多测师讲解python _re模块_高级讲师肖sir
import re
# 一、常用方法:
# match():从头匹配
# search():从整个文本搜索
# findall():找到所有符合的
# split():分割
# sub():替换
# group():结果转化为内容
# groupdict():结果转化为字典
二、常用的正则表达式符号
# '^'匹配字符开头
#
# '$'匹配字符结尾
#
# '*'匹配*号前的字符0次或多次
#
# '+'匹配前一个字符1次或多次
#
# '?'匹配前一个字符1次或0次
#
# '{m}'匹配前一个字符m次
#
# '{n,m}匹配前一个字符n到m次
#
# '|'匹配符号两边的任意一个,相当于或
#
# '(...)'分组匹配
#
# '\A'只从字符开头匹配,比如re.search("\Aabc","gggggabc") 是匹配不到的
#
# '\Z'匹配字符结尾,和$一样
#
# '\d'匹配数字0-9
#
# '\D'匹配非数字
#
# '\w'匹配[A-Za-z0-9]
#
# '\W'匹配非[A-Za-z0-9]
#
# '\s'匹配空白字符、\t、\n、\r
三、
match

# (1).:默认匹配除\n之外的任意一个字符。'''
# s='abc123wfj456'
# c = re.match('....', s) #match():从头匹配
# print(c.group()) # 结果:abc1 group():结果转化为内容
# #(.)代表一个字符
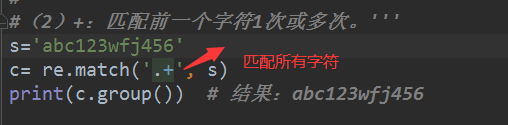
#(2)+:匹配前一个字符1次或多次。'''
s='abc123wfj456'
c= re.match('.+', s)
print(c.group()) # 结果:abc123wfj456

#(3)^:从开头匹配字符。'''
s='abc123wfj456'
c = re.match('^abc\d+', s) #\d表示字符
print(c.group()) # 结果:abc123
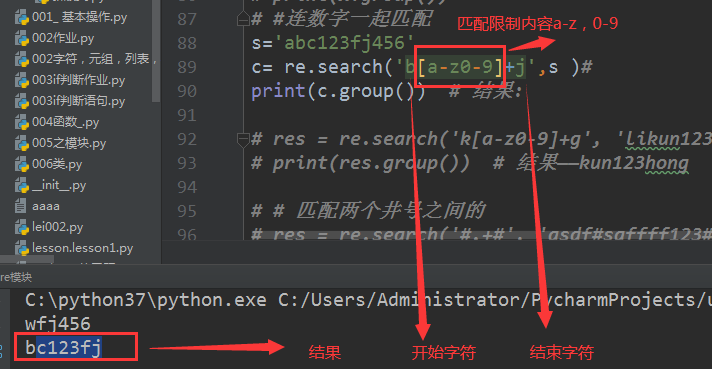
search方法
# (4)字母数字一起匹配
# s='abc123fj456'
# c= re.search('b[a-z0-9]+j',s )#
# print(c.group()) # 结果:bc123fj
x = re.search('a[a-z0-9]+v', 'aaaaa1111444avbdfff')
print(x.group()) # 结果

search方法
(5)?:匹配?的前一个字符出现或者不出现'''
s='abc123fj456'
c= re.search('ab?',s )#?前一个字符可取可不取,a必须取
print(c.group()) # 结果:ab
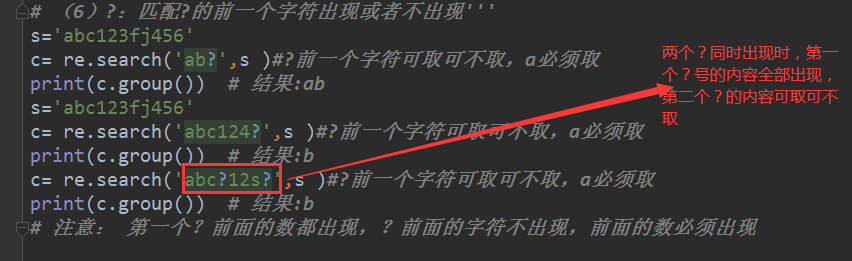
search方法
(6)
c= re.search('abc?12s?',s )#?前一个字符可取可不取,a必须取
print(c.group()) # 结果:b
# 注意: 第一个?前面的数都出现,?前面的字符不出现,前面的数必须出现
# s='abc123fj456'
# c= re.search('ab?',s )#?前一个字符可取可不取,a必须取
# print(c.group()) # 结果:ab
# s='abc123fj456'
# c= re.search('abc124?',s )#?前一个字符可取可不取,a必须取
# print(c.group()) # 结果:abc12
# c= re.search('abc?12s?',s )#?前一个字符可取可不取,a必须取
# print(c.group()) # 结果:abc12
# # 注意: 第一个?前面的数都出现,?前面的字符不出现,前面的数必须出现

search方法
# (7)|:或'''
s='abc123fj456'
c= re.search('abc|123',s )#匹配符号两边任意一个,如果都存在就从左开始取
print(c.group()) # 结果:ab
s='abc123fj456'
c= re.search('abd|123',s )#匹配符号两边任意一个,如果都存左边不存在,就取右边
print(c.group()) # 结果:123

search方法
(8)s='yihang18boss01'
c= re.search("(?P<name>[a-zA-Z]+)(?P<age>[0-9]+)(?P<job>\w+)", s).groupdict()
print(c)
# 结果为:{'name': 'yihang', 'age': '18', 'job': 'boss01'}
#备注:groupdict():结果转化为字典 ;? 匹配前一个字符1次或0次;[]:限制''',\w+匹配[A-Za-z0-9]

search方法
(9)
s = '362421199806106218'
c = re.search('(?P<province>\d{3})(?P<shi>\d{3})(?P<birth>\d{8})(?P<num>\d{2})(?P<last>\d{2})', s).groupdict()
print(c)
# 结果为:{'province': '362', 'shi': '421', 'birth': '19980610', 'num': '62', 'last': '18'}

split方法
(10)
# #split()分割'''
# res = re.split('[a-z]+', 'ab23bas23basd9989ad')
# print(res) # 结果为['', '23', '23', '9989', '']
# res = re.split('[1-9]+', 'ab23bas3basd9989ad')
# print(res) # 结果为['ab', 'bas', 'basd', 'ad']
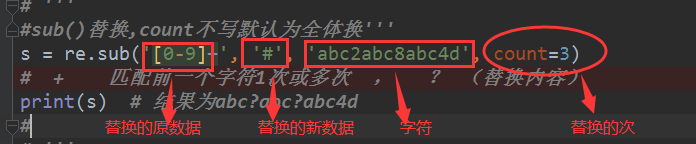
sub方法
(11)
#sub()替换,count不写默认为全体换'''
s = re.sub('[0-9]+', '#', 'abc2abc8abc4d', count=3)
# + 匹配前一个字符1次或多次 , ? (替换内容)
print(s) # 结果:abc#abc#abc#d

match方法
(12)
aa=re.match('\d+',a) #
print (aa.group()) #通过group函数获取对象中的结果
b='a2233113abf123'
bb=re.match('\d+',b) #
print (bb.group()) #通过group函数获取对象中的结果

match方法
(13)
#大写的D:匹配非数字
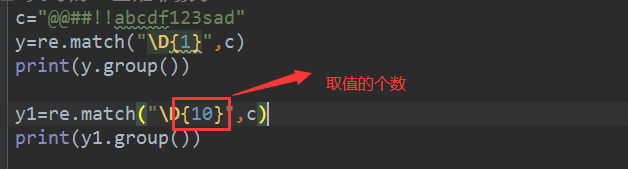
c="@@##!!abc123sad"
y=re.match("\D{1}",c)
print(y.group())
match方法
(14)
y1=re.match("\D{10}",c)
print(y1.group())

find all 方法
(15)
# import re
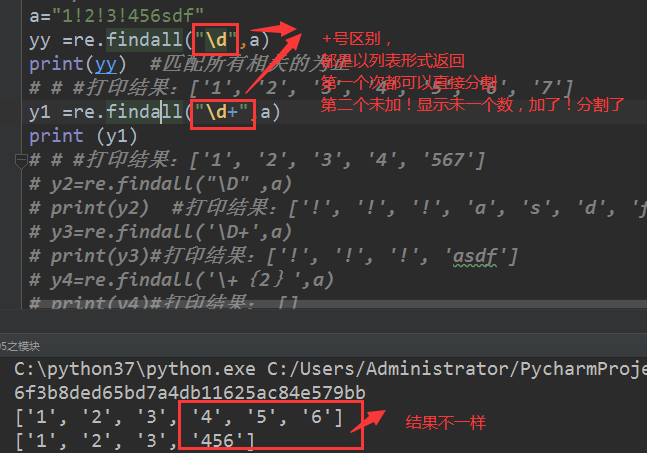
a="1!2!3!4asdf567"
yy =re.findall("\d",a)
print(yy) #匹配所有相关的为止
# # #打印结果:['1', '2', '3', '4', '5', '6', '7']
find all 方法
(16)
# import re
a="1!2!3!456sdf"
yy =re.findall("\d",a)
print(yy) #匹配所有相关的为止
# # #打印结果:['1', '2', '3', '4', '5', '6', '7']
y1 =re.findall("\d+",a)
print (y1)
拓展:
compile 方法O(只是用来编译
)
compile 方法
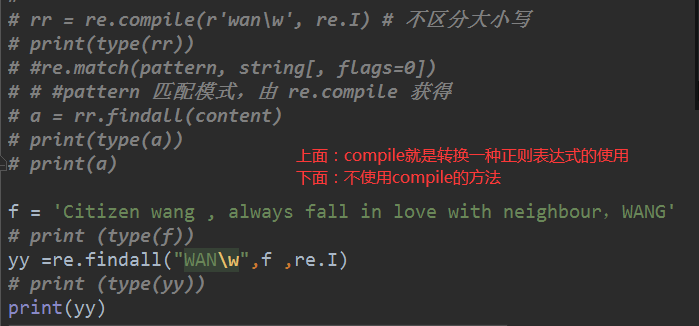
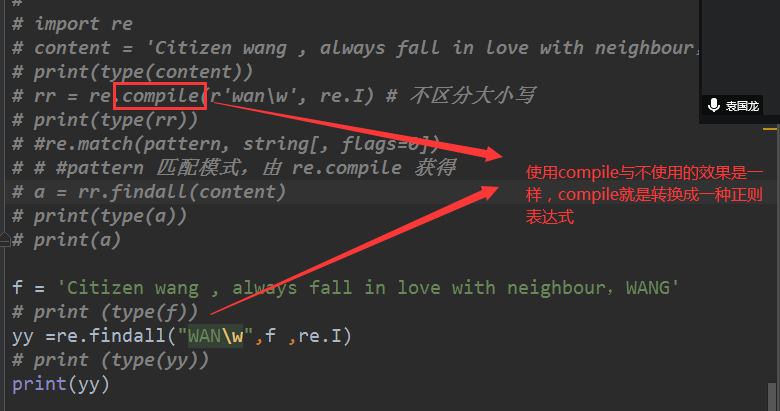
# import re
# content = 'Citizen wang , always fall in love with neighbour,WANG'
# print(type(content))
# rr = re.compile(r'wan\w', re.I) # 不区分大小写
# print(type(rr))
# #re.match(pattern, string[, flags=0])
# # #pattern 匹配模式,由 re.compile 获得
# a = rr.findall(content)
# print(type(a))
# print(a)
f = 'Citizen wang , always fall in love with neighbour,WANG'
# print (type(f))
yy =re.findall("WAN\w",f ,re.I)
# print (type(yy))
print(yy)
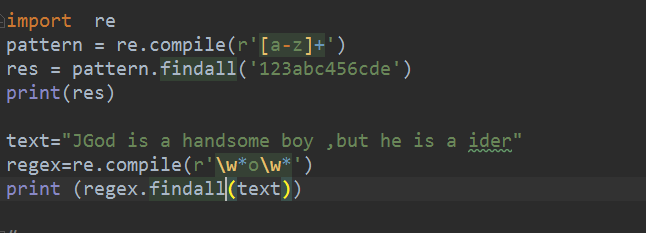
import re
pattern = re.compile(r'[a-z]+')
res = pattern.findall('123abc456cde')
print(res)
text="JGod is a handsome boy ,but he is a ider"
regex=re.compile(r'\w*o\w*')
print (regex.findall(text))
备注拓展:
# re.I(re.IGNORECASE)
# 使匹配对大小写不敏感
# re.L(re.LOCAL)
# 做本地化识别(locale-aware)匹配
# re.M(re.MULTILINE)
# 多行匹配,影响 ^ 和 $
# re.S(re.DOTALL)
# 使 . 匹配包括换行在内的所有字符
# re.U(re.UNICODE)
# 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B.
# re.X(re.VERBOSE)


多测师讲解python _re模块_高级讲师肖sir的更多相关文章
- 多测师讲解requests __介绍_高级讲师肖sir
我们今天讲解的内容 一.什么是Requests? Requests是用Python语言编写的简单易用的HTTP库,用来做接口测试的库. 二.安装requests库 1.按住Windows标志+r,在运 ...
- 多测师讲解requests __中_高级讲师肖sir
(1)生成报告 import unittest #导入单元测试框架 import requests #导入接口库 import time # #时间戳,导入time模块 from api.HTMLTe ...
- 多测师讲解requests __上_高级讲师肖sir
1.三种接口接口请求方式 # # 在python当中接口的请求方式有哪些:# import requests # 导入requests接口库# # # # 请求方式有三种:# # # # 第一种:# ...
- 多测师讲解selenium _assert断言_高级讲师肖sir
assert断言 # # 断言:最常用的断言方法if判断# assert Python语法中自带的断言from selenium import webdriverfrom time import sl ...
- 多测师讲解 _requests安装问题解决_高级讲师肖sir
步骤一:"dos下新建一个pip文件,在文件下建一个pip.ini 文件,步骤二:文件中内容[global]index-url=http://mirrors.aliyun.com/pypi/ ...
- 多测师讲解自动化 _rf 变量_高级讲师肖sir
rf变量 log 打印全局变量 列表变量: 字典变量: 查看当前工程下的变量 紫色表示变量名有误 设置全局变量 设置列表变量 设置字段变量 关键字书写格式问题
- 多测师讲解自动化测试 _RF连接数据库_高级讲师肖sir
RF连接数据库:1.Connect To Database(连接数据库)2.Table Must Exist(表必须存在)3.Check If Exists In Database(查询某条件是否存在 ...
- 多测师讲解seleniun_ ACTIONCHAUNS定位_高级讲师肖sir
1.传统方法定位 2.模拟鼠标定位
- 多测师讲解selenium_iframe框定位_高级讲师肖sir
iframe 框定位方法: 查看iframe框 京东点击登录定位元素 定位qq: qq登录定位的元素 查找iframe框 定位iframe框 from selenium import webdrive ...
随机推荐
- 杭电oj2093题,Java版
杭电2093题,Java版 虽然不难但很麻烦. import java.util.ArrayList; import java.util.Collections; import java.util.L ...
- Mockito在JUnit测试中的使用
Mockito是一种用于替代在测试中难以实现的成员,从而让testcase能顺利覆盖到目标代码的手段.下面例子将展示Mockito的使用. 完整代码下载:https://files.cnblogs.c ...
- 深入理解Go系列一之指针变量
指针变量 基本概念 &a,代表 a 变量的内存地址 p,代表一个句柄引用(句柄由实例数据指针与实例类型指针两部分组成) ,句柄的好处是,当实例数据值改变时,不需要改动实例数据指针与实例类型指针 ...
- Webpack 打包优化之速度篇
在前文 Webpack 打包优化之体积篇中,对如何减小 Webpack 打包体积,做了些探讨:当然,那些法子对于打包速度的提升,也是大有裨益.然而,打包速度之于开发体验和及时构建,相当重要:所以有必要 ...
- pytest测试框架 -- 简介
一.pytest测试框架简介: (1)pytest是python的第三方测试框架,是基于unittest的扩展框架,比unittest更简洁,更高效. (2)pytest框架可以兼容unittest用 ...
- Windows docker镜像文件无法删除
最近刚开始玩docker,下载镜像之前没有修改docker的保存路径,因此默认存在了c:\programdata下面,导致C盘空间不足. 之后修改了保存路径之后( docker engin里加&quo ...
- sql注入--bool盲注,时间盲注
盲注定义: 有时目标存在注入,但在页面上没有任何回显,此时,我们需要利用一些方法进行判断或者尝试得到数据,这个过程称之为盲注. 布尔盲注: 布尔盲注只有true跟false,也就是说它根据你的注入信息 ...
- [Java并发]实现两个线程交替打印奇偶数(volatile+yield实现)
解题思路 实现一个类OddEven 有一个打印奇数的方法,有一个打印偶数的方法. 类中有一个volatile变量 ,用来控制当前状态是该哪个方法打印. 方法中打印每个数前首先判断volatile变量的 ...
- 360 Atlas生产环境使用心得
一.Atlas介绍 Atlas是360开源的一个Mysql Proxy,以下是官方介绍: Atlas是由 Qihoo 360公司Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目 ...
- springboot之零碎小知识
1.springboot启动类加载yml配置项 主要是如下方法,读取了yml的配置项,赋值为类成员属性 @Autowired public void setEnvironment(Environmen ...