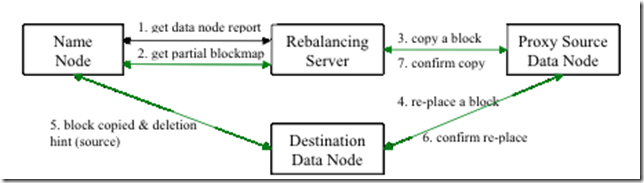
hadoop 中balance 机制
hadoop 中balance 机制的更多相关文章
- hbase中balance机制
HBase是一种支持自动负载均衡的分布式KV数据库,在开启balance的开关(balance_switch)后,HBase的HMaster进程会自动根据指定策略挑选出一些Region,并将这些Reg ...
- 3 weekend110的hadoop中的RPC框架实现机制 + hadoop中的RPC应用实例demo
hadoop中的RPC框架实现机制 RPC是Remotr Process Call, 进程间的远程过程调用,不是在一个jvm里. 即,Controller拿不到Service的实例对象. hadoop ...
- 1 weekend110的复习 + hadoop中的序列化机制 + 流量求和mr程序开发
以上是,weekend110的yarn的job提交流程源码分析的复习总结 下面呢,来讲weekend110的hadoop中的序列化机制 1363157985066 13726230503 ...
- HADOOP高可用机制
HADOOP高可用机制 HA运作机制 什么是HA HADOOP如何实现HA HDFS-HA详解 HA集群搭建 目标: 掌握分布式系统中HA机制的思想 掌握HADOOP内置HA的运作机制 掌握HADOO ...
- Hadoop中客户端和服务器端的方法调用过程
1.Java动态代理实例 Java 动态代理一个简单的demo:(用以对比Hadoop中的动态代理) Hello接口: public interface Hello { void sayHello(S ...
- MapReduce中作业调度机制
MapReduce中作业调度机制主要有3种: 1.先入先出FIFO Hadoop 中默认的调度器,它先按照作业的优先级高低,再按照到达时间的先后选择被执行的作业. 2.公平调度器(相当于时间 ...
- Hadoop 中疑问解析
Hadoop 中疑问解析 FAQ问题剖析 一.HDFS 文件备份与数据安全性分析1 HDFS 原理分析1.1 Hdfs master/slave模型 hdfs采用的是master/slave模型,一个 ...
- hadoop 错误处理机制
hadoop 错误处理机制 1.硬件故障 硬件故障是指jobtracker故障或TaskTracker 故障 jobtracker是单点,若发生故障,目前hadoop 还无法处理,唯有选择最牢靠的硬件 ...
- Hadoop 中 IPC 的源码分析
最近开始看 Hadoop 的一些源码,展开hadoop的源码包,各个组件分得比较清楚,于是开始看一下 IPC 的一些源码. IPC模块,也就是进程间通信模块,如果是在不同的机器上,那就可以理解为 RP ...
随机推荐
- macOS:按钮类型
for (int i = 0; i < 10; i++) { for (int j = 1; j < 16; j++) { NSButton *btn = [[NSButton alloc ...
- linux学习笔记三:防火墙设置
请注意:centOS7和7之前的版本在防火墙设置上不同,只有正确的设置防火墙才能实现window下访问linux中的web应用. centOS6添加端口: vi /ets/sysconfig/ipta ...
- Windows搭建SFTP服务器
1.项目需要搭建一个SFTP服务器,网上搜了一下,用的是freeSSHd软件,网上查一下我用的是1.3.1版本https://freesshd.updatestar.com/网址自己下载即可. 2.安 ...
- windows系统,MongoDB开启用户验证登录的正确姿势
MongoDB默认安装并没有开启用户名密码登录,这样太不安全了,百度出来的开启验证登录的文章,对初次使用MongoDB的小白太不友好了,总结下经验,自己写一份指引. 1,我的安装路径是C:\Progr ...
- 使用Hexo + GitHub Pages 搭建个人博客
一.前言 之前是在CSDN上写博客的,但是无奈其广告满天飞,还有因为个人不太喜欢CSDN博客里的一些东西,加上看到很多技术大牛都有自己的个人博客,于是乎!便想着搭建一个自己的个人博客.其实之前写博客还 ...
- 树莓派3B+学习笔记:4、查看GPIO
GPIO(General Purpose I/O Ports)意思为通用输入/输出端口. 可以在终端重直接查看GPIO的定义. 查看方式1: gpio readall 查看方式2: pinout 可以 ...
- HTML学习笔记--元素
1. 开始标签称为起始标签,结束标签称为闭合标签 openging tag closing tag HTML 元素以开始标签起始 HTML 元素以结束标签终止 元素的内容是开始标签与结束标签之间的内容 ...
- vue相关理论知识
es6常用语法简介 es是js的规范标准 let 特点: 1.有全局和函数作用域,以及块级作用域(用{}表示块级作用域范围) 2.不会存在变量提升 3.变量不能重复声明 const 特点: 1.有块级 ...
- ruby Rspec+jenkins+allure持续集成
1.Allure2使用说明 2.ruby下载allure的gem gem install allure-rspec 3.修改源码 C:\Ruby23-x64\lib\ruby\gems\2.3.0\g ...
- A1033
找出最小开销. 思路: 出发点的加油站编号设为0,终点的加油站编号设为n,其他加油站编号按距离依次排序. 如果0号加油站的距离!=0,则无法出发,行驶距离为0. 从起点开始,寻找规则为,如果存在油价小 ...