python预课05 爬虫初步学习+jieba分词+词云库+哔哩哔哩弹幕爬取示例(数据分析pandas)
结巴分词
import jieba
"""
pip install jieba 1、精确模式
2、全模式
3、搜索引擎模式
"""
txt = '中国,是以华夏文明为源泉、中华文化为基础,并以汉族为主体民族的多民族国家,通用汉语、汉字,汉族与少数民族被统称为“中华民族”,又自称为炎黄子孙、龙的传人。'
# 精确模式(没有冗余)
# res = jieba.cut(txt) # 获取可迭代对象
res = jieba.lcut(txt) # 获取列表
result:
['中国', ',', '是', '以', '华夏', '文明', '为', '源泉', '、', '中华文化', '为', '基础', ',', '并', '以', '汉族', '为', '主体', '民族', '的', '多', '民族', '国家', ',', '通用', '汉语', '、', '汉字', ',', '汉族', '与', '少数民族', '被', '统称', '为', '“', '中华民族', '”', ',', '又', '自称为', '炎黄子孙', '、', '龙的传人', '。']
# 全模式
# res1 = jieba.cut(txt, cut_all=True) # 获取可迭代对象
res1 = jieba.lcut(txt, cut_all = True)
result:
['中国', '', '', '是', '以', '华夏', '文明', '明为', '源泉', '', '', '中华', '中华文化', '华文', '文化', '化为', '基础', '', '', '并以', '汉族', '为主', '主体', '民族', '的', '多', '民族', '国家', '', '', '通用', '汉语', '', '', '汉字', '', '', '汉族', '与', '少数', '少数民族', '民族', '被', '统称', '称为', '', '', '中华', '中华民族', '民族', '', '', '', '又', '自称', '自称为', '称为', '炎黄', '炎黄子孙', '子孙', '', '', '龙的传人', '传人', '', '']
# 搜索引擎模式
# res2 = jieba.cut_for_search(txt) # 获取可迭代对象
res2 = jieba.lcut_for_search(txt)
result:
['中国', ',', '是', '以', '华夏', '文明', '为', '源泉', '、', '中华', '华文', '文化', '中华文化', '为', '基础', ',', '并', '以', '汉族', '为', '主体', '民族', '的', '多', '民族', '国家', ',', '通用', '汉语', '、', '汉字', ',', '汉族', '与', '少数', '民族', '少数民族', '被', '统称', '为', '“', '中华', '民族', '中华民族', '”', ',', '又', '自称', '称为', '自称为', '炎黄', '子孙', '炎黄子孙', '、', '传人', '龙的传人', '。']
词云:
示例一:
 五角星.jpg
五角星.jpg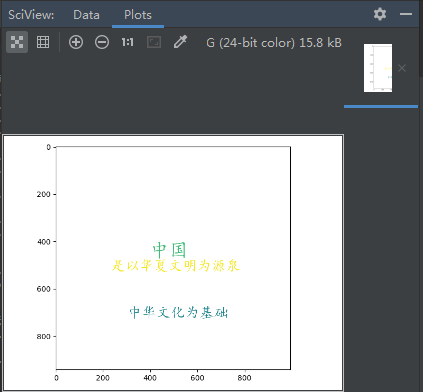 运行结果
运行结果 程序输出cy.png
程序输出cy.png
# pip install wordcloud
# from wordcloud import WordCloud
# pip install scipy==1.2.0 #下载老版本,已装新版本会被覆盖,新版本没有该方法
# pip install imageio
from wordcloud import WordCloud #导入子包,节约资源
import matplotlib.pyplot as plt #绘图分析模块
from scipy.misc import imread #用于读写图像
#from imageio import imread #可用imageio库替代scipy库 txt="life uis short you need python"
txt1='中国,是以华夏文明为源泉、中华文化为基础' color_mask=imread('五角星.jpg') #项目内放入一张五角星.jpg wc= WordCloud(font_path=r'C:\Windows\Fonts\simkai.ttf', #windows自带字体文件路径
background_color='white', #设置背景色为白色
width=1080,
height=960,
min_font_size=4, #设定词云中最小字号,默认为4号
mask=color_mask #给定词云形状
) wc.generate(txt1) #向WordCloud对象wc中加载文本txt1
wc.to_file('cy.png') #将词云输出为图像文件
plt.imshow(wc)
plt.show() #显示图片
示例二:
 运行结果
运行结果 输出小康社会.png
输出小康社会.png
import jieba
from wordcloud import WordCloud #导入子包,节约资源
import matplotlib.pyplot as plt #下载matplotlib包
from scipy.misc import imread
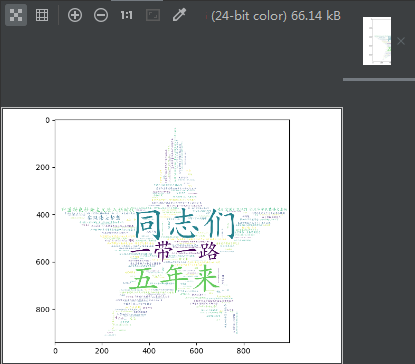
f = open('决胜全面建成小康社会.txt',encoding='utf-8') #打开指定txt文件,编码为utf-8
data = f.read() #读取文件内容
res=jieba.lcut(data) #精确分词,变为列表
result = ''.join(res) #把列表组合成字符串
color_mask = imread('五角星.jpg') #设定形状
wc = WordCloud(font_path = r'C:\Windows\Fonts\simkai.ttf', #windows内的字体文件
background_color = 'white',
width = 1080,
height = 960,
mask = color_mask #给定词云形状
)
wc.generate(result) #向WordCloud对象wc中加载文本
wc.to_file('小康社会.png') #将词云输出为图像文件
plt.imshow(wc)
plt.show() #显示图片
哔哩哔哩弹幕爬取示例:
 sign.txt(中途生成,传入弹幕信息)
sign.txt(中途生成,传入弹幕信息)
 输出bili.png
输出bili.png
"""
pip install pandas 数据分析包
pip install bs4 HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据
pip install requests
pip install lxml
""" import requests
from bs4 import BeautifulSoup
import pandas as pd
import datetime
import re #用于正则表达式
from wordcloud import WordCloud
import jieba
from scipy.misc import imread
import matplotlib.pyplot as plt header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
} #模拟浏览器访问
url = 'http://comment.bilibili.com/106015992.xml' #视频弹幕网页(下方标注B站弹幕来源)
response = requests.get(url=url,headers=header) # 向对方服务器发送请求
response.encoding = response.apparent_encoding # 设置字符编码为获取网页当前编码格式
data = response.text #获取文本
soup = BeautifulSoup(data,'lxml') #只有lxml 解析,才能进行各种参数分析
d_list = soup.find_all('d') #获取所有的d标签
dlst = []
for i in d_list: # 循环拿出所有的d标签
danmu = {}
danmu['弹幕'] = i.text #获取文本信息
# danmu['时间']=datetime.datetime.now()
# danmu['路径']=url
dlst.append(danmu) #添加到数组中
df = pd.DataFrame(dlst) #转换成二维数组,类似于execl表格 f = open('sign.txt','w',encoding = 'utf') #打开sign.txt文件,没有则自动生成文件
for i in df['弹幕'].values: # 循环所有的文本信息
pat = re.compile(r'[一-龥]+') #定义过滤数据的规则,[一-龥]代表所有的汉字
filter_data = re.findall(pattern = pat,string = i) # 执行过滤操作
f.write(''.join(filter_data)) #写入文本,样式如上图文本图片所示
f.close() #关闭txt文件 f = open('sign.txt', 'r', encoding='utf8') #打开sign.txt文件
data = f.read() #读取文本,传入data变量
result = ' '.join(jieba.lcut(data)) #把读取内容分词,然后用空格连接成字符串
f.close() #关闭txt文件 color_mask = imread('五角星.jpg') #设定形状 wc = WordCloud(
font_path=r'C:\Windows\Fonts\simkai.ttf', #windows内的字体文件
width=1000,
height=800,
mask=color_mask, #给定词云形状
background_color='white' #设定词云背景为白色
) wc.generate(result) #向WordCloud对象wc中加载文本 wc.to_file('bili.png') #将词云输出为图像文件 plt.imshow(wc)
plt.show() # 显示图片
B站弹幕弹幕查找:
1.视频页面右键,点击查看源代码
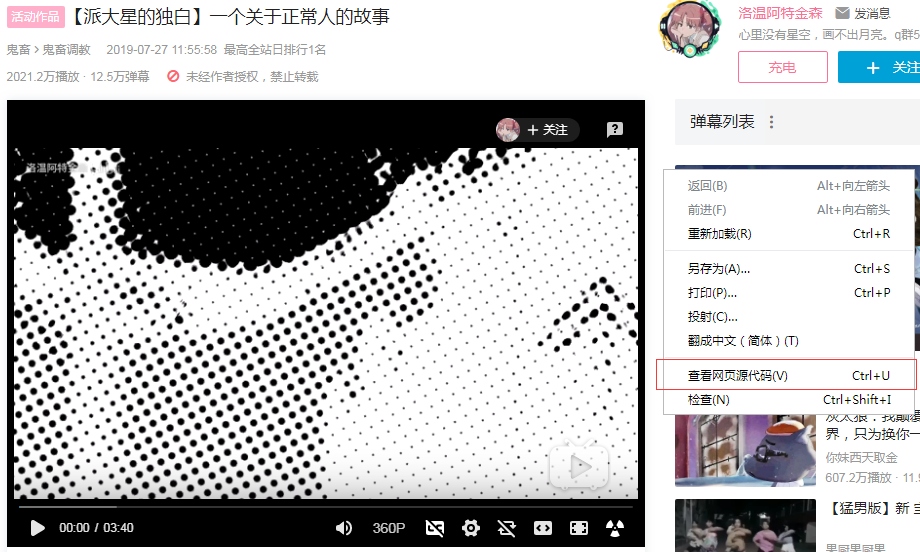
2.在源码中搜索cid",找出对应ID
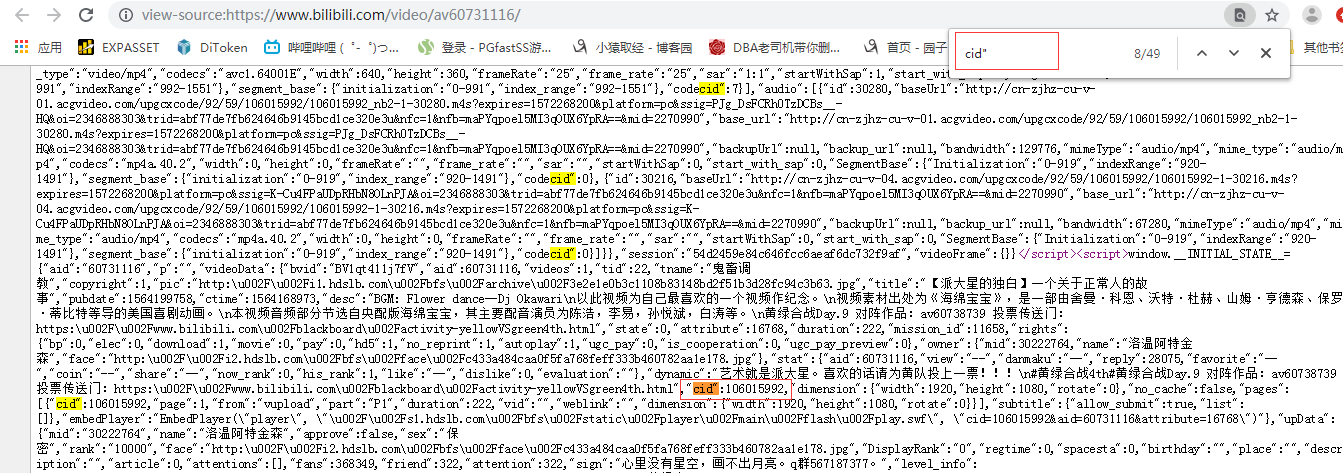
3.输入comment.bilibili.com/对应ID.xml 即可找到对应弹幕页面

python预课05 爬虫初步学习+jieba分词+词云库+哔哩哔哩弹幕爬取示例(数据分析pandas)的更多相关文章
- python预课04 列表,元祖,统计值计算示例,py文件转为EXE文件,爬虫初步学习
列表,元组 #list l1 = [1, 2, 3, '高弟弟'] #定义一个列表 #增 l1.append("DSB") #最后增加"DSB"的元素 #删 l ...
- python爬虫10 | 网站维护人员:真的求求你们了,不要再来爬取了!!
今天 小帅b想给大家讲一个小明的小故事 ... 话说 在很久很久以前 小明不小心发现了一个叫做 学习python的正确姿势 的公众号 从此一发不可收拾 看到什么网站都想爬取 有一天 小明发现了一个小黄 ...
- 爬虫05 /js加密/js逆向、常用抓包工具、移动端数据爬取
爬虫05 /js加密/js逆向.常用抓包工具.移动端数据爬取 目录 爬虫05 /js加密/js逆向.常用抓包工具.移动端数据爬取 1. js加密.js逆向:案例1 2. js加密.js逆向:案例2 3 ...
- python3网络爬虫系统学习:第一讲 基本库urllib
在python3中爬虫常用基本库为urllib以及requests 本文主要描述urllib的相关内容 urllib包含四个模块:requests——模拟发送请求 error——异常处理模块 pars ...
- python爬虫16 | 你,快去试试用多进程的方式重新去爬取豆瓣上的电影
我们在之前的文章谈到了高效爬虫 在 python 中 多线程下的 GIL 锁会让多线程显得有点鸡肋 特别是在 CPU 密集型的代码下 多线程被 GIL 锁搞得效率不高 特别是对于多核的 CPU 来说 ...
- python 生成18年写过的博客词云
文章链接:https://mp.weixin.qq.com/s/NmJjTEADV6zKdT--2DXq9Q 回看18年,最有成就的就是有了自己的 博客网站,坚持记录,写文章,累计写了36篇了,从一开 ...
- 爬虫之绘图matplotlib与词云(七)
1 绘制条形图 import matplotlib # 数据可视化 from matplotlib import pyplot as plt # 配置字体 matplotlib.rcParams[&q ...
- 爬虫开发6.selenuim和phantonJs处理网页动态加载数据的爬取
selenuim和phantonJs处理网页动态加载数据的爬取阅读量: 1203 动态数据加载处理 一.图片懒加载 什么是图片懒加载? 案例分析:抓取站长素材http://sc.chinaz.com/ ...
- wordcloud + jieba 生成词云
利用jieba库和wordcloud生成中文词云. jieba库:中文分词第三方库 分词原理: 利用中文词库,确定汉字之间的关联概率,关联概率大的生成词组 三种分词模式: 1.精确模式:把文本精确的切 ...
随机推荐
- python的JSON库
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,易于人阅读和编写. 1.json库的使用 使用 JSON 函数需要导入 json 库:import jso ...
- selenium又一小坑 无法用XPATH直接获取属性值 需要使用.get_attribute(“href”)
在使用selenium进行抓取url的时候,试图使用find_elements_by_xpath来获取. 因此想当然的直接使用XPATH的语法进行获取属性 事例缩略后xml结构如下 <div c ...
- C语言向txt文件写入当前系统时间(Log)
程序实现很简单,涉及到的只有两个知识点. 1.文件最最基本的打开关闭: 2.系统时间的获取. 代码是在VS2019环境下编写的,部分函数在其他编译器中会无法识别.这个就只能需要自己去查找对应的函数简单 ...
- deepin安装卡在deepin标志界面解决方案
再次重启前将U盘插上,进系统前按快速选择启动装置F12(不同品牌电脑可能不同),选择从U盘启动: 进入第一个安装界面时一定要注意:在跳转前,按E进入grub设置界面,移动光标到倒数第二行的”quiet ...
- 【题解】Luogu P3349 [ZJOI2016]小星星
原题传送门 我们考虑设\(dp_{i,j}\)表示树上的点\(i\)在图上对应的点为\(j\)时\(i\)和子树对应在图上的方案数 \(dp_{u_i}=\prod_{v \in u.son} dp_ ...
- java学习:循环结构的使用规则和注意事项
循环结构的基本组成部分,一般可分为四部分: 初始化语句:在循环开始最初执行,而且只做唯一一次 条件判断:如果成立,则循环继续:如果不成立,则循环退出. 循环体:重复要做的事情内容,若干行语句. 进步语 ...
- Windows定时清理文件处理脚本
一.运行CMD,输入forfile/?,即可获取forfile的使用方法 /P 路径 /M 文件类型 /D 时间 + | - +:之后 - :之前 example:-2 ...
- spring Boot 学习(六、Spring Boot与分布式)
一.分布式应用在分布式系统中,国内常用zookeeper+dubbo组合,而Spring Boot推荐使用 全栈的Spring,Spring Boot+Spring Cloud 分布式系统: 单一应用 ...
- Puppet自动化管理配置
Puppet:开源系统配置和管理工具 随着虚拟化和云计算技术的兴起,计算机集群的自动化管理和配置成为了数据中心运维管理的热点.对于 IaaS.Paas.Saas 来说,随着业务需求的提升,后台计算机集 ...
- 二.HTML
1.HTML 1. <head></head>标签 <!DOCTYPE html> <!--统一规范--> <!----> <html ...