Greenplum 性能优化之路 --(三)ANALYZE
一、为什么需要 ANALYZE
首先介绍下 RBO 和 CBO,这是数据库引擎在执行 SQL 语句时的2种不同的优化策略。
RBO(Rule-Based Optimizer)
基于规则的优化器,就是优化器在优化查询计划的时候,是根据预先设置好的规则进行的,这些规则无法灵活改变。举个例子,索引优先于扫描,这是一个规则,优化器在遇到所有可以利用索引的地方,都不会选择扫描。这在多数情况下是正确的,但也不完全如此:
比如 一张个人信息表中性别栏目加上索引,由于性别是只有2个值的枚举类,也就是常说的基数非常低的列,在这种列上使用索引往往效果还不如扫描
SELET count(*) FROM person WHERE gender = 'M';
因此 RBO 的优化方式是死板的,粗放的,目前已逐渐被 CBO 方式取代。
CBO(Cost Based Optimizer)
基于代价的优化器,就是优化器在优化查询计划的时候,是根据动态计算出来的 Cost(代价)来判断如何进行选择。那如何计算代价呢?这里一般是基于代价模型和统计信息,代价模型是否合理,统计信息是否准确都会影响优化的效果。
还是拿上面员工性别统计为例,在 CBO 的优化方式下,物理计划就不会选择走索引。当然上面的例子比较简单,在 Greenplum 运行的复杂 SQL 中,优化器最核心的还是在 scan 和 join 的各种实现方式中做出选择,这才是能大幅提升性能的关键点。
前面提到 CBO 需要一个代价模型和统计信息,代价模型和规则一样,需要预先设置好,那统计信息是如何收集的?多数基于 CBO 优化的计算引擎,包括 Greenplum,Oracle,Hive,Spark 等都类似,除了可以按一定规则自动收集统计信息外,还都支持手动输入命令进行收集,通常这个命令都叫 ANALYZE。
结论:由于 CBO 优化的需求,因此我们需要使用 ANALYZE 命令去收集统计信息。
二、ANALYZE 怎么使用
说明
ANALYZE 是 Greenplum 提供的收集统计信息的命令。
ANALYZE 支持三种粒度,列,表,库,如下:
CREATE TABLE foo (id int NOT NULL, bar text NOT NULL) DISTRIBUTED BY (id); // 创建测试表fooANALYZE foo(bar); // 只搜集bar列的统计信息ANALYZE foo; // 搜集foo表的统计信息ANALYZE; // 搜集当前库所有表的统计信息,需要有权限才行
限制
ANALYZE 会给目标表加 SHARE UPDATE EXCLUSIVE 锁,也就是与 UPDATE,DELETE,还有 DDL 语句冲突。
速度
ANALYZE 是一种采样统计算法,通常不会扫描表中所有的数据,但是对于大表,也仍会消耗一定的时间和计算资源。
采样统计会有精度的问题,因此 Greenplum 也提供了一个参数 default_statistics_target,调整采样的比例。简单说来,这个值设置得越大,采样的数量就越多,准确性就越高,但是消耗的时间和资源也越多。

default_statistics_target.png
直接修改服务器的参数会影响整个集群,通常不建议这样操作。如果确实有需要,可以尝试只修改某列的对应参数,如下:
ALTER TABLE {table_name} ALTER COLUMN {col_name} SET STATISTICS {-1|0-1000};
时机
根据上文所述,ANALYZE 会加锁并且也会消耗系统资源,因此运行命令需要选择合适的时机尽可能少的运行。根据 Greenplum 官网建议,以下3种情况发生后建议运行 ANALYZE
批量加载数据后,比如 COPY
创建索引之后
INSERT, UPDATE, and DELETE 大量数据之后
自动化
除了手动运行,ANALYZE 也可以自动化。实际上默认情况下,我们对空表写入数据后, Greenplum 也会自动帮我们收集统计信息,不过之后在写入数据,就需要手动操作了。
有2个参数可以用来调整自动化收集的时机,gp_autostats_mode 和 gp_autostats_on_change_threshold。gp_autostats_mode 默认是 on_no_stats,也就是如果表还没有统计信息,这时候写入数据会导致自动收集,这之后,无论表数据变化多大,都只能手动收集了。如果将 gp_autostats_mode 修改为 on_change ,就是在数据变化量达到 gp_autostats_on_change_threshold 参数配置的量之后,系统就会自动收集统计信息。
分区表
Greenplum 官网对于分区表的 ANALYZE 专门进行了讲解,其实只要保持默认值,不去修改系统参数 optimizer_analyze_root_partition,那么对于分区表的操作并没有什么不同,直接在 root 表上进行 ANALYZE 即可,系统会自动把所有叶子节点的分区表的统计信息都收集起来。
如果分区表的数目很多,那在 root 表上进行 ANALYZE 可能会非常耗时,通常的分区表都是带有时间维度的,历史的分区表并不会修改,因此单独 ANALYZE 数据发生变化的分区,是更好的实践。
三、统计信息去了哪里
pg_class
表的大小是统计信息里面最直观,也几乎是最重要的,这个信息是放在 pg_catalog.pg_class 系统表中,reltuples 代表元组数(行数),relpages 代表实际占用的 page 数目(Greenplum中一个 page 为32KB)。
需要注意以下3点
1. reltuples 不是准确值,获取表的准确行数还是需要 count。
2. reltuples 和 relpages 需要通过 ANALYZE 进行收集,对于已有数据的表,系统不会自动更新。
3. reltuples 和 relpages 不一定能对齐,比如条数看起来不多的表,实际占用的 page 数目很大,这种一般是由于数据膨胀(bloat)造成,这时候需要 vacuum 等操作。
pg_statistic
关于列的统计信息都是存放在 pg_catalog.pg_statistic 系统表中。其中表的每一列(如果有统计)都会有一行对应的数据。了解并掌握 pg_statistic 的内容,对于深入理解查询优化非常重要。
列的统计信息内容很丰富,但是目的都是让优化器估算出,一个查询条件,能够过滤多少数据。
以下列举了 pg_statistic 的重要字段:

对于 stakindN 字段中的统计方式,这里选择3个最常见的进行说明:
1. STATISTIC_KIND_MCV
高频值,在一个列中出现最频繁的值。
高频值统计在很多场景下都有价值,这里举一个数据倾斜的 hash join 例子,如下代码:
/* * ExecHashBuildSkewHash * * Set up for skew optimization if we can identify the most common values * (MCVs) of the outer relation's join key. We make a skew hash bucket * for the hash value of each MCV, up to the number of slots allowed * based on available memory. */static voidExecHashBuildSkewHash(HashJoinTable hashtable, Hash *node, int mcvsToUse){....}
hash join 场景下,我们需要尽可能的把 inner table 构建在内存中,但内存资源是有限的,因此我们需要做出一些选择,什么内容优先放入内存中。如果外表有高频值,那我们可以考虑把高频值对应的内表信息优先放入到内存中,在实践中,Greenplum 是单独构建一个 skew hash table 与 main hash table 并存。
2. STATISTIC_KIND_HISTOGRAM
直方图,使用等频直方图来描述一个列中的数据的分布。
直方图主要用于数据分布不均匀的情况下,对按列过滤后能返回多少数据进行预估。
举个例子,一个有3种产品的订单表,商品 A 很热销,订单量在90%,商品 B 一般,订单量在9%,商品 C 只有1%,则该列的 NDV(Number of Distinct Value)值为3,如果一共有1000000条数据,在没有直方图统计的情况下,如果查询商品 C 的订单,优化器会预计要扫描1000000/3≈330000,因此可能选择全表 scan,如果含有直方图统计,优化器就知道实际上 C 商品可能就几千条数据,因此会选择走索引。当然这个例子很简单,实际情况会复杂很多。
3. STATISTIC_KIND_CORRELATION
相关系数,记录的是当前列未排序的数据分布和排序后的数据分布的相关性。
用于估算索引扫描代价的,统计值在-1到1,值越大,表示相关性越高,也就是使用索引扫描代价越低。
举个例子,初始化如下2张表
create table t_correlation_asc (id int, number int) DISTRIBUTED BY (id);INSERT INTO t_correlation_asc SELECT 1, i FROM generate_series(1, 1000) AS i; create table t_correlation_desc (id int, number int) DISTRIBUTED BY (id);INSERT INTO t_correlation_desc SELECT 1, 1001-i FROM generate_series(1, 1000) AS i;
在查看表对应的统计信息,可以看出在 number 列,你按升序写入1000个数,该列物理存储的数据实际上就是按升序排序的,反过来降序写入1000个数,由于顺序是相反的,所以相关性是-1
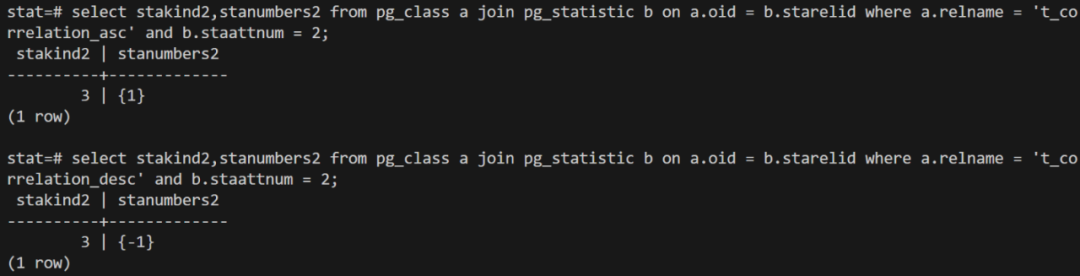
correlation.png
四、例子
以下将会构造一个大小表 join 的场景,来说明统计信息的收集对于查询计划的影响。
1. 初始化表结构和数据:
CREATE TABLE small_table (id int NOT NULL, bar text NOT NULL) DISTRIBUTED BY (id);INSERT INTO small_table SELECT i, 'test:' || i FROM generate_series(1, 10) AS i; CREATE TABLE big_table (id int NOT NULL, bar text NOT NULL) DISTRIBUTED BY (id);INSERT INTO big_table SELECT i, 'test:' || i FROM generate_series(1, 100000) AS i;
pg_class 中对应的数据如下:

small_table.png

big_table.png
2. 大小表 join
注意为了构造小表广播的场景,这里关联键需要选择非分布键。
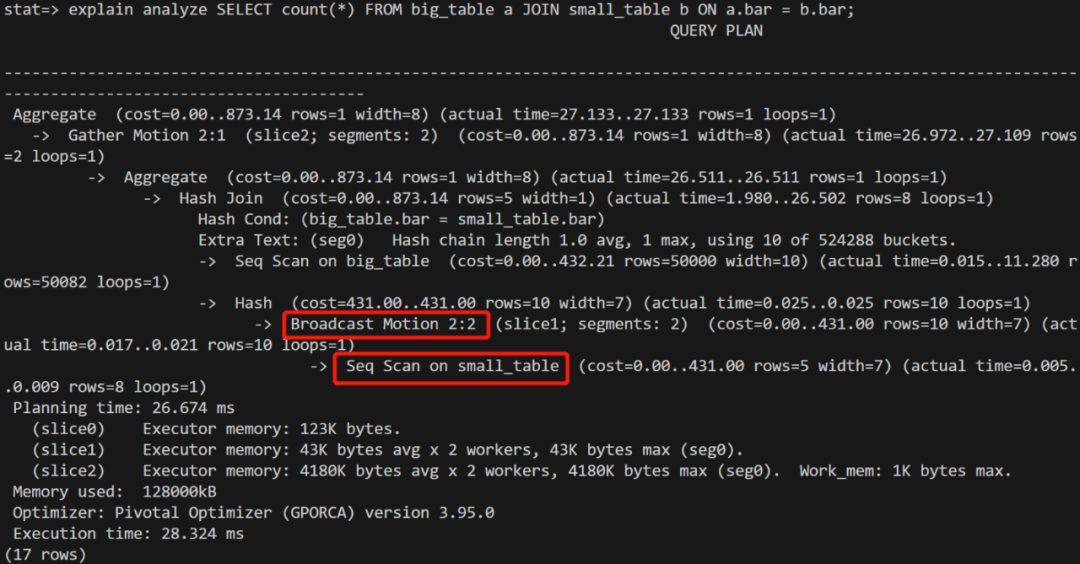
explain1.png
3. 给小表插入数据
这里给小表插入数据后,小表的数据量超过大表
INSERT INTO small_table SELECT i, 'test:' || i FROM generate_series(1, 200000) AS i;
在没有 ANALYZE 的情况下,pg_class 中的数据没有发生变化,因此查询计划也没有发生变化。
4. 收集统计信息
运行 ANALYZE 收集小表的统计信息,如下:

new_small_table.png
在运行 join 语句,查询计划发生变化:
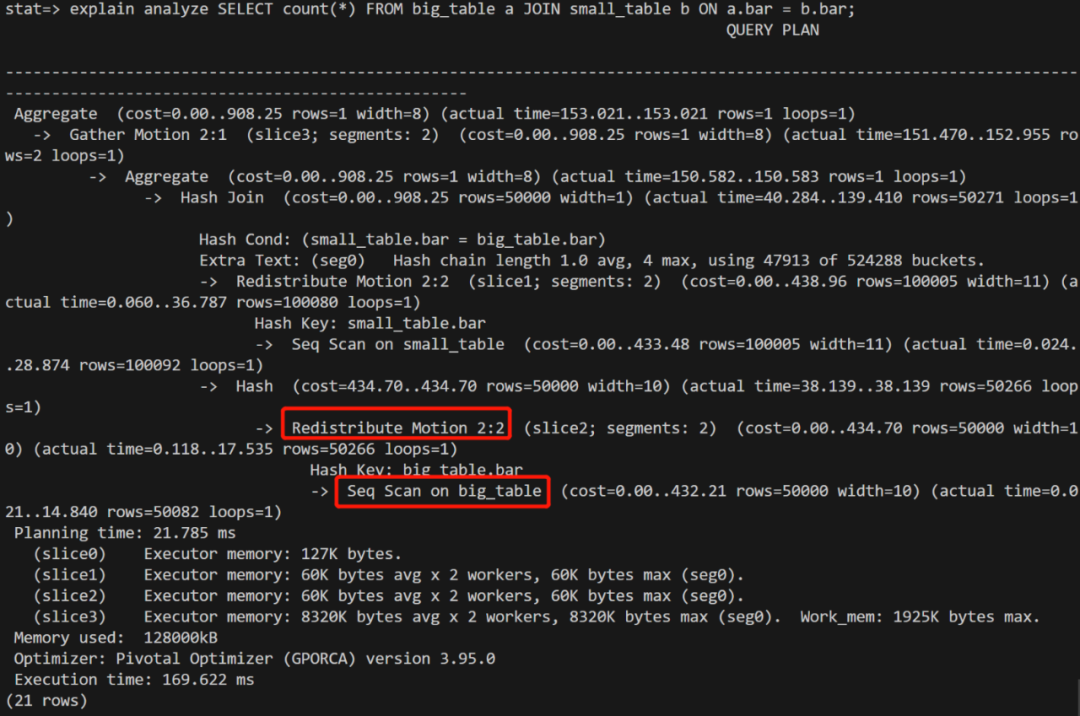
explain2.png
结论:查询优化器在收到新的统计信息之后,发现是2张数据量差不多的表进行 join,因此选择重分布而不是小表广播。

关注“腾讯云大数据”公众号,技术交流、最新活动、服务专享一站Get~
Greenplum 性能优化之路 --(三)ANALYZE的更多相关文章
- Greenplum 性能优化之路 --(二)存储格式
一.存储格式介绍 Greenplum(以下简称 GP)有2种存储格式,Heap 表和 AO 表(AORO 表,AOCO 表). Heap 表:这种存储格式是从 PostgreSQL 继承而来的,目前是 ...
- Greenplum 性能优化之路 --(一)分区表
一.什么是分区表 分区表就是将一个大表在物理上分割成若干小表,并且整个过程对用户是透明的,也就是用户的所有操作仍然是作用在大表上,不需要关心数据实际上落在哪张小表里面.Greenplum 中分区表的原 ...
- 阿里巴巴 web前端性能优化进阶路
Web前端性能优化WPO,相信大多数前端同学都不会陌生,在各自所负责的站点页面中,也都会或多或少的有过一定的技术实践.可以说,这个领域并不缺乏成熟技术理论和技术牛人:例如Yahoo的web站点性能优化 ...
- 专访阿里巴巴研究员“赵海平”:Facebook的PHP底层性能优化之路(HipHop,HHVM)
专访阿里巴巴研究员“赵海平”:Facebook的PHP底层性能优化之路 http://www.infoq.com/cn/articles/interview-alibaba-zhaohaiping
- PLSQL_性能优化系列16_Oracle Tuning Analyze优化分析
2014-12-23 Created By BaoXinjian
- Android性能优化第(三)篇---MAT比Menmery Monitor更强大
作者 LooperJing 2016.11.17 16:42* 字数 1687 阅读 1603评论 3喜欢 21 在Android性能优化第(一)篇---基本概念中讲了JAVA的四大引用,讲了一下GC ...
- 40+倍提升,详解 JuiceFS 元数据备份恢复性能优化之路
JuiceFS 支持多种元数据存储引擎,且各引擎内部的数据管理格式各有不同.为了便于管理,JuiceFS 自 0.15.2 版本提供了 dump 命令允许将所有元数据以统一格式写入到 JSON 文件进 ...
- Android 开发性能优化之SparseArray(三)
SparseArray是android里为<Interger,Object>这样的Hashmap而专门写的class,目的是提高效率,其核心是折半查找函数(binarySearch) pr ...
- 李洪强iOS开发之性能优化技巧
李洪强iOS开发之性能优化技巧 通过静态 Analyze 工具,以及运行时 Profile 工具分析性能瓶颈,并进行性能优化.结合本人在开发中遇到的问题,可以从以下几个方面进行性能优化. 一.view ...
随机推荐
- sqlilab less32-less37
less-32 过滤了单引号,双引号,斜杠,同时设置数据库为GBK编码,可以考虑宽字节注入, 当设置gbk编码后,遇到连续两个字节,都符合gbk取值范围,会自动解析为一个汉字.用脚本来测试下哪些符合 ...
- 企业级工作流解决方案(六)--微服务消息处理模型之与Abp集成
身份认证传递 对于Abp比较熟悉的朋友应该对他里面的用户身份认证比较熟悉,他是通过实现微软提供的权限认证方式实现的,用户登录身份信息存储在System.Security.Claims.ClaimsPr ...
- Guitar Pro小课堂之弹唱和弦转换小技巧
吉他相对其他乐器的便携性,还有其便于弹唱的特点,受到了很多音乐萌新们的喜爱.对于刚刚接触吉他的萌新来说,学琴初期弹唱的时候经常会因为和弦卡顿的转换,和因为食指力度不够或技巧不对无法顺利演奏的大横按,导 ...
- jQuery 第一章 $()选择器
jquery 是什么? jquery 其实就是一堆的js函数(js库),也是普通的js而已. 有点像我们封装一个函数,把他放到单独的js 文件,等待有需要的时候调用它. 那么使用它有啥好处呢? jqu ...
- python-交互模式
1.打开python交互式命令行: Windows+R→回车→输入python 如图 输入python进入交互模式,相当于启动了python解释器,输入一行代码就执行一行代码,可以用交互模式去验证每一 ...
- JUC详解--【Foam番茄】
1.什么是JUC java.util 工具包 业务:普通的线程代码 Thread Runnable 没有返回值,效率相比于 Callable 相对较低! 2.线程和进程 进程:一个程序,QQ.exe ...
- 1.Cobaltstrike 安装与简介
1.Cobaltstrike 安装与简介 一.简介 Cobalt Strike是一款美国Red Team开发的渗透测试神器,常被业界人内称为CS.自去年起, Cobaltstrike升级到3.0版本, ...
- Spring mvc与springboot
org.springframework.boot.autoconfigure.web.servlet.WebMvcAutoConfiguration: viewResolver 类路径文件 把类路径下 ...
- 集群--lvs
快一个月没有更新博客了,最近一段时间在忙世界技能大赛网络系统系管理这个项目,没有太多的时间,我百忙之中更新一下.最近赛题中有说到集群这个,lvs这个东西(我也该学学这个了,一直停留在基础部分,是时候学 ...
- 关于老猿Python系列文章发布网址变化的说明
老猿Python系列文章最开始在新浪发布,后逐渐开通了CSDN.博客园和简书三个网址,但老猿一来工作忙,二来Python需要学习的内容太多,因此实在没时间同时维护这么多博客,事实上除了CSDN其他网站 ...