Momentum Contrast for Unsupervised Visual Representation Learning (MoCo)
Momentum Contrast for Unsupervised Visual Representation Learning
一、Methods Previously Proposed
1. End-to-end Mechanisms

方法简介:对于每个mini-batch中的 image 进行增强,每一张图片经过增强处理都得到两张图片q 和 $ k_+ $, 这两张互为正样本。采用两个不同的 encoder 分别对 q和 dictionary中的keys(包含q对应的正样本 $ k_+ $) 进行编码得到相应特征,通过计算特征间的 contrastive loss 对两个encoder都进行一次参数更新。
弊端:dictionary size 和 mini-batch 的强耦合性,也就是dictionary size = mini-batch size,而dictionary size 取决于最终的模型特征表达性能,也就是GPU大小限制了模型的性能。
2. Memory Bank
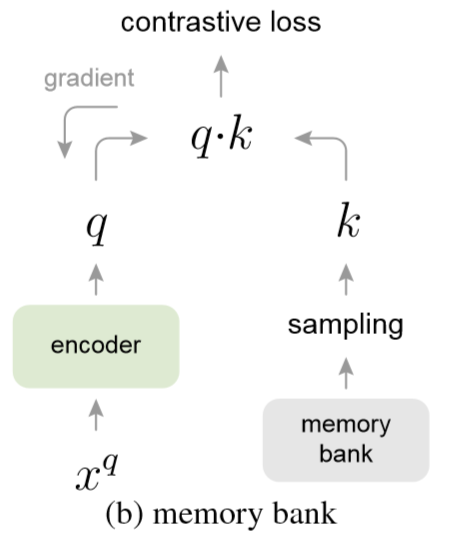
- 方法简介:大致方式与 end-to-end 差不多,主要有以下几点区别:
- decoupled:memory bank 让 dictionary size 从 mini-batch 中解耦出来,这个 dictionary size 就是整个样本的数量。
- update: query 的编码器每次都通过SGD进行更新,而 dictionary key 对应的编码器的更新时刻是当同一个样本 image 再次出现的时候,进行更新。
- 弊端:当 dictionary 中的 key 再次更新的时候,可能是时隔好几个 epoch 的事情,因此 dictionary 中的 key 可能是用不同时刻差异性较大的encoder编码得到的,因此在计算 constrative loss 时,丢失了编码的一致性,导致网络的性能受到限制。
二、Motivation
- 无监督表征学习在NLP中获得了巨大的成果(e.g. GPT,BERT),如何将无监督应用到计算机视觉任务中,取代原先的有监督与训练模型。
- 如何将NLP无监督学习中适用于离散空间的建立字典方法应用到数据空间为连续的、高维的计算机视觉任务中去。
- 如何解决之前提出两个方法的弊端:在解耦的同时,维护 dictionary 中 key 的一致性。
三、Proposed Method
先说一下我对 pretext task 的个人理解:在解决一个具体任务之前,先制定一个前置(代理)任务,用于得到一个好的特征表达的模型。本文设定的 pretext task 是 instance discrimination task。
1. Contrastive Learning
- 核心思想 : 将 dictionary 作为一个 queue 进行维护

- 方法简介:在 memory bank 的机制上做一些优化,引入动量更新机制(MoCo),保持 dictionary 编码的一致性。dictionary 的更新方式做了改进:对于当前的 mini-batch 进行排队处理,进队后相对于一些最早进入队列的 mini-batch 对应的 key 进行出队操作,这样保证一些过时的、一致性较弱的 key 可以被清除掉。
2. Contrastive Loss Function(InfoNCE)

其中,$\tau$ 是超参数,实验设置为0.07,两个向量的点积用于衡量两个向量的相似性。
3. Momentum Contrast (MoCo)
每一次迭代的时候都用 MoCo 机制对 momentum encoder 进行模型参数更新,而 query 对应的 encoder 则是用SGD的方式进行更新,MoCo 机制对应的更新公式如下:
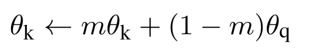
其中,$\theta_k$ 对应的是 dictionary 的编码器 momentum encoder 网络的参数, $\theta_q$ 对应的是 query 的编码器参数,$m$ 是动量系数, $m\in [0, 1)$ , 实验表明,当 $m = 0.999$ 时效果最好,也证明了一点:对 momentum encoder 进行缓慢更新是使用队列的关键所在,可以保证 dictionary keys 中的一致性。
4. Algorithm

5. Shuffling BN
这里提到传统的 BN 不能得到很好的特征表示,因此作者用了 Shuffling BN ,针对 dictionary 编码器,将 batch 中的样本顺序打乱后,放到多个GPUs中进行 BN 操作,编码后,再进行打乱操作,从而达到 query 和 keys 来自于不同的子集。(纯属个人理解,如有误请包涵并指出)
四、Experiments
1.Datasets
- Image Net - 1M ( IN - 1M )
- ~1.28 million images in 1000 classes
- well-ballanced
- Instragram - 1B ( IG - 1B )
- ~1 billion public images from Instagram
- uncurated, long-tailed, unbalanced
2. Trian Setting ( Optimizer:SGD )

3. ImageNet Validation
I. Albation: contrastive loss mechanisms

- End-to-end 机制受到了GPU内存大小的限制,无法继续增加K的大小
- Memory bank 的性能也不如 MoCo, 再一次验证了 dictionary key 中的一致性
- 从实验中也可以看出,K越大也就是dictionary的大小越大,模型性能也越好
II. Albation: momentum
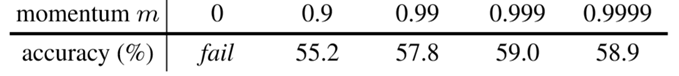
- 对 momentum encoder 进行缓慢更新是使用队列的关键所在,可以保证 dictionary keys 中的一致性
III. Comparison with previous results


- 在同等参数量情况下,性能优于其他方法
- 随着参数量增加,性能也随之提升
4. PASCAL VOC Object Detection
I. Albation:backbones
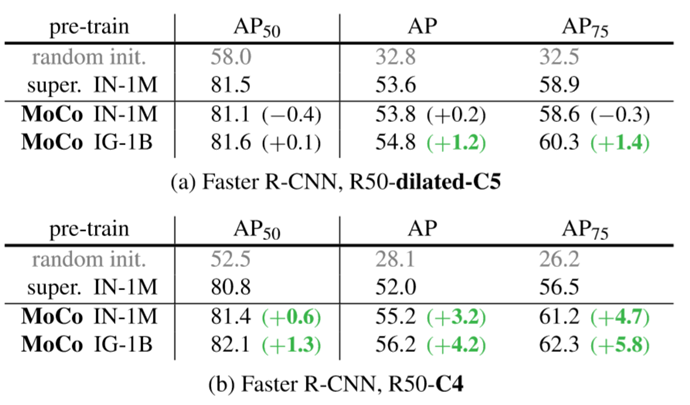
- backbone 不同,模型性能也不同,R50-C4 的性能优于R50-dilated-C5
II. Albation:contrastive loss mechanisms (pre-trained on IN-1M)

- MoCo 性能优于 end-to-end 和 memory bank
III. Comparison with previous results

- MoCo 优秀!
5. COCO Object Detection and Segmentation
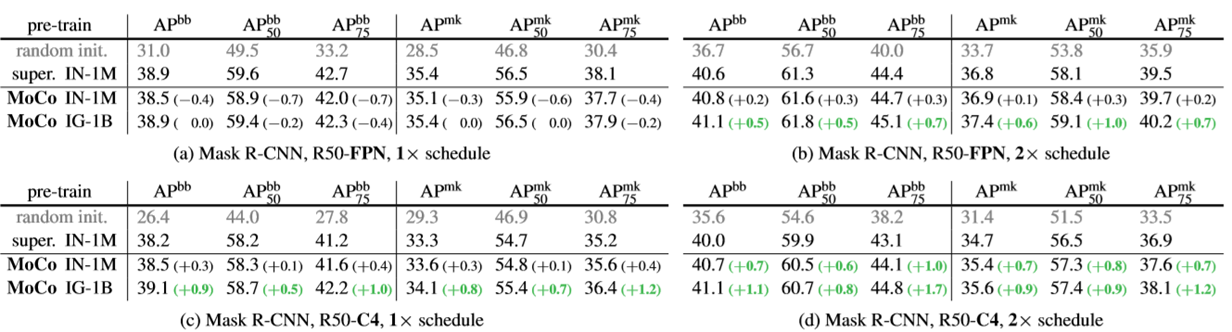
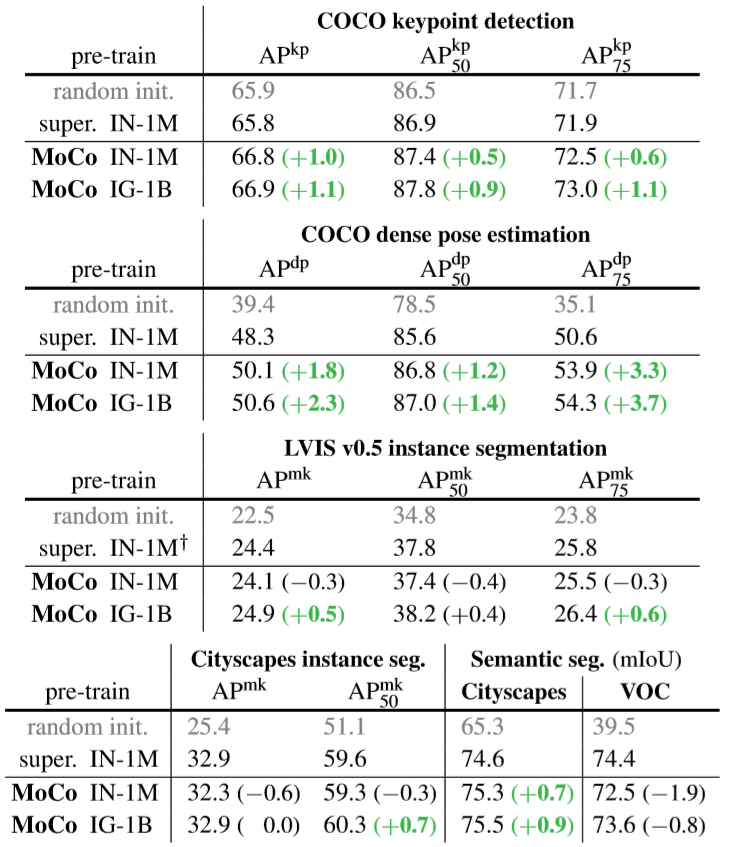
- MoCo 在多个任务上都有优异的性能,但在 VOC 的 Semantic Segmentation 任务中发现,性能不如有监督,这也是作者做了这么多实验唯一一个反例,即便如此,MoCo的性能也是不容置疑的。
五、Conclusion
- 巧妙地利用了维护队列的思想,让 dictionary 的大小尽可能大的同时保证了 dictionary 中 key 的一致性。
- MoCo 的无监督学习得到的模型性能在下游任务中展现出同等甚至超越有监督预训练模型的性能,大大拉近了有监督和无监督的鸿沟。
- 一些感慨:大牛之所以是大牛,是有原因的,想法与硬件条件起飞,想法的落地,还是需要强大的GPU啊。当然,有想法的前提,还是得有强大的知识储备,一只默默仰望大佬的小菜蜗牛。
Momentum Contrast for Unsupervised Visual Representation Learning (MoCo)的更多相关文章
- 论文解读《Momentum Contrast for Unsupervised Visual Representation Learning》俗称 MoCo
论文题目:<Momentum Contrast for Unsupervised Visual Representation Learning> 论文作者: Kaiming He.Haoq ...
- Momentum Contrast for Unsupervised Visual Representation Learning
Momentum Contrast for Unsupervised Visual Representation Learning 一.Methods Previously Proposed 1. E ...
- 【CV】ICCV2015_Unsupervised Visual Representation Learning by Context Prediction
Unsupervised Visual Representation Learning by Context Prediction Note here: it's a learning note on ...
- 论文解读GALA《Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learning》
论文信息 Title:<Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learn ...
- 论文解读(SUGRL)《Simple Unsupervised Graph Representation Learning》
Paper Information Title:Simple Unsupervised Graph Representation LearningAuthors: Yujie Mo.Liang Pen ...
- 论文解读(USIB)《Towards Explanation for Unsupervised Graph-Level Representation Learning》
论文信息 论文标题:Towards Explanation for Unsupervised Graph-Level Representation Learning论文作者:Qinghua Zheng ...
- Self-Supervised Representation Learning
Self-Supervised Representation Learning 2019-11-11 21:12:14 This blog is copied from: https://lilia ...
- 论文解读(MVGRL)Contrastive Multi-View Representation Learning on Graphs
Paper Information 论文标题:Contrastive Multi-View Representation Learning on Graphs论文作者:Kaveh Hassani .A ...
- 论文笔记之:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS ICLR 2 ...
随机推荐
- C++线程同步与互斥之互斥体
抢红包练习 第一步:在第一个文本框中输入一个值,比如1000: 第二步:点击抢红包,同时创建3个线程,每个线程循环进行抢红包的操作,每次抢50; 第三步:使用Mutex进行线程控制,当第一个文本框中的 ...
- Hive的五个基础介绍
一.什么是Hive? 1.Hive是一个翻译器,SQL ---> Hive引擎 ---> MR程序 2.Hive是构建在HDFS上的一个数据仓库(Data Warehouse) Hive ...
- Multipath 多路径配置说明
查看主机或者存储交换机上的www号,在存储上将LUN映射给需要的主机 cat /sys/class/fc_host/host*/port_name 0x2002d0431efb7f5d 6d 该ww ...
- 微信小程序跑马灯效果--基于CSS3 animation 及 基于JS
如果本文对你有用,请爱心点个赞,提高排名,帮助更多的人.谢谢大家!❤ 如果解决不了,可以在文末进群交流. 基于CSS3主要代码实现 效果图: 视图模板wxml中: <view class=&qu ...
- (critical) chassis-frontend.c:122: Failed to get log directory, please set by --log-path
Atlas MySQL 读写分离 [root@localhost ~]# /usr/local/mysql-proxy/bin/mysql-proxy test start2019-05-07 10: ...
- Ansible_Day1
1.传统运维&自动化运维概念 1)传统的运维概念(硬件.软件.系统.网络) 手工安装系统.机房建设: 软件服务配置.部署通过手工的操作: 没有自动化脚本.流程: 依靠大量的运维人员完成任务: ...
- Centos 7 SSH 无密码登录
需求 本人使用CENTOS7进行开发调试,所以要经常通过 SSH 连接到服务器进行应用部署与维护.所以,迫切需要有一种方法能够免密码登录到云服务器,而且随处可用. 方案 使用"公私钥&quo ...
- [LeetCode] 0155. Min Stack 最小栈 & C++Runtime加速
题目 Design a stack that supports push, pop, top, and retrieving the minimum element in constant time. ...
- 给定数字N,输出小于10^N的所有整数
讲起来比较简单,从0到N遍历输出就行了,但是如果N非常大,就涉及整数溢出问题,很明显是一个全排列问题,也就是输出N,代表N位上所有的数字取值是0-9,做一个全排列,还需要考虑的就是对于0001,006 ...
- 使用AutoIt实现文件上传
在网页上上传文件的时候,Selenium无法直接操作如Flash.JavaScript 或Ajax 等技术所实现的上传功能,这时候我们需要借用一个叫做AutoIt的软件来帮助我们事先自动化的上传操作. ...