ssd训练自己的数据集
1.在ssd/caffe/data下创建VOC2007的目录,将ssd/caffe/data/VOC0712里的create_data.sh、create_list.sh和labelmap_voc.prototxt拷贝到VOC2007下,得如下图:

2.在/home/bnrc下创建data目录,在data目录下创建VOCdevkit2007目录,直接把VOC2007整个数据的文件夹放在VOCdevkit2007目录下,结构如图:

VOC2007文件夹所包含的目录:

3.在ssd/caffe/examples目录下,创建VOC2007文件夹,这个文件夹之后要存储生成的lmdb数据
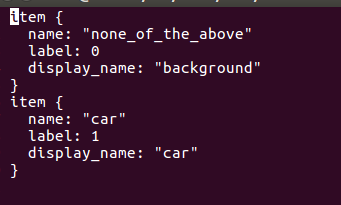
4.修改labelmap_voc.prototxt成你自己的格式:
运行create_list.sh:./create_list.sh,报以下错误:

因为我的data目录下是VOCdevkit2007,所以需要修改create_list.sh中的root_dir=$HOME/data/VOCdevkit/为root_dir=$HOME/data/VOCdevkit2007/
修改之后依旧报以下错:

这是因为/data/VOCdevkit2007下只有VOC2007,没有2012,所以需要把for name in VOC2007 VOC2012中的VOC2012删除
修改之后报以下错误:

这是还没有编译ssd这个目录的原因
之后再运行create_data.sh :./create_data.sh,报以下错误:

需要将create_data.sh中的data_root_dir="$HOME/data/VOCdevkit"改为data_root_dir="$HOME/data/VOCdevkit2007",将dataset_name="VOC0712"改为dataset_name="VOC2007"
再运行报以下错误:

用export PYTHONPATH=/home/bnrc/ssd/caffe/python修改PYTHONPATH
修改之后又报错:
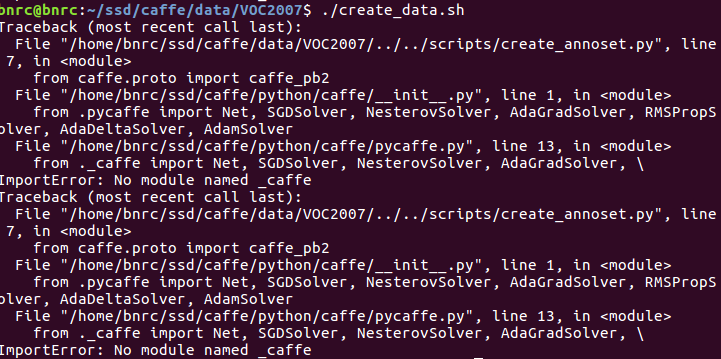
这是因为我之前只在ssd/caffe进行make,没有make pycaffe
make pycaffe的显示:

可以看到,生成了_caffe
再运行就能正确在./examples/VOC2007下生成lmdb数据了
5.修改ssd_pascal.py代码:

自己的是VOC2007

model_name修改为VOC2007
save_dir修改为VOC2007
snapshot_dir修改为VOC2007
job_dir修改为VOC2007
output_result_dir在/data前加/home/bnrc
name_size_file修改为VOC2007
label_map_file修改为VOC2007
num_classes修改为2

gpu可以根据需要选择

6.训练数据:python ./examples/ssd/ssd_pascal.py
ssd训练自己的数据集的更多相关文章
- SSD框架训练自己的数据集
SSD demo中详细介绍了如何在VOC数据集上使用SSD进行物体检测的训练和验证.本文介绍如何使用SSD实现对自己数据集的训练和验证过程,内容包括: 1 数据集的标注2 数据集的转换3 使用SSD如 ...
- 目标检测算法SSD之训练自己的数据集
目标检测算法SSD之训练自己的数据集 prerequesties 预备知识/前提条件 下载和配置了最新SSD代码 git clone https://github.com/weiliu89/caffe ...
- 目标检测算法SSD在window环境下GPU配置训练自己的数据集
由于最近想试一下牛掰的目标检测算法SSD.于是乎,自己做了几千张数据(实际只有几百张,利用数据扩充算法比如镜像,噪声,切割,旋转等扩充到了几千张,其实还是很不够).于是在网上找了相关的介绍,自己处理数 ...
- 【Tensorflow系列】使用Inception_resnet_v2训练自己的数据集并用Tensorboard监控
[写在前面] 用Tensorflow(TF)已实现好的卷积神经网络(CNN)模型来训练自己的数据集,验证目前较成熟模型在不同数据集上的准确度,如Inception_V3, VGG16,Inceptio ...
- 可变卷积Deforable ConvNet 迁移训练自己的数据集 MXNet框架 GPU版
[引言] 最近在用可变卷积的rfcn 模型迁移训练自己的数据集, MSRA官方使用的MXNet框架 环境搭建及配置:http://www.cnblogs.com/andre-ma/p/8867031. ...
- caffe训练自己的数据集
默认caffe已经编译好了,并且编译好了pycaffe 1 数据准备 首先准备训练和测试数据集,这里准备两类数据,分别放在文件夹0和文件夹1中(之所以使用0和1命名数据类别,是因为方便标注数据类别,直 ...
- 使用yolo3模型训练自己的数据集
使用yolo3模型训练自己的数据集 本项目地址:https://github.com/Cw-zero/Retrain-yolo3 一.运行环境 1. Ubuntu16.04. 2. TensorFlo ...
- Win10中用yolov3训练自己的数据集全过程(VS、CUDA、CUDNN、OpenCV配置,训练和测试)
在Windows系统的Linux系统中用yolo训练自己的数据集的配置差异很大,今天总结在win10中配置yolo并进行训练和测试的全过程. 提纲: 1.下载适用于Windows的darknet 2. ...
- TensorFlow学习笔记——LeNet-5(训练自己的数据集)
在之前的TensorFlow学习笔记——图像识别与卷积神经网络(链接:请点击我)中了解了一下经典的卷积神经网络模型LeNet模型.那其实之前学习了别人的代码实现了LeNet网络对MNIST数据集的训练 ...
随机推荐
- 洛谷 P2444 [ POI 2000 ] 病毒 —— AC自动机+dfs
题目:https://www.luogu.org/problemnew/show/P2444 AC自动机上 dfs,不走结尾点,如果走出环就是有无限长度的串: RE无数,原来是数组开成 2000 的了 ...
- bzoj1046 [HAOI2007]上升序列——LIS
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=1046 倒序求最长下降子序列,则得到了每个点开始的最长上升子序列: 然后贪心输出即可. 代码如 ...
- 2-18 matplotlib模块的使用
import numpy as np import matplotlib.pyplot as plt x = np.array([1,2,3,4,5,6,7,8]) y = np.array([3,5 ...
- Redis学习记录
参考资料: http://www.dengshenyu.com/%E5%90%8E%E7%AB%AF%E6%8A%80%E6%9C%AF/2016/01/09/redis-reactor-patter ...
- UVa 12717 Fiasco (BFS模拟)
题意:给定一个错误代码,让你修改数据,使得它能够输出正确答案,错误代码是每次取最短的放入. 析:那么我们就可以模拟这个过程,然后修改每条边的权值,使得它能输出正确答案. 代码如下: #pragma c ...
- linux更改用户名,域名(转载)
转自:http://huangro.iteye.com/blog/365975 1. 我们在root权限下,使用命令: usermod -l new_user_name old_user_name 即 ...
- phpStudy安装配置小记
一.phpStudy简介 该程序包集成最新的Apache+PHP+MySQL+phpMyAdmin+ZendOptimizer,一次性安装,无须配置即可使用,是非常方便.好用的PHP调试环境·该程序不 ...
- bzoj 3470: Freda’s Walk【拓扑排序+期望dp】
dfs会T,只好正反两遍拓扑了-- #include<iostream> #include<cstdio> #include<queue> #include< ...
- 【爬坑系列】之vxlan网络实现
linux 内核从3.7之后就内部集成了vxlan功能,所以可以使用linux内核提供的vxlan功能,经过配置创建vxlan网络. 而从Docker自Docker Engine 1.9之后,就自带o ...
- B - Burning Midnight Oil CodeForces - 165B
One day a highly important task was commissioned to Vasya — writing a program in a night. The progra ...