Failed to create Spark client for Spark session
最近在hive里将mr换成spark引擎后,执行插入和一些复杂的hql会触发下面的异常:
org.apache.hive.service.cli.HiveSQLException: Error while compiling statement: FAILED: SemanticException Failed to get a spark session: org.apache.hadoop.hive.ql.metadata.HiveException: Failed to create Spark client for Spark session c5924990-6187-4a15-a760-ec3b1afbc199
未能创建spark客户端的原因有这几个:
1,spark没有打卡
2,spark和hive版本不匹配
3,hive连接spark客户端时长过短
解决方案:
1,在进入hive之前,需要依次启动hadoop,spark,hiveservice,这样才能确保hive在启动spark引擎时能成功
spark启动:
cd /opt/spark
./sbin/start-all.sh
2,版本问题是最常见也是出现最多的问题,我用的版本依次为hadoop3.3.0,hive3.1.2,spark2.4.7,之前测试过spark3.0.1,发现和hive不兼容
这里还需要注意Apache官网的提供了如图所示的几个spark包版本:

但在集成hive时spark本身不能自带hive配置,所以只有第三个是可以用的,但是我测试了一下在我的电脑上还是报错,所以我选择了自己编译,下载最后一个源码包,解压后进入spark目录
输入命令:
./dev/make-distribution.sh --name without-hive --tgz -Pyarn -Phadoop-3.3 -Dhadoop.version=3.3.0 -Pparquet-provided -Porc-provided -Phadoop-provided
但是发现编译卡住了,原来编译会自动下载maven,scala,zinc,存放在build目录下,如图:
由于下载过于缓慢,这里直接将这三个包放在build目录下,解压好,编译时会自动识别,可以省去很多时间,快速进入编译,需要压缩包的可以关注公众号:Tspeaker97 给我发消息找我要
编译过程比较慢,我花了30分钟才将spark编译好,中间还网络断流卡住失败了一次,如果不能访问外网的,建议将maven镜像改为阿里云。
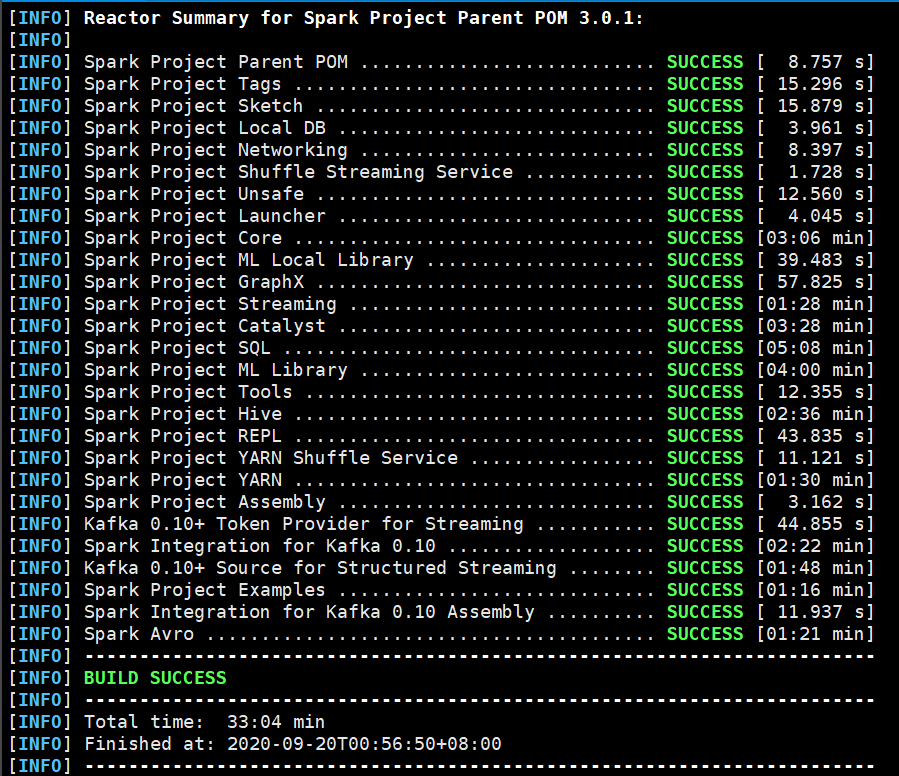
编译完成后在spark目录下就可以看到编译出的tgz包,解压到对应目录:
vim spark-env.sh
插入如下代码:
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
接下来就是hive的设置,这里我用的是公司编译好的版本,大小比Apache官网大一点,想要可以微信扣我
进入hive/conf目录:
vim spark-defaults.conf
插入如下代码:
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop01:9820/spark-history
spark.executor.memory 2g
在hdfs创建对应目录并拷贝jar包:
hadoop fs -mkdir /spark-history
hadoop fs -mkdir /spark-jars
hadoop fs -put /opt/spark/jars/* /spark-jars
在hive/conf/hive-site.xml中增加:(这里特地延长了hive和spark连接的时间,可以有效避免超时报错)
<!--Spark依赖位置-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop01:9820/spark-jars/*</value>
</property> <!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property> <!--Hive和spark连接超时时间-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>100000ms</value>
</property>
然后启动spark服务,hive服务,并进入hive客户端,执行hql:
set hive.exec.mode.local.auto=true; create table visit(user_id string,shop string) row format delimited fields terminated by '\t'; load data local inpath '/opt/hive/datas/user_id' into table visit; SELECT t1.shop,
t1.user_id,
t1.count,
t1.rank
FROM
(SELECT shop,
user_id,
count(user_id) COUNT,
rank() over(partition BY shop ORDER BY count(user_id) DESC) rank
FROM visit
GROUP BY user_id,
shop
ORDER BY shop ASC, COUNT DESC ) t1
WHERE rank <4;
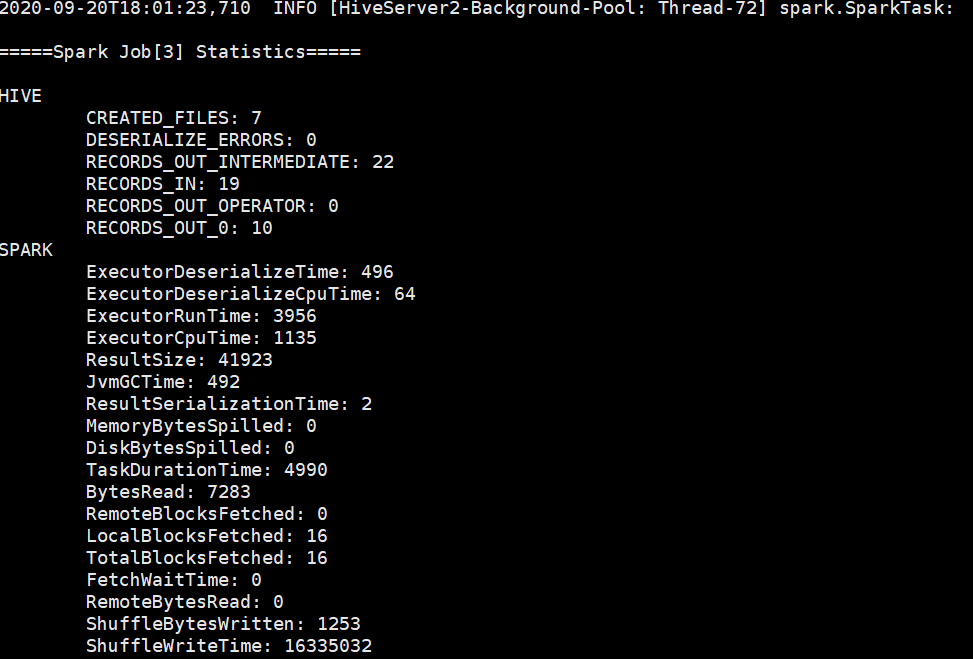
spark引擎成功启动:
如果有其他问题,欢迎叨扰:
Failed to create Spark client for Spark session的更多相关文章
- hive on spark:return code 30041 Failed to create Spark client for Spark session原因分析及解决方案探寻
最近在Hive中使用Spark引擎进行执行时(set hive.execution.engine=spark),经常遇到return code 30041的报错,为了深入探究其原因,阅读了官方issu ...
- AX2012 R3 Data upgrade checklist sync database step, failed to create a session;
最近在做AX2012 R3 CU9 到CU11的upgrade时 (用的Admin帐号), 在Date upgrade 的 synchronize database 这步 跑了一半,报出错误 说“fa ...
- Tensorflow 报错:tensorflow.python.framework.errors_impl.InternalError: Failed to create session.
问题描述 IDE:pycharm,环境中安装tensorflow-gpu 1.8.0 ,Cuda9 ,cudnn 7,等,运行代码 报错如下 tensorflow.python.framework.e ...
- Spark On Yarn报警告信息 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
1 贴出完整日志信息 // :: INFO client.RMProxy: Connecting to ResourceManager at hdp1/ // :: INFO yarn.Client: ...
- Spark Client启动原理探索
经过几天闲暇时间的学习,终于又理解的深入了一些,关于Spark Client如何提交作业也更清晰了点. 在整体的流程图上是这样的: 大体的思路就是应用程序通过SparkSubmit提交程序后,自动在当 ...
- 用NFS挂载root出现:NFS: failed to create MNT RPC client, status=-101(-110)
2014-02-18 08:06:17 By Ly #Linux 阅读(78) 评论(0) 错误信息如下: Root-NFS: nfsroot=/home/zenki/nfs/rootfs NFS ...
- spark client + yarn计算
前提:完成hadoop + kerberos安全环境搭建. 安装配置spark client: 1. wget https://d3kbcqa49mib13.cloudfront.net/spark- ...
- 【原创】大数据基础之Spark(1)Spark Submit即Spark任务提交过程
Spark2.1.1 一 Spark Submit本地解析 1.1 现象 提交命令: spark-submit --master local[10] --driver-memory 30g --cla ...
- Docker 搭建Spark 依赖sequenceiq/spark:1.6镜像
使用Docker-Hub中Spark排行最高的sequenceiq/spark:1.6.0. 操作: 拉取镜像: [root@localhost home]# docker pull sequence ...
随机推荐
- moviepy音视频开发:音频文件存取类AudioFileClip属性和方法介绍
☞ ░ 前往老猿Python博文目录 ░ 一.概述 AudioFileClip是AudioClip的直接子类,用于从一个音频文件或音频数组中读入音频到内存构建音频剪辑.但AudioFileClip并不 ...
- PyQt(Python+Qt)学习随笔:部件的大小策略sizePolicy的含义
在Qt Designer中的每个部件,除了设置部件的位置(geometry)之外,还可以指定部件的大小策略sizePolicy.部件的sizePolicy用于说明部件在布局管理中的缩放方式,当部件没有 ...
- pytorch实战(一)hw1——李宏毅老师作业1
任务描述:利用前9小时数据,预测第10小时的pm2.5的数值,回归任务 kaggle地址:https://www.kaggle.com/c/ml2020spring-hw1 训练集为: 12个月*20 ...
- 第 2 篇Scrum 冲刺博客
每天举行会议 会议照片: 昨天已完成的工作与今天计划完成的工作及工作中遇到的困难: 成员姓名 昨天完成工作 今天计划完成的工作 工作中遇到的困难 蔡双浩 完成修改个人信息剩余部分 了解任务,并做相关学 ...
- NOI Online #1 入门组 魔法
全网都是矩阵快速幂,我只会倍增DP 其实这题与 AcWing 345. 牛站 还是比较像的,那题可以矩阵快速幂 / 倍增,这题也行. 先 \(Floyd\) 预处理两点之间不用魔法最短距离 \(d_{ ...
- KM 算法
KM 算法 可能需要先去学学匈牙利算法等二分图相关知识. 模板题-洛谷P6577 [模板]二分图最大权完美匹配 给 \(n\) 和 \(m\) 与边 \(u_i,v_i,w_i(1\le i\le m ...
- redis学习之——在分布式数据库中CAP原理CAP+BASE
分布式系统 分布式系统(distributed system) 由多台计算机和通信的软件组件通过计算机网络连接(本地网络或广域网)组成.分布式系统是建立在网络之上的软件系统.正是因为软件的特性,所以分 ...
- Spring AOP的理解(通俗易懂)。
转载 原文链接:http://www.verydemo.com/demo_c143_i20837.html 这种在运行时,动态地将代码切入到类的指定方法.指定位置上的编程思想就是面向切面的编程. 1. ...
- Day11 python高级特性-- 迭代器 Iterator
直接可以作用于for循环的数据类型有以下几种: • 集合数据类型: list.tuple.dict.set.str • Generator: 生成器 和 带 y ...
- learn Docker from scratch (1)
一.前言 Docker容器一个很有趣的东西,下面链接内容适合docker的入门非常棒! 链接如下: http://www.ruanyifeng.com/blog/2018/02/docker-tuto ...