springcloud系列七 整合slueth,zipkin 分布式链路调用系统:
首先在代码里面引入依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
这个依赖包括了前几个依赖,所以引入一个就可以了
可以点进这个依赖看下:
</parent>
<artifactId>spring-cloud-starter-zipkin</artifactId>
<name>Spring Cloud Starter Zipkin</name>
<description>Spring Cloud Starter Zipkin</description>
<properties>
<main.basedir>${basedir}/../..</main.basedir>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
</dependencies>
所以只需要引入刚才那个依赖就可以了
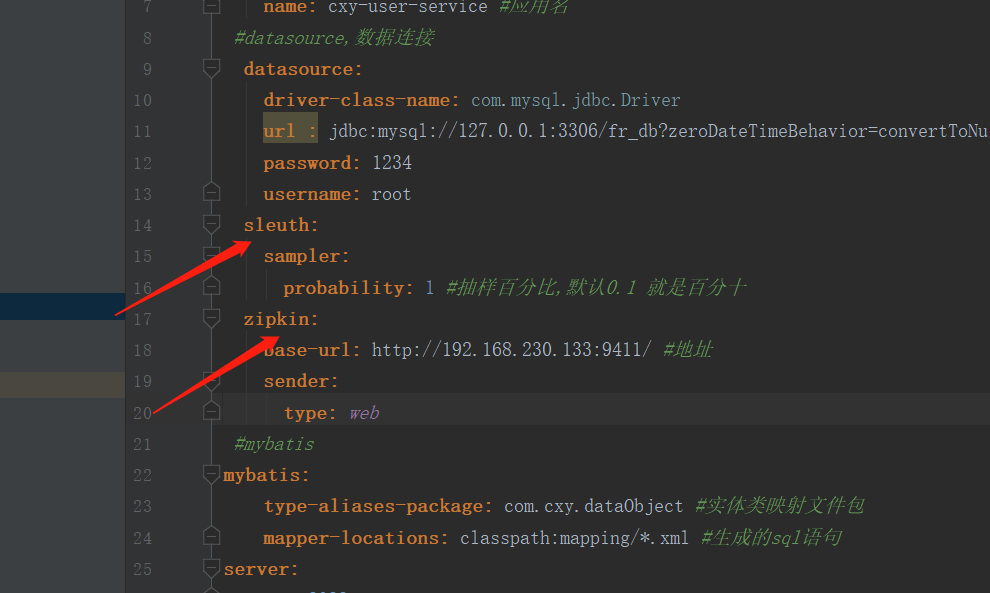
yml 配置:
eureka:
client:
serviceUrl:
defaultZone: http://admin:admin@127.0.0.1:8761/eureka/ #eureka注册中心地址
spring:
application:
name: cxy-user-service #应用名
#datasource,数据连接
datasource:
driver-class-name: com.mysql.jdbc.Driver
url : jdbc:mysql://127.0.0.1:3306/fr_db?zeroDateTimeBehavior=convertToNull&autoReconnect=true&useUnicode=true&characterEncoding=utf-8
password:
username: root
sleuth:
sampler:
probability: #抽样百分比,默认0. 就是百分十
zipkin:
base-url: http://192.168.230.133:9411/ #地址
sender:
type: web
#mybatis
mybatis:
type-aliases-package: com.cxy.dataObject #实体类映射文件包
mapper-locations: classpath:mapping/*.xml #生成的sql语句
server:
port: 8082
feign:
hystrix:
enabled: true
logging:
level:
org.springframework.cloud.openfeign: debug
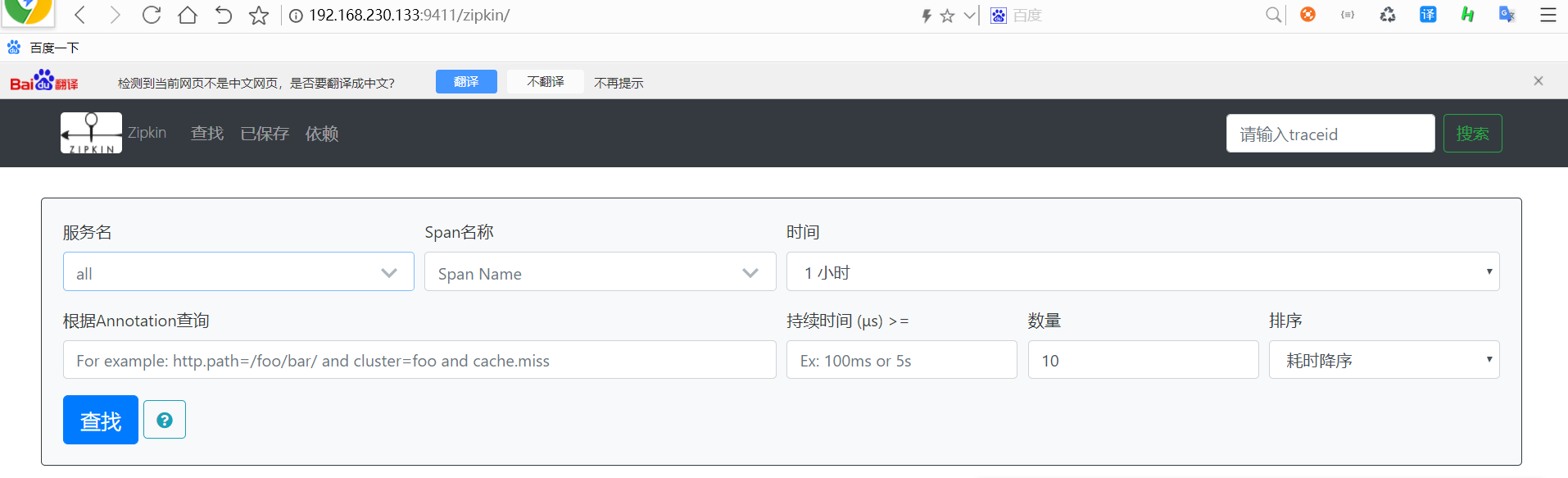
然后docker安装zipkin
启动zipkin
在浏览器输入地址:
然后启动服务:
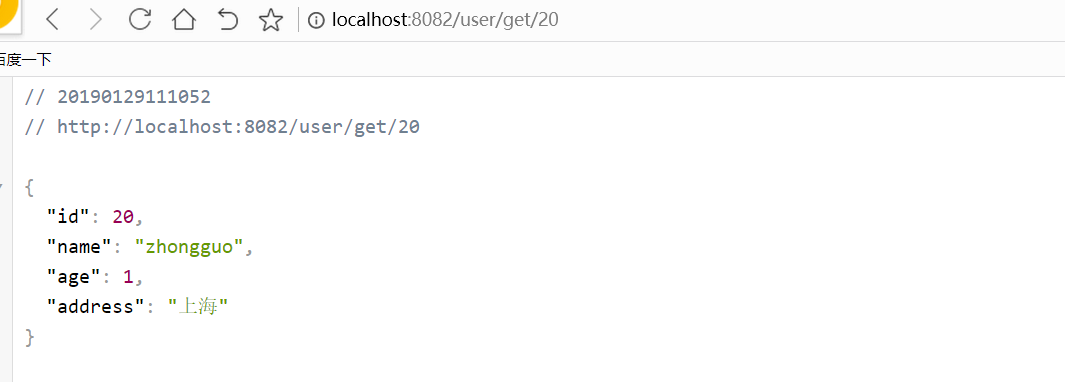
服务调用成功:


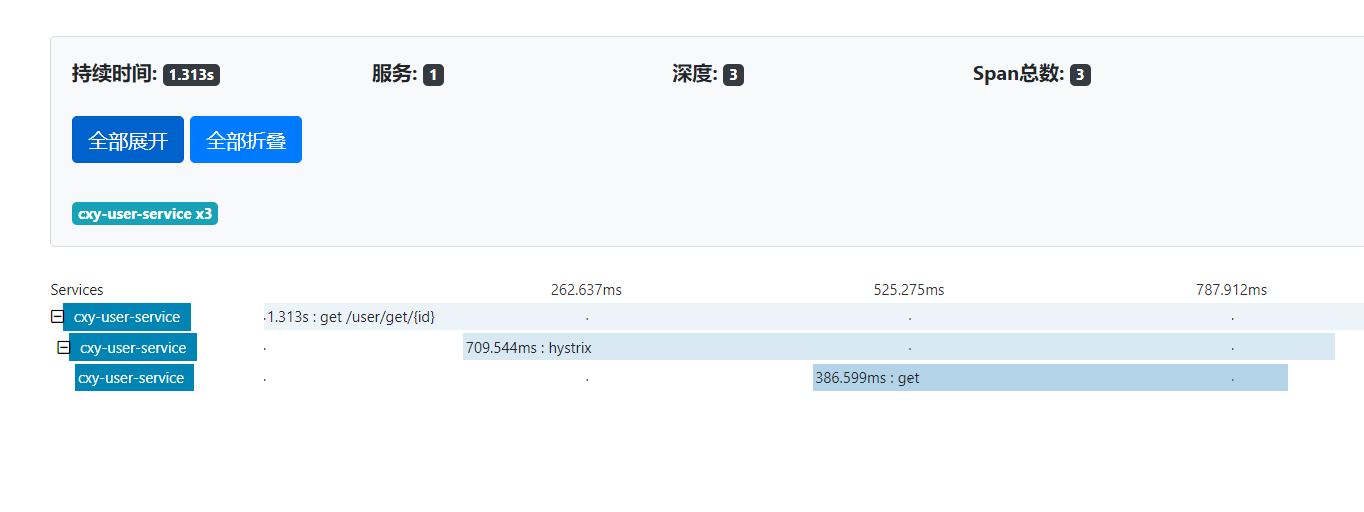
可以看到每个服务的调用时间,可以进行优化相关配置
springcloud系列七 整合slueth,zipkin 分布式链路调用系统:的更多相关文章
- zipkin分布式链路追踪系统
基于zipkin分布式链路追踪系统预研第一篇 分布式服务追踪系统起源于Google的论文“Dapper, a Large-Scale Distributed Systems Tracing Inf ...
- 基于zipkin分布式链路追踪系统预研第一篇
本文为博主原创文章,未经博主允许不得转载. 分布式服务追踪系统起源于Google的论文“Dapper, a Large-Scale Distributed Systems Tracing Infras ...
- spring cloud 2.x版本 Sleuth+Zipkin分布式链路追踪
前言 本文采用Spring cloud本文为2.1.8RELEASE,version=Greenwich.SR3 本文基于前两篇文章eureka-server.eureka-client.eureka ...
- 分布式链路追踪系统Sleuth和ZipKin
1.微服务下的链路追踪讲解和重要性 简介:讲解什么是分布式链路追踪系统,及使用好处 进行日志埋点,各微服务追踪. 2.SpringCloud的链路追踪组件Sleuth 1.官方文档 http://cl ...
- 分布式链路跟踪系统架构SkyWalking和zipkin和pinpoint
Net和Java基于zipkin的全链路追踪 https://www.cnblogs.com/zhangs1986/p/8966051.html 在各大厂分布式链路跟踪系统架构对比 中已经介绍了几大框 ...
- spring-cloud-sleuth 和 分布式链路跟踪系统
==================spring-cloud-sleuth==================spring-cloud-sleuth 可以用来增强 log 的跟踪识别能力, 经常在微服 ...
- NET Core微服务之路:SkyWalking+SkyApm-dotnet分布式链路追踪系统的分享
对于普通系统或者服务来说,一般通过打日志来进行埋点,然后再通过elk或splunk进行定位及分析问题,更有甚者直接远程服务器,直接操作查看日志,那么,随着业务越来越复杂,企业应用也进入了分布式服务化的 ...
- SkyWalking+SkyApm-dotnet分布式链路追踪系统
SkyWalking+SkyApm-dotnet分布式链路追踪系统 对于普通系统或者服务来说,一般通过打日志来进行埋点,然后再通过elk或splunk进行定位及分析问题,更有甚者直接远程服务器,直接操 ...
- 使用Skywalking分布式链路追踪系统
使用Skywalking分布式链路追踪系统 https://www.cnblogs.com/sunyuliang/p/11424848.html 当我们用很多服务时,各个服务间的调用关系是怎么样的?各 ...
随机推荐
- 记工作的变化--入住DB
2013年11月1日----一个值得纪念的日子! 今天才是我作为一个劳动者,步入社会的真正开始. 以前一直觉得做技术的技术做好就行了不用在意其余的细节.现实是做人(沟通)比做技术更重要! 以前一直觉得 ...
- c:if标签数据回显判断是否选中
<form action="/brand/list.do" method="post" style="padding-top:5px;" ...
- Activity的显式跳转和隐式挑战
安卓中Activity的跳转几乎是每一个APP都会用到的技术点.而且他的使用时十分简单的. 这里我们先说一下主要的技术要点: 1.在清单文件中注册新的Activity 2.通过意图跳转 这里我们看一下 ...
- 理解和正确使用Java中的断言(assert)
一.语法形式: Java2在1.4中新增了一个关键字:assert.在程序开发过程中使用它创建一个断言(assertion),它的语法形式有如下所示的两种形式:1.assert conditio ...
- Tkinter控件(python GUI)
- getParameter的用法及含义
equest.getparameter用来获取页面输入框输入的数据例如:jsp页面学员账户:<input type="text" name="username&qu ...
- 关于FILL_PARENTE和match_parent布局属性
在观看早期的代码的时候,经常会看到FILL_PARENT属性,但是新的代码中却有了MATCH_PARENT 那么,两者有何区别呢? 答案是,没有,只是换了个名字而已,均为-1
- windows下单机版的伪分布式solrCloud环境搭建Tomcat+solr+zookeeper
原文出自:http://sbp810050504.blog.51cto.com/2799422/1408322 按照该方法,伪分布式solr部署成功 ...
- [luogu3385]dfs_spfa判负环模板
解题关键:模板保存. 判负环不需要memset dis数组,因为已经更新过得d数组一定小于0,如果当前点可以更新d,说明d更小,有可能继续扩大负环,所以继续更新:如果比d[v]大,则不可能继续更新负环 ...
- Codeforces #499 Div2 E (1010C) Border
一直第9个样例WA,发现事情没有这么简单的时候只剩20分钟了...... 看了一些大神提交的代码,发现还能这么玩..... 这个题目可以转化成这个问题:给一堆[0,m)之间的数,可以随意组合成新的数( ...