基于sklearn的波士顿房价预测_线性回归学习笔记
> 以下内容是我在学习https://blog.csdn.net/mingxiaod/article/details/85938251 教程时遇到不懂的问题自己查询并理解的笔记,由于sklearn版本更迭改动了原作者的代码,如有理解偏差欢迎指正。
1. np.linspace
np.linspace(1,10) 在numpy中生成一个等差数列,可以加三个参数,np.linspace(1,10,10)在是两个参数时默认生成五十个数字的等差数列,第一第二哥数字分别代表数列的开头和结尾,如果是三哥参数,第三个参数代表等差数列的长度,既可以生成一个长度为10数字开头为1结尾为10的等差数列(1,2,3,4,5,6,7,8,9,10)
2. plt.subplot(nrows, ncols, index, **kwargs)
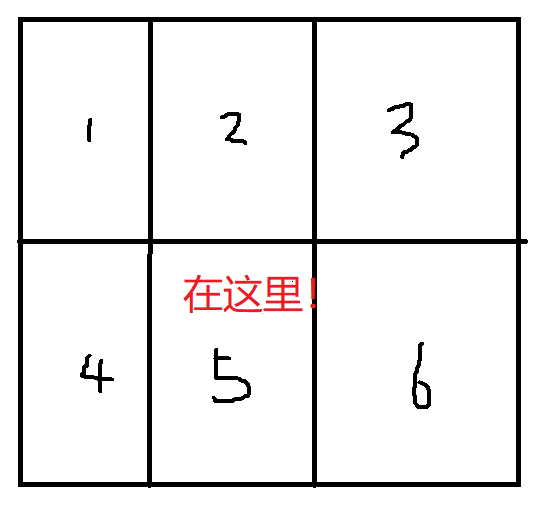
plt.subploy(2,3,5)这个代码的核心意思就是使用”整数来描述子图的位置信息“,顾名思义就是在一个画布中画多个图片,第一个参数nrows代表你把画布分为多少行,ncols代表你把画布分为多少列,index就更好理解了,它的意思就是接下来要画的图的索引位置,比如(2,3,5)他代表的意思就是把一张空白的画布分为两行,三列。六个位置区域,第三个索引参数一般就是从左上角开始到右下角依次编号(如下图),我查阅资料的时候有的博主强行机器翻译官方文档,并注明第三个参数不能大于10,其实不然,官方的意思是index<= nrows*ncols,也就是索引数字不能大于已有的画布分割数量。还有就是(2,3,5)与(235)效果等同,至于第三个参数**kwargs,作用是设置子图类型,极点图或线型图。
3.np.delete(x_data,abnormal_data,axis = 0)
第一个参数代表要处理的数据矩阵,第二个参数代表在什么位置处理(一般为一维数组),第三个参数 0 代表删除所在列,1代表删除所在行。
1 from sklearn import preprocessing
2 from sklearn.datasets import load_boston
3 from sklearn.metrics import r2_score
4 from sklearn.linear_model import LinearRegression
5 from sklearn.model_selection import train_test_split
6 import matplotlib.pyplot as plt
7 import numpy as np
8
9 #数据初始化
10 dataset = load_boston()
11 x_data,y_data=load_boston(return_X_y = True) #导入数据,x_data为特征变量、y_data为目标值
12 print("--------------'''获取自变量数据的形状'''--------------")
13 print(x_data.shape)
14 print(y_data.shape)
15 name_data = dataset.feature_names #导入特证名
16
17 #数据可视化
18 for i in range(len(name_data)):
19 plt.scatter(x_data[:,i],y_data,s = 20,marker = '<',c = 'r')
20 plt.title(name_data[i])
21 plt.show()
22 #处理异常数据
23 abnormal_data = []
24 for i in range(len(y_data)):
25 if y_data[i] == 50:
26 abnormal_data.append(i)#存储异常值的下标;
27 x_data = np.delete(x_data,abnormal_data,axis = 0)#删除值为y值为50的特征变量所在行
28 y_data = np.delete(y_data,abnormal_data,axis = 0)#删除值为y值为50的特征值所在行
29 print("------检测-------")
30 print(x_data.shape)
31 print(y_data.shape)
32
33 abnormal_title = []
34 for i in range(len(name_data)):
35 if name_data[i] == 'RM' or name_data[i] =='PTRATIO'or name_data[i] == 'LSTAT':
36 continue
37 else:
38 abnormal_title.append(i)#存储不相关数据特证名下标
39 x_data = np.delete(x_data,abnormal_title,axis = 1)#删除不相关数据所在列
40 print("--------------'''输出有效数据形状'''--------------")
41 print(x_data.shape)
42 print(y_data.shape)
43
44 #数据分割
45 x_train,x_test = train_test_split(x_data,test_size=0.2,random_state=0)
46 y_train,y_test = train_test_split(y_data,test_size=0.2,random_state=0)
47 print("--------------'''输出实验数据长度'''--------------")
48 print(len(x_train))
49 print(len(x_test))
50 print(len(y_train))
51 print(len(y_test))
52
53 #数据归一化(无量纲化处理β=(x-min(x))/max(x)-min(x),将数据归集到0~1之间)
54 min_max_scaler = preprocessing.MinMaxScaler()
55 x_test = min_max_scaler.fit_transform(x_test)
56 x_train = min_max_scaler.fit_transform(x_train)
57 y_train = min_max_scaler.fit_transform(y_train.reshape(-1,1))
58 y_test = min_max_scaler.fit_transform(y_test.reshape(-1,1))#转化为一列行自动确认
59 #模型训练和评估
60 lr = LinearRegression()
61 lr.fit(x_train,y_train)
62 lr_y_predict = lr.predict(x_test)
63 #使用r2_score预测样本
64 score = r2_score(y_test, lr_y_predict)
65 print("样本预测得分:{}".format(score))
输出结果:
--------------'''获取自变量数据的形状'''--------------
(506, 13)
(506,)
------检测-------
(490, 13)
(490,)
--------------'''输出有效数据形状'''--------------
(490, 3)
(490,)
--------------'''输出实验数据长度'''--------------
392
98
392
98
样本预测得分:0.7091901425426
基于sklearn的波士顿房价预测_线性回归学习笔记的更多相关文章
- 机器学习实战二:波士顿房价预测 Boston Housing
波士顿房价预测 Boston housing 这是一个波士顿房价预测的一个实战,上一次的Titantic是生存预测,其实本质上是一个分类问题,就是根据数据分为1或为0,这次的波士顿房价预测更像是预测一 ...
- 波士顿房价预测 - 最简单入门机器学习 - Jupyter
机器学习入门项目分享 - 波士顿房价预测 该分享源于Udacity机器学习进阶中的一个mini作业项目,用于入门非常合适,刨除了繁琐的部分,保留了最关键.基本的步骤,能够对机器学习基本流程有一个最清晰 ...
- 使用sklearn进行数据挖掘-房价预测(5)—训练模型
使用sklearn进行数据挖掘系列文章: 1.使用sklearn进行数据挖掘-房价预测(1) 2.使用sklearn进行数据挖掘-房价预测(2)-划分测试集 3.使用sklearn进行数据挖掘-房价预 ...
- 使用sklearn进行数据挖掘-房价预测(4)—数据预处理
在使用机器算法之前,我们先把数据做下预处理,先把特征和标签拆分出来 housing = strat_train_set.drop("median_house_value",axis ...
- 使用sklearn进行数据挖掘-房价预测(6)—模型调优
通过上一节的探索,我们会得到几个相对比较满意的模型,本节我们就对模型进行调优 网格搜索 列举出参数组合,直到找到比较满意的参数组合,这是一种调优方法,当然如果手动选择并一一进行实验这是一个十分繁琐的工 ...
- 使用sklearn进行数据挖掘-房价预测(1)
使用sklearn进行数据挖掘系列文章: 1.使用sklearn进行数据挖掘-房价预测(1) 2.使用sklearn进行数据挖掘-房价预测(2)-划分测试集 3.使用sklearn进行数据挖掘-房价预 ...
- 使用sklearn进行数据挖掘-房价预测(2)—划分测试集
使用sklearn进行数据挖掘系列文章: 1.使用sklearn进行数据挖掘-房价预测(1) 2.使用sklearn进行数据挖掘-房价预测(2)-划分测试集 3.使用sklearn进行数据挖掘-房价预 ...
- 使用sklearn进行数据挖掘-房价预测(3)—绘制数据的分布
使用sklearn进行数据挖掘系列文章: 1.使用sklearn进行数据挖掘-房价预测(1) 2.使用sklearn进行数据挖掘-房价预测(2)-划分测试集 3.使用sklearn进行数据挖掘-房价预 ...
- Tensorflow之多元线性回归问题(以波士顿房价预测为例)
一.根据波士顿房价信息进行预测,多元线性回归+特征数据归一化 #读取数据 %matplotlib notebook import tensorflow as tf import matplotlib. ...
随机推荐
- Dart Generic All In One
Dart Generic All In One Dart 泛型 https://dart.dev/guides/language/language-tour#generics /** * * @aut ...
- Deno 1.0 & Node.js
Deno 1.0 & Node.js A secure runtime for JavaScript and TypeScript. https://deno.land/v1 https:// ...
- Dva & Umi
Dva & Umi Dva.js & Umi.js React & Redux https://dvajs.com/ React and redux based, lightw ...
- Docker使用指南
上文简单介绍了docker,这边记录一下docker的使用. 一.Docker启停 1.启动docker systemctl start docker 2.关闭docker systemctl sto ...
- mui调用本地相册调用相机上传照片
调用mui的常用库和jquery html部分: <header class="mui-bar mui-bar-nav"> <a class="mui- ...
- 微信小程序:页面全局参数(注意不是小程序的全局变量globalData)
为什么要使用页面全局参数:方便使用数据. 由于总页数需要再另外的一个方法中使用,所以要把总页数变成一个页面全局参数.因为取数据使用this.xxx即可,中间不用加data,给页面全局参数赋值页方便,直 ...
- SpringCloud之服务配置
1.config 1.1定义 对于分布式微服务,有很多的配置,那么修改起来很麻烦.这就需要对这些配置文件进行集中式的管理,config的功能就是用来统一管理配置文件的.它为微服务提供集中化的外部配置支 ...
- Java基础语法:abstract修饰符
一.简介 描述: 'abstract'修饰符可以用来修饰方法,也可以修饰类. 如果修饰方法,那么该方法就是抽象方法:如果修饰类,那么该类就是抽象类. 抽象类和抽象方法起到一个框架作用,方便后期扩展的重 ...
- Python2和Python3编码的区别
Python2 python2中有两种储存变量的形式,第一种:Unicode:第二种:按照coding头来的. 假设python2用utf8存储x='中文',当你print(x)的时候,终端接收gbk ...
- 如何用Eggjs从零开始开发一个项目(1)
前言 "纸上得来终觉浅,绝知此事要躬行."虽然node一直在断断续续地学,但总是东一榔头西一榔头的,没有一点系统,所以打算写一个项目来串联一下之前的学习成果. 为什么选择Eggjs ...