Spark(四十六):Spark 内存管理之—OFF_HEAP
存储级别简介
Spark中RDD提供了多种存储级别,除去使用内存,磁盘等,还有一种是OFF_HEAP,称之为 使用JVM堆外内存

使用OFF_HEAP的优点:在内存有限时,可以减少频繁GC及不必要的内存消耗(减少内存的使用),提升程序性能。
Spark内存管理根据版本划分为两个阶段:spark1.6[官网给出spark1.5之前(包含spark1.5)]之前阶段、spark1.6之后阶段。
1.6.0及以后版本,使用的统一内存管理器,由UnifiedMemoryManager实现。
- ü MemoryManger在spark1.6之前采用静态内存管理
(StaticMemoryManager[https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/memory/StaticMemoryManager.scala]),
- ü Spark1.6之后默认为统一内存管理
(UnifiedMemoryManager[https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/memory/UnifiedMemoryManager.scala])统一内存管理模块包括了堆内内存(On-heap Memory)和堆外内存(Off-heap Memory)两大区域
从1.6.0版本开始,Spark内存管理模型发生了变化。旧的内存管理模型由StaticMemoryManager类实现,现在称为“legacy(遗留)”。默认情况下,“Legacy”模式被禁用,这意味着在Spark 1.5.x和1.6.0上运行相同的代码会导致不同的行为。
为了兼容,您可以使用spark.memory.useLegacyMode参数(目前spark2.4版本中也依然保留这个静态内存管理模型)启用“旧”内存模型:
spark.memory.useLegacyMode=true(默认为false)
该参数官网给出的解释:
Whether to enable the legacy memory management mode used in Spark 1.5 and before. The legacy mode rigidly partitions the heap space into fixed-size regions, potentially leading to excessive spilling if the application was not tuned. The following deprecated memory fraction configurations are not read unless this is enabled:
spark.shuffle.memoryFraction
spark.storage.memoryFraction
spark.storage.unrollFraction
在Spark1.x以前,默认的off_heap使用的是Tachyon。但是Spark中默认操作Tachyon的TachyonBlockManager开发完成之后,代码就不再更新。当Tachyon升级为Alluxio之后移除不使用的API,导致Spark默认off_heap不可用(spark1.6+)。
错误情况可参考:https://alluxio.atlassian.net/browse/ALLUXIO-1881
Spark2.0的OFF_HEAP
从spark2.0开始,移除默认的TachyonBlockManager以及ExternalBlockManager相关的API。
移除情况可参考:https://issues.apache.org/jira/browse/SPARK-12667。
但是在Spark2.x的版本中,OFF_HEAP这一存储级别,依然存在:

那么,这里的OFF_HEAD 数据是如何存储的呢?
在org.apache.spark.memory中,有一个MemoryMode,MemoryMode标记了是使用ON_HEAP还是OFF_HEAP。
在org.apache.spark.storage.memory.MemoryStore中,根据MemoryMode类型来调用不同的存储。

在MemoryStore中putIteratorAsBytes方法,是用于存储数据的方法。

其实真正管理(存储)values的对象是valuesHolder,valueHolder是SerializedValuesHolder的类对象,我们看下SerializedValuesHolder是怎么定义的。
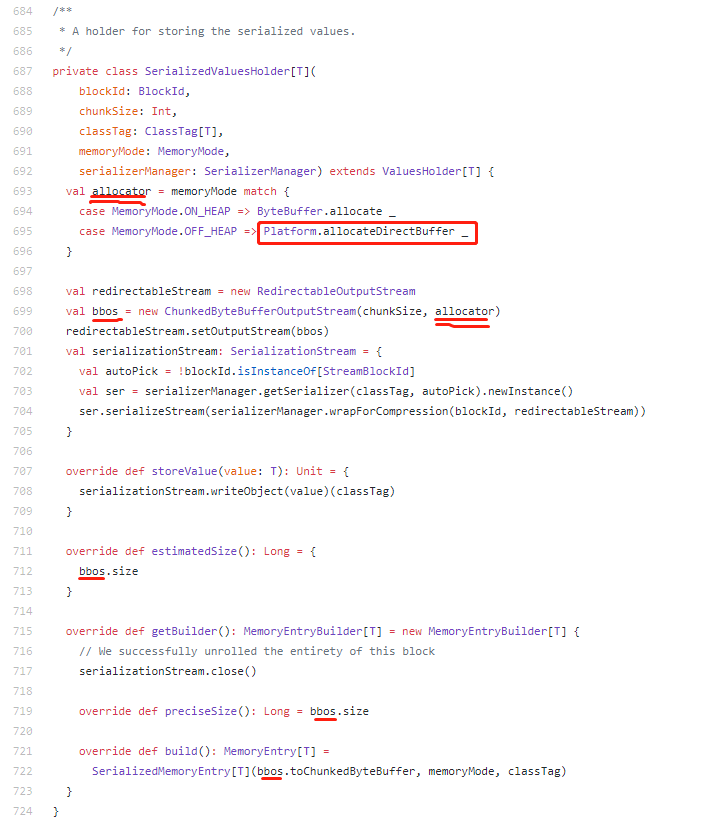
在该方法中,OFF_HEAP使用的是org.apache.spark.unsafe.Platform(https://github.com/apache/spark/blob/master/common/unsafe/src/main/java/org/apache/spark/unsafe/Platform.java)来做底层存储的,Platform是利用java unsafe API实现的一个访问off_heap的类,所以,spark2.x的OFF_HEAP就是利用java unsafe API实现的内存管理。
Spark2.x OFF_HEAP优势:
- ü 优点:在内存有限时,可以减少频繁GC及不必要的内存消耗(减少内存的使用,),提升程序性能。
- ü 缺点:没有数据备份,也不能像alluxio那样保证数据高可用,丢失数据则需要重新计算。
参考
《Spark2.x 内存管理之---OFF_HEAP https://blog.csdn.net/qq_21439395/article/details/80773121》
- 关于 java unsafe API 可参考:
《Java中Unsafe类详解 https://www.cnblogs.com/mickole/articles/3757278.html 》
《JAVA并发编程学习笔记之Unsafe类 https://blog.csdn.net/aesop_wubo/article/details/7537278》
Spark(四十六):Spark 内存管理之—OFF_HEAP的更多相关文章
- Android简易实战教程--第四十六话《RecyclerView竖向和横向滚动》
Android5.X后,引入了RecyclerView,这个控件使用起来非常的方便,不但可以完成listView的效果,而且还可以实现ListView无法实现的效果.当然,在新能方便也做了大大的提高. ...
- linux基础-第十六单元 yum管理RPM包
第十六单元 yum管理RPM包 yum的功能 本地yum配置 光盘挂载和镜像挂载 本地yum配置 网络yum配置 网络yum配置 Yum命令的使用 使用yum安装软件 使用yum删除软件 安装组件 删 ...
- NeHe OpenGL教程 第四十六课:全屏反走样
转自[翻译]NeHe OpenGL 教程 前言 声明,此 NeHe OpenGL教程系列文章由51博客yarin翻译(2010-08-19),本博客为转载并稍加整理与修改.对NeHe的OpenGL管线 ...
- Linux操作系统基础(四)保护模式内存管理(2)【转】
转自:http://blog.csdn.net/rosetta/article/details/8570681 Linux操作系统基础(四)保护模式内存管理(2) 转载请注明出处:http://blo ...
- 四十六、android中的Bitmap
四十六.android中的Bitmap: http://www.cnblogs.com/linjiqin/archive/2011/12/28/2304940.html 四十七.实现调用Android ...
- “全栈2019”Java第四十六章:继承与字段
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- 第四十六个知识点 在Sigma协议中,正确性,公正性和零知识性意味着什么
第四十六个知识点 在Sigma协议中,正确性,公正性和零知识性意味着什么 Sigma协议 Sigma协议是Alice想要向Bob证明一些东西的协议(Alice知道一些秘密).他们有下面的一般范式:Al ...
- spark 源码分析之十六 -- Spark内存存储剖析
上篇spark 源码分析之十五 -- Spark内存管理剖析 讲解了Spark的内存管理机制,主要是MemoryManager的内容.跟Spark的内存管理机制最密切相关的就是内存存储,本篇文章主要介 ...
- Spark 1.6以后的内存管理机制
Spark 内部管理机制 Spark的内存管理自从1.6开始改变.老的内存管理实现自自staticMemoryManager类,然而现在它被称之为"legacy". " ...
随机推荐
- 本地安装部署ActiveCollab
ActiveCollab是一个非常易于使用.基于Web.开源的协作开发与项目管理工具. 我们公司一直在用这款工具,进行任务分配和时间填写,十分简便 ActiveCollab可以利用它轻松地搭建一个包括 ...
- Ajax -02 -JQuery+Servlet -实现页面点击刷出表格数据
demo功能分析 jquery 的js文件需要导入,json的三个文件需要导入,不然writeValueAsString 会转化成JsonArray(json 数组)失败 $("#mytbo ...
- Python语言程序设计(2)--深入理解python
- “只有DBA才能导入由其他DBA导出的文件”各种解决办法
“只有DBA才能导入由其他DBA导出的文件”各种解决办法 当oracle导入的时候出现“只有 DBA 才能导入由其他 DBA 导出的文件”的时候通常有以下几种解决办法! 1:常见的是直接grant ...
- 单片机开发之C语言编程基本规范
为了提高源程序的质量和可维护性,从而最终提高软件产品生产力,特编写此规范.本标准规定了程序设计人员进行程序设计时必须遵循的规范.本规范主要针对单片机编程语言和08编译器而言,包括排版.注释.命名.变量 ...
- 向指定URL发送GET和POST请求
package com.sinosoft.ap.wj.common.util; import java.io.BufferedReader;import java.io.IOException;imp ...
- Java - 框架之 MyBites
一. 开发步骤: 1. 创建 PO (model) 类,根据需求创建. 2. 创建全局配置文件 sqlMapConfig.xml. 3. 编写映射文件. 4. 加载映射文件, 在 SqlMapConf ...
- learning java AWT 手绘窗口
import java.awt.*;port java.awt.event.ActionListener; import java.awt.event.MouseAdapter; import jav ...
- C# 字符串String相关
是否可以继承String类 不能,因为从定义上看String类是sealed类[密封]故不可以继承.当对一个类应用 sealed 修饰符时,此修饰符会阻止其他类从该类继承.若硬要写,则编译不通过 字符 ...
- mysqli扩展和持久化连接
mysqli扩展的持久化连接在PHP5.3中被引入.支持已经存在于PDO MYSQL 和ext/mysql中. 持久化连接背后的思想是客户端进程和数据库之间的连接可以通过一个客户端进程来保持重用, 而 ...