ORM框架对分表分库之分库和分表指定不同的字段
ORM框架分库分表已实现了
最近我完善了分库分表功能:
分库和分表可以指定不同的字段
首先看下配置上是如何配置的
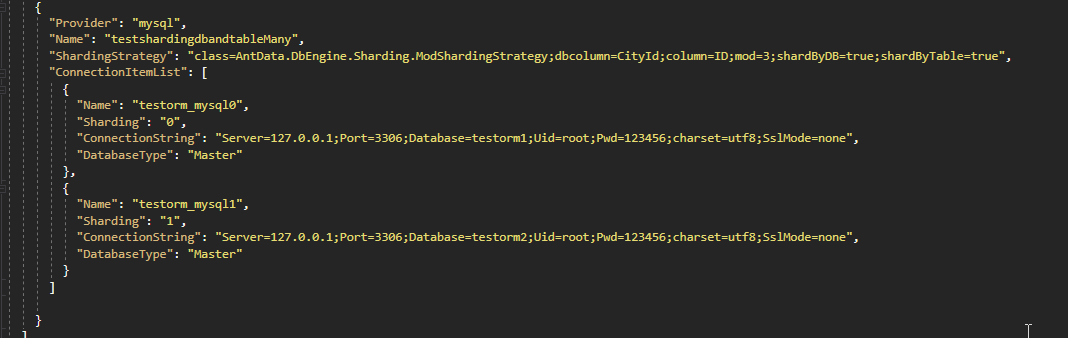
在配置上相比于上面提到的第3点,配置文件新增了
- dbcolumn 代表db是根据哪个字段分
- column 代表的table是根据哪个字段分
{
"Provider": "mysql",
"Name": "testshardingdbandtableMany",
"ShardingStrategy": "class=AntData.DbEngine.Sharding.ModShardingStrategy;dbcolumn=CityId;column=ID;mod=3;shardByDB=true;shardByTable=true",
"ConnectionItemList": [
{
"Name": "testorm_mysql0",
"Sharding": "0",
"ConnectionString": "Server=127.0.0.1;Port=3306;Database=testorm1;Uid=root;Pwd=123456;charset=utf8;SslMode=none",
"DatabaseType": "Master"
},
{
"Name": "testorm_mysql1",
"Sharding": "1",
"ConnectionString": "Server=127.0.0.1;Port=3306;Database=testorm2;Uid=root;Pwd=123456;charset=utf8;SslMode=none",
"DatabaseType": "Master"
}
]
}
根据上面的配置的意思就是:
- class=AntData.DbEngine.Sharding.ModShardingStrategy代表的是按照取模策略来分表分库
- shardByDB=true;shardByTable=true 开启了分库分表的开关
- dbcolumn=CityId 代表的是分库是按照CityId的来分
- column=ID;代表的是分表是按照ID的值字段来分
- mod=3;代表的分表是按照3来取模
- db的取模是看ConnectionItemList有配置几个,上面的例子是配置2个,所以分库是按照2来取模
对应我的库和表如下
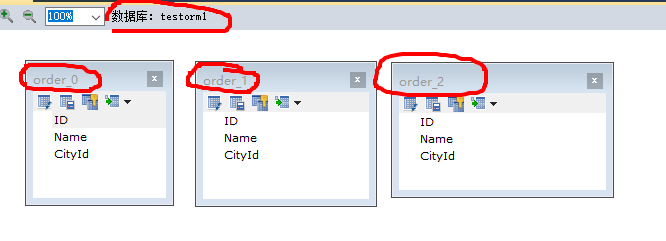
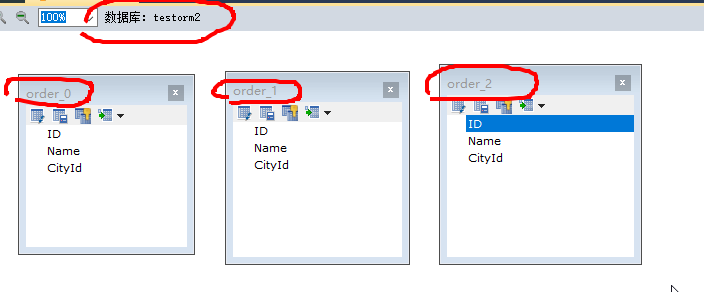
根据codegen来生成代码
注意一点:
代码生成器生成的表需要自己加一个_{0}
例如:[Table(Comment = "订单表", Name = "order_{0}")]
/// <summary>
/// Database : testorm1
/// Data Source : localhost
/// Server Version : 5.6.26-log
/// </summary>
public partial class Entitys : IEntity
{
/// <summary>
/// 订单表
/// </summary>
public IQueryable<Order> Orders { get { return this.Get<Order>(); } }
private readonly IDataContext con;
public IQueryable<T> Get<T>()
where T : class
{
return this.con.GetTable<T>();
}
public Entitys(IDataContext con)
{
this.con = con;
}
}
/// <summary>
/// 订单表
/// </summary>
[Table(Comment = "订单表", Name = "order_{0}")]
public partial class Order : BaseEntity
{
#region Column
/// <summary>
/// 订单号
/// </summary>
[Column("ID", DataType = DataType.Int64, Comment = "订单号"), Nullable]
public long? ID { get; set; } // bigint(20)
/// <summary>
/// 名称
/// </summary>
[Column("Name", DataType = DataType.VarChar, Length = 50, Comment = "名称"), Nullable]
public string Name { get; set; } // varchar(50)
/// <summary>
/// CityId
/// </summary>
[Column("CityId", DataType = DataType.Int64, Comment = "CityId"), Nullable]
public long CityId { get; set; }
#endregion
}
下面来写测试代码验证
/// <summary>
/// 测试mod分库插入到testorm2数据库的order_1表
/// </summary>
[TestMethod]
public void TestMethod6_01()
{
var id = 1;
//查testorm2 的 order_1 表
var odIsExist = DB.Tables.Orders.Any(r => r.ID.Equals(1) && r.CityId == 1);
if (odIsExist)
{
return;
}
var order = new Order
{
ID = 1,//按照id分表
Name = "上海大学",
CityId = 1//按照cityid分库
};
var result = DB.Insert(order);
Assert.AreEqual(result, 1);
}
/// <summary>
/// 测试mod分库插入到testorm1数据库
/// </summary>
[TestMethod]
public void TestMethod6_02()
{
var id = 2;
//查testorm1 的 order_2 表
var odIsExist = DB.Tables.Orders.Any(r => r.ID.Equals(2) && r.CityId == 2);
if (odIsExist)
{
return;
}
var order = new Order
{
ID = 2,
Name = "北京大学",
CityId = 2
};
var result = DB.Insert(order);
Assert.AreEqual(result, 1);
}
[TestMethod]
public void TestMethod6_022()
{
var id = 2;
//3%2=1 查testorm1 的3%3=0 order_0 表
var odIsExist = DB.Tables.Orders.Any(r => r.ID.Equals(3) && r.CityId == 3);
if (odIsExist)
{
return;
}
var order = new Order
{
ID = 3,
Name = "厦门大学",
CityId =3
};
var result = DB.Insert(order);
Assert.AreEqual(result, 1);
}
/// <summary>
/// 测试mod分库 查询testorm2数据库
/// </summary>
[TestMethod]
public void TestMethod6_03()
{
var id = 1;
// 1%2=1 testorm2的 1%3=1 order_1
var tb1 = DB.Tables.Orders.FirstOrDefault(r => r.ID.Equals(1)&&r.CityId ==1);
Assert.IsNotNull(tb1);
}
/// <summary>
/// 测试mod分库 查询testorm1数据库
/// </summary>
[TestMethod]
public void TestMethod6_04()
{
var id = 2;
// 2%2=0 testorm1的 2%3=2 order_2
var tb1 = DB.Tables.Orders.FirstOrDefault(r => r.ID.Equals(2)&&r.CityId ==2);
Assert.IsNotNull(tb1);
}
/// <summary>
/// 测试mod分库 不指定sharing column 查询叠加
/// </summary>
[TestMethod]
public void TestMethod6_05()
{
//没有指定CityID也没有指定ID 会查询2个db的各3张表 6次的叠加
var tb1 = DB.Tables.Orders.ToList();
Assert.IsNotNull(tb1);
Assert.AreEqual(tb1.Count, 3);
//没有指定CityID 那么会查询2个db 。由于指定了ID 那么只会查询 1%3=1 order_1 2%3=2 order_2
var odIsExist = DB.Tables.Orders.Where(r => r.ID.Equals(1) || r.ID.Equals(2)).ToList();
Assert.AreEqual(odIsExist.Count, 2);
}
/// <summary>
/// 测试mod分库修改到testorm2数据库
/// </summary>
[TestMethod]
public void TestMethod6_06()
{
var id = 1;
//没有指定CityID 那么会查询2个db 。由于指定了ID 那么只会查询 1%3=1 order_1
var result = DB.Tables.Orders.Where(r => r.ID.Equals(1)).Set(r => r.Name, y => y.Name + "1").Update();
Assert.AreEqual(result, 1);
}
/// <summary>
/// 测试mod分库修改到testorm1数据库
/// </summary>
[TestMethod]
public void TestMethod6_07()
{
var id = 2;
//没有指定CityID 那么会查询2个db 。由于指定了ID 那么只会查询 2%3=2 order_2
var result = DB.Tables.Orders.Where(r => r.ID.Equals(2)).Set(r => r.Name, y => y.Name + "1").Update();
Assert.AreEqual(result, 1);
}
/// <summary>
/// 测试mod分库删除到testorm2数据库
/// </summary>
[TestMethod]
public void TestMethod6_08()
{
var id = 1;
//没有指定CityID 那么会查询2个db 。由于指定了ID 那么只会查询 1%3=1 order_1
var result = DB.Tables.Orders.Where(r => r.ID.Equals(1)).Delete();
Assert.AreEqual(result, 1);
}
/// <summary>
/// 测试mod分库删除到testorm1数据库
/// </summary>
[TestMethod]
public void TestMethod6_09()
{
var id = 2;
//没有指定CityID 那么会查询2个db 。由于指定了ID 那么只会查询 2%3=2 order_2
var result = DB.Tables.Orders.Where(r => r.ID.Equals(2)).Delete();
Assert.AreEqual(result, 1);
}
/// <summary>
/// 测试mod分库批量分别插入到testorm1 和 testorm2数据库
/// </summary>
[TestMethod]
public void TestMethod7_02()
{
var orderList = new List<Order>();
//会分到3%2=1 testorm2 的 order_0
orderList.Add(new Order
{
ID = 3,
Name = "上海大学",
CityId = 3
});
//会分到4%2=0 testorm1 的 order_1
orderList.Add(new Order
{
ID = 4,
Name = "上海大学",
CityId = 4
});
//没有指定 shading column的话是默认分到第一个分片
orderList.Add(new Order
{
ID = null,
Name = "上海大学",
//CityId = 0
});
var rows = DB.BulkCopy(orderList);
Assert.AreEqual(rows.RowsCopied, 3);
}
[TestMethod]
public void TestMethod7_03()
{
var odIsExist = DB.Tables.Orders.Delete();
}
/// <summary>
/// 指定了shadingtable的分库 自动会走到1对应的db
/// </summary>
[TestMethod]
public void TestMethod7_04()
{
DB.UseShardingDbAndTable("1","1", con =>
{
//1%2 = 1 1%3 = 1 testorm2 的 order_1
var first = con.Tables.Orders.FirstOrDefault();
Assert.IsNotNull(first);
Assert.AreEqual(1, first.ID);
});
}
/// <summary>
/// 指定了shadingtable的分库 自动会走到0对应的db
/// </summary>
[TestMethod]
public void TestMethod7_05()
{
DB.UseShardingDbAndTable("0","0", con =>
{
//0%2 = 0 0%3 = 0 testorm1 的 order_0
var first = con.Tables.Orders.FirstOrDefault();
Assert.IsNotNull(first);
Assert.AreEqual(2, first.ID);
});
}
总结
目前在AntData orm中使用分库分表在使用上是不是很爽:
- 决定好用哪种策略 是取模 还是区间分片
- 支持只分表,只分库,或者既分表又分库
- 如果既分表又分库还可以指定分库和分表的字段不同
- 只需要在配置文件上配置好即可
- 在写代码和平常一样
ORM框架对分表分库之分库和分表指定不同的字段的更多相关文章
- .Net下的分库分表帮助类——用分库的思想来分表
简介 在大型项目中,我们会遇到分表分库的情景. 分库,将不同模块对应的表拆分到对应的数据库下,其实伴随着公司内分布式系统的出现,这个过程也是自然而然就发生了,对应商品模块和用户模块, ...
- 分库分表(6)--- SpringBoot+ShardingSphere实现分表+ 读写分离
分库分表(6)--- ShardingSphere实现分表+ 读写分离 有关分库分表前面写了五篇博客: 1.分库分表(1) --- 理论 2.分库分表(2) --- ShardingSphere(理论 ...
- mysql分表场景分析与简单分表操作
为什么要分表 首先要知道什么情况下,才需要分表个人觉得单表记录条数达到百万到千万级别时就要使用分表了,分表的目的就在于此,减小数据库的负担,缩短查询时间. 表分割有两种方式: 1水平分割:根据一列或多 ...
- ORM框架对分表分库的实现
*:first-child { margin-top: 0 !important; } .markdown-body>*:last-child { margin-bottom: 0 !impor ...
- Mysql性能优化四:分库,分区,分表,你们如何做?
分库分区分表概念 分区 就是把一张表的数据分成N个区块,在逻辑上看最终只是一张表,但底层是由N个物理区块组成的 分表 就是把一张数据量很大的表按一定的规则分解成N个具有独立存储空间的实体表.系统读写时 ...
- 分库分表(4) ---SpringBoot + ShardingSphere 实现分表
分库分表(4)--- ShardingSphere实现分表 有关分库分表前面写了三篇博客: 1.分库分表(1) --- 理论 2.分库分表(2) --- ShardingSphere(理论) 3.分库 ...
- (动态模型类,我的独创)Django的原生ORM框架如何支持MongoDB,同时应对客户使用时随时变动字段
1.背景知识 需要开发一个系统,处理大量EXCEL表格信息,各种类别.表格标题多变,因此使用不需要预先设计数据表结构的MongoDB,即NoSQL.一是字段不固定,二是同名字段可以存储不同的字段类型. ...
- .net core 基于Dapper 的分库分表开源框架(core-data)
一.前言 感觉很久没写文章了,最近也比较忙,写的相对比较少,抽空分享基于Dapper 的分库分表开源框架core-data的强大功能,更好的提高开发过程中的效率: 在数据库的数据日积月累的积累下,业务 ...
- 学习sharding-jdbc 分库分表扩展框架
先丢代码地址 https://gitee.com/a247292980/sharding-jdbc 再丢pom.xml的dependency <properties> <projec ...
随机推荐
- 【1w字+干货】第一篇,基础:让你的 Redis 不再只是安装吃灰到卸载(Linux环境)
Redis 基础以及进阶的两篇已经全部更新好了,为了字数限制以及阅读方便,分成两篇发布. 本篇主要内容为:NoSQL 引入 Redis ,以及在 Linux7 环境下的安装,配置,以及总结了非常详细的 ...
- Redis 核心篇:唯快不破的秘密
天下武功,无坚不摧,唯快不破! 学习一个技术,通常只接触了零散的技术点,没有在脑海里建立一个完整的知识框架和架构体系,没有系统观.这样会很吃力,而且会出现一看好像自己会,过后就忘记,一脸懵逼. 跟着「 ...
- 忒修斯的Mac
我有一台Mac笔记本,用了快6年了,当初买它的时候还借了几千块. 三年前,它的屏幕坏了,修理的方式就是直接换屏,而换屏其实就是上半部分连壳带屏幕整个换掉,简单的说:另一台电脑的上半身嫁接过来. 今年, ...
- 【故障公告】K8s CofigMap 挂载问题引发网站故障
今天凌晨我们用阿里云服务器自建的 kubernetes 集群出现突发异常情况,博客站点(blog-web)与博客 web api(blog-api)的 pod 无法正常启动(CrashLoopBack ...
- shell批量解压源码包
有时候部署环境有很多安装包,如果一个一个地解压缩实在太麻烦了,可以用shell批量进行解压缩.命令如下: [root@localhost ~]# vi tar.sh #! /bin/bash #标称是 ...
- C#高级编程第11版 - 第三章 索引
[1]3.1 创建及使用类 1.构造函数:构造函数的名字与类名相同: 使用 new 表达式创建类的对象或者结构(例如int)时,会调用其构造函数.并且通常初始化新对象的数据成员. 除非类是静态的,否则 ...
- LOJ10102旅游航道
题目描述 SGOI 旅游局在 SG-III 星团开设了旅游业务,每天有数以万计的地球人来这里观光,包括联合国秘书长,各国总统和 SGOI 总局局长等.旅游线路四通八达,每天都有众多的载客太空飞船在星团 ...
- Java 学习之路 -- day00
Java 学习之路 -- day00 Typora 快捷键操作 标题:#+空格 2. *斜体* 3. **加粗** 4. **斜体加粗*** 5. ~~删除线~~ 6. > 引用 7. ···分 ...
- C链表-C语言入门经典例题
struct student { long num; float score; struct student *next; }; 注意:只是定义了一个struct student类型,并未实际分配存储 ...
- VIT Vision Transformer | 先从PyTorch代码了解
文章原创自:微信公众号「机器学习炼丹术」 作者:炼丹兄 联系方式:微信cyx645016617 代码来自github [前言]:看代码的时候,也许会不理解VIT中各种组件的含义,但是这个文章的目的是了 ...