Slf4j打印异常的堆栈信息
一、前言
直接用logger.info("异常信息为:"+e)或者logger.info(e.getMessage())只能记录到异常的描述信息,却没有其异常具体发生在哪一行代码。
这样即使通过日志发现出现了异常,也没法马上定位问题。
因此就催生了一个想法,打印日志是否能像在IDE本地跑程序时出现未捕获的异常时,控制台能打印出完整的错误堆栈信息。
二、问题场景
日常开发中,经常在service实现层使用try-catch-finally保证代码的健壮性, 直接用logger.info("异常信息为:"+e)或者logger.info(e.getMessage())只能记录到异常的描述信息,无法打印完整异常堆栈信息,无法定位其异常具体发生在哪一行代码,当面对比较复杂的代码,那么排查问题将会非常麻烦。
下文将简单重现这类场景,并得到相应的解决方法。
1、不加try-catch
示例:
@GetMapping("/hello")
public String sayHello(){
logger.info("hello Sfl4j + logback......");
int i = 3/0;
return helloService.sayHello();
}
运行结果:
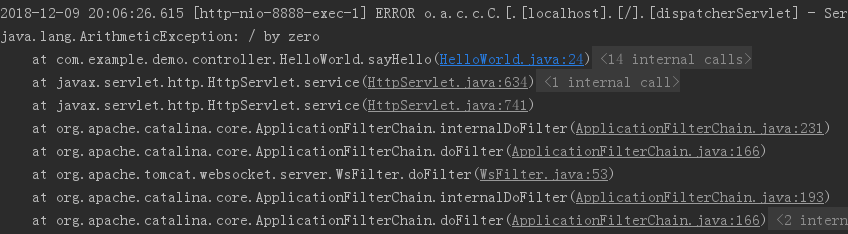
即:当不加try-catch的时候,当出现了意料之外的运行时异常,控制台是能够能打印出完整的错误信息。
2、加上try-catch
示例:
@GetMapping("/hello")
public String sayHello(){
logger.info("hello Sfl4j + logback......");
try{
int i = 3/0;
}catch (Exception e){
logger.info("计算出错1:"+e);
logger.info("计算出错2:"+e.getMessage());
}
return helloService.sayHello();
}
运行结果:

即:try-catch代码中使用logger.info("异常信息为:"+e)或者logger.info(e.getMessage()),只能打印异常描述信息,无法打印异常堆栈,无法定位具体出错位置。
三、解决方法
--->打印出完整的异常堆栈信息方法
方法1:e.printStackTrace();
示例:
@GetMapping("/hello")
public String sayHello(){
logger.info("hello Sfl4j + logback......");
try{
int i = 3/0;
}catch (Exception e){
e.printStackTrace();
}
return helloService.sayHello();
}
运行结果:
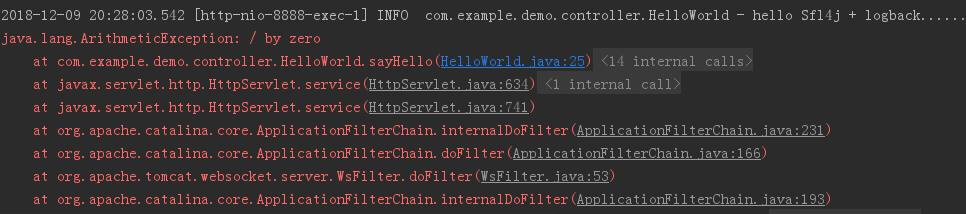
注:
这种方式很占内存空间,尤其生产环境不能过多使用。
并且这种方式只是控制台打印,日志文件中不打印。
方法2:
logger.error(String msg, Throwable t);------>logger.error(e.getMessage(),e);
或者
logger.info(String msg, Throwable t);------>logger.info(e.getMessage(),e);
示例:
@GetMapping("/hello")
public String sayHello(){
logger.info("hello Sfl4j + logback......");
try{
int i = 3/0;
}catch (Exception e){
logger.error(e.getMessage(),e);
// logger.info(e.getMessage(),e);
}
return helloService.sayHello();
}
运行结果:
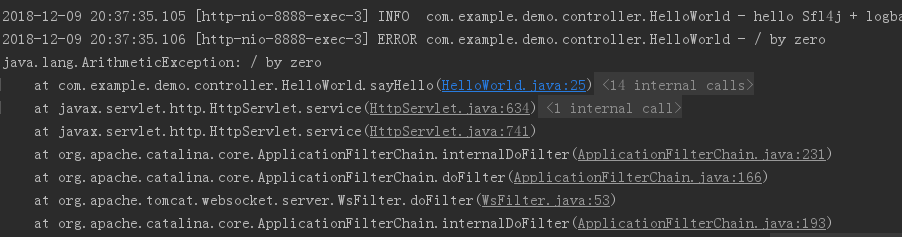
使用扩展:
如果msg含有变量,SLF4J 1.6.0之前版本一般用String.format方法格式化msg。
SLF4J 1.6.0版本之后,
error(String format, Object... arguments)
info(String format, Object... arguments)
方法也会打印异常堆栈信息,只不过规定Throwable对象必须为最后一个参数.如果不遵守这个规定,异常堆栈信息不会打印出来。
官网示例:
String s = "Hello world";
try {
Integer i = Integer.valueOf(s);
} catch (NumberFormatException e) {
logger.error("Failed to format {}", s, e);
}
使用示例:
@GetMapping("/hello")
public String sayHello(){
logger.info("hello Sfl4j + logback......");
try{
int i=3/0;
}catch(Exception e){
logger.error("错误消息:{}",e.getMessage(),e);
}
return helloService.sayHello();
}
}
运行示例:
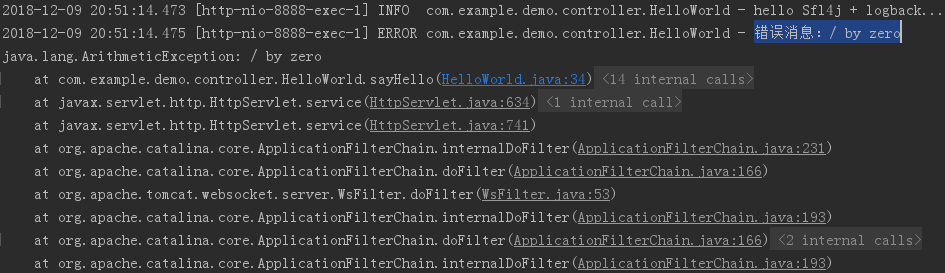
小结:
1、Slf4j打印异常堆栈信息使用:
logger.error(String msg, Throwable t);------>logger.error(e.getMessage(),e);
或者
logger.info(String msg, Throwable t);------>logger.info(e.getMessage(),e);
规范示例:
logger.error("错误消息:{}",e.getMessage(),e);
2、异常信息Exception e 的相关方法
- e.toString():获得异常类型和错误信息描述
- e.getMessage():获得错误信息描述
- e.printStackTrace():在控制台打印出异常堆栈(异常类型、错误信息描述和出错位置等)。
Slf4j打印异常的堆栈信息的更多相关文章
- JAVA将异常的堆栈信息转成String
有时候我们需要将系统出现异常的堆栈信息显示到异常页面的一个隐藏的DIV内,这样查看源时就可以快速的定位到异常信息.这个时候就要将异常信息转成String. /* * 将异常的堆栈信息转成String ...
- Java异常---获取异常的堆栈信息
Java 实例 - 获取异常的堆栈信息 Java 实例 以下实例演示了使用异常类的 printStack() 方法来获取堆栈信息: Main.java 文件 public class Main{ p ...
- Java如何打印异常的堆栈?
在Java编程中,如何打印异常的堆栈? 此示例显示如何使用异常类的printStack()方法打印异常的堆栈. package com.yiibai; public class PrintStackT ...
- 利用Xposed Hook打印Java函数调用堆栈信息的几种方法
本文博客链接:http://blog.csdn.net/QQ1084283172/article/details/79378374 在进行Android逆向分析的时候,经常需要进行动态调试栈回溯,查看 ...
- 在java中捕获异常时,使用log4j打印出错误堆栈信息
当java捕获到异常时,把详细的堆栈信息打印出来有助于我们排查异常原因,并修复相关bug,比如下面两张图,是打印未打印堆栈信息和打印堆栈信息的对比: 那么在使用log4j输出日志时,使用org.apa ...
- 使用linux backtrace打印出错函数堆栈信息
一般察看函数运行时堆栈的方法是使用GDB(bt命令)之类的外部调试器,但是,有些时候为了分析程序的BUG,(主要针对长时间运行程序的分析),在程序出错时打印出函数的调用堆栈是非常有用的. 在glibc ...
- Logger.error方法之打印错误异常的详细堆栈信息
一.问题场景 使用Logger.error方法时只能打印出异常类型,无法打印出详细的堆栈信息,使得定位问题变得困难和不方便. 二.先放出结论 Logger类下有多个不同的error方法,根据传入参数的 ...
- 打印Java异常堆栈信息
背景 在开发Java应用程序的时候,遇到程序抛异常,我们通常会把抛异常时的运行时环境保存下来(写到日志文件或者在控制台中打印出来).这样方便后续定位问题. 需要记录的运行时环境包含两部分内容:抛异常时 ...
- log4j打印错误异常的详细堆栈信息
一.问题场景 使用Logger.error方法时只能打印出异常类型,无法打印出详细的堆栈信息,使得定位问题变得困难和不方便. 二.先放出结论 Logger类下有多个不同的error方法,根据传入参数的 ...
随机推荐
- noip | 题目 | noip数据 收集站 | noipdata
这是什么 一个NOIP历年比赛数据及题目的收集站,方便大家查找使用 网站链接:https://noipdata.github.io 点击这里立即跳转 新连接:noipdata.rcxzsc.com 点 ...
- LINQ to Entities does not recognize the method , and this method cannot be translated into a store expression 解决办法
根据用户输入的起始日期,查询以起始日期开始的前20条记录,在ASP.NET MVC的Controller代码中这样写: var Logs = db.Log.Take(20); if (!string. ...
- SpringBoot项目中加入jsp页面
根据我们之前搭建好的SpringBoot+SSm的项目的基础上,来增加webapp/WEB-INF的文件,由此来完成jsp页面的跳转. 先增加jsp的pom依赖: <!-- https://mv ...
- dip,px,sp区别及使用场景
1.区别 dip(device independent pixels)——设备独立像素:这个和设备硬件有关,一般哦我们为了支持WCGA.HVGA和QVGA推荐使用这个,不依赖于像素.等同于dp. px ...
- 《Algorithms算法》笔记:元素排序(4)——凸包问题
<Algorithms算法>笔记:元素排序(4)——凸包问题 Algorithms算法笔记元素排序4凸包问题 凸包问题 凸包问题的应用 凸包的几何性质 Graham 扫描算法 代码 凸包问 ...
- CentOS 6.4下安装JIRA6.3.6破解汉化
JIRA产品非常完善且功能强大,安装配置简单,多语言支持.界面十分友好,和其他系统如CVS.Subversion(SVN).VSS.LDAP.邮件服务整合得相当好,文档齐全,可用性以及可扩展性方面都十 ...
- Linux 命令学习之cd
功能说明: cd 命令是 linux 最基本的命令语句,其他的命令都会依赖与 cd 命令.因此学好 cd 命令是必须的. 语 法:cd [目的目录] 补充说明:cd指令可让用户在不同的目录间切换,需要 ...
- shell -- sample -- 关闭tomcat
#!/bin/bash process_name="org.apache.catalina.startup.Bootstrap" shutdown_call= function s ...
- HDU 2193 AVL Tree
AVL Tree An AVL tree is a kind of balanced binary search tree. Named after their inventors, Adelson- ...
- 基础爬虫,谁学谁会,用requests、正则表达式爬取豆瓣Top250电影数据!
爬取豆瓣Top250电影的评分.海报.影评等数据! 本项目是爬虫中最基础的,最简单的一例: 后面会有利用爬虫框架来完成更高级.自动化的爬虫程序. 此项目过程是运用requests请求库来获取h ...