LinkedHashMap及其源码分析
以下内容基于jdk1.7.0_79源码;
什么是LinkedHashMap
继承自HashMap,一个有序的Map接口实现,这里的有序指的是元素可以按插入顺序或访问顺序排列;
LinkedHashMap补充说明
与HashMap的异同:同样是基于散列表实现,区别是,LinkedHashMap内部多了一个双向循环链表的维护,该链表是有序的,可以按元素插入顺序或元素最近访问顺序(LRU)排列,
简单地说:LinkedHashMap=散列表+循环双向链表
LinkedHashMap的数组结构
用画图工具简单画了下散列表和循环双向链表,如下图,简单说明下:
第一张图是LinkedHashMap的全部数据结构,包含散列表和循环双向链表,由于循环双向链表线条太多了,不好画,简单的画了一个节点(黄色圈出来的)示意一下,注意左边的红色箭头引用为Entry节点对象的next引用(散列表中的单链表),绿色线条为Entry节点对象的before, after引用(循环双向链表的前后引用);
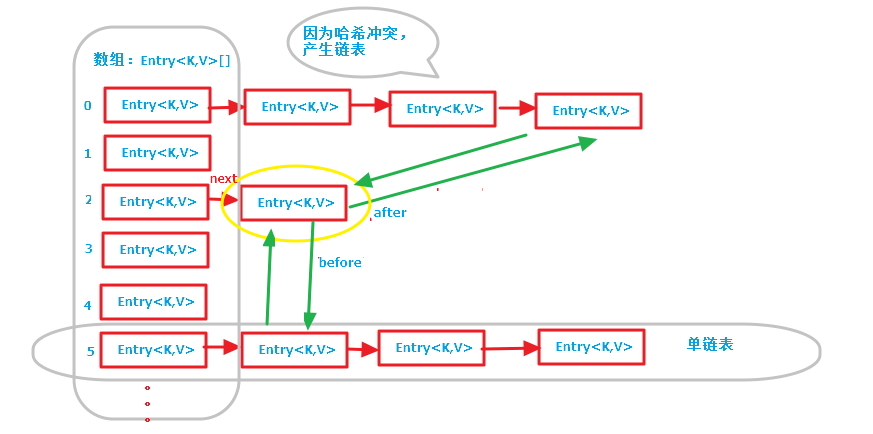
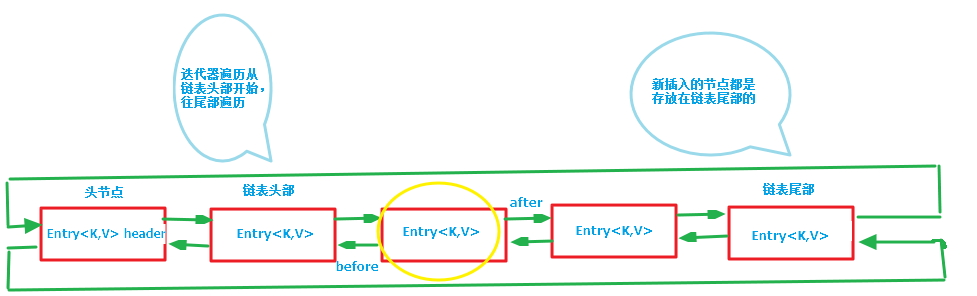
第二张图专门把循环双向链表抽取出来,直观一点,注意该循环双向链表的头部存放的是最久访问的节点或最先插入的节点,尾部为最近访问的或最近插入的节点,迭代器遍历方向是从链表的头部开始到链表尾部结束,在链表尾部有一个空的header节点,该节点不存放key-value内容,为LinkedHashMap类的成员属性,循环双向链表的入口;
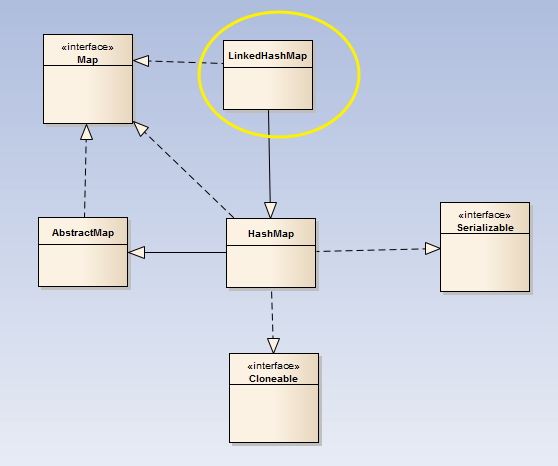
LinkedHashMap继承的类与实现的接口
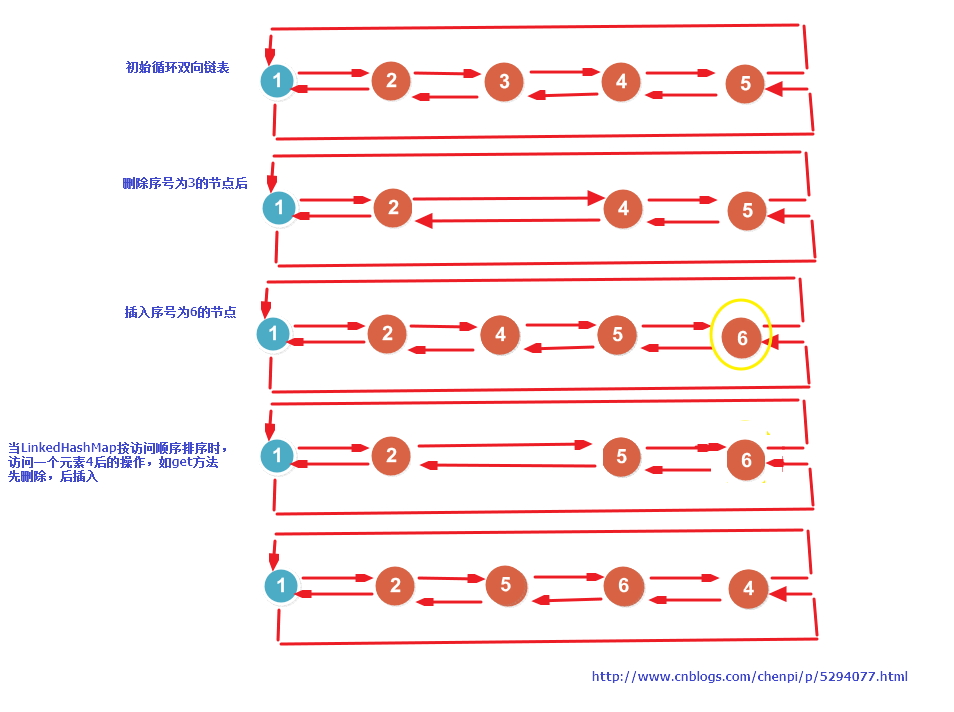
LinkedHashMap源码中双向链表的操作
同样画了一张图,主要是插入删除、操作,如下图,应该挺好理解的,链表的操作
LinkedHashMap源码解析,基本全部加了注释,建议看之前,先看HashMap的源码
package java.util;
import java.io.*; public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{ private static final long serialVersionUID = 3801124242820219131L; /**
* 双向循环链表, 头结点(空节点)
*/
private transient Entry<K,V> header; /**
* accessOrder为true时,按访问顺序排序,false时,按插入顺序排序
*/
private final boolean accessOrder; /**
* 生成一个空的LinkedHashMap,并指定其容量大小和负载因子,
* 默认将accessOrder设为false,按插入顺序排序
*/
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
} /**
* 生成一个空的LinkedHashMap,并指定其容量大小,负载因子使用默认的0.75,
* 默认将accessOrder设为false,按插入顺序排序
*/
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
} /**
* 生成一个空的HashMap,容量大小使用默认值16,负载因子使用默认值0.75
* 默认将accessOrder设为false,按插入顺序排序.
*/
public LinkedHashMap() {
super();
accessOrder = false;
} /**
* 根据指定的map生成一个新的HashMap,负载因子使用默认值,初始容量大小为Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,DEFAULT_INITIAL_CAPACITY)
* 默认将accessOrder设为false,按插入顺序排序.
*/
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(m);
accessOrder = false;
} /**
* 生成一个空的LinkedHashMap,并指定其容量大小和负载因子,
* 默认将accessOrder设为true,按访问顺序排序
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
} /**
* 覆盖HashMap的init方法,在构造方法、Clone、readObject方法里会调用该方法
* 作用是生成一个双向链表头节点,初始化其前后节点引用
*/
@Override
void init() {
header = new Entry<>(-1, null, null, null);
header.before = header.after = header;
} /**
* 覆盖HashMap的transfer方法,性能优化,这里遍历方式不采用HashMap的双重循环方式
* 而是直接通过双向链表遍历Map中的所有key-value映射
*/
@Override
void transfer(HashMap.Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
//遍历旧Map中的所有key-value
for (Entry<K,V> e = header.after; e != header; e = e.after) {
if (rehash)
e.hash = (e.key == null) ? 0 : hash(e.key);
//根据新的数组长度,重新计算索引,
int index = indexFor(e.hash, newCapacity);
//插入到链表表头
e.next = newTable[index];
//将e放到索引为i的数组处
newTable[index] = e;
}
} /**
* 覆盖HashMap的transfer方法,性能优化,这里遍历方式不采用HashMap的双重循环方式
* 而是直接通过双向链表遍历Map中的所有key-value映射,
*/
public boolean containsValue(Object value) {
// Overridden to take advantage of faster iterator
if (value==null) {
for (Entry e = header.after; e != header; e = e.after)
if (e.value==null)
return true;
} else {
for (Entry e = header.after; e != header; e = e.after)
if (value.equals(e.value))
return true;
}
return false;
} /**
* 通过key获取value,与HashMap的区别是:当LinkedHashMap按访问顺序排序的时候,会将访问的当前节点移到链表尾部(头结点的前一个节点)
*/
public V get(Object key) {
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
e.recordAccess(this);
return e.value;
} /**
* 调用HashMap的clear方法,并将LinkedHashMap的头结点前后引用指向自己
*/
public void clear() {
super.clear();
header.before = header.after = header;
} /**
* LinkedHashMap节点对象
*/
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// 节点前后引用
Entry<K,V> before, after; //构造函数与HashMap一致
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
} /**
* 移除节点,并修改前后引用
*/
private void remove() {
before.after = after;
after.before = before;
} /**
* 将当前节点插入到existingEntry的前面
*/
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
} /**
* 在HashMap的put和get方法中,会调用该方法,在HashMap中该方法为空
* 在LinkedHashMap中,当按访问顺序排序时,该方法会将当前节点插入到链表尾部(头结点的前一个节点),否则不做任何事
*/
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//当LinkedHashMap按访问排序时
if (lm.accessOrder) {
lm.modCount++;
//移除当前节点
remove();
//将当前节点插入到头结点前面
addBefore(lm.header);
}
} void recordRemoval(HashMap<K,V> m) {
remove();
}
} //迭代器
private abstract class LinkedHashIterator<T> implements Iterator<T> {
//初始化下个节点引用
Entry<K,V> nextEntry = header.after;
Entry<K,V> lastReturned = null; /**
* 用于迭代期间快速失败行为
*/
int expectedModCount = modCount; //链表遍历结束标志,当下个节点为头节点的时候
public boolean hasNext() {
return nextEntry != header;
} //移除当前访问的节点
public void remove() {
//lastReturned会在nextEntry方法中赋值
if (lastReturned == null)
throw new IllegalStateException();
//快速失败机制
if (modCount != expectedModCount)
throw new ConcurrentModificationException(); LinkedHashMap.this.remove(lastReturned.key);
lastReturned = null;
//迭代器自身删除节点,并不是其他线程修改Map结构,所以这里要修改expectedModCount
expectedModCount = modCount;
} //返回链表下个节点的引用
Entry<K,V> nextEntry() {
//快速失败机制
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
//链表为空情况
if (nextEntry == header)
throw new NoSuchElementException(); //给lastReturned赋值,最近一个从迭代器返回的节点对象
Entry<K,V> e = lastReturned = nextEntry;
nextEntry = e.after;
return e;
}
}
//key迭代器
private class KeyIterator extends LinkedHashIterator<K> {
public K next() { return nextEntry().getKey(); }
}
//value迭代器
private class ValueIterator extends LinkedHashIterator<V> {
public V next() { return nextEntry().value; }
}
//key-value迭代器
private class EntryIterator extends LinkedHashIterator<Map.Entry<K,V>> {
public Map.Entry<K,V> next() { return nextEntry(); }
} // 返回不同的迭代器对象
Iterator<K> newKeyIterator() { return new KeyIterator(); }
Iterator<V> newValueIterator() { return new ValueIterator(); }
Iterator<Map.Entry<K,V>> newEntryIterator() { return new EntryIterator(); } /**
* 创建节点,插入到LinkedHashMap中,该方法覆盖HashMap的addEntry方法
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
super.addEntry(hash, key, value, bucketIndex); // 注意头结点的下个节点即header.after,存放于链表头部,是最不经常访问或第一个插入的节点,
//有必要的情况下(如容量不够,具体看removeEldestEntry方法的实现,这里默认为false,不删除),可以先删除
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
}
} /**
* 创建节点,并将该节点插入到链表尾部
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
//将该节点插入到链表尾部
e.addBefore(header);
size++;
} /**
* 该方法在创建新节点的时候调用,
* 判断是否有必要删除链表头部的第一个节点(最不经常访问或最先插入的节点,由accessOrder决定)
*/
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
}
LinkedHashMap及其源码分析的更多相关文章
- hadoop之hdfs------------------FileSystem及其源码分析
FileSystem及其源码分析 FileSystem这个抽象类提供了丰富的方法用于对文件系统的操作,包括上传.下载.删除.创建等.这里多说的文件系统通常指的是HDFS(DistributedFile ...
- Qt QComboBox之setEditable和currentTextChanged及其源码分析
目录 Qt QComboBox之setEditable和currentTextChanged以及其源码分析 前言 问题的出现 问题分析 currentTextChanged信号触发 源码分析 Qt Q ...
- pdfmake.js使用及其源码分析
公司项目在需要将页面的文本导出成DPF,和支持打印时,一直没有做过这样的功能,花了一点时间将其做了出来,并且本着开源的思想和技术分享的目的,将自己的编码经验分享给大家,希望对大家有用. 现在是有一个文 ...
- 8.深入k8s:资源控制Qos和eviction及其源码分析
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com,源码版本是1.19 又是一个周末,可以愉快的坐下来静静的品味一段源码,这一篇涉及到资源的 ...
- 9.深入k8s:调度器及其源码分析
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com 源码版本是1.19 这次讲解的是k8s的调度器部分的代码,相对来说比较复杂,慢慢的梳理清 ...
- Golang的Context介绍及其源码分析
简介 在Go服务中,对于每个请求,都会起一个协程去处理.在处理协程中,也会起很多协程去访问资源,比如数据库,比如RPC,这些协程还需要访问请求维度的一些信息比如说请求方的身份,授权信息等等.当一个请求 ...
- 13.深入k8s:Pod 水平自动扩缩HPA及其源码分析
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com 源码版本是1.19 Pod 水平自动扩缩 Pod 水平自动扩缩工作原理 Pod 水平自动 ...
- 14.深入k8s:kube-proxy ipvs及其源码分析
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com 源码版本是1.19 这一篇是讲service,但是基础使用以及基本概念由于官方实在是写的 ...
- 15.深入k8s:Event事件处理及其源码分析
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com 源码版本是1.19 概述 k8s的Event事件是一种资源对象,用于展示集群内发生的情况 ...
随机推荐
- vs2010 用户控件拖到aspx页面不可用
错误描述: 在web项目中添加一个用户控件,直接拖动用户控件ascx到aspx页面出现a标签而不是控件标签 解决办法: 把“源”切换为“设计”视图,然后拖动ascx用户控件到页面即可:
- Java总结篇系列:Java String
String作为Java中最常用的引用类型,相对来说基本上都比较熟悉,无论在平时的编码过程中还是在笔试面试中,String都很受到青睐,然而,在使用String过程中,又有较多需要注意的细节之处. 1 ...
- spring3.0结合Redis在项目中的运用
推荐一个程序员的论坛网站:http://ourcoders.com/home/ 以下内容使用到的技术有:Redis缓存.SpringMVC.Maven.项目中使用了redis缓存,目的是在业务场景中, ...
- JavaWeb前端基础复习笔记系列 一
课程:孔浩前端视频教程(CMS内容管理系统case) 1.背景知识 ASPCMS,是一个基于asp的CMS.类似于Jeecms是基于Java的.aspcms:http://www.aspcms.com ...
- 【FOL】第一周
本来打算按计划做下去的,发现原来那个sprite虽然功能强大,但是对我想要做的东西来说,冗余似乎有些多,决定自己写一个. 之前做了一段时间的h5游戏,用的是panda.js,发现这个引擎封装的还不错, ...
- Spring面试基本问题(1)
1.什么是Spring框架?Spring框架有哪些主要模块? Spring框架是一个为Java应用程序的开发提供了综合.广泛的基础性支持的Java平台.Spring帮助开发者解决了开发中基础性的问题, ...
- Linux下安装DB2_v9.7详细教程
一:平台 1:HP服务器 cpu:Inter (R) Xeon (R) E5606 2.13G 磁盘:本地磁盘外加存储 2:操作系统 RedHet 5.4 64位 内核:2.6.18-194.1.AX ...
- jackson中JSON字符串节点遍历和修改
有些场景下,在实现一些基础服务和拦截器的时候,我们可能需要在不知道JSON字符串所属对象类型的情况下,对JSON字符串中的某些属性进行遍历和修改,比如,设置或查询一些报文头字段. 在jackson中, ...
- ecshop适应PHP7的修改
说实话,ecshop这个系统,到目前也没见怎么推出新版本,如果是新项目,不太建议使用它.不过,因为我一直以来都在使用中,所以不得不更改让其适应PHP新版本.现在PHP 7已经出发行版了,所以更改来继续 ...
- phonegap安卓手机开发入门
先安装安卓开发安环境 http://www.cnblogs.com/zhangsanshi/p/3582368.html 安装phonegap 在安装ant http://www.cnblogs.co ...