大数据体系概览Spark、Spark核心原理、架构原理、Spark特点
大数据体系概览Spark、Spark核心原理、架构原理、Spark特点
小提示:这里,使用axure(原型制作工具),来画图十分方便,个人认为比viso或者是processon等流程图制作工具简单多了。
点击链接,看取axure画完以后生成的html网页。
spark的axure原型
效果图:
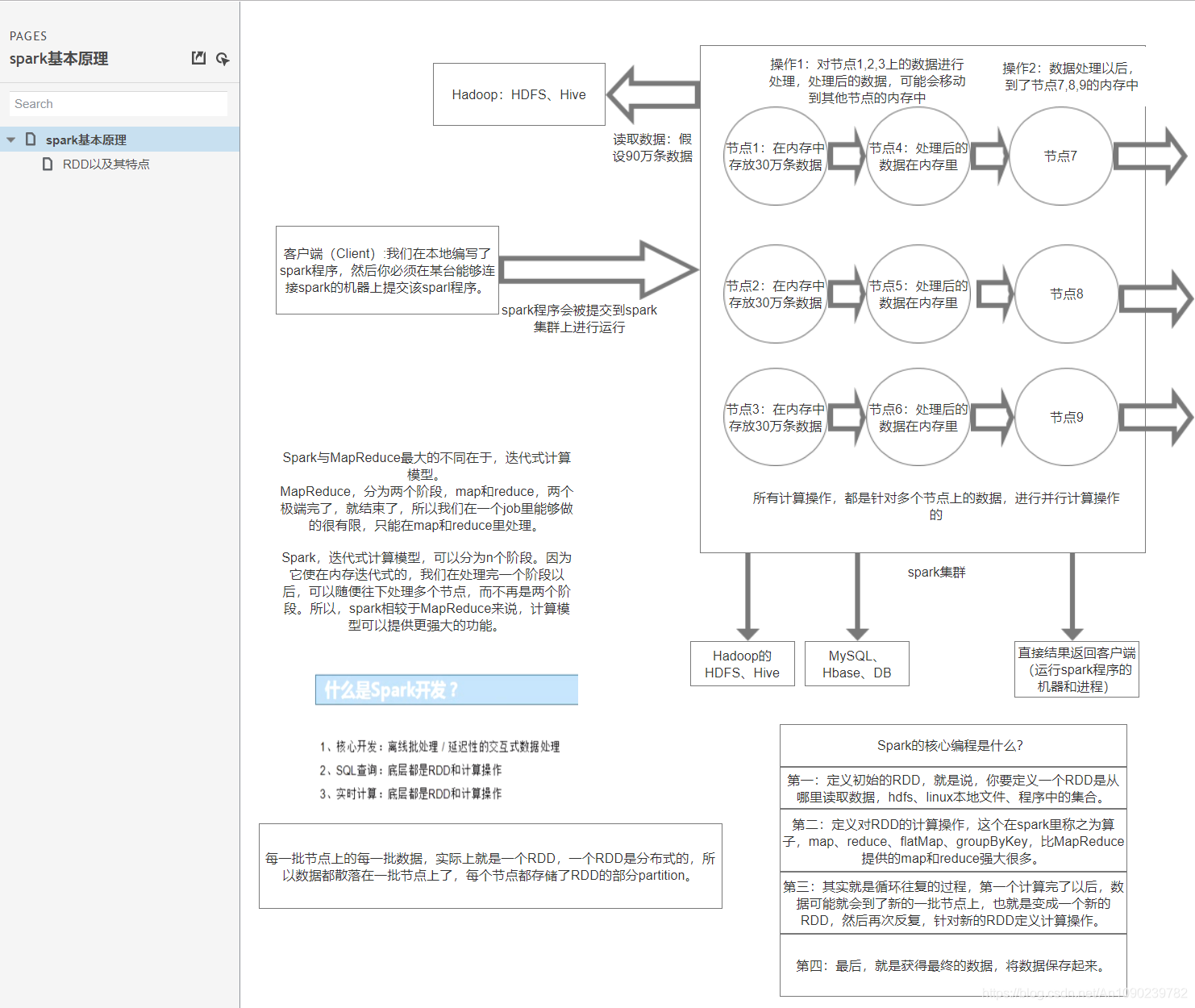
大数据体系概览(Spark的地位)
Hadoop生态圈重点组件:
HDFS:Hadoop的分布式文件存储系统。
MapReduce:Hadoop的分布式程序运算框架,也可以叫做一种编程模型。
Hive:基于Hadoop的类SQL数据仓库工具
Hbase:基于Hadoop的列式分布式NoSQL数据库
ZooKeeper:分布式协调服务组件
Mahout:基于MapReduce/Flink/Spark等分布式运算框架的机器学习算法库
Oozie/Azkaban:工作流调度引擎
Sqoop:数据迁入迁出工具
Flume:日志采集工具
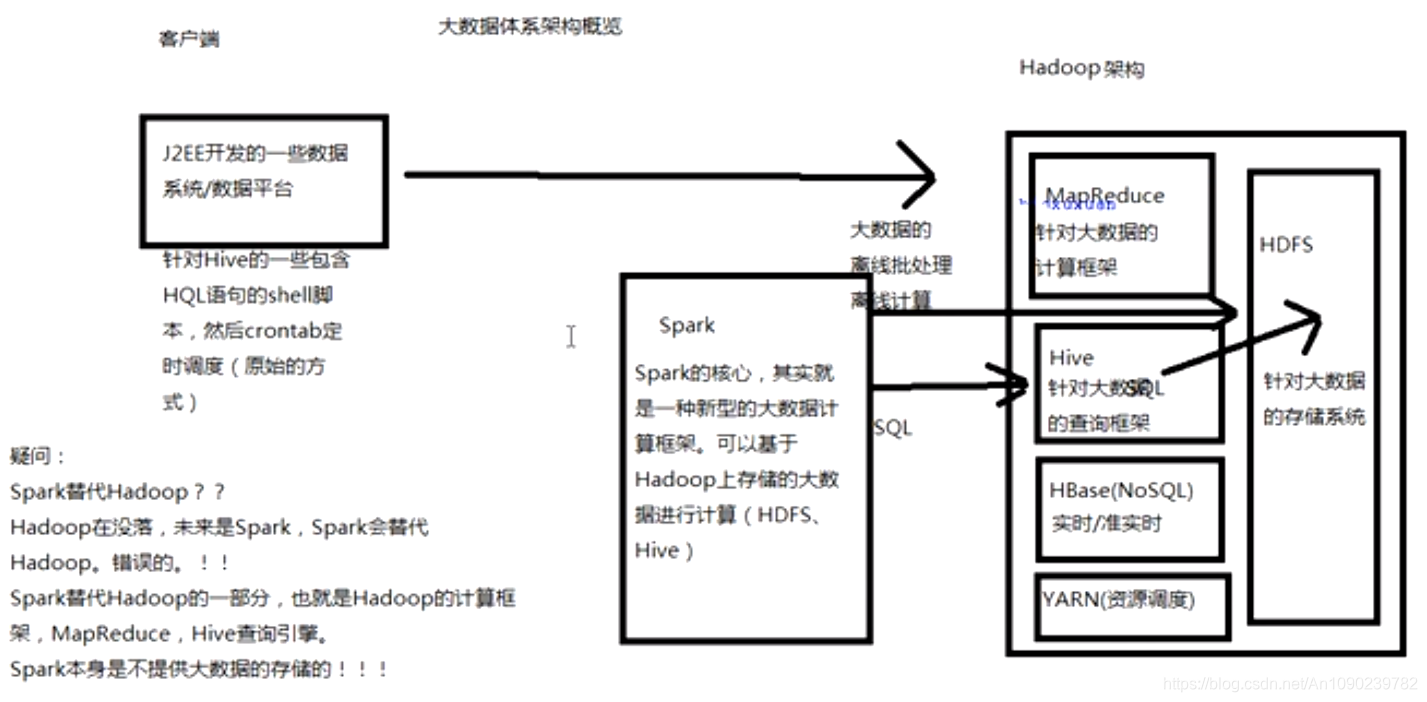
什么是Spark?
Spark,是一种通用的大数据计算框架,如Hadoop的MapReduce、Hive引擎,以及Storm流式实时计算引擎等。
Spark包含了大数据领域常见的各种计算框架:比如Spark Core用于离线计算,Spark SQL用于交互式查询,Spark Streaming用于实时流式计算,Spark MLlib用于机器学习,Spark Graphx用于图计算。
Spark主要用于大数据的计算,而Hadoop主要用于大数据的存储(比如HDFS、Hive、HBase),以及资源调度(Yarn)。
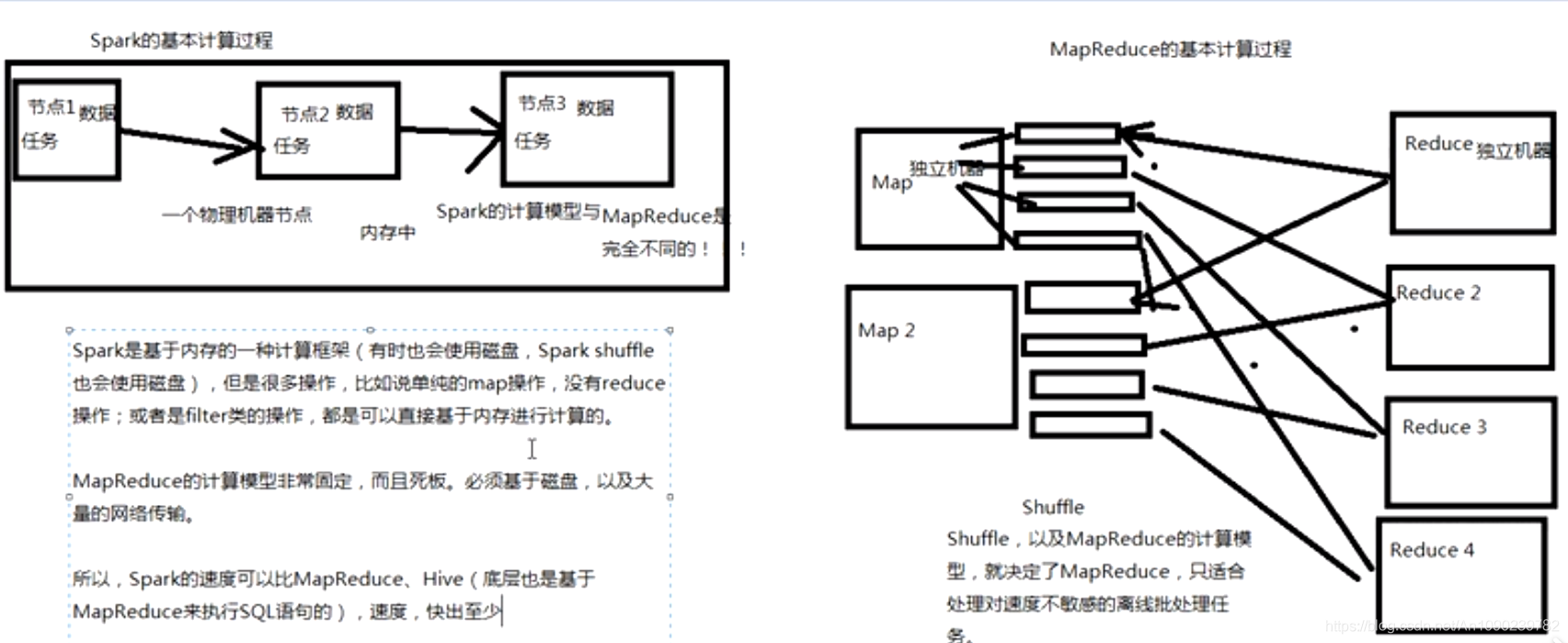
Spark除了一站式的特点之外,就是基于内存进行计算,从而让它的速度可以达到MapReduce、Hive的数倍甚至十倍!
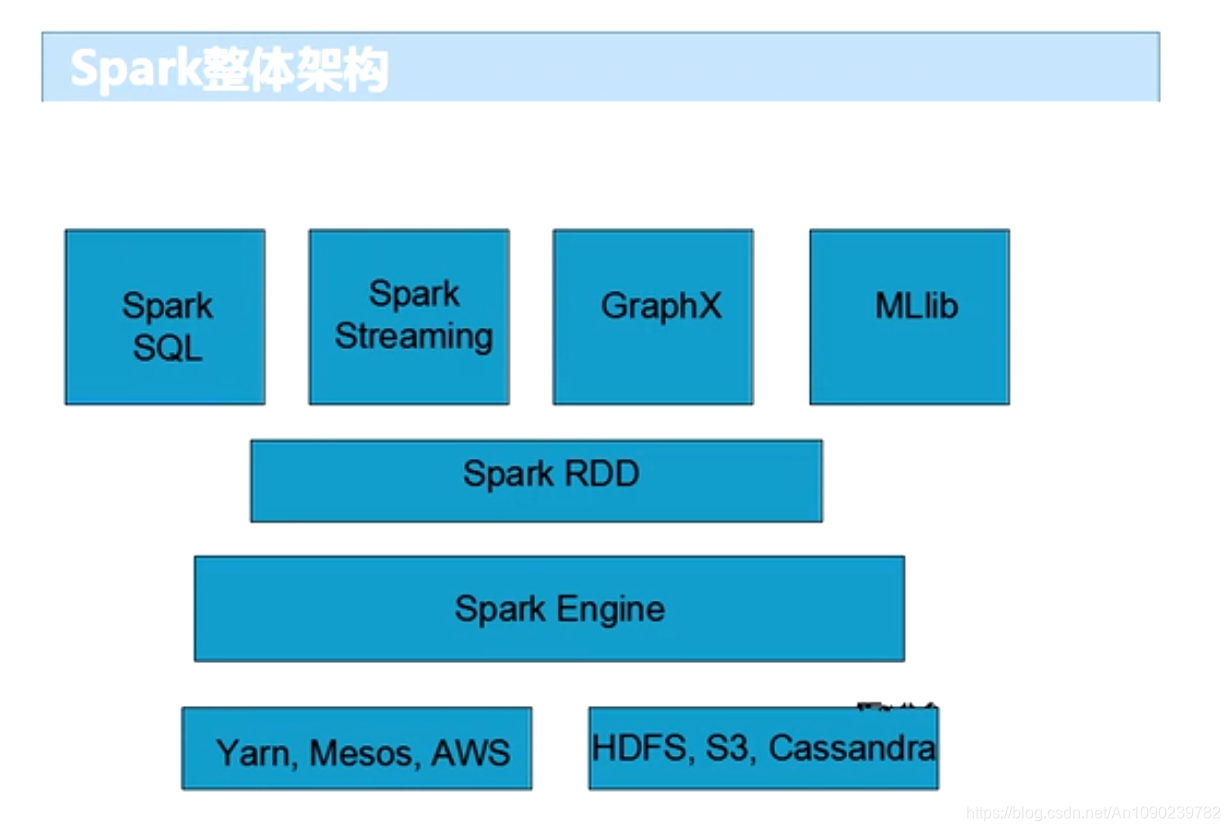
Spark整体架构
Spark的特点
- 速度快:Spark基于内存计算(部分基于磁盘,如shuffle)
- 超强的通用性:Spark提供了Spark RDD、Spark SQL、Spark Streaming、Spark MLlib、Spark Graphx等组件,可以一站式完成大数据领域的离线批处理、交互式查询、流式计算、机器学习、图形计算等常见的任务。
- 集成Hadoop:与Hadoop进行了高度的集成,Hadoop的HDFS、Hive、HBase负责存储,Yarn负责资源调度,Spark负责大数据计算。
Spark核心原理
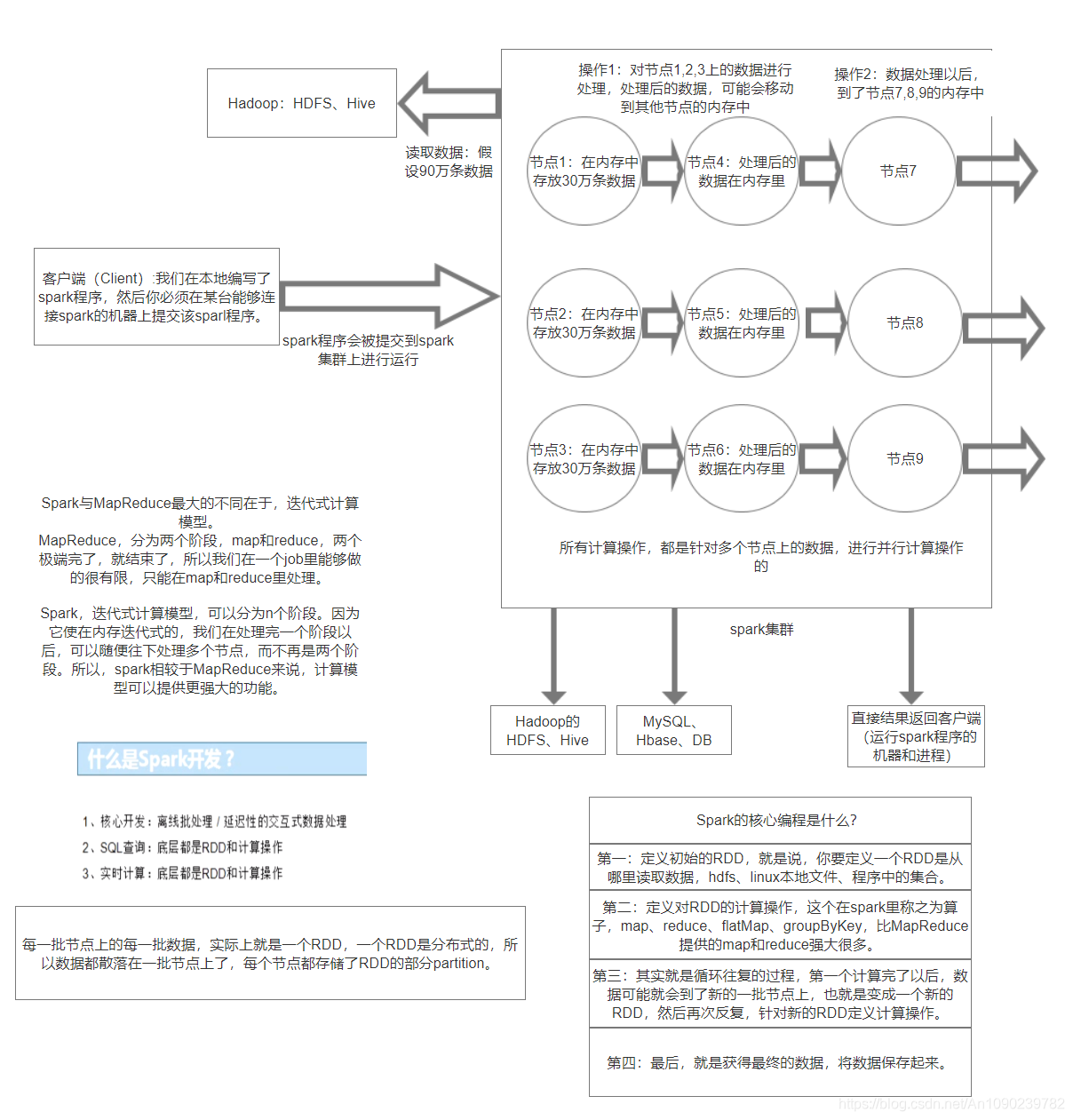
Spark架构原理
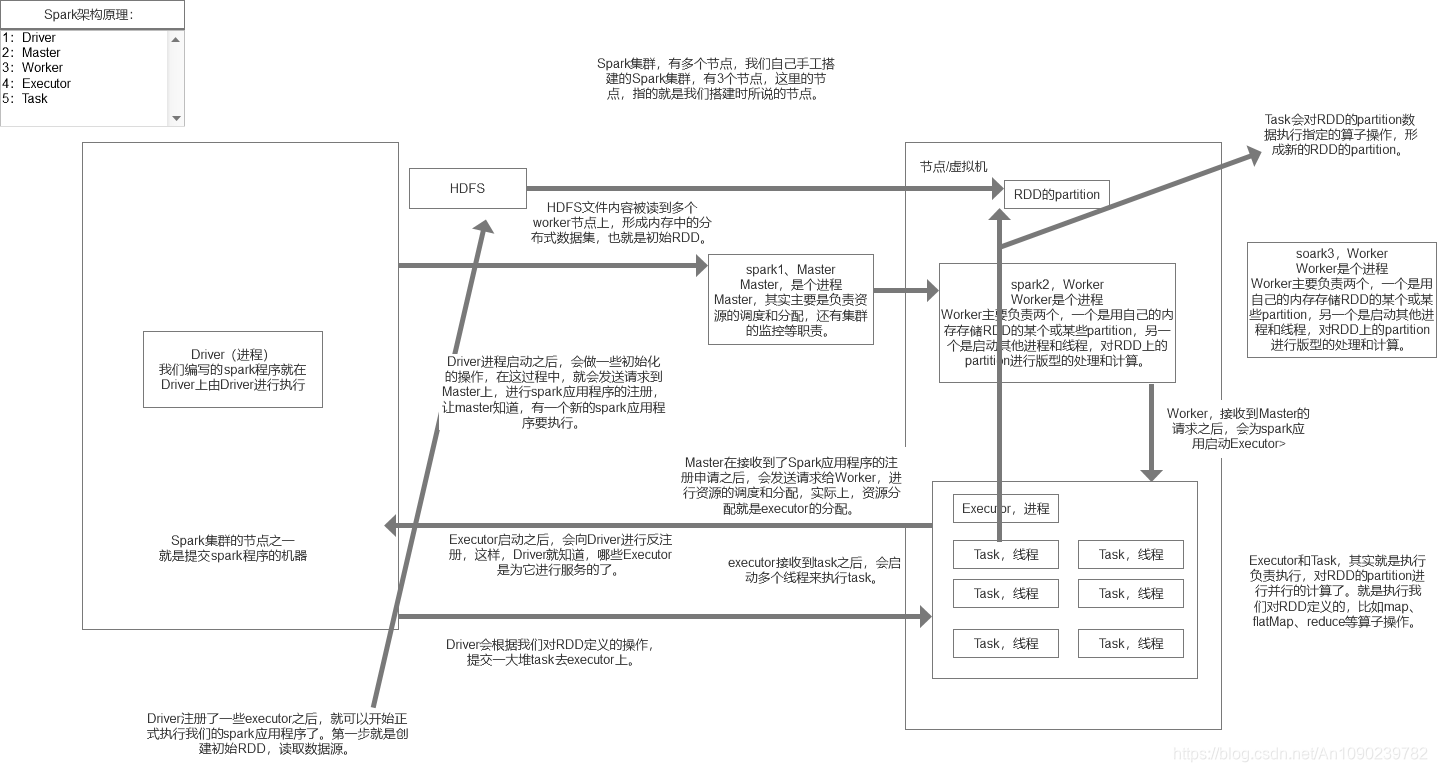
spark内核架构
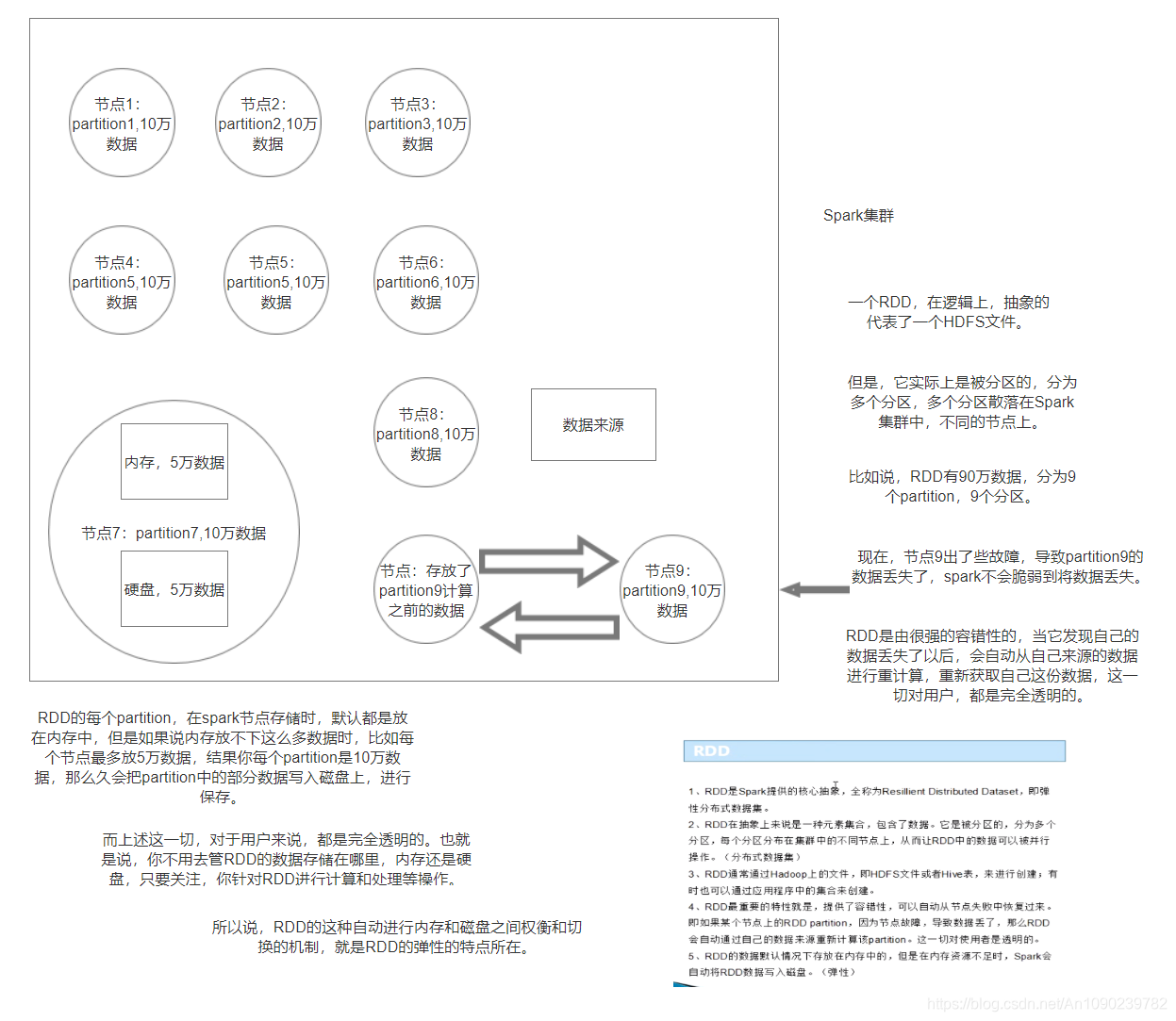
RDD及其特点
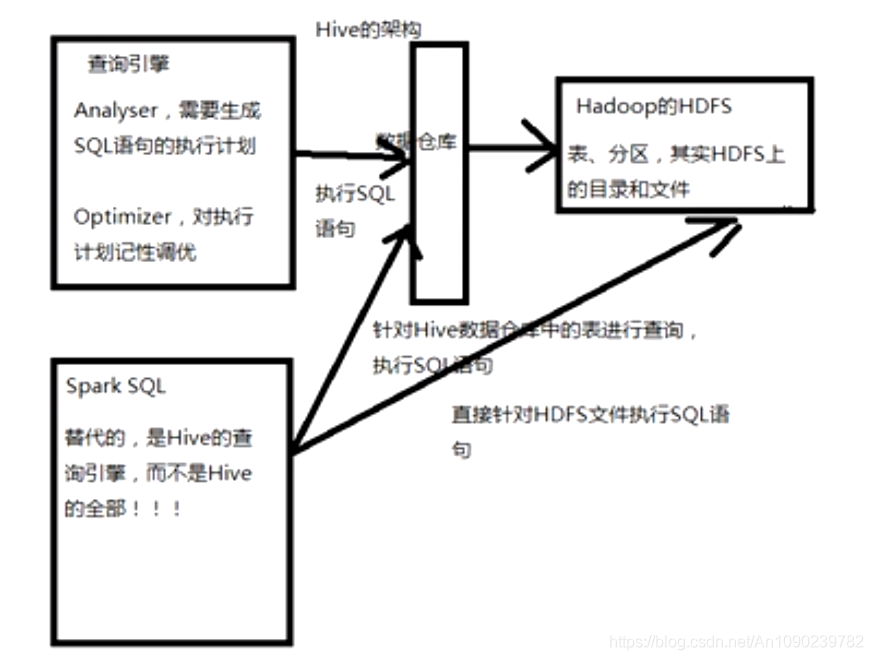
Spark SQL VS Hive
Hive基于HDFS的数据仓库,并提供了SQL模型的,针对存储了大数据的数据仓库,进行分布式交互查询的查询引擎。
Spark SQL是针对Hive数据仓库中的数据进行查询,Spark本身自己不提供存储。
Spark SQL支持大量不同的数据源,包括hive、json、parquet、jdbc等。
Spark Streaming VS Storm
Spark Streaming与Storm都可以进行实时流计算,但是二者区别很大。
Spark Streaming和Storm计算模型完全不一样,Spark Streaming是基于RDD的,因此需要将一小段时间内的,比如1s的数据,收集起来,作为一个RDD,然后再针对这个batch得数据进行处理。
而Storm却可以做到每来一条数据,都可以立即进行处理和计算。
Storm支持在分布式流式计算程序运行过程中,可以动态地调整并行度,从而动态提供并发处理能力,而Spark Streaming是无法动态调整并行度的。
Spark Streaming由于是基于batch进行处理的,因此相较于Storm基于单条数据进行处理,具有数倍甚至数十倍的吞吐量。

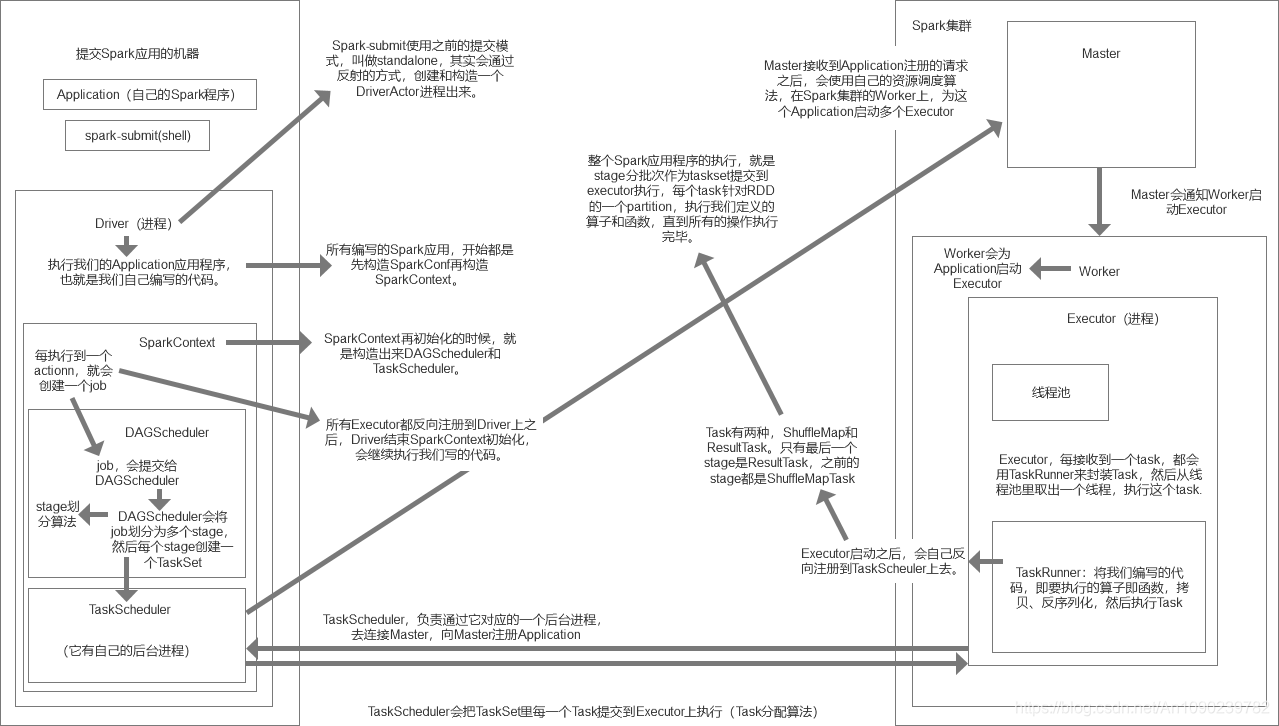
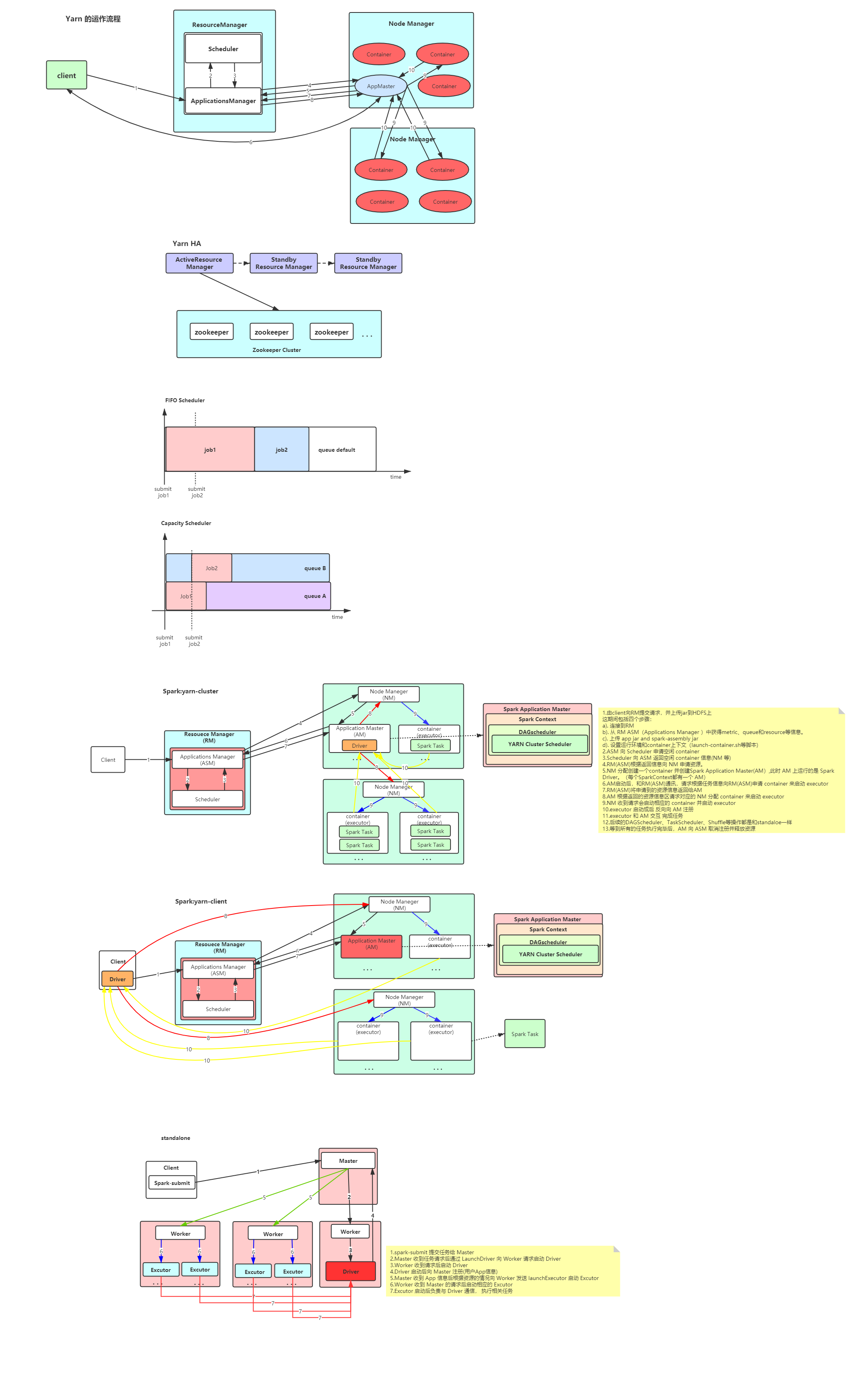
spark 任务提交流程
大数据体系概览Spark、Spark核心原理、架构原理、Spark特点的更多相关文章
- 一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了 转载: 大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你可以把它 ...
- [大数据从入门到放弃系列教程]第一个spark分析程序
[大数据从入门到放弃系列教程]第一个spark分析程序 原文链接:http://www.cnblogs.com/blog5277/p/8580007.html 原文作者:博客园--曲高终和寡 **** ...
- 大数据技术之_19_Spark学习_04_Spark Streaming 应用解析 + Spark Streaming 概述、运行、解析 + DStream 的输入、转换、输出 + 优化
第1章 Spark Streaming 概述1.1 什么是 Spark Streaming1.2 为什么要学习 Spark Streaming1.3 Spark 与 Storm 的对比第2章 运行 S ...
- 大数据技术之_19_Spark学习_05_Spark GraphX 应用解析 + Spark GraphX 概述、解析 + 计算模式 + Pregel API + 图算法参考代码 + PageRank 实例
第1章 Spark GraphX 概述1.1 什么是 Spark GraphX1.2 弹性分布式属性图1.3 运行图计算程序第2章 Spark GraphX 解析2.1 存储模式2.1.1 图存储模式 ...
- 【科普杂谈】一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你可以把它比作一个厨房所以需要的各种工具.锅碗瓢盆,各有各的用处,互相之间又有重合.你可 ...
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
- 【原创】大数据基础之Hive(5)hive on spark
hive 2.3.4 on spark 2.4.0 Hive on Spark provides Hive with the ability to utilize Apache Spark as it ...
- 大数据平台R语言web UI应用架构 设计与开发
1. 系统拓扑图 在日常业务分析中,R是非常常用的分析工具,而当数据量较大时,用R语言需要需用更多的时间来完成训练模型,spark作为大规模数据处理框架,采用内存计算,可以短时间内完成大量的数据的处理 ...
- 大数据学习(05)——MapReduce/Yarn架构
Hadoop1.x中的MapReduce MapReduce作为Hadoop最核心的两个组件之一,在1.0版本中就已经存在了.它包含这么几个角色: Client 多数情况下Client的作用就是向服务 ...
随机推荐
- 使用jmeter进行压力测试与nginx连接数优化
案例训练目标 学会使用jmeter工具 学会配置nginx连接数优化 包含技能点 使用jmeter做压力测试 配置nginx的并发连接数 环境要求 PC支持VT,4G内存以上:vmware虚拟机安装有 ...
- 技术选型关于redis客户端选择
redis作为分布式缓存框架的首选 相信已经毋庸置疑.能高效.合理的使用好它 必定能提升系统的可用性,高性能.高吞吐量的保障.但选择一个客户端,充分发挥它的能力,就是一个选型问题.现在市场上能选择 ...
- reactor模式:主从式reactor
前面两篇文章提到 reactor模式:单线程的reactor模式 reactor模式:多线程的reactor模式 NIO的server模式只有5个阶段,但是,NIO的selectionkey里确实有个 ...
- reactor模式:单线程的reactor模式
reactor模式称之为响应器模式,常用于nio的网络通信框架,其服务架构图如下 不同于传统IO的串行调度方式,NIO把整个服务请求分为五个阶段 read:接收到请求,读取数据 decode:解码数据 ...
- java类的主动使用/被动使用
对类的使用方式分为:主动使用.被动使用 所有的java虚拟机实现必须在每个类或接口被java程序"首次主动使用"时才初始化他们 ps:被动使用不会初始化类,但是有可能会加载类(JV ...
- 一次mongo查询不存在字段引发的事故
话说今天的一个小小的查询失误给了我比较深刻的教训,也让我对mongo有了更深刻的理解,下面我们来说说这个事情的原委: 我们经常使用阿里云子账号在DMS上查询线上数据库数据,今天也是平常的一次操作 集合 ...
- k8s之HTTP请求负载分发
一.导读 对于基于HTTP的服务来说,不同的URL地址经常对应不同的后端服务或者虚拟服务器,通常的做法是在应用前添加一个反向代理服务器Nginx,进行请求的负载转发,在Spring Cloud这个微服 ...
- HBase 底层原理详解(深度好文,建议收藏)
HBase简介 HBase 是一个分布式的.面向列的开源数据库.建立在 HDFS 之上.Hbase的名字的来源是 Hadoop database,即 Hadoop 数据库.HBase 的计算和存储能力 ...
- PMP知识领域
· 十大知识领域 整合-项目整合管理 识别.定义.组合.统一和协调个项目管理过程组的各种过程和活动而展开的活动与过程. 整合:统一.合并.沟通和简历联系:贯穿项目始终 七个过程组 一.制定项目章程(启 ...
- SonarQube学习(六)- SonarQube之扫描报告解析
登录http://192.16.1.105:9000,加载项目扫描情况 点击项目名称,查看报告总览 开发人员主要关注为[问题]标签页. 类型 主要关注为bug和漏洞. 其中bug是必须要修复的,漏洞是 ...