Java集合类解析 ***
collection集合

Map集合

Hashtable和HashMap的区别:
Hashtable的方法是同步的,而HashMap的方法不是。
HashMap可以将空值作为一个表的条目的key或value。
Collection接口
Collection接口是List、Set和Queue接口的父接口,该接口里定义的方法既可用于操作Set集合,也可用于操作List和Queue集Collection提供了大量添加、删除、访问的方法来访问集合元素。主要的方法如下:
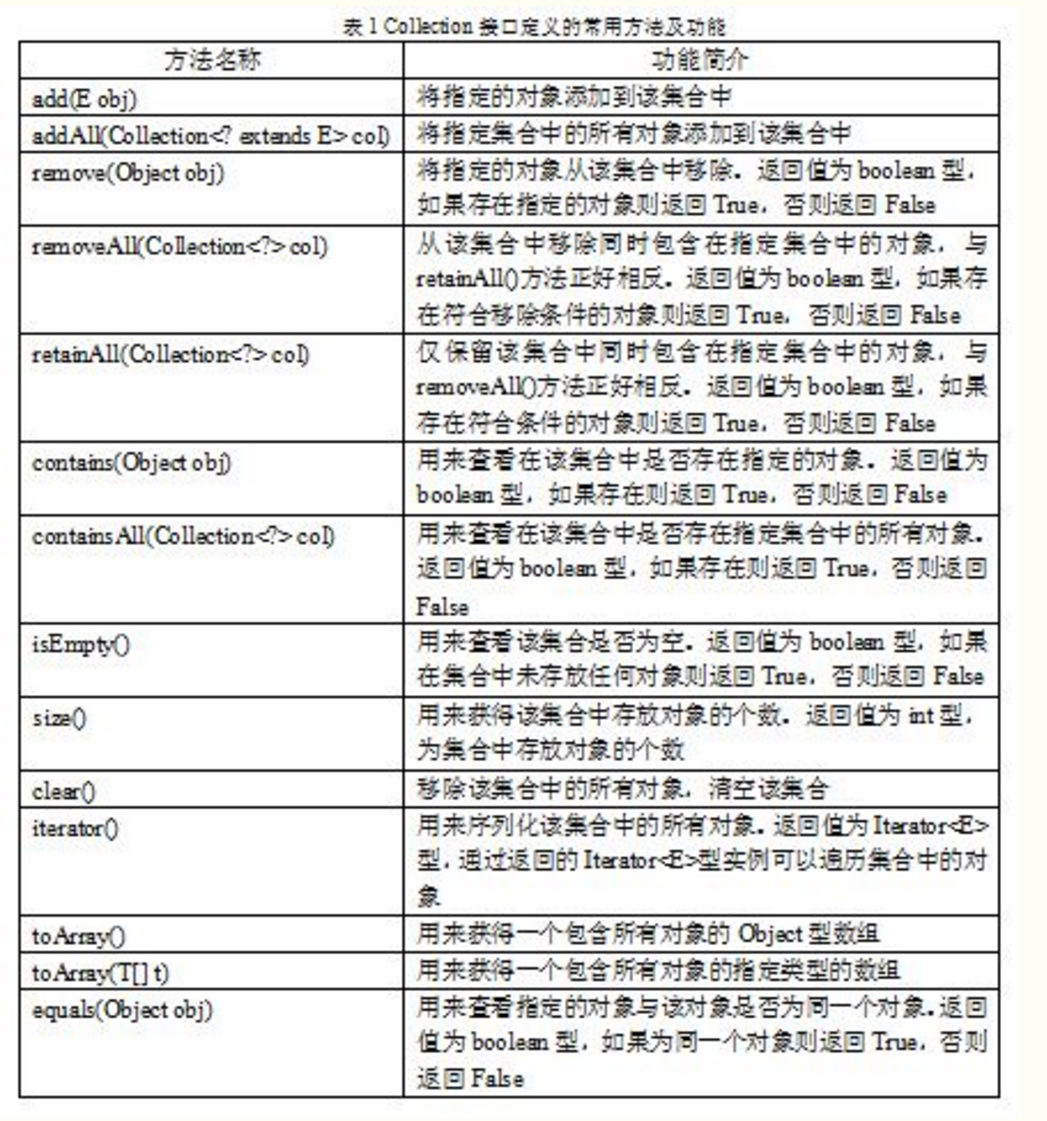
Java中的集合类包含的内容很多而且很重要,很多数据的存储和处理(排序,去重,筛选等)都需要通过集合类来完成。
首先java中集合类主要有两大分支:
(1)Collection (2)Map
先看它们的类图:
(1)Collection

(2)Map

可以看到它们之间的关系纷繁复杂,如果不系统的学习一下,还真是不知道有什么区别,该怎么选择。由于HashSet的内部实现原理是使用了HashMap,所以我们的学习路线为先学习Map集合类,然后再来学习Collection集合类。
(1)HashMap和Hashtable ( 注意table是小写的t,搞不懂为什么要这样,老是会写错。。。)
首先来看HashMap和HashTable,这两兄弟经常被放到一起来比较,那么它们有什么不一样呢?
a.HashMap不是线程安全的;HashTable是线程安全的,其线程安全是通过Sychronize实现。
b.由于上述原因,HashMap效率高于HashTable。
c.HashMap的键可以为null,HashTable不可以。
d.多线程环境下,通常也不是用HashTable,因为效率低。HashMap配合Collections工具类使用实现线程安全。同时还有ConcurrentHashMap可以选择,该类的线程安全是通过Lock的方式实现的,所以效率高于Hashtable。
好,比较了他们的不一样后,来讲讲它们的原理。
数组,链表,哈希表。各有优劣,顺便提一下,数组连续内存空间,查找速度快,增删慢;链表充分利用了内存,存储空间是不连续的,首尾存储上下一个节点的信息,所以寻址麻烦,查找速度慢,但是增删快;哈希表呢,综合了它们两个的有点,一个哈希表,由数组和链表组成。假设一条链表有1000个节点,现在查找最后一个节点,就得从第一个遍历到最后一个;如果用哈希表,将这条链表分为10组,用一个容量为10数组来存储这10组链表的头结点(a[0] = 0 , a[1] = 100 , a[2] = 200 …)。这样寻址就快了。
HashMap实现原理就是上述原理了,当然其具体实现还有很多其他的东西。Hashtable同理,只不过做了同步处理。
Hash碰撞,不同的key根据hash算法算出的值可能一样,如果一样就是所谓的碰撞。
优化措施:
(1) HashMap的扩容代价非常大,要生成一个新的桶数组,然后要把所有元素都重新Hash落桶一次,几乎等于重新执行了一次所有元素的put。所以如果我们对Map的大小有一个范围的话,可以在构造时给定大小,一般大小设置为:(int) ((float) expectedSize / 0.75F + 1.0F)。
(2) key的设计尽量简洁。
HashMap一些功能实现:
a.按值排序
HashMap按值排序通过Collections的sort方法,在实现排序之前,我们先看看HashMap的几种遍历方式:
//Collection And Map
public static void testCM(){
//Collection
Map<Integer , String> hs = new HashMap<Integer , String>();
int i = 0;
hs.put(199, "序号:"+201);
while(i<50){
hs.put(i, "序号:"+i);
i++;
}
hs.put(-1, "序号:"+200);
hs.put(200, "序号:"+200);
//遍历方式一:for each遍历HashMap的entryset,注意这种方式在定义的时候就必须写成
//Map<Integer , String> hs,不能写成Map hs;
for(Entry<Integer , String> entry : hs.entrySet()){
System.out.println("key:"+entry.getKey()+" value:"+entry.getValue());
}
//遍历方式二:使用EntrySet的Iterator
Iterator<Map.Entry<Integer , String>> iterator = hs.entrySet().iterator();
while(iterator.hasNext()){
Entry<Integer , String> entry = iterator.next();
System.out.println("key:"+entry.getKey()+" value:"+entry.getValue());
};
//遍历方式三:for each直接使用HashMap的keyset
for(Integer key : hs.keySet()){
System.out.println("key:"+key+" value:"+hs.get(key));
};
//遍历方式四:使用keyset的Iterator
Iterator keyIterator = hs.keySet().iterator();
while(keyIterator.hasNext()){
Integer key = (Integer)keyIterator.next();
System.out.println("key:"+key+" value:"+hs.get(key));
}
}(1)使用keyset的两种方式都会遍历两次,所以效率没有使用EntrySet高。
(2)HashMap输出是无序的,这个无序不是说每次遍历的结果顺序不一样,而是说与插入顺序不一样。
接下来我们看按值排序,注释比较详细就不赘述过程了。
//对HashMap排序
public static void sortHashMap(Map<Integer , String> hashmap){
System.out.println("排序后");
//第一步,用HashMap构造一个LinkedList
Set<Entry<Integer , String>> sets = hashmap.entrySet();
LinkedList<Entry<Integer , String>> linkedList = new LinkedList<Entry<Integer , String>>(sets);
//用Collections的sort方法排序
Collections.sort(linkedList , new Comparator<Entry<Integer , String>>(){
@Override
public int compare(Entry<Integer , String> o1, Entry<Integer , String> o2) {
// TODO Auto-generated method stub
/*String object1 = (String) o1.getValue();
String object2 = (String) o2.getValue();
return object1.compareTo(object2);*/
return o1.getValue().compareTo(o2.getValue());
}
});
//第三步,将排序后的list赋值给LinkedHashMap
Map<Integer , String> map = new LinkedHashMap();
for(Entry<Integer , String> entry : linkedList){
map.put(entry.getKey(), entry.getValue());
}
for(Entry<Integer , String> entry : map.entrySet()){
System.out.println("key:"+entry.getKey()+" value:"+entry.getValue());
}
}b.按键排序
HashMap按键排序要比按值排序方法容易实现,而且方法很多,下面一一介绍。
第一种:还是熟悉的配方还是熟悉的味道,用Collections的sort方法,只是更改一下比较规则。
第二种:TreeMap是按键排序的,默认升序,所以可以通过TreeMap来实现。
public static void sortHashMapByKey(Map hashmap){
System.out.println("按键排序后");
//第一步:先创建一个TreeMap实例,构造函数传入一个Comparator对象。
TreeMap<Integer , String> treemap = new TreeMap<Integer , String>(new Comparator<Integer>(){
@Override
public int compare(Integer o1,Integer o2) {
// TODO Auto-generated method stub
return Integer.compare(o1, o2);
}
});
//第二步:将要排序的HashMap添加到我们构造的TreeMap中。
treemap.putAll(hashmap);
for(Entry<Integer , String> entry : treemap.entrySet()){
System.out.println("key:"+entry.getKey()+" value:"+entry.getValue());
}
}第三种:可以通过keyset取出所有的key,然后将key排序,再有序的将key-value键值对存到LinkedHashMap中,这个就不贴代码了,有兴趣的可以自己去尝试一下。
c.value去重
对于HashMap而言,它的key是不能重复的,但是它的value是可以重复的,有的时候我们要将重复的部分剔除掉。
方法一:将HashMap的key-value对调,然后赋值给一个新的HashMap,由于key的不可重复性,此时就将重复值去掉了。最后将新得到的HashMap的key-value再对调一次即可。
d.HashMap线程同步
第一种:
Map<Integer , String> hs = new HashMap<Integer , String>();
hs = Collections.synchronizedMap(hs);第二种:
ConcurrentHashMap<Integer , String> hs = new ConcurrentHashMap<Integer , String>();(2)IdentifyHashMap
IdentityHashMap与HashMap基本相似,只是当两个key严格相等时,即key1==key2时,它才认为两个key是相等的 。IdentityHashMap也允许使用null,但不保证键值对之间的顺序。
(3)WeakHashMap
WeakHashMap与HashMap的用法基本相同,区别在于:后者的key保留对象的强引用,即只要HashMap对象不被销毁,其对象所有key所引用的对象不会被垃圾回收,HashMap也不会自动删除这些key所对应的键值对对象。但WeakHashMap的key所引用的对象没有被其他强引用变量所引用,则这些key所引用的对象可能被回收。WeakHashMap中的每个key对象保存了实际对象的弱引用,当回收了该key所对应的实际对象后,WeakHashMap会自动删除该key所对应的键值对。
接下来是Collection接口及其子类:
(4)ArrayList , LinkedList , Vector
(1)首先,说说它们的关系和区别。ArrayList和Vector本质都是用数组实现的,而LinkList是用双链表实现的;所以,Arraylist和Vector在查找效率上比较高,增删效率比较低;LinkedList则正好相反。ArrayList是线程不安全的,Vector是线程安全的,效率肯定没有ArrayList高了。实际中一般也不怎么用Vector,可以自己做线程同步,也可以用Collections配合ArrayList实现线程同步。
(2)Tips
前面多次提到扩容的代价很高,所以如果能确定容量的大致范围就可以在创建实例的时候指定,注意,这个仅限于ArrayList和Vector哟:
ArrayList arrayList = new ArrayList(100);
arrayList.ensureCapacity(200);
Vector vector = new Vector(100);
vector.ensureCapacity(200);(3)其他功能实现
a.排序
List的排序的话就是使用Collections的sort方法,构造Comparator或者让List中的对象实现Comparaable都可以,这里就不贴代码了。
b.去重
第一种:用Iterator遍历,遍历出来的放到一个临时List中,放之前用contains判断一下。
第二种:利用set的不可重复性,只需三步走。
//第一步:用HashSet的特性去重
HashSet tempSet = new HashSet(arrayList);
//第二步:将arrayList清除
tempSet.clear();
//第三步:将去重后的重新赋给List
arrayList.addAll(tempSet);(5)Stack
Stack呢,是继承自Vector的,所以用法啊,线程安全什么的跟Vector都差不多,只是有几个地方需要注意:
第一:add()和push(),stack是将最后一个element作为栈顶的,所以这两个方法对stack而言是没什么区别的,但是,它们的返回值不一样,add()返回boolean,就是添加成功了没有;push()返回的是你添加的元素。为了可读性以及将它跟栈有一丢丢联系,推荐使用push。
第二:peek()和pop(),这两个方法都能得到栈顶元素,区别是peek()只是读取,对原栈没有什么影响;pop(),从字面上就能理解,出栈,所以原栈的栈顶元素就没了。
(6)HashSet和TreeSet
Set集合类的特点就是可以去重,它们的内部实现都是基于Map的,用的是Map的key,所以知道为什么可以去重复了吧。
既然要去重,那么久需要比较,既然要比较,那么久需要了解怎么比较的,不然它将1等于2了,你怎么办?
比较是基于hascode()方法和equals()方法的,所以必要情况下需要重新这两个方法。
好了,到了总结的时候了,其实你会发现集合类虽然看起来多,但是都是很有规律的。ArrayList,LinkedList一个无序,一个有序;HashSet,TreeSet一个无序,一个有序;HashMap,LinkedHasmMap,一个无序,一个有序;Vector和HashTable,Stack是线程安全的,但是效率低;线程不安全的类都可以配合Collections得到线程安全的类。
Java集合类解析 ***的更多相关文章
- Java集合类源码解析:Vector
[学习笔记]转载 Java集合类源码解析:Vector 引言 之前的文章我们学习了一个集合类 ArrayList,今天讲它的一个兄弟 Vector.为什么说是它兄弟呢?因为从容器的构造来说,Vec ...
- Java集合类源码解析:ArrayList
目录 前言 源码解析 基本成员变量 添加元素 查询元素 修改元素 删除元素 为什么用 "transient" 修饰数组变量 总结 前言 今天学习一个Java集合类使用最多的类 Ar ...
- Java集合类源码解析:AbstractList
今天学习Java集合类中的一个抽象类,AbstractList. 初识AbstractList AbstractList 是一个抽象类,实现了List<E>接口,是隶属于Java集合框架中 ...
- Java集合类源码解析:AbstractMap
目录 引言 源码解析 抽象函数entrySet() 两个集合视图 操作方法 两个子类 参考: 引言 今天学习一个Java集合的一个抽象类 AbstractMap ,AbstractMap 是Map接口 ...
- Java容器解析系列(0) 开篇
最近刚好学习完成数据结构与算法相关内容: Data-Structures-and-Algorithm-Analysis 想结合Java中的容器类加深一下理解,因为之前对Java的容器类理解不是很深刻, ...
- Java泛型解析(01):认识泛型
Java泛型解析(01):认识泛型 What Java从1.0版本号到如今的8.中间Java5中发生了一个非常重要的变化,那就是泛型机制的引入.Java5引入了泛型,主要还是为了满足在199 ...
- 一篇搞定Java集合类原理
Java集合类实现原理 1.Iterable接口 定义了迭代集合的迭代方法 iterator() forEach() 对1.8的Lambda表达式提供了支持 2. Collection接口 定义了集合 ...
- Java集合类--温习笔记
最近面试发现自己的知识框架有好多问题.明明脑子里知道这个知识点,流程原理也都明白,可就是说不好,不知道是自己表达技能没点,还是确实是自己基础有问题.不管了,再巩固下基础知识总是没错的,反正最近空闲时间 ...
- 做JavaWeb开发不知Java集合类不如归家种地
Java作为面向对象语言对事物的体现都是以对象的形式,为了方便对多个对象的操作,就要对对象进行存储.但是使用数组存储对象方面具有一些弊端,而Java 集合就像一种容器,可以动态地把多个对象的引用放入容 ...
随机推荐
- 记一次C++编程引用obj文件作为静态库文件
简介 常用静态库文件的名字一般是 ***.lib ,例如 nisyscfg.lib 就是一个静态库文件,但是一个例程居然是引用 **.obj 文件作为静态库,有点非常规啊. 这是一个NI488.2 的 ...
- Swagger UI教程
文档源地址 http://www.68idc.cn/help/makewebs/qitaasks/20160621620667.html Swagger-UI本身只提供在线测试功能,要集成它还需要告诉 ...
- 阿里云ubuntu服务器安装使用mysql并配置远程连接记录
实践2要继续做实践1的项目 项目在本地使用本地数据库对于团队开发来说太麻烦了 所以改把项目放在服务器上使用服务器数据库 进入主题 0.参考:https://www.cnblogs.com/ywf520 ...
- 如何判断CPU、内存、磁盘的性能瓶颈?
1.如何判断CPU.内存.磁盘的瓶颈? CPU瓶颈1) 查看CPU利用率.建议CPU指标如下 a) User Time:65%-70% b) System Time:30%-35% c) Idle:0 ...
- oracle 互锁的sql查询
SELECT DECODE(request, 0, 'Holder: ', 'Waiter: ') || sid sess, id1, id2, lmode, ...
- hihoCoder#1054 滑动解锁
原题地址 回溯搜索 对于每个待枚举的点,检查: 1. 度数检查:是否违反了出度入度限制.因为生成的路径除了首尾节点外,其他节点的出度和入度只能为2 2. 共线检查:是否违反了共线条件.即跨越了尚未枚举 ...
- Bzoj3060 [Poi2012]Tour de Byteotia
3060: [Poi2012]Tour de Byteotia Time Limit: 30 Sec Memory Limit: 256 MBSubmit: 251 Solved: 161 Des ...
- IntelliJ IDEA在行尾增加分号
IntelliJ IDEA在行尾增加分号 Ctrl+Shift+Enter - 本身的含义是自动完成,如果需要的话,会在行尾添加分号:
- node安装-Win+Linux+Mac osx
node下载地址,除了Mac osx或Win平台,仅有Linux平台命令安装. Win.Mac 点击即可下载(注:Mac有dmg和pkg安装格式). Linux分为Redhot和Deepin系列,安装 ...
- Kinect驱动的人脸实时动画
近期几年.realtime的人脸动画開始风声水起.不少图形图像的研究者開始在这个领域不断的在顶级会议siggraph和期刊tog上面发文章. 随着kinect等便宜的三维数据採集设备的运用.以及其功能 ...