Spark之编程模型RDD
前言:Spark编程模型两个主要抽象,一个是弹性分布式数据集RDD,它是一种特殊集合,支持多种数据源,可支持并行计算,可缓存;另一个是两种共享变量,支持并行计算的广播变量和累加器。
1.RDD介绍
Spark大数据处理平台建立在RDD之上,RDD是Spark的核心概念,最主要的抽象之一。RDD和Spark之间的关系是,RDD是一种基于内存的具有容错性的集群抽象方法,Spark是这个抽象方法的实现。
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
1.1 RDD的特征
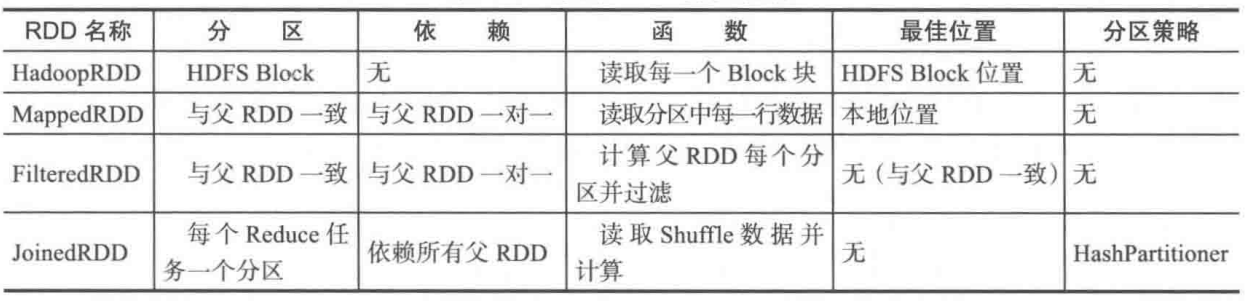
(1)分区(Partition):一个数据分片列表。能够将数据切分,切分好的数据能够进行并行计算,是数据集的原子组成部分。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
(2)函数(Compute):一个计算RDD每个分片的函数。RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
(3)依赖(Dependency):RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
(4)优先位置(可选):一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
(5)分区策略(可选):一个Partitioner,即RDD的分片函数,描述分区的模式和数据存放的位置。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
常见的RDD有很多种,每个Transformation操作都会产生一种RDD,一下是各种RDD特征比较。
1.2 RDD依赖
Spark之编程模型RDD的更多相关文章
- Spark核心编程---创建RDD
创建RDD: 1:使用程序中的集合创建RDD,主要用于进行测试,可以在实际部署到集群运行之前,自己使用集合构造测试数据,来测试后面的spark应用流程. 2:使用本地文件创建RDD,主要用于临时性地处 ...
- spark wordcount 编程模型详解
spark wordcount中一共经历多少个RDD?以及RDD提供的toDebugString 在控制台输入spark-shell 系统会默认创建一个SparkContext sc h ...
- Spark 编程模型(上)
Spark的编程模型 核心概念(注意对比MR里的概念来学习) Spark Application的组成 Spark Application基本概念 Spark Application编程模型 回顾sc ...
- Spark编程模型(博主推荐)
福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 Java全栈大联盟 ...
- Spark1.0.0 编程模型
Spark Application能够在集群中并行执行,其关键是抽象出RDD的概念(详见RDD 细解),也使得Spark Application的开发变得简单明了.下图浓缩了Spark的编程模型. w ...
- Spark编程模型(RDD编程模型)
Spark编程模型(RDD编程模型) 下图给出了rdd 编程模型,并将下例中用 到的四个算子映射到四种算子类型.spark 程序工作在两个空间中:spark rdd空间和 scala原生数据空间.在原 ...
- Spark入门实战系列--3.Spark编程模型(上)--编程模型及SparkShell实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spar ...
- Spark中文指南(入门篇)-Spark编程模型(一)
前言 本章将对Spark做一个简单的介绍,更多教程请参考:Spark教程 本章知识点概括 Apache Spark简介 Spark的四种运行模式 Spark基于Standlone的运行流程 Spark ...
- Spark:Spark 编程模型及快速入门
http://blog.csdn.net/pipisorry/article/details/52366356 Spark编程模型 SparkContext类和SparkConf类 代码中初始化 我们 ...
随机推荐
- Maven创建Web项目、、、整合SSM框架
自己接触ssm框架有一段时间了,从最早的接触新版ITOO项目的(SSM/H+Dobbu zk),再到自己近期来学习到的<淘淘商城>一个ssm框架的电商项目.用过,但是还真的没有自己搭建过, ...
- CCF认证201803-2 碰撞的小球 java代码实现。
问题描述 数轴上有一条长度为L(L为偶数)的线段,左端点在原点,右端点在坐标L处.有n个不计体积的小球在线段上,开始时所有的小球都处在偶数坐标上,速度方向向右,速度大小为1单位长度每秒. 当小球到达线 ...
- iOS 推送功能打包后获取不到deviceToken
公司项目用ionic3构建, 用了极光推送插件(cordova-plugin-jpush). 开发时一切将各种Bundle Id, 推送证书等都绑定完测试一切正常. 可是要给测试人员打Ad-Hoc包时 ...
- ztz11的noip模拟赛T2:查房
链接: https://www.luogu.org/problemnew/show/U46611 思路: 这道题告你n-1条边就是骗你的 部分分也是骗你的 这道题连对边5分钟的事 一个点对另一个点有影 ...
- mysql事件关闭解决办法
Mysql 事件event_scheduler是OFF 开启 Event Scheduler,以下4种方式等效 SET GLOBAL event_scheduler = ON; SET @@globa ...
- CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- PTA(BasicLevel)-1007素数对猜想
一 问题描述-素数对 让我们定义素数差dn为:dn=pn+1−pn,其中pi是第i个素数.显然有d1=1,且对于n>1有dn是偶数.“素数对猜想”认为“ ...
- golang基础--Interface接口
接口是一个或多个方法签名名的集合,定义方式如下 type Interface_Name interface { method_a() string method_b() int .... } 只要某个 ...
- 20155215 2006-2007-2 《Java程序设计》第2周学习总结
20155215 2006-2007-2 <Java程序设计>第2周学习总结 教材学习内容总结 第三章主要讲述了JAVA程序编写中的一些基本语法.其实看了第三章之后我就感觉到,C语言不愧是 ...
- 20155320 《Java程序设计》实验三 敏捷开发与XP实践
20155320 <Java程序设计>实验三 敏捷开发与XP实践 实验内容 XP基础 XP核心实践 相关工具 (一)研究一下Code菜单 具体内容: 在IDEA中使用工具(Code-> ...