Spring+quartz 实现定时任务job集群配置
为什么要有集群定时任务?
因为如果多server都触发相同任务,又同时执行,那在99%的场景都是不适合的.比如银行每晚24:00都要汇总营业额.像下面3台server同时进行汇总,最终计算结果可能是真实结果的3倍,那对银行来说是无法想象的,完全不可接受.
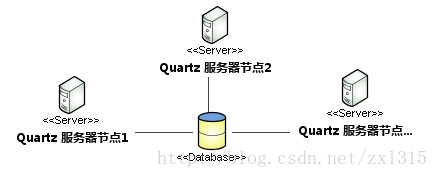
集群定时任务工作原理
所以为了解决以上问题,每个server把将要及正在运行的job所有状态都即时同步到中央数据库,然后再次触发调用时从数据库中分析是否已有别的server正在运行相同job (同名同定时时间点的job属于相当job),如果相同job正在别的server运行,那么当前server忽略本次运行的job.
Quartz的 Task(11 张表)实例化采用数据库存储,基于数据库引擎及 High-Available 的策略(集群的一种策略)自动协调每个节点的 Quartz。
相关下载

git地址: https://git.oschina.net/KingBoBo/SpringQuartzCluster.git
相关文件
ClusterJob.java
说明:集群下工作的Job,仅是实现了Serializable的Bean.
package king.quartz.job; import java.io.Serializable;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory; /**
* 可序列化的集群job
* @author King
*
*/
public class ClusterJob implements Serializable {
public static int i = 0; private static Log log = LogFactory.getLog(ClusterJob.class); public void execute() throws InterruptedException {
log.debug("begin begin begin begin begin begin begin begin ! job = "+ ++i);
System.out.print("job = "+i+" is running ");
for(int j = 1 ; j <= 5;j++){//运行5秒
System.out.print( j +" ");
Thread.sleep(1*1000);
}
System.out.println();
log.debug("end end end end end end end end end end end end ! job = "+ i);
} }
被修改后的MethodInvokingJobDetailFactoryBean
因为spring自带的org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean的invoke()方法不能序列化job,导致无法把序列化后的信息写到表中,这可以算是spring的一个bug.
所以有民间大神修改后的MethodInvokingJobDetailFactoryBean,该Bean的invoke()方法可使job序列化,2拿来直接上手用吧(注意按包路径要和applicationContext-quartz.xml文件中的路径一致)
package king.springframework.scheduling.quartz; import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.quartz.Job;
import org.quartz.JobDetail;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.quartz.Scheduler;
import org.quartz.StatefulJob;
import org.springframework.beans.factory.BeanNameAware;
import org.springframework.beans.factory.FactoryBean;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.context.ApplicationContext;
import org.springframework.util.MethodInvoker; /**
* 该类可让生成的job可以序列化到数据库中,Spring自带的MethodInvokingJobDetailFactoryBean却不能序列化生成的job
* This is a cluster safe Quartz/Spring FactoryBean implementation, which produces a JobDetail implementation that can invoke any no-arg method on any Class.
* <p>
* Use this Class instead of the MethodInvokingJobDetailBeanFactory Class provided by Spring when deploying to a web environment like Tomcat.
* <p>
* <b>Implementation</b><br>
* Instead of associating a MethodInvoker with a JobDetail or a Trigger object, like Spring's MethodInvokingJobDetailFactoryBean does, I made the [Stateful]MethodInvokingJob, which is not persisted in the database, create the MethodInvoker when the [Stateful]MethodInvokingJob is created and executed.
* <p>
* A method can be invoked one of several ways:
* <ul>
* <li>The name of the Class to invoke (targetClass) and the static method to invoke (targetMethod) can be specified.
* <li>The Object to invoke (targetObject) and the static or instance method to invoke (targetMethod) can be specified (the targetObject must be Serializable when concurrent=="false").
* <li>The Class and static Method to invoke can be specified in one property (staticMethod). example: staticMethod = "example.ExampleClass.someStaticMethod"
* <br><b>Note:</b> An Object[] of method arguments can be specified (arguments), but the Objects must be Serializable if concurrent=="false".
* </ul>
* <p>
* I wrote MethodInvokingJobDetailFactoryBean, because Spring's MethodInvokingJobDetailFactoryBean does not produce Serializable
* JobDetail objects, and as a result cannot be deployed into a clustered environment like Tomcat (as is documented within the Class).
* <p>
* <b>Example</b>
* <code>
* <ul>
* <bean id="<i>exampleTrigger</i>" class="org.springframework.scheduling.quartz.CronTriggerBean">
* <ul>
<i><!-- Execute example.ExampleImpl.fooBar() at 2am every day --></i><br>
<property name="<a href="http://www.opensymphony.com/quartz/api/org/quartz/CronTrigger.html">cronExpression</a>" value="0 0 2 * * ?" /><br>
<property name="jobDetail">
<ul>
<bean class="frameworkx.springframework.scheduling.quartz.<b>MethodInvokingJobDetailFactoryBean</b>">
<ul>
<property name="concurrent" value="<i>false</i>"/><br>
<property name="targetClass" value="<i>example.ExampleImpl</i>" /><br>
<property name="targetMethod" value="<i>fooBar</i>" />
</ul>
</bean>
</ul>
</property>
</ul>
</bean>
<p>
<bean class="org.springframework.scheduling.quartz.SchedulerFactoryBean">
<ul>
<property name="triggers">
<ul>
<list>
<ul>
<ref bean="<i>exampleTrigger</i>" />
</ul>
</list>
</ul>
</property>
</ul>
</bean>
</ul>
* </code>
* In this example we created a MethodInvokingJobDetailFactoryBean, which will produce a JobDetail Object with the jobClass property set to StatefulMethodInvokingJob.class (concurrent=="false"; Set to MethodInvokingJob.class when concurrent=="true"), which will in turn invoke the static <code>fooBar</code>() method of the "<code>example.ExampleImpl</code>" Class. The Scheduler is the heart of the whole operation; without it, nothing will happen.
* <p>
* For more information on <code>cronExpression</code> syntax visit <a href="http://www.opensymphony.com/quartz/api/org/quartz/CronTrigger.html">http://www.opensymphony.com/quartz/api/org/quartz/CronTrigger.html</a>
*
* @author Stephen M. Wick
*
* @see #afterPropertiesSet()
*/
public class MethodInvokingJobDetailFactoryBean implements FactoryBean, BeanNameAware, InitializingBean
{
private Log logger = LogFactory.getLog(getClass()); /**
* The JobDetail produced by the <code>afterPropertiesSet</code> method of this Class will be assigned to the Group specified by this property. Default: Scheduler.DEFAULT_GROUP
* @see #afterPropertiesSet()
* @see Scheduler#DEFAULT_GROUP
*/
private String group = Scheduler.DEFAULT_GROUP; /**
* Indicates whether or not the Bean Method should be invoked by more than one Scheduler at the specified time (like when deployed to a cluster, and/or when there are multiple Spring ApplicationContexts in a single JVM<i> - Tomcat 5.5 creates 2 or more instances of the DispatcherServlet (a pool), which in turn creates a separate Spring ApplicationContext for each instance of the servlet</i>)
* <p>
* Used by <code>afterPropertiesSet</code> to set the JobDetail.jobClass to MethodInvokingJob.class or StatefulMethodInvokingJob.class when true or false, respectively. Default: true
* @see #afterPropertiesSet()
*/
private boolean concurrent = true; /** Used to set the JobDetail.durable property. Default: false
* <p>Durability - if a job is non-durable, it is automatically deleted from the scheduler once there are no longer any active triggers associated with it.
* @see <a href="http://www.opensymphony.com/quartz/wikidocs/TutorialLesson3.html">http://www.opensymphony.com/quartz/wikidocs/TutorialLesson3.html</a>
* @see #afterPropertiesSet()
*/
private boolean durable = false; /**
* Used by <code>afterPropertiesSet</code> to set the JobDetail.volatile property. Default: false
* <p>Volatility - if a job is volatile, it is not persisted between re-starts of the Quartz scheduler.
* <p>I set the default to false to be the same as the default for a Quartz Trigger. An exception is thrown
* when the Trigger is non-volatile and the Job is volatile. If you want volatility, then you must set this property, and the Trigger's volatility property, to true.
* @see <a href="http://www.opensymphony.com/quartz/wikidocs/TutorialLesson3.html">http://www.opensymphony.com/quartz/wikidocs/TutorialLesson3.html</a>
* @see #afterPropertiesSet()
*/
private boolean volatility = false; /**
* Used by <code>afterPropertiesSet</code> to set the JobDetail.requestsRecovery property. Default: false<BR>
* <p>RequestsRecovery - if a job "requests recovery", and it is executing during the time of a 'hard shutdown' of the scheduler (i.e. the process it is running within crashes, or the machine is shut off), then it is re-executed when the scheduler is started again. In this case, the JobExecutionContext.isRecovering() method will return true.
* @see <a href="http://www.opensymphony.com/quartz/wikidocs/TutorialLesson3.html">http://www.opensymphony.com/quartz/wikidocs/TutorialLesson3.html</a>
* @see #afterPropertiesSet()
*/
private boolean shouldRecover = false; /**
* A list of names of JobListeners to associate with the JobDetail object created by this FactoryBean.
*
* @see #afterPropertiesSet()
**/
private String[] jobListenerNames; /** The name assigned to this bean in the Spring ApplicationContext.
* Used by <code>afterPropertiesSet</code> to set the JobDetail.name property.
* @see afterPropertiesSet()
* @see JobDetail#setName(String)
**/
private String beanName; /**
* The JobDetail produced by the <code>afterPropertiesSet</code> method, and returned by the <code>getObject</code> method of the Spring FactoryBean interface.
* @see #afterPropertiesSet()
* @see #getObject()
* @see FactoryBean
**/
private JobDetail jobDetail; /**
* The name of the Class to invoke.
**/
private String targetClass; /**
* The Object to invoke.
* <p>
* {@link #targetClass} or targetObject must be set, but not both.
* <p>
* This object must be Serializable when {@link #concurrent} is set to false.
*/
private Object targetObject; /**
* The instance method to invoke on the Class or Object identified by the targetClass or targetObject property, respectfully.
* <p>
* targetMethod or {@link #staticMethod} should be set, but not both.
**/
private String targetMethod; /**
* The static method to invoke on the Class or Object identified by the targetClass or targetObject property, respectfully.
* <p>
* {@link #targetMethod} or staticMethod should be set, but not both.
*/
private String staticMethod; /**
* Method arguments provided to the {@link #targetMethod} or {@link #staticMethod} specified.
* <p>
* All arguments must be Serializable when {@link #concurrent} is set to false.
* <p>
* I strongly urge you not to provide arguments until Quartz 1.6.1 has been released if you are using a JDBCJobStore with
* Microsoft SQL Server. There is a bug in version 1.6.0 that prevents Quartz from Serializing the Objects in the JobDataMap
* to the database. The workaround is to set the property "org.opensymphony.quaryz.useProperties = true" in your quartz.properties file,
* which tells Quartz not to serialize Objects in the JobDataMap, but to instead expect all String compliant values.
*/
private Object[] arguments; /**
* Get the targetClass property.
* @see #targetClass
* @return targetClass
*/
public String getTargetClass()
{
return targetClass;
} /**
* Set the targetClass property.
* @see #targetClass
*/
public void setTargetClass(String targetClass)
{
this.targetClass = targetClass;
} /**
* Get the targetMethod property.
* @see #targetMethod
* @return targetMethod
*/
public String getTargetMethod()
{
return targetMethod;
} /**
* Set the targetMethod property.
* @see #targetMethod
*/
public void setTargetMethod(String targetMethod)
{
this.targetMethod = targetMethod;
} /**
* @return jobDetail - The JobDetail that is created by the afterPropertiesSet method of this FactoryBean
* @see #jobDetail
* @see #afterPropertiesSet()
* @see FactoryBean#getObject()
*/
public Object getObject() throws Exception
{
return jobDetail;
} /**
* @return JobDetail.class
* @see FactoryBean#getObjectType()
*/
public Class getObjectType()
{
return JobDetail.class;
} /**
* @return true
* @see FactoryBean#isSingleton()
*/
public boolean isSingleton()
{
return true;
} /**
* Set the beanName property.
* @see #beanName
* @see BeanNameAware#setBeanName(String)
*/
public void setBeanName(String beanName)
{
this.beanName = beanName;
} /**
* Invoked by the Spring container after all properties have been set.
* <p>
* Sets the <code>jobDetail</code> property to a new instance of JobDetail
* <ul>
* <li>jobDetail.name is set to <code>beanName</code><br>
* <li>jobDetail.group is set to <code>group</code><br>
* <li>jobDetail.jobClass is set to MethodInvokingJob.class or StatefulMethodInvokingJob.class depending on whether the <code>concurrent</code> property is set to true or false, respectively.<br>
* <li>jobDetail.durability is set to <code>durable</code>
* <li>jobDetail.volatility is set to <code>volatility</code>
* <li>jobDetail.requestsRecovery is set to <code>shouldRecover</code>
* <li>jobDetail.jobDataMap["targetClass"] is set to <code>targetClass</code>
* <li>jobDetail.jobDataMap["targetMethod"] is set to <code>targetMethod</code>
* <li>Each JobListener name in <code>jobListenerNames</code> is added to the <code>jobDetail</code> object.
* </ul>
* <p>
* Logging occurs at the DEBUG and INFO levels; 4 lines at the DEBUG level, and 1 line at the INFO level.
* <ul>
* <li>DEBUG: start
* <li>DEBUG: Creating JobDetail <code>{beanName}</code>
* <li>DEBUG: Registering JobListener names with JobDetail object <code>{beanName}</code>
* <li>INFO: Created JobDetail: <code>{jobDetail}</code>; targetClass: <code>{targetClass}</code>; targetMethod: <code>{targetMethod}</code>;
* <li>DEBUG: end
* </ul>
* @see org.springframework.beans.factory.InitializingBean#afterPropertiesSet()
* @see JobDetail
* @see #jobDetail
* @see #beanName
* @see #group
* @see MethodInvokingJob
* @see StatefulMethodInvokingJob
* @see #durable
* @see #volatility
* @see #shouldRecover
* @see #targetClass
* @see #targetMethod
* @see #jobListenerNames
*/
public void afterPropertiesSet() throws Exception
{
try
{
logger.debug("start"); logger.debug("Creating JobDetail "+beanName);
jobDetail = new JobDetail();
jobDetail.setName(beanName);
jobDetail.setGroup(group);
jobDetail.setJobClass(concurrent ? MethodInvokingJob.class : StatefulMethodInvokingJob.class);
jobDetail.setDurability(durable);
jobDetail.setVolatility(volatility);
jobDetail.setRequestsRecovery(shouldRecover);
if(targetClass!=null)
jobDetail.getJobDataMap().put("targetClass", targetClass);
if(targetObject!=null)
jobDetail.getJobDataMap().put("targetObject", targetObject);
if(targetMethod!=null)
jobDetail.getJobDataMap().put("targetMethod", targetMethod);
if(staticMethod!=null)
jobDetail.getJobDataMap().put("staticMethod", staticMethod);
if(arguments!=null)
jobDetail.getJobDataMap().put("arguments", arguments); logger.debug("Registering JobListener names with JobDetail object "+beanName);
if (this.jobListenerNames != null) {
for (int i = 0; i < this.jobListenerNames.length; i++) {
this.jobDetail.addJobListener(this.jobListenerNames[i]);
}
}
logger.info("Created JobDetail: "+jobDetail+"; targetClass: "+targetClass+"; targetObject: "+targetObject+"; targetMethod: "+targetMethod+"; staticMethod: "+staticMethod+"; arguments: "+arguments+";");
}
finally
{
logger.debug("end");
}
} /**
* Setter for the concurrent property.
*
* @param concurrent
* @see #concurrent
*/
public void setConcurrent(boolean concurrent)
{
this.concurrent = concurrent;
} /**
* setter for the durable property.
*
* @param durable
*
* @see #durable
*/
public void setDurable(boolean durable)
{
this.durable = durable;
} /**
* setter for the group property.
*
* @param group
*
* @see #group
*/
public void setGroup(String group)
{
this.group = group;
} /**
* setter for the {@link #jobListenerNames} property.
*
* @param jobListenerNames
* @see #jobListenerNames
*/
public void setJobListenerNames(String[] jobListenerNames)
{
this.jobListenerNames = jobListenerNames;
} /**
* setter for the {@link #shouldRecover} property.
*
* @param shouldRecover
* @see #shouldRecover
*/
public void setShouldRecover(boolean shouldRecover)
{
this.shouldRecover = shouldRecover;
} /**
* setter for the {@link #volatility} property.
*
* @param volatility
* @see #volatility
*/
public void setVolatility(boolean volatility)
{
this.volatility = volatility;
} /**
* This is a cluster safe Job designed to invoke a method on any bean defined within the same Spring
* ApplicationContext.
* <p>
* The only entries this Job expects in the JobDataMap are "targetClass" and "targetMethod".<br>
* - It uses the value of the <code>targetClass</code> entry to get the desired bean from the Spring ApplicationContext.<br>
* - It uses the value of the <code>targetMethod</code> entry to determine which method of the Bean (identified by targetClass) to invoke.
* <p>
* It uses the static ApplicationContext in the MethodInvokingJobDetailFactoryBean,
* which is ApplicationContextAware, to get the Bean with which to invoke the method.
* <p>
* All Exceptions thrown from the execute method are caught and wrapped in a JobExecutionException.
*
* @see MethodInvokingJobDetailFactoryBean#applicationContext
* @see #execute(JobExecutionContext)
*
* @author Stephen M. Wick
*/
public static class MethodInvokingJob implements Job
{
protected Log logger = LogFactory.getLog(getClass()); /**
* When invoked by a Quartz scheduler, <code>execute</code> invokes a method on a Class or Object in the JobExecutionContext provided.
* <p>
* <b>Implementation</b><br>
* The Class is identified by the "targetClass" entry in the JobDataMap of the JobExecutionContext provided. If targetClass is specified, then targetMethod must be a static method.<br>
* The Object is identified by the 'targetObject" entry in the JobDataMap of the JobExecutionContext provided. If targetObject is provided, then targetClass will be overwritten. This Object must be Serializable when <code>concurrent</code> is set to false.<br>
* The method is identified by the "targetMethod" entry in the JobDataMap of the JobExecutionContext provided.<br>
* The "staticMethod" entry in the JobDataMap of the JobExecutionContext can be used to specify a Class and Method in one entry (ie: "example.ExampleClass.someStaticMethod")<br>
* The method arguments (an array of Objects) are identified by the "arguments" entry in the JobDataMap of the JobExecutionContext. All arguments must be Serializable when <code>concurrent</code> is set to false.
* <p>
* Logging is provided at the DEBUG and INFO levels; 8 lines at the DEBUG level, and 1 line at the INFO level.
* @see Job#execute(JobExecutionContext)
*/
public void execute(JobExecutionContext context) throws JobExecutionException
{
try
{
logger.debug("start");
String targetClass = context.getMergedJobDataMap().getString("targetClass");
logger.debug("targetClass is "+targetClass);
Class targetClassClass = null;
if(targetClass!=null)
{
targetClassClass = Class.forName(targetClass); // Could throw ClassNotFoundException
}
Object targetObject = context.getMergedJobDataMap().get("targetObject");
logger.debug("targetObject is "+targetObject);
String targetMethod = context.getMergedJobDataMap().getString("targetMethod");
logger.debug("targetMethod is "+targetMethod);
String staticMethod = context.getMergedJobDataMap().getString("staticMethod");
logger.debug("staticMethod is "+staticMethod);
Object[] arguments = (Object[])context.getMergedJobDataMap().get("arguments");
logger.debug("arguments are "+arguments); logger.debug("creating MethodInvoker");
MethodInvoker methodInvoker = new MethodInvoker();
methodInvoker.setTargetClass(targetClassClass);
methodInvoker.setTargetObject(targetObject);
methodInvoker.setTargetMethod(targetMethod);
methodInvoker.setStaticMethod(staticMethod);
methodInvoker.setArguments(arguments);
methodInvoker.prepare();
logger.info("Invoking: "+methodInvoker.getPreparedMethod().toGenericString());
methodInvoker.invoke();
}
catch(Exception e)
{
throw new JobExecutionException(e);
}
finally
{
logger.debug("end");
}
}
} public static class StatefulMethodInvokingJob extends MethodInvokingJob implements StatefulJob
{
// No additional functionality; just needs to implement StatefulJob.
} public Object[] getArguments()
{
return arguments;
} public void setArguments(Object[] arguments)
{
this.arguments = arguments;
} public String getStaticMethod()
{
return staticMethod;
} public void setStaticMethod(String staticMethod)
{
this.staticMethod = staticMethod;
} public void setTargetObject(Object targetObject)
{
this.targetObject = targetObject;
}
}
web.xml
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://java.sun.com/xml/ns/javaee" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd" id="WebApp_ID" version="2.5">
<display-name>SpringQuartzCluster</display-name>
<welcome-file-list>
<welcome-file>index.jsp</welcome-file>
</welcome-file-list>
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:applicationContext-quartz.xml</param-value>
</context-param>
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
<servlet>
<servlet-name>dispatcher</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>dispatcher</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
<session-config>
<session-timeout>60</session-timeout>
</session-config>
</web-app>
applicationContext-quartz.xml
正常情况应该从applicationContext.xml的总配置文件中import该applicationContext-quartz.xml. 由于小项目,直接作为总配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.0.xsd"
default-lazy-init="false" default-autowire="byName"> <!-- ClusterJob -->
<bean id="clusterJob" class="king.quartz.job.ClusterJob" /> <!-- ClusterJobDetail -->
<bean id="clusterJobDetail"
class="king.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean">
<!-- concurrent(并发) : false表示等上一个任务执行完后再开启新的任务 -->
<property name="concurrent" value="false" />
<property name="shouldRecover" value="true" />
<property name="targetObject" ref="clusterJob" />
<property name="targetMethod" value="execute" />
</bean> <!-- ClusterCronTriggerBean -->
<bean id="clusterCronTriggerBean" class="org.springframework.scheduling.quartz.CronTriggerBean">
<property name="jobDetail" ref="clusterJobDetail" />
<property name="cronExpression" value="0/7 * * * * ? *" /> <!-- 每10秒触发一次 -->
</bean> <!-- ClusterSchedulerFactoryBean -->
<bean id="clusterSchedulerFactoryBean"
class="org.springframework.scheduling.quartz.SchedulerFactoryBean">
<!-- 指定quartz配置文件 -->
<property name="configLocation" value="classpath:quartz.properties" />
<!--必QuartzScheduler 延时启动,应用启动完后 QuartzScheduler 再启动,单位秒 -->
<property name="startupDelay" value="1" />
<!-- 设置自动启动 -->
<property name="autoStartup" value="true" />
<property name="applicationContextSchedulerContextKey" value="applicationContextKey" />
<property name="triggers">
<list>
<ref bean="clusterCronTriggerBean" />
</list>
</property>
</bean> </beans>
quartz.properties
该配置文件一定要放在classpath目录下,因为SchedulerFactoryBean直接引用了configuration配置,所以还要配置相关数据源,见尾部Configure DataSource,其它保持原样即可,当然如果要调优的话里面参数肯定可以........
#============================================================================
# Configure Main Scheduler Properties
#============================================================================
org.quartz.scheduler.instanceName = DefaultQuartzScheduler
org.quartz.scheduler.instanceId = AUTO
org.quartz.scheduler.rmi.export = false
org.quartz.scheduler.rmi.proxy = false
org.quartz.scheduler.wrapJobExecutionInUserTransaction = false #============================================================================
# Configure ThreadPool
#============================================================================
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount =
org.quartz.threadPool.threadPriority =
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread = true #============================================================================
# Configure JobStore
#============================================================================
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.oracle.OracleDelegate
org.quartz.jobStore.misfireThreshold =
org.quartz.jobStore.useProperties = false
org.quartz.jobStore.tablePrefix = QRTZ_
org.quartz.jobStore.dataSource = myDS org.quartz.jobStore.isClustered = true
org.quartz.jobStore.clusterCheckinInterval = #============================================================================
# Configure DataSource
#============================================================================
org.quartz.dataSource.myDS.driver = oracle.jdbc.driver.OracleDriver
org.quartz.dataSource.myDS.URL = jdbc:oracle:thin:@192.168.1.214::DWXDBDEV
org.quartz.dataSource.myDS.user = bobo
org.quartz.dataSource.myDS.password =
org.quartz.dataSource.myDS.maxConnections =
#org.quartz.dataSource.myDS.driver = oracle.jdbc.driver.OracleDriver
#org.quartz.dataSource.myDS.URL = jdbc:oracle:thin:@LonelyTear-PC::ORACLEDB
#org.quartz.dataSource.myDS.user = bobo
#org.quartz.dataSource.myDS.password = b
#org.quartz.dataSource.myDS.maxConnections =
Main方法入口
package king.quartz.main;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class Main {
public static void main(String[] args) {
//下面的非web形式直接加载可能会导致job同时加载并执行2次,原因不明(历史印象是用了log4j的日志会导致该情况)
//只能做普通测试用,最好在Tomcat等容器中以web形式运行,且指明docBase路径
new ClassPathXmlApplicationContext("applicationContext-quartz.xml");
}
}
当我们启动2次Main方法,最终只有一个Main会运行,如下:
job = 65 is running 1 2 3 4 5
job = 66 is running 1 2 3 4 5
job = 67 is running 1 2 3 4 5
job = 68 is running 1 2 3 4 5
job = 69 is running 1 2 3 4 5
job = 70 is running 1 2 3 4 5
job = 71 is running 1 2 3 4 5
sql
特别注意下面的sql版本要和squartz完全一致,在解压后的quartz\quartz-1.8.6\docs\dbTables文件夹在都有
tables_mysql_innodb.sql
mysql对应数据表,拉下来全导入执行一遍
#
# In your Quartz properties file, you'll need to set
# org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
#
#
# By: Ron Cordell - roncordell
# I didn't see this anywhere, so I thought I'd post it here. This is the script from Quartz to create the tables in a MySQL database, modified to use INNODB instead of MYISAM. DROP TABLE IF EXISTS QRTZ_JOB_LISTENERS;
DROP TABLE IF EXISTS QRTZ_TRIGGER_LISTENERS;
DROP TABLE IF EXISTS QRTZ_FIRED_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_PAUSED_TRIGGER_GRPS;
DROP TABLE IF EXISTS QRTZ_SCHEDULER_STATE;
DROP TABLE IF EXISTS QRTZ_LOCKS;
DROP TABLE IF EXISTS QRTZ_SIMPLE_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_CRON_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_BLOB_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_JOB_DETAILS;
DROP TABLE IF EXISTS QRTZ_CALENDARS;
CREATE TABLE QRTZ_JOB_DETAILS(
JOB_NAME VARCHAR(200) NOT NULL,
JOB_GROUP VARCHAR(200) NOT NULL,
DESCRIPTION VARCHAR(250) NULL,
JOB_CLASS_NAME VARCHAR(250) NOT NULL,
IS_DURABLE VARCHAR(1) NOT NULL,
IS_VOLATILE VARCHAR(1) NOT NULL,
IS_STATEFUL VARCHAR(1) NOT NULL,
REQUESTS_RECOVERY VARCHAR(1) NOT NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (JOB_NAME,JOB_GROUP))
TYPE=InnoDB; CREATE TABLE QRTZ_JOB_LISTENERS (
JOB_NAME VARCHAR(200) NOT NULL,
JOB_GROUP VARCHAR(200) NOT NULL,
JOB_LISTENER VARCHAR(200) NOT NULL,
PRIMARY KEY (JOB_NAME,JOB_GROUP,JOB_LISTENER),
INDEX (JOB_NAME, JOB_GROUP),
FOREIGN KEY (JOB_NAME,JOB_GROUP)
REFERENCES QRTZ_JOB_DETAILS(JOB_NAME,JOB_GROUP))
TYPE=InnoDB; CREATE TABLE QRTZ_TRIGGERS (
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
JOB_NAME VARCHAR(200) NOT NULL,
JOB_GROUP VARCHAR(200) NOT NULL,
IS_VOLATILE VARCHAR(1) NOT NULL,
DESCRIPTION VARCHAR(250) NULL,
NEXT_FIRE_TIME BIGINT(13) NULL,
PREV_FIRE_TIME BIGINT(13) NULL,
PRIORITY INTEGER NULL,
TRIGGER_STATE VARCHAR(16) NOT NULL,
TRIGGER_TYPE VARCHAR(8) NOT NULL,
START_TIME BIGINT(13) NOT NULL,
END_TIME BIGINT(13) NULL,
CALENDAR_NAME VARCHAR(200) NULL,
MISFIRE_INSTR SMALLINT(2) NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (TRIGGER_NAME,TRIGGER_GROUP),
INDEX (JOB_NAME, JOB_GROUP),
FOREIGN KEY (JOB_NAME,JOB_GROUP)
REFERENCES QRTZ_JOB_DETAILS(JOB_NAME,JOB_GROUP))
TYPE=InnoDB; CREATE TABLE QRTZ_SIMPLE_TRIGGERS (
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
REPEAT_COUNT BIGINT(7) NOT NULL,
REPEAT_INTERVAL BIGINT(12) NOT NULL,
TIMES_TRIGGERED BIGINT(10) NOT NULL,
PRIMARY KEY (TRIGGER_NAME,TRIGGER_GROUP),
INDEX (TRIGGER_NAME, TRIGGER_GROUP),
FOREIGN KEY (TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(TRIGGER_NAME,TRIGGER_GROUP))
TYPE=InnoDB; CREATE TABLE QRTZ_CRON_TRIGGERS (
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
CRON_EXPRESSION VARCHAR(120) NOT NULL,
TIME_ZONE_ID VARCHAR(80),
PRIMARY KEY (TRIGGER_NAME,TRIGGER_GROUP),
INDEX (TRIGGER_NAME, TRIGGER_GROUP),
FOREIGN KEY (TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(TRIGGER_NAME,TRIGGER_GROUP))
TYPE=InnoDB; CREATE TABLE QRTZ_BLOB_TRIGGERS (
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
BLOB_DATA BLOB NULL,
PRIMARY KEY (TRIGGER_NAME,TRIGGER_GROUP),
INDEX (TRIGGER_NAME, TRIGGER_GROUP),
FOREIGN KEY (TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(TRIGGER_NAME,TRIGGER_GROUP))
TYPE=InnoDB; CREATE TABLE QRTZ_TRIGGER_LISTENERS (
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
TRIGGER_LISTENER VARCHAR(200) NOT NULL,
PRIMARY KEY (TRIGGER_NAME,TRIGGER_GROUP,TRIGGER_LISTENER),
INDEX (TRIGGER_NAME, TRIGGER_GROUP),
FOREIGN KEY (TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(TRIGGER_NAME,TRIGGER_GROUP))
TYPE=InnoDB; CREATE TABLE QRTZ_CALENDARS (
CALENDAR_NAME VARCHAR(200) NOT NULL,
CALENDAR BLOB NOT NULL,
PRIMARY KEY (CALENDAR_NAME))
TYPE=InnoDB; CREATE TABLE QRTZ_PAUSED_TRIGGER_GRPS (
TRIGGER_GROUP VARCHAR(200) NOT NULL,
PRIMARY KEY (TRIGGER_GROUP))
TYPE=InnoDB; CREATE TABLE QRTZ_FIRED_TRIGGERS (
ENTRY_ID VARCHAR(95) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
IS_VOLATILE VARCHAR(1) NOT NULL,
INSTANCE_NAME VARCHAR(200) NOT NULL,
FIRED_TIME BIGINT(13) NOT NULL,
PRIORITY INTEGER NOT NULL,
STATE VARCHAR(16) NOT NULL,
JOB_NAME VARCHAR(200) NULL,
JOB_GROUP VARCHAR(200) NULL,
IS_STATEFUL VARCHAR(1) NULL,
REQUESTS_RECOVERY VARCHAR(1) NULL,
PRIMARY KEY (ENTRY_ID))
TYPE=InnoDB; CREATE TABLE QRTZ_SCHEDULER_STATE (
INSTANCE_NAME VARCHAR(200) NOT NULL,
LAST_CHECKIN_TIME BIGINT(13) NOT NULL,
CHECKIN_INTERVAL BIGINT(13) NOT NULL,
PRIMARY KEY (INSTANCE_NAME))
TYPE=InnoDB; CREATE TABLE QRTZ_LOCKS (
LOCK_NAME VARCHAR(40) NOT NULL,
PRIMARY KEY (LOCK_NAME))
TYPE=InnoDB; INSERT INTO QRTZ_LOCKS values('TRIGGER_ACCESS');
INSERT INTO QRTZ_LOCKS values('JOB_ACCESS');
INSERT INTO QRTZ_LOCKS values('CALENDAR_ACCESS');
INSERT INTO QRTZ_LOCKS values('STATE_ACCESS');
INSERT INTO QRTZ_LOCKS values('MISFIRE_ACCESS');
commit;
tables_oracle.sql
oracle对应数据表,拉下来全导入执行一遍
--
-- A hint submitted by a user: Oracle DB MUST be created as "shared" and the
-- job_queue_processes parameter must be greater than 2, otherwise a DB lock
-- will happen. However, these settings are pretty much standard after any
-- Oracle install, so most users need not worry about this.
--
-- Many other users (including the primary author of Quartz) have had success
-- runing in dedicated mode, so only consider the above as a hint ;-)
-- delete from qrtz_job_listeners;
delete from qrtz_trigger_listeners;
delete from qrtz_fired_triggers;
delete from qrtz_simple_triggers;
delete from qrtz_cron_triggers;
delete from qrtz_blob_triggers;
delete from qrtz_triggers;
delete from qrtz_job_details;
delete from qrtz_calendars;
delete from qrtz_paused_trigger_grps;
delete from qrtz_locks;
delete from qrtz_scheduler_state; drop table qrtz_calendars;
drop table qrtz_fired_triggers;
drop table qrtz_trigger_listeners;
drop table qrtz_blob_triggers;
drop table qrtz_cron_triggers;
drop table qrtz_simple_triggers;
drop table qrtz_triggers;
drop table qrtz_job_listeners;
drop table qrtz_job_details;
drop table qrtz_paused_trigger_grps;
drop table qrtz_locks;
drop table qrtz_scheduler_state; CREATE TABLE qrtz_job_details
(
JOB_NAME VARCHAR2(200) NOT NULL,
JOB_GROUP VARCHAR2(200) NOT NULL,
DESCRIPTION VARCHAR2(250) NULL,
JOB_CLASS_NAME VARCHAR2(250) NOT NULL,
IS_DURABLE VARCHAR2(1) NOT NULL,
IS_VOLATILE VARCHAR2(1) NOT NULL,
IS_STATEFUL VARCHAR2(1) NOT NULL,
REQUESTS_RECOVERY VARCHAR2(1) NOT NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (JOB_NAME,JOB_GROUP)
);
CREATE TABLE qrtz_job_listeners
(
JOB_NAME VARCHAR2(200) NOT NULL,
JOB_GROUP VARCHAR2(200) NOT NULL,
JOB_LISTENER VARCHAR2(200) NOT NULL,
PRIMARY KEY (JOB_NAME,JOB_GROUP,JOB_LISTENER),
FOREIGN KEY (JOB_NAME,JOB_GROUP)
REFERENCES QRTZ_JOB_DETAILS(JOB_NAME,JOB_GROUP)
);
CREATE TABLE qrtz_triggers
(
TRIGGER_NAME VARCHAR2(200) NOT NULL,
TRIGGER_GROUP VARCHAR2(200) NOT NULL,
JOB_NAME VARCHAR2(200) NOT NULL,
JOB_GROUP VARCHAR2(200) NOT NULL,
IS_VOLATILE VARCHAR2(1) NOT NULL,
DESCRIPTION VARCHAR2(250) NULL,
NEXT_FIRE_TIME NUMBER(13) NULL,
PREV_FIRE_TIME NUMBER(13) NULL,
PRIORITY NUMBER(13) NULL,
TRIGGER_STATE VARCHAR2(16) NOT NULL,
TRIGGER_TYPE VARCHAR2(8) NOT NULL,
START_TIME NUMBER(13) NOT NULL,
END_TIME NUMBER(13) NULL,
CALENDAR_NAME VARCHAR2(200) NULL,
MISFIRE_INSTR NUMBER(2) NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (JOB_NAME,JOB_GROUP)
REFERENCES QRTZ_JOB_DETAILS(JOB_NAME,JOB_GROUP)
);
CREATE TABLE qrtz_simple_triggers
(
TRIGGER_NAME VARCHAR2(200) NOT NULL,
TRIGGER_GROUP VARCHAR2(200) NOT NULL,
REPEAT_COUNT NUMBER(7) NOT NULL,
REPEAT_INTERVAL NUMBER(12) NOT NULL,
TIMES_TRIGGERED NUMBER(10) NOT NULL,
PRIMARY KEY (TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(TRIGGER_NAME,TRIGGER_GROUP)
);
CREATE TABLE qrtz_cron_triggers
(
TRIGGER_NAME VARCHAR2(200) NOT NULL,
TRIGGER_GROUP VARCHAR2(200) NOT NULL,
CRON_EXPRESSION VARCHAR2(120) NOT NULL,
TIME_ZONE_ID VARCHAR2(80),
PRIMARY KEY (TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(TRIGGER_NAME,TRIGGER_GROUP)
);
CREATE TABLE qrtz_blob_triggers
(
TRIGGER_NAME VARCHAR2(200) NOT NULL,
TRIGGER_GROUP VARCHAR2(200) NOT NULL,
BLOB_DATA BLOB NULL,
PRIMARY KEY (TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(TRIGGER_NAME,TRIGGER_GROUP)
);
CREATE TABLE qrtz_trigger_listeners
(
TRIGGER_NAME VARCHAR2(200) NOT NULL,
TRIGGER_GROUP VARCHAR2(200) NOT NULL,
TRIGGER_LISTENER VARCHAR2(200) NOT NULL,
PRIMARY KEY (TRIGGER_NAME,TRIGGER_GROUP,TRIGGER_LISTENER),
FOREIGN KEY (TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(TRIGGER_NAME,TRIGGER_GROUP)
);
CREATE TABLE qrtz_calendars
(
CALENDAR_NAME VARCHAR2(200) NOT NULL,
CALENDAR BLOB NOT NULL,
PRIMARY KEY (CALENDAR_NAME)
);
CREATE TABLE qrtz_paused_trigger_grps
(
TRIGGER_GROUP VARCHAR2(200) NOT NULL,
PRIMARY KEY (TRIGGER_GROUP)
);
CREATE TABLE qrtz_fired_triggers
(
ENTRY_ID VARCHAR2(95) NOT NULL,
TRIGGER_NAME VARCHAR2(200) NOT NULL,
TRIGGER_GROUP VARCHAR2(200) NOT NULL,
IS_VOLATILE VARCHAR2(1) NOT NULL,
INSTANCE_NAME VARCHAR2(200) NOT NULL,
FIRED_TIME NUMBER(13) NOT NULL,
PRIORITY NUMBER(13) NOT NULL,
STATE VARCHAR2(16) NOT NULL,
JOB_NAME VARCHAR2(200) NULL,
JOB_GROUP VARCHAR2(200) NULL,
IS_STATEFUL VARCHAR2(1) NULL,
REQUESTS_RECOVERY VARCHAR2(1) NULL,
PRIMARY KEY (ENTRY_ID)
);
CREATE TABLE qrtz_scheduler_state
(
INSTANCE_NAME VARCHAR2(200) NOT NULL,
LAST_CHECKIN_TIME NUMBER(13) NOT NULL,
CHECKIN_INTERVAL NUMBER(13) NOT NULL,
PRIMARY KEY (INSTANCE_NAME)
);
CREATE TABLE qrtz_locks
(
LOCK_NAME VARCHAR2(40) NOT NULL,
PRIMARY KEY (LOCK_NAME)
);
INSERT INTO qrtz_locks values('TRIGGER_ACCESS');
INSERT INTO qrtz_locks values('JOB_ACCESS');
INSERT INTO qrtz_locks values('CALENDAR_ACCESS');
INSERT INTO qrtz_locks values('STATE_ACCESS');
INSERT INTO qrtz_locks values('MISFIRE_ACCESS');
create index idx_qrtz_j_req_recovery on qrtz_job_details(REQUESTS_RECOVERY);
create index idx_qrtz_t_next_fire_time on qrtz_triggers(NEXT_FIRE_TIME);
create index idx_qrtz_t_state on qrtz_triggers(TRIGGER_STATE);
create index idx_qrtz_t_nft_st on qrtz_triggers(NEXT_FIRE_TIME,TRIGGER_STATE);
create index idx_qrtz_t_volatile on qrtz_triggers(IS_VOLATILE);
create index idx_qrtz_ft_trig_name on qrtz_fired_triggers(TRIGGER_NAME);
create index idx_qrtz_ft_trig_group on qrtz_fired_triggers(TRIGGER_GROUP);
create index idx_qrtz_ft_trig_nm_gp on qrtz_fired_triggers(TRIGGER_NAME,TRIGGER_GROUP);
create index idx_qrtz_ft_trig_volatile on qrtz_fired_triggers(IS_VOLATILE);
create index idx_qrtz_ft_trig_inst_name on qrtz_fired_triggers(INSTANCE_NAME);
create index idx_qrtz_ft_job_name on qrtz_fired_triggers(JOB_NAME);
create index idx_qrtz_ft_job_group on qrtz_fired_triggers(JOB_GROUP);
create index idx_qrtz_ft_job_stateful on qrtz_fired_triggers(IS_STATEFUL);
create index idx_qrtz_ft_job_req_recovery on qrtz_fired_triggers(REQUESTS_RECOVERY); commit;
遇见异常
异常一 No row exists in table QRTZ_LOCKS for lock named: TRIGGER_ACCESS.
该异常产生原因是,我项目中用的是quartz-1.8.6的jar,但由于quartz版本差异过大,在不知情的情况下从官网down了最新的quartz-2.2.3且把2.2.3的dbTables文件夹下的tables_oracle.sql导了进来.所以最终和1.8.6的表结构不一致.
就目前来看quartz-2.2.3的tables_oracle.sql比1.8.6的合理很多,1.8.6建表始化时还会建一些尴尬的外键关联,这是让我极不喜欢的一点.
异常如下,请点击展开
log4j:WARN No appenders could be found for logger (king.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean).
log4j:WARN Please initialize the log4j system properly.
Exception in thread "main" org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'clusterSchedulerFactoryBean' defined in class path resource [applicationContext-quartz.xml]: Invocation of init method failed; nested exception is org.quartz.impl.jdbcjobstore.LockException: Failure obtaining db row lock: No row exists in table QRTZ_LOCKS for lock named: TRIGGER_ACCESS [See nested exception: java.sql.SQLException: No row exists in table QRTZ_LOCKS for lock named: TRIGGER_ACCESS]
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.initializeBean(AbstractAutowireCapableBeanFactory.java:1338)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:473)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory$1.run(AbstractAutowireCapableBeanFactory.java:409)
at java.security.AccessController.doPrivileged(Native Method)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:380)
at org.springframework.beans.factory.support.AbstractBeanFactory$1.getObject(AbstractBeanFactory.java:264)
at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:222)
at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:261)
at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:185)
at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:164)
at org.springframework.beans.factory.support.DefaultListableBeanFactory.preInstantiateSingletons(DefaultListableBeanFactory.java:423)
at org.springframework.context.support.AbstractApplicationContext.finishBeanFactoryInitialization(AbstractApplicationContext.java:728)
at org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:380)
at org.springframework.context.support.ClassPathXmlApplicationContext.<init>(ClassPathXmlApplicationContext.java:139)
at org.springframework.context.support.ClassPathXmlApplicationContext.<init>(ClassPathXmlApplicationContext.java:83)
at king.quartz.main.Main.main(Main.java:10)
Caused by: org.quartz.impl.jdbcjobstore.LockException: Failure obtaining db row lock: No row exists in table QRTZ_LOCKS for lock named: TRIGGER_ACCESS [See nested exception: java.sql.SQLException: No row exists in table QRTZ_LOCKS for lock named: TRIGGER_ACCESS]
at org.quartz.impl.jdbcjobstore.StdRowLockSemaphore.executeSQL(StdRowLockSemaphore.java:109)
at org.quartz.impl.jdbcjobstore.DBSemaphore.obtainLock(DBSemaphore.java:112)
at org.quartz.impl.jdbcjobstore.JobStoreSupport.executeInNonManagedTXLock(JobStoreSupport.java:3781)
at org.quartz.impl.jdbcjobstore.JobStoreTX.executeInLock(JobStoreTX.java:90)
at org.quartz.impl.jdbcjobstore.JobStoreSupport.executeInLock(JobStoreSupport.java:3712)
at org.quartz.impl.jdbcjobstore.JobStoreSupport.storeJob(JobStoreSupport.java:1095)
at org.quartz.core.QuartzScheduler.addJob(QuartzScheduler.java:905)
at org.quartz.impl.StdScheduler.addJob(StdScheduler.java:266)
at org.springframework.scheduling.quartz.SchedulerAccessor.addJobToScheduler(SchedulerAccessor.java:317)
at org.springframework.scheduling.quartz.SchedulerAccessor.addTriggerToScheduler(SchedulerAccessor.java:340)
at org.springframework.scheduling.quartz.SchedulerAccessor.registerJobsAndTriggers(SchedulerAccessor.java:276)
at org.springframework.scheduling.quartz.SchedulerFactoryBean.afterPropertiesSet(SchedulerFactoryBean.java:483)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.invokeInitMethods(AbstractAutowireCapableBeanFactory.java:1369)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.initializeBean(AbstractAutowireCapableBeanFactory.java:1335)
... 15 more
Caused by: java.sql.SQLException: No row exists in table QRTZ_LOCKS for lock named: TRIGGER_ACCESS
at org.quartz.impl.jdbcjobstore.StdRowLockSemaphore.executeSQL(StdRowLockSemaphore.java:91)
... 28 more
异常二 在xml配置中把定时任务的配置全删了,竟然还是执行了
这是spring的一个bug,所以需要去查询这三张表,它们储存了定时任务,把相关的定时任务删了即可
delete from QRTZ_CRON_TRIGGERS where TRIGGER_NAME = 'echannel.synchronizeJobTrigger'; delete from QRTZ_TRIGGERS where TRIGGER_NAME = 'echannel.synchronizeJobTrigger'; delete from QRTZ_JOB_DETAILS where job_name = 'echannel.synchronize.content';
其它无关紧要的资料
SimpleTriggerBean
简易版Spring触发器,功能和org.springframework.scheduling.quartz.CronTriggerBean相似
<!-- ClusterSimpleTriggerBean 未使用,被注释了 -->
<bean id="clusterSimpleTriggerBean" class="org.springframework.scheduling.quartz.SimpleTriggerBean">
<property name="startDelay" value="10000" />
<property name="repeatInterval" value="10000" />
<property name="jobDetail" ref="clusterJobDetail" />
</bean>
参考
Spring+quartz集群配置,Spring定时任务集群,quartz定时任务集群(强烈推荐)
本文原创,转载请说明出处 by 金墨痴 http://www.cnblogs.com/whatlonelytear/p/5823837.html
Spring+quartz 实现定时任务job集群配置的更多相关文章
- Spring+quartz 实现定时任务job集群配置【原】
为什么要有集群定时任务? 因为如果多server都触发相同任务,又同时执行,那在99%的场景都是不适合的.比如银行每晚24:00都要汇总营业额.像下面3台server同时进行汇总,最终计算结果可能是真 ...
- Spring Cloud(Dalston.SR5)--Config 集群配置中心
Spring Cloud Config 是一个全新的项目,用来为分布式系统中的基础设施和微服务应用提供集中化的外部配置支持,他分为服务端和客户端两个部分.服务端也称为分布式配置中心,是一个独立的微服务 ...
- Spring Cloud(Dalston.SR5)--Config 集群配置中心-加解密
实际应用中会涉及很多敏感的数据,这些数据会被加密保存到 SVN 仓库中,最常见的就是数据库密码.Spring Cloud Config 为这类敏感数据提供了加密和解密的功能,加密后的密文在传输给客户端 ...
- Spring Cloud(Dalston.SR5)--Config 集群配置中心-刷新配置
远程 SVN 服务器上面的配置修改后,需要通知客户端来改变配置,需要增加 spring-boot-starter-actuator 依赖并将 management.security.enabled 设 ...
- spring boot JedisCluster连接redis集群配置
配置文件 配置类 构造的时候, 可以看一下, 只有Set<HostAndPort> 参数是必须的 做了一层封装, 更方便使用 结果
- Spring+quartz集群配置,Spring定时任务集群,quartz定时任务集群
Spring+quartz集群配置,Spring定时任务集群,quartz定时任务集群 >>>>>>>>>>>>>> ...
- Spring整合Quartz定时任务 在集群、分布式系统中的应用(Mysql数据库环境)
Spring整合Quartz定时任务 在集群.分布式系统中的应用(Mysql数据库环境) 转载:http://www.cnblogs.com/jiafuwei/p/6145280.html 单个Q ...
- 浅析Quartz的集群配置
浅析Quartz的集群配置(一) 收藏人:Rozdy 2015-01-13 | 阅:1 转:22 | 来源 | 分享 1 基本信息 摘要:Quar ...
- Spring+Quartz 实现定时任务的配置方法
Spring+Quartz 实现定时任务的配置方法 整体介绍 一.Quartz介绍 在企业应用中,我们经常会碰到时间任务调度的需求,比如每天凌晨生成前天报表,每小时生成一次汇总数据等等.Quartz是 ...
随机推荐
- 转 @html.ActionLink的几种参数格式
一 Html.ActionLink("linkText","actionName") 该重载的第一个参数是该链接要显示的文字,第二个参数是对应的控制器的方法, ...
- 从一个int值显示相应枚举类型的名称或者描述
我正在做一个出入库管理的简单项目,在Models里定义了这样的枚举类型 public enum InOrOut { [Description("出库")] Out = , [Des ...
- R语言 三个函数sort();rank();order()
R语言入门,弄懂了几个简单的函数,分享一下:R语言排序有几个基本函数: sort():rank():order()sort()是对向量进行从小到大的排序rank()返回的是对向量中每个数值对应的秩or ...
- java写入excel文件poi
java写入excel文件 java写入excel文件poi,支持xlsx与xls,没有文件自动创建 package com.utils; import java.io.File; import ja ...
- oracle计算两行差值
Lag和Lead分析函数可以在同一次查询中取出同一字段的前N行的数据(Lag)和后N行的数据(Lead)作为独立的列. 这种操作可以代替表的自联接,并且LAG和LEAD有更高的效率. SELECT c ...
- 进击的docker 一 : Docker 简介
Docker简介 1.什么是docker 1.1.docker 起源 开源项目 诞生2013年初 GO语言开发实现 遵从了Apache2.0协议 项目代码在GitHub维护 1.2.docker目标 ...
- WEBPACK开始
这是一个非常简单的例子,通过这个例子你将学习到 1.How to install webpack 2.How to use webpack 3.How to use loaders 4.How to ...
- C/C++程序员应聘试题剖析(转载)
转载自:http://www.cnitblog.com/zouzheng/articles/21856.html 1.引言 本文的写作目的并不在于提供C/C++程序员求职面试指导,而旨在从技术上分析面 ...
- 将字母变为其下个字母(abc变为bcd)
题目描述 输入一行电报文字,将字母变成其下一字母(如'a'变成'b'--'z'变成'a'其它字符不变). 输入 一行字符 输出 加密处理后的字符 样例输入 a b 样例输出 b c#include & ...
- python 实现 斐波那契数列
#!usr/bin/python#_*_coding=utf-8_*_ def fin(n): li=[0,1] for i in range(2,n): li.append(li[-1]+li[-2 ...