SQLite中字段顺序和PAGE_SIZE对性能的影响
1.背景
SQLite数据库中有1张表,该表含若干个字段,其中有1个字段为BLOB类型,且BLOB字段不是最后1个字段。表结构类似如下(col3为BLOB字段):
T (col1 INTEGER,col2 TEXT,col3 BLOB,col4 REAL,col5 TEXT)
业务系统要遍历这张表的内容,但查询内容不包括BLOB字段,即查询SQL类似如下:
Select col1,col2,col4,col5 from T;
2.问题说明
上述的使用模式,在表T较小的情况下运转尚且良好,但当表T较大时(在我们的系统中.DB文件达到了100G,且BLOB占了主要的存储),遍历一次表需要很长的时间,长达几个小时。那么对于这样的使用场景,应该要如何去优化呢?
3.优化思路
若不考虑物理IO优化和操作系统优化,仅考虑DB优化,一般来说,优化无外乎如下几种常用的方式:
- 索引。但对于需要进行遍历访问的表,通过索引显然毫无优化空间,甚至会效率更低。因此索引的优化思路首先被放弃。
- SQL优化。但这个SQL,属于最基本的查询SQL,因此也没有优化空间。
- 并行查询。将之前1个进程访问所有的记录,改为多个进程分别访问不同的记录区间。这种方式可以尝试。
- 参数优化。例如通过设置PAGE_SIZE参数,调整最小存储单元PAGE的大小。
- 其它优化。基于DB文件格式和数据库运行原理进行优化。
根据以上描述,下文我将从并行查询、参数优化、其它优化3个方面进行优化实验。
4.优化实验
4.1.并行查询
我将表T的所有记录,按ROWID每5000条作为一个单元,然后开启多个进程分别查询不同的单元。通过这种方式的确实现了并行,但单个进程的IO吞吐会随进程数的增加而减小,使总体的性能未有提升,下表是开启不同个数的并行进程时,各进程获得的IO吞吐量:
|
并行进程个数 |
各进程的IO吞吐 |
全部执行完毕耗时 |
|
1 |
18M/s |
约2小时 |
|
4 |
4.4M/s |
约2小时 |
|
6 |
2.9M/s |
约2小时 |
|
8 |
2.2M/s |
约2小时 |
尽管可以实现多个进程同时工作,但对于SQLite来说,并行并没有扩展IO的吞吐能力。因此并行查询,不能起到优化效果。
4.2.参数优化
SQLite可通过PRAGMA宏来设置不同的运行参数。通过分析所有可被设置的参数,我认为PAGE_SIZE参数可能会较明显地影响优化效果。基于如下分析:
PAGE是SQLite的最小存储单元,它是表扩张和收缩的基本单位,表中的记录都存储在PAGE中(类似于ORACLE中的block)。PAGE_SIZE用来指定PAGE的大小,不同版本有不同的默认值(v3.12之前是1024 Byte,v3.12之后是4096 Byte),改变默认值只能在创建.DB中第1张表之前进行(或改变默认值之后立刻执行VACUUM)。
我们的业务系统使用的数据库版本小于v3.12,因此其默认的PAGE_SIZE为1KB,而通过分析数据,发现几乎表中所有的记录,其大小均大于1KB,甚至达到几百KB。在PAGE中的存储表记录时(在SQLite中也称为payload),会首先使用当前PAGE中剩余的存储空间,当剩余空间不够用时,会产生一个overflow page(溢出页),然后继续在溢出页中存储payload剩余的内容,空间仍然不够用时,会继续产生溢出页,以此种方式直到将payload表达完整。其示意图如下:
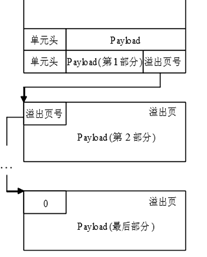
假设一条记录为3K,当PAGE_SIZE为1K时,完全查询这一条记录需要3次寻址(查找对应的PAGE);而当PAGE_SIZE为4K,完全查询这一条记录仅需1次寻址。
制作了一个测试表,平均记录大小为76KB,一共有12000条记录,表大小约960M,设置不了不同的PAGE_SIZE,其查询效率的对比如下:
|
PAGE_SIZE |
该使用场景查询耗时 |
|
1K |
4.93s |
|
2K |
2.74s |
|
4K |
1.67s |
|
8K |
1.08s |
|
16K |
0.79 |
根据上表可知,当表记录较大时(超过PAGE_SIZE的大小),随着PAGE_SIZE的增大,本使用场景的查询耗时越小。查询效率提升的倍数大致与PAGE_SIZE的倍数一致。
4.3.其它优化
通过分析SQLite的文件格式可知,表记录的所有字段的内容是连续排列的,这与ORACLE等数据库是不同的(ORACLE对于LOB对象,仅在字段内容中记录LOB的地址,而非实际LOB内容)。差别如下图:

对于SQLite,如果要查询col4和col5,需要将col3 value完全"走过",当col3 value由于过大而分散存储在多个溢出页时,还需要"走过"所有这些溢出页,虽然这些"走过"完全是无意义的,但仍然会发生IO。
由于SQLite的文件格式有上述特征,因此只需将BLOB字段顺序由第3位调整为最末位,即可避免对BLOB字段无效的IO"走过"。
仍然使用4.2中的数据,设PAGE_SIZE为1K,将BLOB字段分别设为中间位置和最末位创建数据库,比较性能如下:
|
PAGE_SIZE |
BLOB字段的位置 |
该使用场景查询耗时 |
|
1K |
中间位置 |
4.93s |
|
1K |
最末位 |
0.28s |
将BLOB字段由中间位置调整为最未位之后,优化效果明显,查询效率约为调整前的17.6倍。
5.结论
关于第一章背景中提到的优化场景,有如下两种优化手段:
- 将BLOB字段由中间位置调整为最末位。此种优化手段优化效果非常明显。
- 根据表记录的大小,设置合适的PAGE_SIZE,以尽量减少溢出页,进而减少IO次数。此种优化方式优化效果尚可,但没有第一种优化手段效果明显。
SQLite中字段顺序和PAGE_SIZE对性能的影响的更多相关文章
- 关于数据库优化1——关于count(1),count(*),和count(列名)的区别,和关于表中字段顺序的问题
1.关于count(1),count(*),和count(列名)的区别 相信大家总是在工作中,或者是学习中对于count()的到底怎么用更快.一直有很大的疑问,有的人说count(*)更快,也有的人说 ...
- 一天五道Java面试题----第九天(简述MySQL中索引类型对数据库的性能的影响--------->缓存雪崩、缓存穿透、缓存击穿)
这里是参考B站上的大佬做的面试题笔记.大家也可以去看视频讲解!!! 文章目录 1.简述MySQL中索引类型对数据库的性能的影响 2.RDB和AOF机制 3.Redis的过期键的删除策略 4.Redis ...
- Android中查看SQLite中字段数据的两种方式
方式一:ADB Pull 通过adb pull导出*.db文件到PC的文件夹中,通过可视化工具 SQLiteExpertPers 进行查看.编辑: adb pull /data/data/com.jo ...
- SQL where 条件顺序对性能的影响有哪些
经常有人问到oracle中的Where子句的条件书写顺序是否对SQL性能有影响,我的直觉是没有影响,因为如果这个顺序有影响,Oracle应该早就能够做到自动优化,但一直没有关于这方面的确凿证据.在网上 ...
- 优化 : Oracle数据库Where条件执行顺序 及Where子句的条件顺序对性能的影响
.Oracle数据库Where条件执行顺序: 由于SQL优化起来比较复杂,并且还会受环境限制,在开发过程中,写SQL必须必须要遵循以下几点的原则: 1.ORACLE采用自下而上的顺序解析WHERE子句 ...
- SQL Server中多表连接时驱动顺序对性能的影响
本文出处:http://www.cnblogs.com/wy123/p/7106861.html (保留出处并非什么原创作品权利,本人拙作还远远达不到,仅仅是为了链接到原文,因为后续对可能存在的一些错 ...
- 在sqlite中,如何删除字段? how to drop a column in sqlite
在sqlite中可以使用ALTER TABLE语法对表结构进行修改,从官方的文档说明中,语法如下图: 从图中可以看出,ALTER TABLE仅仅支持表名重命名,添加字段,却没有删除字段的方法.那么该如 ...
- 解决SpringDataJpa实体类中属性顺序与数据库中生成字段顺序不一致的问题
一.在application.yml配置中添加数据库根据实体类自动创建数据库表的配置(这里数据库采用MySQL数据库) jpa: database: MYSQL show-sql: true #Hib ...
- 在oracle表中增加、修改、删除字段,表的重命名,字段顺序调整
增加字段语法:alter table tablename add (column datatype [default value][null/not null],….); 说明:alter table ...
随机推荐
- asp.net 版本一键升级,后台直接调用升级脚本
应客户需求,要求实现一个版本一键升级的功能,咨询过同事之后弄了个demo出来,后台代码如下: //DBConnModelInfo:连接字符串的对象 (包含数据库实例名,数据库名,登陆名,登陆密码) p ...
- 机甲大师S1机器人编程学习
机甲大师 S1(RoboMaster S1)是大疆新出的教育机器人,很期待.S1支持Scratch和Python编程.(Scratch是麻省理工学院的“终身幼儿园团队”(Lifelong Kinder ...
- Python多任务—线程
并发:指的是任务数多余cpu核数,通过操作系统的各种任务调度算法,实现用多个任务“一起”执行(实际上总有一些任务不在执行,因为切换任务的速度相当快,看上去一起执行而已) 并行:指的是任务数小于等于cp ...
- idea中 Application Server not specified
一.问题 idea中的tomcat报错: Application Server not specified 二.解决 原因是没有关联本地的tomcat,关联本地tomcat即可
- APS的未来会怎么样?历史给了你答案
一项技术从概念推广到实际应用推广需要十五到二十年时间,21世纪的头十年是APS的概念推广时期,随着理论的成熟,软件的实用化,企业应用的深入,下一个十年,APS将是实际应用推广的时期. APS兴起 从上 ...
- IDEA安装(2019.2版)
IDEA安装(2019.2版) 前段时间在公司实习接触过现下很火的 IDE,这里我根据搜集到的资料以及自己的实际操作整合了这篇博客,包括了安装和破解 IDEA,借此打开学习之旅. IntelliJ ...
- java全套学习资料
1.背景 技术需要大家的共同努力,在这里我将平时学习过的觉得比较好的资料分享给大家; 当然,最好的学习就是输出,与大家分享,在分享的资料中有的是自己的总结,有的是分享来自互联网,如果有侵权请联系删除; ...
- 快速生成mysql上百万条测试数据
方案:编写一个存储过程循环添加数据 1. 创建表index_test DROP TABLE IF EXISTS index_test; CREATE TABLE index_test( id ) PR ...
- centos自动同步服务器时间
原文:https://my.oschina.net/yysue/blog/1628733 1.安装ntpdate yum install ntpdate -y 2.测试是否正常 ntpdate cn. ...
- ansible自动化运维02
ansible清单管理 inventory文件通常用于定义要管理主机的认证信息,例如:ssh登录用户名,密码,以及key相关信息. 举个例子:定义清单组 注意:组名为pro,关键字段children表 ...