SpringBoot2.x入门教程:引入jdbc模块与JdbcTemplate简单使用
这是公众号《Throwable文摘》发布的第23篇原创文章,收录于专辑《SpringBoot2.x入门》。
前提
这篇文章是《SpringBoot2.x入门》专辑的第7篇文章,使用的SpringBoot版本为2.3.1.RELEASE,JDK版本为1.8。
这篇文章会简单介绍jdbc模块也就是spring-boot-starter-jdbc组件的引入、数据源的配置以及JdbcTemplate的简单使用。为了让文中的例子相对通用,下文选用MySQL8.x、h2database(内存数据库)作为示例数据库,选用主流的Druid和HikariCP作为示例数据源。
引入jdbc模块
引入spring-boot-starter-jdbc组件,如果在父POM全局管理spring-boot依赖版本的前提下,只需要在项目pom文件的dependencies元素直接引入:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
通过IDEA展开该依赖的关系图如下:
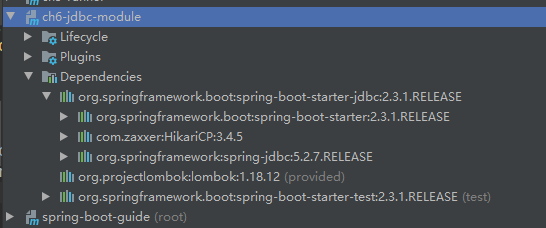
其实spring-boot-starter-jdbc模块本身已经引入了spring-jdbc(间接引入spring-core、spring-beans、spring-tx)、spring-boot-starter和HikariCP三个依赖,如果希望启动Servlet容器,可以额外引入spring-boot-starter-jdbc。
spring-boot-starter-jdbc提供了数据源配置、事务管理、数据访问等等功能,而对于不同类型的数据库,需要提供不同的驱动实现,才能更加简单地通过驱动实现根据连接URL、用户口令等属性直接连接数据库(或者说获取数据库的连接),因此对于不同类型的数据库,需要引入不同的驱动包依赖。对于MySQL而言,需要引入mysql-connector-java,而对于h2database而言,需要引入h2(驱动包和数据库代码位于同一个依赖中),两者中都具备数据库抽象驱动接口java.sql.Driver的实现类:
- 对于
mysql-connector-java而言,常用的实现是com.mysql.cj.jdbc.Driver(MySQL8.x版本)。 - 对于
h2而言,常用的实现是org.h2.Driver。
如果需要连接的数据库是h2database,引入h2对应的数据库和驱动依赖如下:
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>1.4.200</version>
</dependency>
如果需要连接的数据库是MySQL,引入MySQL对应的驱动依赖如下:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.20</version>
</dependency>
上面的类库版本选取了编写本文时候的最新版本,实际上要根据软件对应的版本选择合适的驱动版本。
数据源配置
spring-boot-starter-jdbc模块默认使用HikariCP作为数据库的连接池。
HikariCP,也就是Hikari Connection Pool,Hikari连接池。HikariCP的作者是日本人,而Hikari是日语,意义和light相近,也就是"光"。Simplicity is prerequisite for reliability(简单是可靠的先决条件)是HikariCP的设计理念,他是一款代码精悍的高性能连接池框架,被Spring项目选中作为内建默认连接池,值得信赖。
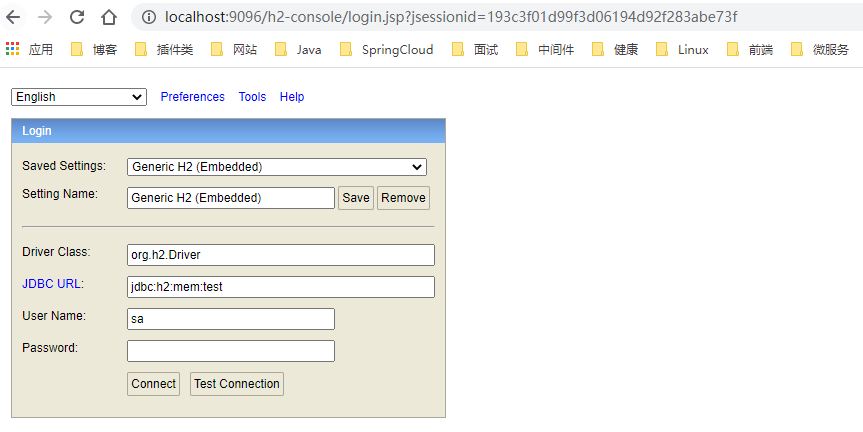
如果决定使用HikariCP连接h2数据库,则配置文件中添加如下的配置项以配置数据源HikariDataSource:
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.url=jdbc:h2:mem:test
spring.datasource.username=root
spring.datasource.password=123456
# 可选配置,是否启用h2数据库的WebUI控制台
spring.h2.console.enabled=true
# 可选配置,访问h2数据库的WebUI控制台的路径
spring.h2.console.path=/h2-console
# 可选配置,是否允许非本机访问h2数据库的WebUI控制台
spring.h2.console.settings.web-allow-others=true
如果决定使用HikariCP连接MySQL数据库,则配置文件中添加如下的配置项以配置数据源HikariDataSource:
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
# 注意MySQL8.x需要指定服务时区属性
spring.datasource.url=jdbc:mysql://localhost:3306/local?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false
spring.datasource.username=root
spring.datasource.password=root
有时候可能更偏好于使用其他连接池,例如Alibaba出品的Durid,这样就要禁用默认的数据源加载,改成Durid提供的数据源。引入Druid数据源需要额外添加依赖:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.23</version>
</dependency>
如果决定使用Druid连接MySQL数据库,则配置文件中添加如下的配置项以配置数据源DruidDataSource:
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
# 注意MySQL8.x需要指定服务时区属性
spring.datasource.url=jdbc:mysql://localhost:3306/local?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false
spring.datasource.username=root
spring.datasource.password=root
# 指定数据源类型为Druid提供的数据源
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
上面这样配置DruidDataSource,所有数据源的属性值都会选用默认值,如果想深度定制数据源的属性,则需要覆盖由DataSourceConfiguration.Generic创建的数据源,先预设所有需要的配置,为了和内建的spring.datasource属性前缀避嫌,这里自定义一个属性前缀druid,配置文件中添加自定义配置项如下:
druid.url=jdbc:mysql://localhost:3306/local?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false
druid.driver-class-name=com.mysql.cj.jdbc.Driver
druid.username=root
druid.password=root
# 初始化大小
druid.initialSize=1
# 最大
druid.maxActive=20
# 空闲
druid.minIdle=5
# 配置获取连接等待超时的时间
druid.maxWait=60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
druid.timeBetweenEvictionRunsMillis=60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
druid.minEvictableIdleTimeMillis=60000
druid.validationQuery=SELECT 1 FROM DUAL
druid.testWhileIdle=true
druid.testOnBorrow=false
druid.testOnReturn=false
# 打开PSCache,并且指定每个连接上PSCache的大小
druid.poolPreparedStatements=true
druid.maxPoolPreparedStatementPerConnectionSize=20
# 配置监控统计拦截的filters,后台统计相关
druid.filters=stat,wall
# 打开mergeSql功能;慢SQL记录
druid.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
这里要确保本地安装了一个8.x版本的MySQL服务,并且建立了一个命名为local的数据库。
需要在项目中添加一个数据源自动配置类,这里命名为DruidAutoConfiguration,通过注解@ConfigurationProperties把druid前缀的属性注入到数据源实例中:
@Configuration
public class DruidAutoConfiguration {
@Bean
@ConfigurationProperties(prefix = "druid")
public DataSource dataSource() {
return new DruidDataSource();
}
@Bean
public ServletRegistrationBean<StatViewServlet> statViewServlet() {
ServletRegistrationBean<StatViewServlet> servletRegistrationBean
= new ServletRegistrationBean<>(new StatViewServlet(), "/druid/*");
// 添加IP白名单
servletRegistrationBean.addInitParameter("allow", "127.0.0.1");
// 添加控制台管理用户
servletRegistrationBean.addInitParameter("loginUsername", "admin");
servletRegistrationBean.addInitParameter("loginPassword", "123456");
// 是否能够重置数据
servletRegistrationBean.addInitParameter("resetEnable", "true");
return servletRegistrationBean;
}
@Bean
public FilterRegistrationBean<WebStatFilter> webStatFilter() {
WebStatFilter webStatFilter = new WebStatFilter();
FilterRegistrationBean<WebStatFilter> filterRegistrationBean = new FilterRegistrationBean<>();
filterRegistrationBean.setFilter(webStatFilter);
// 添加过滤规则
filterRegistrationBean.addUrlPatterns("/*");
// 忽略过滤格式
filterRegistrationBean.addInitParameter("exclusions", "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*,");
return filterRegistrationBean;
}
}
可以通过访问${requestContext}/druid/login.html跳转到Druid的监控控制台,登录账号密码就是在statViewServlet中配置的用户和密码:
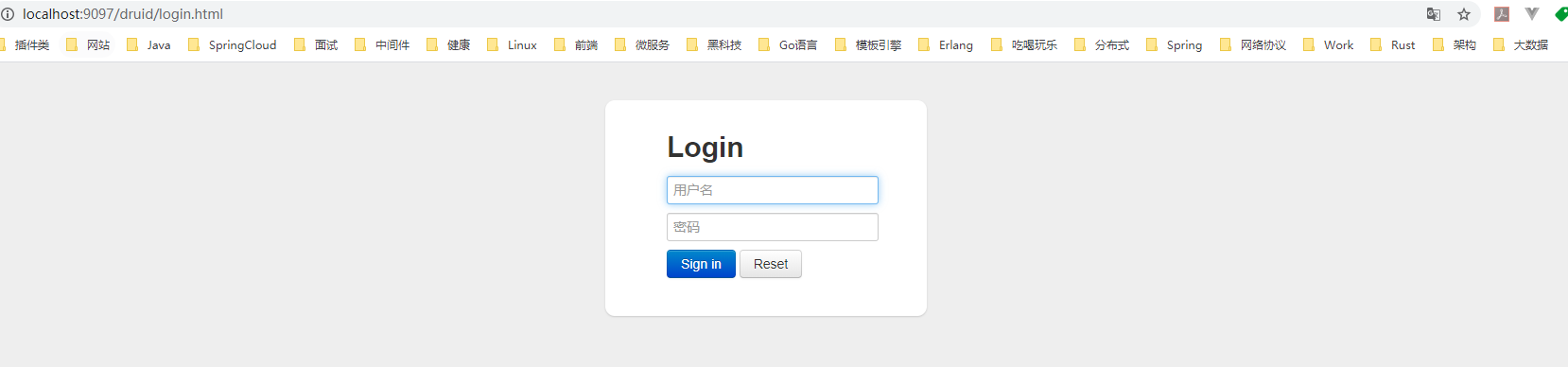
Druid是一款争议比较多的数据源框架,项目的Issue中也有人提出过框架中加入太多和连接池无关的功能,例如SQL监控、属性展示等等,这些功能本该让专业的监控软件完成。但毫无疑问,这是一款活跃度比较高的优秀国产开源框架。
配置schema和data脚本
spring-boot-starter-jdbc可以通过一些配置然后委托DataSourceInitializerInvoker进行schema(一般理解为DDL)和data(一般理解为DML)脚本的加载和执行,具体的配置项是:
# 定义schema的加载路径,可以通过英文逗号指定多个路径
spring.datasource.schema=classpath:/ddl/schema.sql
# 定义data的加载路径,可以通过英文逗号指定多个路径
spring.datasource.data=classpath:/dml/data.sql
# 可选
# spring.datasource.schema-username=
# spring.datasource.schema-password=
# 项目数据源初始化之后的执行模式,可选值EMBEDDED、ALWAYS和NEVER
spring.datasource.initialization-mode=always
类路径的resources文件夹下添加ddl/schema.sql:
DROP TABLE IF EXISTS customer;
CREATE TABLE customer
(
id BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY COMMENT '主键',
customer_name VARCHAR(32) NOT NULL COMMENT '客户名称',
create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
edit_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间'
) COMMENT '客户表';
由于spring.datasource.initialization-mode指定为ALWAYS,每次数据源初始化都会执行spring.datasource.schema中配置的脚本,会删表重建。接着类路径的resources文件夹下添加dml/data.sql:
INSERT INTO customer(customer_name) VALUES ('throwable');
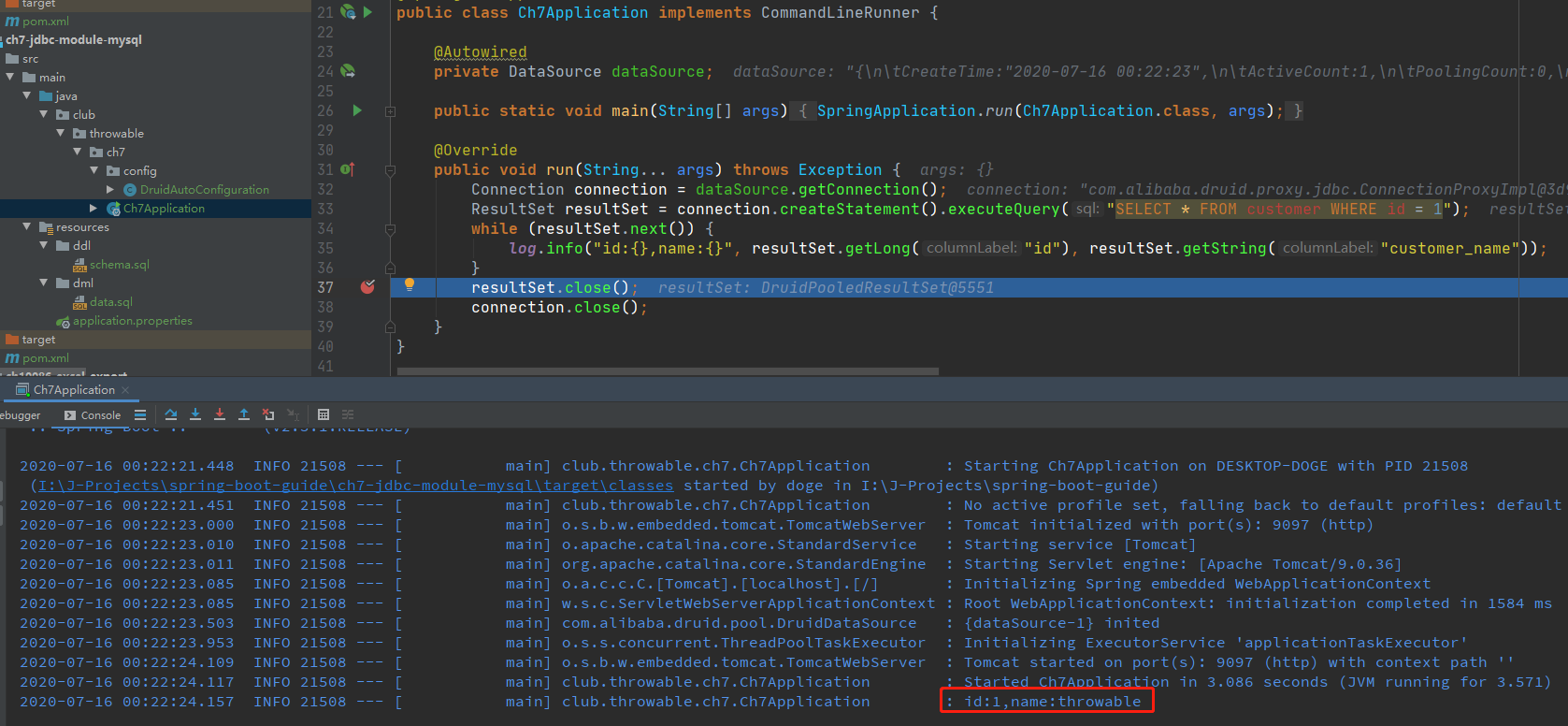
添加一个CommandLineRunner实现验证一下:
@Slf4j
@SpringBootApplication
public class Ch7Application implements CommandLineRunner {
@Autowired
private DataSource dataSource;
public static void main(String[] args) {
SpringApplication.run(Ch7Application.class, args);
}
@Override
public void run(String... args) throws Exception {
Connection connection = dataSource.getConnection();
ResultSet resultSet = connection.createStatement().executeQuery("SELECT * FROM customer WHERE id = 1");
while (resultSet.next()) {
log.info("id:{},name:{}", resultSet.getLong("id"), resultSet.getString("customer_name"));
}
resultSet.close();
connection.close();
}
}
启动后执行结果如下:
这里务必注意一点,spring.datasource.schema指定的脚本执行成功之后才会执行spring.datasource.data指定的脚本,如果想仅仅执行spring.datasource.data指定的脚本,那么需要至少把spring.datasource.schema指向一个空的文件,确保spring.datasource.schema指定路径的文件初始化成功。
使用JdbcTemplate
spring-boot-starter-jdbc中自带的JdbcTemplate是对JDBC的轻度封装。这里只简单介绍一下它的使用方式,构建一个面向前面提到的customer表的具备CURD功能的DAO。这里先在前文提到的DruidAutoConfiguration中添加一个JdbcTemplate实例到IOC容器中:
@Bean
public JdbcTemplate jdbcTemplate(DataSource dataSource){
return new JdbcTemplate(dataSource);
}
添加一个Customer实体类:
// 实体类
@Data
public class Customer {
private Long id;
private String customerName;
private LocalDateTime createTime;
private LocalDateTime editTime;
}
接着添加一个CustoemrDao类,实现增删改查:
// CustoemrDao
@RequiredArgsConstructor
@Repository
public class CustomerDao {
private final JdbcTemplate jdbcTemplate;
/**
* 增
*/
public int insertSelective(Customer customer) {
StringJoiner p = new StringJoiner(",", "(", ")");
StringJoiner v = new StringJoiner(",", "(", ")");
Optional.ofNullable(customer.getCustomerName()).ifPresent(x -> {
p.add("customer_name");
v.add("?");
});
Optional.ofNullable(customer.getCreateTime()).ifPresent(x -> {
p.add("create_time");
v.add("?");
});
Optional.ofNullable(customer.getEditTime()).ifPresent(x -> {
p.add("edit_time");
v.add("?");
});
String sql = "INSERT INTO customer" + p.toString() + " VALUES " + v.toString();
KeyHolder keyHolder = new GeneratedKeyHolder();
int updateCount = jdbcTemplate.update(con -> {
PreparedStatement ps = con.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS);
int index = 1;
if (null != customer.getCustomerName()) {
ps.setString(index++, customer.getCustomerName());
}
if (null != customer.getCreateTime()) {
ps.setTimestamp(index++, Timestamp.valueOf(customer.getCreateTime()));
}
if (null != customer.getEditTime()) {
ps.setTimestamp(index, Timestamp.valueOf(customer.getEditTime()));
}
return ps;
}, keyHolder);
customer.setId(Objects.requireNonNull(keyHolder.getKey()).longValue());
return updateCount;
}
/**
* 删
*/
public int delete(long id) {
return jdbcTemplate.update("DELETE FROM customer WHERE id = ?", id);
}
/**
* 查
*/
public Customer queryByCustomerName(String customerName) {
return jdbcTemplate.query("SELECT * FROM customer WHERE customer_name = ?",
ps -> ps.setString(1, customerName), SINGLE);
}
public List<Customer> queryAll() {
return jdbcTemplate.query("SELECT * FROM customer", MULTI);
}
public int updateByPrimaryKeySelective(Customer customer) {
final long id = Objects.requireNonNull(Objects.requireNonNull(customer).getId());
StringBuilder sql = new StringBuilder("UPDATE customer SET ");
Optional.ofNullable(customer.getCustomerName()).ifPresent(x -> sql.append("customer_name = ?,"));
Optional.ofNullable(customer.getCreateTime()).ifPresent(x -> sql.append("create_time = ?,"));
Optional.ofNullable(customer.getEditTime()).ifPresent(x -> sql.append("edit_time = ?,"));
StringBuilder q = new StringBuilder(sql.substring(0, sql.lastIndexOf(","))).append(" WHERE id = ?");
return jdbcTemplate.update(q.toString(), ps -> {
int index = 1;
if (null != customer.getCustomerName()) {
ps.setString(index++, customer.getCustomerName());
}
if (null != customer.getCreateTime()) {
ps.setTimestamp(index++, Timestamp.valueOf(customer.getCreateTime()));
}
if (null != customer.getEditTime()) {
ps.setTimestamp(index++, Timestamp.valueOf(customer.getEditTime()));
}
ps.setLong(index, id);
});
}
private static Customer convert(ResultSet rs) throws SQLException {
Customer customer = new Customer();
customer.setId(rs.getLong("id"));
customer.setCustomerName(rs.getString("customer_name"));
customer.setCreateTime(rs.getTimestamp("create_time").toLocalDateTime());
customer.setEditTime(rs.getTimestamp("edit_time").toLocalDateTime());
return customer;
}
private static ResultSetExtractor<List<Customer>> MULTI = rs -> {
List<Customer> result = new ArrayList<>();
while (rs.next()) {
result.add(convert(rs));
}
return result;
};
private static ResultSetExtractor<Customer> SINGLE = rs -> rs.next() ? convert(rs) : null;
}
测试结果如下:
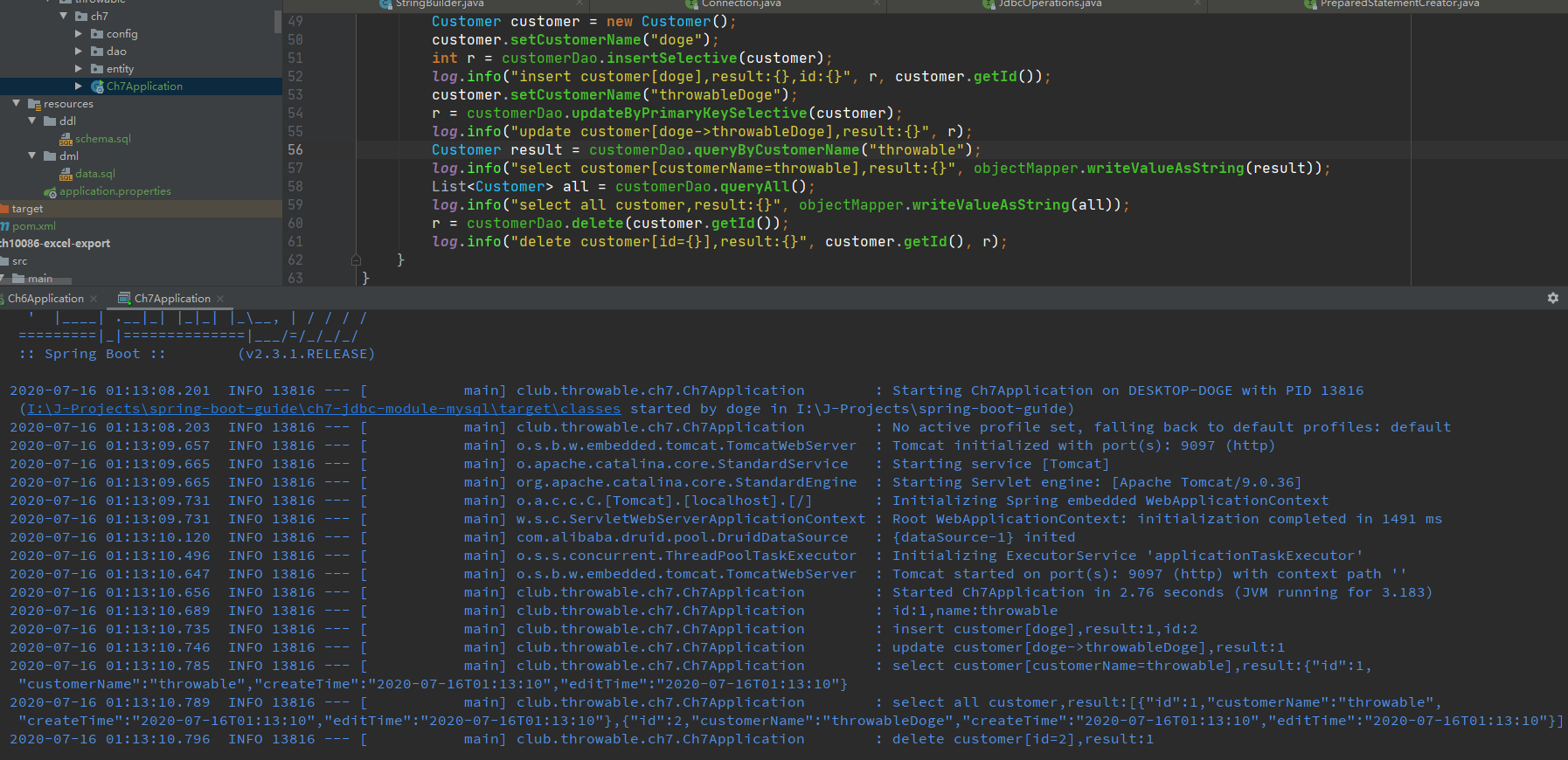
JdbcTemplate的优势是可以应用函数式接口简化一些值设置和值提取的操作,并且获得接近于原生JDBC的执行效率,但是它的明显劣势就是会产生大量模板化的代码,在一定程度上影响开发效率。
小结
本文简单分析spring-boot-starter-jdbc引入,以及不同数据库和不同数据源的使用方式,最后简单介绍了JdbcTemplate的基本使用。
demo项目仓库:
Github:https://github.com/zjcscut/spring-boot-guide/tree/master/ch6-jdbc-module-h2Github:https://github.com/zjcscut/spring-boot-guide/tree/master/ch7-jdbc-module-mysql
(本文完 c-2-d e-a-20200716 1:15 AM)
公众号《Throwable文摘》(id:throwable-doge),不定期推送架构设计、并发、源码探究相关的原创文章:
![]()
SpringBoot2.x入门教程:引入jdbc模块与JdbcTemplate简单使用的更多相关文章
- SpringBoot2.x入门:引入web模块
前提 这篇文章是<SpringBoot2.x入门>专辑的第3篇文章,使用的SpringBoot版本为2.3.1.RELEASE,JDK版本为1.8. 主要介绍SpringBoot的web模 ...
- .NET轻量级MVC框架:Nancy入门教程(二)——Nancy和MVC的简单对比
在上一篇的.NET轻量级MVC框架:Nancy入门教程(一)——初识Nancy中,简单介绍了Nancy,并写了一个Hello,world.看到大家的评论,都在问Nancy的优势在哪里?和微软的MVC比 ...
- SpringBoot2.x入门教程:理解配置文件
前提 这篇文章是<SpringBoot2.x入门>专辑的第4篇文章,使用的SpringBoot版本为2.3.1.RELEASE,JDK版本为1.8. 主要介绍SpringBoot配置文件一 ...
- testng入门教程1在testng运行一个简单的testcase
在eclips运行java,创建一个Java类文件名TestNGSimpleTest C:\ > TestNG_WORKSPACE import org.testng.annotations. ...
- MongoDB最简单的入门教程之五-通过Restful API访问MongoDB
通过前面四篇的学习,我们已经在本地安装了一个MongoDB数据库,并且通过一个简单的Spring boot应用的单元测试,插入了几条记录到MongoDB中,并通过MongoDB Compass查看到了 ...
- Node入门教程(12)第十章:Node的HTTP模块
Ryan Dahl开发node的初衷就是:把Nginx非阻塞IO功能和一个高度封装的WEB服务器结合在一起的东东.所以Node初衷就是为了高性能的Web服务器去的,所以:Node的HTTP模块也是核心 ...
- Node入门教程(8)第六章:path 模块详解
path 模块详解 path 模块提供了一些工具函数,用于处理文件与目录的路径.由于windows和其他系统之间路径不统一,path模块还专门做了相关处理,屏蔽了彼此之间的差异. 可移植操作系统接口( ...
- JDBC快速入门教程
JDBC是什么? JDBC API是一个Java API,可以访问任何类型表列数据,特别是存储在关系数据库中的数据.JDBC代表Java数据库连接. JDBC库中所包含的API通常与数据库使用于: 连 ...
- 转载:《TypeScript 中文入门教程》 7、模块
版权 文章转载自:https://github.com/zhongsp 建议您直接跳转到上面的网址查看最新版本. 关于术语的一点说明: 请务必注意一点,TypeScript 1.5里术语名已经发生了变 ...
随机推荐
- http 的8中请求方式:
http 的8中请求方式: 1.OPTIONS 返回服务器针对特定资源所支持的HTTP请求方法,也可以利用向web服务器发送‘*’的请求来测试服务器的功能性 2.HEAD 向服务器索与GET请求相一致 ...
- Java 中的线程 thread
一.问:线程有哪些状态? new, runnable, running, waiting, dead 线程状态间的流转 二.问:线程实现方式? 实现 Runnable 接口,然后new Thread, ...
- Linux下重新设置 MySQL 的密码
1.重置密码的第一步就是跳过MySQL的密码认证过程,方法如下: #vim /etc/my.cnf(注:windows下修改的是my.ini) 很多老铁,在开始时设置了 MySQL 的密码,后来一段时 ...
- 尚学堂 213_尚学堂_高淇_java300集最全视频教程_反射机制_提高反射效率_操作泛型_操作注解_合并文件.mp4
在反射的时候如果去掉了安全性检测机制,能够大大的提高反射的执行效率,我们来看下面的代码进行比较 package com.bjsxt.test; import java.lang.reflect.Met ...
- php artisan migrate数据迁移报错
laravel 5.4 改变了默认的数据库字符集,现在utf8mb4包括存储emojis支持.如果你运行MySQL v5.7.7或者更高版本,则不需要做任何事情. 当你试着在一些MariaDB或者一些 ...
- ThinkPHP 5接阿里云短信接口
1.首先将api_sdk文件放入vendor文件夹下 2.在config文件中作相应的配置 3.封装发送短信的方法 4.调用发送短信方法
- 推荐一种通过刷leetcode来增强技术功底的方法
背景 如果前人认为这个一种学习提高或者检验能力的成功实践.而自己目前又没有更好的方法,那就不妨试一试. 而不管作为面试官还是被面试者,编码题最近越来越流行.而两种角色都需要思考的问题是希望考察什么能力 ...
- 实现MFC扩展DLL中导出类和对话框
如果要编写模块化的软件,就要对对动态链接库(DLL)有一定的了解,本人这段时间在修改以前的软件时,决定把重复用的类和对话框做到DLL中,下面就从一个简单的例子讲起,如何实现MFC扩展DLL中导出类和对 ...
- 设置CMD窗口为UTF-8编码
Windows下的CMD窗口默认是采用非UTF-8编码的,有时候运行一些UTF-8编写的批处理文件在控制台中的输出就是乱码, CHCP是MD DOS中的命令,用来显示或设置活动代码页编号的.用法是: ...
- angular弹出对话框结构
angular dialog标准结构,注意有checkbox时,需要外包一层div,checkbox-wrapper类的这个样式控制了不显示滚动条.