Hadoop & Spark & Hive & HBase
Hadoop:http://hadoop.apache.org/docs/r2.6.4/hadoop-project-dist/hadoop-common/SingleCluster.html
bin/hdfs namenode -formatsbin/start-dfs.sh
bin/hdfs dfs -mkdir /userbin/hdfs dfs -mkdir /user/<username>these are for testing:
bin/hdfs dfs -put etc/hadoop inputbin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar grep input output 'dfs[a-z.]+'bin/hdfs dfs -cat output/*testing results:
6 dfs.audit.logger4 dfs.class3 dfs.server.namenode.2 dfs.period2 dfs.audit.log.maxfilesize2 dfs.audit.log.maxbackupindex1 dfsmetrics.log1 dfsadmin1 dfs.servers1 dfs.replication1 dfs.fileHistoryServer
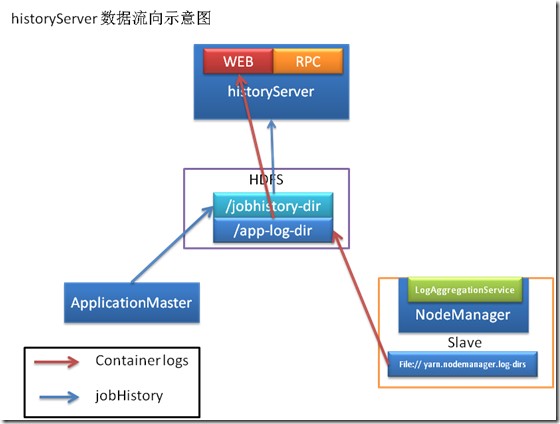
./sbin/mr-jobhistory-daemon.sh start historyserverSpark:start:
./sbin/start-slaves.sh spark://<your-computer-name>:7077You will see:
- Alive Workers: 1
This is for testing:
./bin/spark-shell --master spark://<your-computer-name>:7077You will see the scala shell.use :q to quit.
To see the history:
http://spark.apache.org/docs/latest/monitoring.html
http://blog.chinaunix.net/uid-29454152-id-5641909.html
http://www.cloudera.com/documentation/cdh/5-1-x/CDH5-Installation-Guide/cdh5ig_spark_configure.html
./sbin/start-history-server.sh
jdbc:mysql://localhost:3306/hivedb?useSSL=false&createDatabaseIfNotExist=true
nohup hiveserver2 &
User: is not allowed to impersonate anonymous (state=,code=0)
HWI WAR file not found at
Problem: failed to create task or type componentdef- Or:
./bin/start-hbase.sh
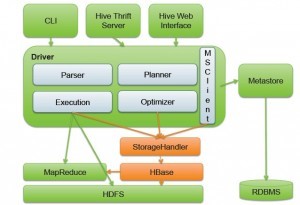
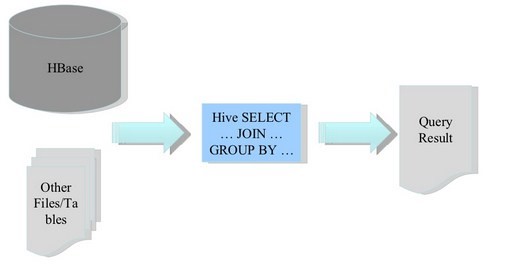
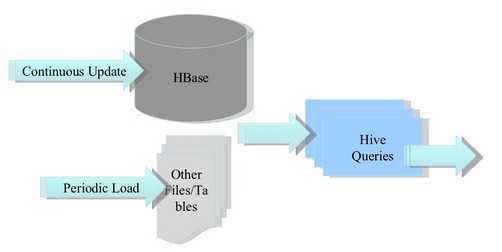
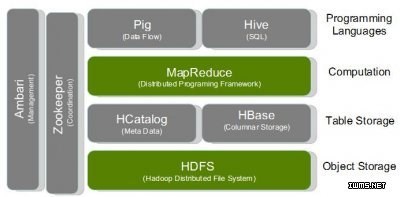
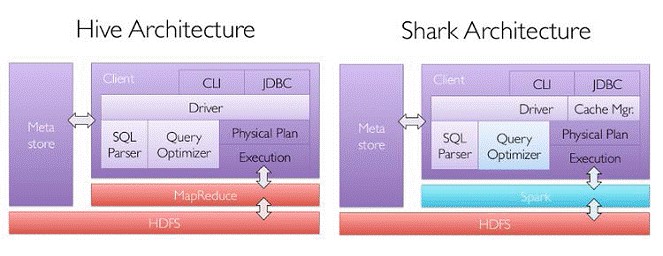
Hive & Shark & SparkSQL

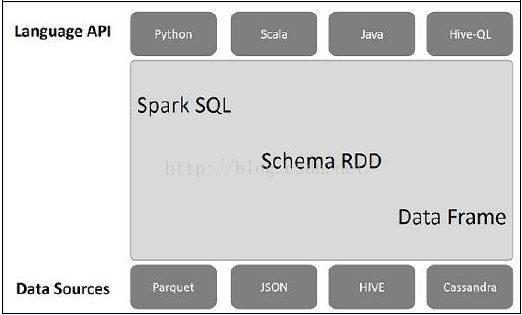
Spark SQL架构如下图所示:
http://blog.csdn.net/wzy0623/article/details/52249187

- queryserver.py start
- jdbc:phoenix:thin:url=http://localhost:8765;serialization=PROTOBUF
phoenix-sqlline.py localhost:2181
Hadoop & Spark & Hive & HBase的更多相关文章
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- HADOOP+SPARK+ZOOKEEPER+HBASE+HIVE集群搭建(转)
原文地址:https://www.cnblogs.com/hanzhi/articles/8794984.html 目录 引言 目录 一环境选择 1集群机器安装图 2配置说明 3下载地址 二集群的相关 ...
- hadoop之hive&hbase互操作
大家都知道,hive的SQL操作非常方便,但是查询过程中需要启动MapReduce,无法做到实时响应. hbase是hadoop家族中的分布式数据库,与传统关系数据库不同,它底层采用列存储格式,扩展性 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- Hadoop + Hive + HBase + Kylin伪分布式安装
问题导读 1. Centos7如何安装配置? 2. linux网络配置如何进行? 3. linux环境下java 如何安装? 4. linux环境下SSH免密码登录如何配置? 5. linux环境下H ...
- 【原创】大叔问题定位分享(16)spark写数据到hive外部表报错ClassCastException: org.apache.hadoop.hive.hbase.HiveHBaseTableOutputFormat cannot be cast to org.apache.hadoop.hive.ql.io.HiveOutputFormat
spark 2.1.1 spark在写数据到hive外部表(底层数据在hbase中)时会报错 Caused by: java.lang.ClassCastException: org.apache.h ...
- Docker搭建大数据集群 Hadoop Spark HBase Hive Zookeeper Scala
Docker搭建大数据集群 给出一个完全分布式hadoop+spark集群搭建完整文档,从环境准备(包括机器名,ip映射步骤,ssh免密,Java等)开始,包括zookeeper,hadoop,hiv ...
- 大数据技术生态圈形象比喻(Hadoop、Hive、Spark 关系)
[摘要] 知乎上一篇很不错的科普文章,介绍大数据技术生态圈(Hadoop.Hive.Spark )的关系. 链接地址:https://www.zhihu.com/question/27974418 [ ...
- spark读取hbase形成RDD,存入hive或者spark_sql分析
object SaprkReadHbase { var total:Int = 0 def main(args: Array[String]) { val spark = SparkSession . ...
随机推荐
- css左右布局,左侧固定,右侧自适应
实现布局的几种方法,见代码: <!DOCTYPE html> <html lang="cn"> <head> <meta charset= ...
- 基于Allwinner的Audio子系统分析(Android-5.1)
前言 一直想总结下Audio子系统的博客,但是各种原因(主要还是自己懒>_<),一直拖到现在才开始重新整理,期间看过H8(Android-4.4),T3(Android-4.4),A64( ...
- (转)OpenStack —— 原理架构介绍(一、二)
原文:http://blog.51cto.com/wzlinux/1961337 http://blog.51cto.com/wzlinux/category18.html-------------O ...
- java常量类的实现方式_枚举类_项目实践
前言 众所周知,系统里有很多比如订单状态.审核状态:性别.结算方式.交易类型等属性,这些属性只有几个值,一般用0.1.2.3等的数字标识存入数据库,每次对这些属性所属对象的增删改操作,都会在代码里给状 ...
- Jquery动画操作的stop()函数
今天做一个点击动画时,遇到了当快速连续点击时,动画效果会乱,并不是我们想要达到的效果. 查询了一下,确认是动画累积的原因.网上搜了一下,发现jquery 的stop()函数刚好能解决. stop(cl ...
- Chrome DevTools的15个使用技巧(译)
谷歌浏览器如今是Web开发者们所使用的最流行的网页浏览器.伴随每六个星期一次的发布周期和不断扩大的强大的开发功能,Chrome变成了一个必须掌握的工具.大多数前端开发者可能熟悉关于chorme的许多特 ...
- mix使用本地依赖
在看elixir程序设计,书中讲到依赖设置,但是都是要联网,自己希望可以下载到本地电脑硬盘,然后项目要使用就用本地的,不要每次都要下载,因为天朝下载真的不稳 官方看到文档 {:deps_name,pa ...
- 用Ajax爬取今日头条图片集
Ajax原理 在用requests抓取页面时,得到的结果可能和浏览器中看到的不一样:在浏览器中可以正常显示的页面数据,但用requests得到的结果并没有.这是因为requests获取的都是原始 ...
- SQL Server中的小技巧(重复、替换、截取、去空格、去小数点后的位数)
PS:随笔写的在SQL Server中要用到的 (重复.替换.截取.去空格.去小数点后的位数) /*---------------------------重复--------------------- ...
- Docker学习(五): 仓库与数据管理
特别声明: 博文主要是学习过程中的知识整理,以便之后的查阅回顾.部分内容来源于网络(如有摘录未标注请指出).内容如有差错,也欢迎指正! =============系列文章============= 1 ...