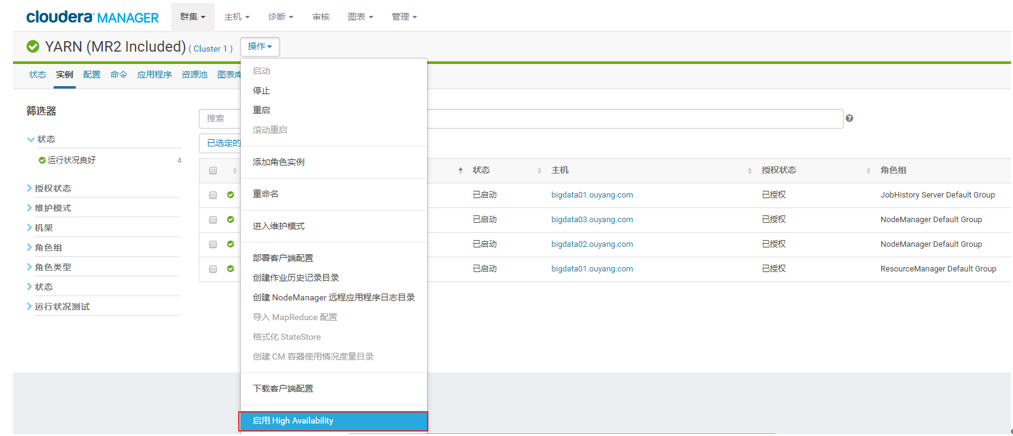
2、选择Yarn高可用所需要的主机

3、安装Yarn高可用所需要的服务

4、Yarn高可用安装成功

4. Yarn中的常用命令
1、查看Yanr中所用正在运行的程序
yarn application -list
2、kill掉通过yarn提交的spark的实时程序
yarn application -kill application_1541073817208_0238
3、查看yarn中的一个程序的任务日志(有些日志只能这样查看,在web界面的log中显示不出来)
yarn logs -applicationId application_1541073817208_0677 |grep "查找的内容"
CentOS7安装CDH 第七章:CDH集群Hadoop的HA配置的更多相关文章
- Spark集群高可用HA配置
本文中的Spark集群包含三个节点,分别是Master,Worker1,Worker2. 1.在Master机器上安装Zookeeper,本文安装在/usr/etc目录下 2.在Master机器配置Z ...
- 《Spark快速大数据分析》—— 第七章 在集群上运行Spark
- 如何使用helm优雅安装prometheus-operator,并监控k8s集群微服务
前言:随着云原生概念盛行,对于容器.服务.节点以及集群的监控变得越来越重要.Prometheus 作为 Kubernetes 监控的事实标准,有着强大的功能和良好的生态.但是它不支持分布式,不支持数据 ...
- Testlink1.9.17使用方法(第七章 测试用例集管理)
第七章 测试用例集管理 QQ交流群:585499566 测试用例准备好以后,可以对测试用例集进行相关的操作. 一. 添加测试用例到测试计划中 在主页的“当前测试计划”下拉列表里-->选择一个测试 ...
- Storm入门教程 第三章Storm集群安装部署步骤、storm开发环境
一. Storm集群组件 Storm集群中包含两类节点:主控节点(Master Node)和工作节点(Work Node).其分别对应的角色如下: 主控节点(Master Node)上运行一个被称为N ...
- Spark(二)CentOS7.5搭建Spark2.3.1分布式集群
一 下载安装包 1 官方下载 官方下载地址:http://spark.apache.org/downloads.html 2 安装前提 Java8 安装成功 zookeeper 安 ...
- linux安装redis-6.0.1单机和集群
redis作为一个直接操作内存的key-value存储系统,也是一个支持数据持久化的Nosql数据库,具有非常快速的读写速度,可用于数据缓存.消息队列等. 一.单机版安装 1.下载redis 进入re ...
- 基于CentOS与VmwareStation10搭建Oracle11G RAC 64集群环境:4.安装Oracle RAC FAQ-4.3.Oracle 集群节点间连通失败
1.检查节点连通性的错误 [grid@linuxrac1 grid]$ ./runcluvfy.sh stage -post hwos -n linuxrac1,linuxrac2 -verbose ...
- Apache shiro集群实现 (七)分布式集群系统下---cache共享
Apache shiro集群实现 (一) shiro入门介绍 Apache shiro集群实现 (二) shiro 的INI配置 Apache shiro集群实现 (三)shiro身份认证(Shiro ...
随机推荐
- Python - Django - ORM 双下划线
id 字段: id__lt:id 小于,id__gt:id 大于 import os if __name__ == '__main__': # 加载 Django 项目的配置信息 os.environ ...
- 实现Modbus TCP多网段客户端应用
对于Modbus TCP来说与Modbus RTU和Modbus ASCII有比较大的区别,因为它是运行于以太网链路之上,是运行于TCP/IP协议之上的一种应用层协议.在协议栈的前两个版本中,Modb ...
- delphi十六进制字符串hex转byte数组互相转换bmp图片
procedure Hex2Png(str: string; out png: TPngObject); var stream: TMemoryStream; begin if not Assigne ...
- C#语法中的select
第一次学着用Linq的盆友们,可以看看哈.... 代码 Code highlighting produced by Actipro CodeHighlighter (freeware)http://w ...
- 【计算机视觉】SeetaFace Engine开源C++人脸识别引擎
SeetaFace Engine是一个开源的C++人脸识别引擎,它可以在不依赖第三方的条件下载CPU上运行.他包含三个关键部分,即:SeetaFace Detection,SeetaFace Alig ...
- Makefile中宏定义
实际上是gcc命令支持-D宏定义,相当于C中的全局#define: gcc -D name gcc -D name=definition Makefile中可以定义变量(和宏很像),但是是给make解 ...
- mysql 连接闪断自动重连的方法(用在后台运行中的PHP代码)
mysql 连接闪断自动重连的方法(用在后台运行中的PHP代码)当mysql断开连接 $_instance这个还是有值得 所以会报错 MySQL server has gone away 这个地方需要 ...
- php有关类和对象的相关知识2
与类有关的魔术常量: __CLASS__,:获取其所在的类的类名. __METHOD__:获取其所在的方法的方法名. class A{ function f1(){ echo __CLASS__: / ...
- R根据列名提取想要的列
数据格式如下: a b c d e 1 2 3 4 5 使用select过滤不要的列 df[,-which(names(df)%in%c("a","b")] s ...
- 使用plotrix做韦恩图
color <- c("#E41A1C","#377EB8","#FDB462") color_transparent <- a ...