ros下基于百度语音的,语音识别和语音合成
概述:
本demo是ros下基于百度语音的,语音识别和语音合成,能够实现文字转语音,语音转文字的功能。
详细:
1. 安装库与环境
首先确保已经安装了以下两个库文件。
1.1 Python 音频处理库 PyAudio
python -m pip install pyaudio
1.2 Python 音频处理库 vlc
pip install python-vlc
1.3 ROS
确保安装了ROS
http://wiki.ros.org/indigo
2. 实时语音识别与语音合成
2.1 运行
Speech Recognition(语音识别):
roslaunch simple_voice simple_voice.launch
Text To Speech(语音合成):
roslaunch simple_voice simple_speaker.launch
2.2 概述
在运行前先确保安装了python的pyaudio 以及 vlc 库文件.
百度语音识别为开发者提供业界优质且免费的语音服务,通过场景识别优化,,准确率达到90%以上,让您的应用绘“声”绘色。
本文中的语音识别功能:采用百度语音识别库,实现语音转化为文字的功能,并且输出为ros话题。
本文中的语音合成功能:采用百度语音识别库,实现将文字转化为语音并且存储为mp3/wav文件。
2.3 Node
包中一共有3个节点:
- node_main.py
- simple_speek.py
- voice_node.py.
node_main.py 是TTS(Text To Speech)的demo节点, 该demo是和laser scanner一起运行的,当laser检测到一个障碍物,node_main将会触发simple_speek.py让机器说出英语或者汉语 'excuse me', 'make a way for me pls'或者'请让一下',等话语。
simple_speek.py 将会订阅 std_msgs/String 消息类型的话题,并且将该话题中输入的文字转化为语音
voice_node.py 将会识别您在5秒内说出的话语并且输出到终端上。
2.4 订阅的 Topic
TTS(Text To Speech - simple_speek.py):
/speak_string(std_msgs/String)
语音合成节点中机器将会说出的文字。
Demo(node_main.py):
/SpeakerSubTopic (std_msgs/String )
这个是也是一个语音合成的demo节点,是用来触发Text To Speech - simple_speek.py节点的,您可以随意更改SpeakerSubTopic中的文本。
当您给该节点发布stop将会立刻出发Text To Speech - simple_speek.py节点开始说话了。
2.5 发布的 Topic
Demo (node_main.py):
/speak_string(std_msgs/String )
该话题将会定义机器的语音合成(TTS)说什么。
Speech Recognition(voice_node.py):
/Rog_result(std_msgs/String )
这个是语音识别程序,功能是将语音转化为文字。
触发是在终点中输入ENTER。
3. 实现过程的部分代码展示
simple_speek.py中播放合成语音部分:
def play_video(self,file_):
#print '\n start speaking ', "file://%s"%file_
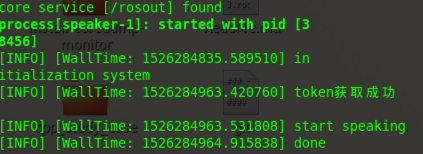
rospy.loginfo('start speaking ')
player = vlc.MediaPlayer("file://%s"%file_)
player.play()
rospy.sleep(1)
while player.is_playing():
pass
#self.pub.publish('PENDING')
rospy.loginfo('done\n')
simple_speek.py中订阅消息部分:
class speeker():
def __init__(self):
self.define()
rospy.Subscriber('speak_string', String, self.SpeedCB, queue_size=1)
rospy.Timer(rospy.Duration(self.ResponseSensitivity), self.TimerCB)
rospy.spin()
simple_speek.py中语音合成部分:
def SpeedCB(self, data):
with self.locker:
speak_string = data.data
if self.TalkNow:
self.WavName = speak_string
self.TalkNow = False
self.mp3file = '%s'%self.path + self.WavName + '.%s'%self.FORMAT
if os.path.exists(r'%s'%self.mp3file):
self.play_video(self.mp3file)
else:
self.speek(speak_string)
voice_node.py 触发部分
def __init__(self):
if_continue=''
while not rospy.is_shutdown() and if_continue == '':
self.define()
self.recode()
words = self.reg()
reg = rospy.Publisher('Rog_result', String, queue_size=1)
reg.publish(words)
#self.savewav("testing")#testing
if_continue = raw_input('pls input ENTER to continue')
voice_node.py 语音识别部分
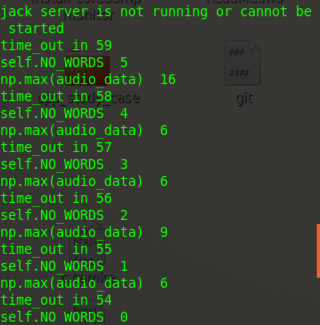
while True and NO_WORDS:
time_out -= 1
print 'time_out in', time_out # 读入NUM_SAMPLES个取样
string_audio_data = stream.read(self.NUM_SAMPLES) # 将读入的数据转换为数组
audio_data = np.fromstring(string_audio_data, dtype=np.short)
# 查看是否没有语音输入
NO_WORDS -= 1
if np.max(audio_data) > self.UPPER_LEVEL:
NO_WORDS=self.NO_WORDS
print 'self.NO_WORDS ', NO_WORDS
print 'np.max(audio_data) ', np.max(audio_data)
# 计算大于LOWER_LEVEL的取样的个数
large_sample_count = np.sum( audio_data > self.LOWER_LEVEL )
# 如果个数大于COUNT_NUM,则至少保存SAVE_LENGTH个块
if large_sample_count > self.COUNT_NUM:
save_count = self.SAVE_LENGTH
else:
save_count -= 1
# 将要保存的数据存放到save_buffer中
if save_count < 0:
save_count = 0
elif save_count > 0 :
save_buffer.append( string_audio_data )
else:
pass
# 将save_buffer中的数据写入WAV文件,WAV文件的文件名是保存的时刻
if len(save_buffer) > 0 and NO_WORDS==0:
self.Voice_String = save_buffer
save_buffer = []
rospy.loginfo( "Recode a piece of voice successfully!")
elif len(save_buffer) > 0 and time_out==0:
self.Voice_String = save_buffer
save_buffer = []
rospy.loginfo( "Recode a piece of voice successfully!")
else:
pass
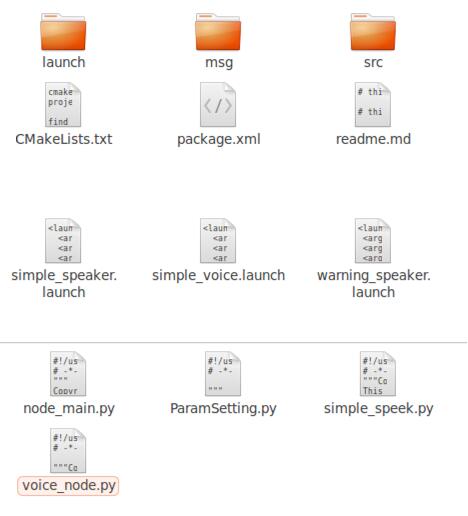
4. 项目文件结构
 ros下基于百度语音的,语音识别和语音合成
ros下基于百度语音的,语音识别和语音合成
注:本文著作权归作者,由demo大师代发,拒绝转载,转载需要作者授权
ros下基于百度语音的,语音识别和语音合成的更多相关文章
- QT调用百度语音REST API实现语音合成
QT调用百度语音REST API实现语音合成 1.首先点击点击链接http://yuyin.baidu.com/docs/tts 点击access_token,获取access_token,里面有详细 ...
- ros实例_百度语音+图灵
1 百度语音模块 参考http://blog.csdn.net/u011118482/article/details/55001444 1.1 百度语音识别包 git clonehttps://git ...
- python调用百度语音(语音识别-斗地主语音记牌器)
一.概述 本篇简要介绍百度语音语音识别的基本使用(其实是斗地主时想弄个记牌器又没money,抓包什么的又不会,只好搞语音识别的了) 二.创建应用 打开百度语音官网,产品与使用->语音识别-> ...
- 百度语音+react+loopback实现语音合成返回播放
1.在百度语音中创建自己的项目,需要拿到APP_ID.API_KEY.SECRET_KEY. 2.loopback端提供接口服务,在./boot目录下新建root.js文件,编写不依赖模型的自定义接口 ...
- 转:基于科大讯飞语音API语音识别开发详解
原文来自于: http://www.52wulian.org/android_voice/ 最近项目需要用到android语音识别,立马就想到科大讯飞,结合官方实例及阅读API文档,初步的完成了And ...
- BaiduSpeechDemo【百度语音SDK集成】(基于v3.0.7.3)
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 本Demo将百度语音SDK(其中一部分功能)和自定义的UI对话框封装到一个module中,便于后续的SDK版本更新以及调用. 本De ...
- BaiduSpeechDemo【百度语音SDK集成】(基于v3.0.8.1)
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 上一篇集成的是V3.0.7.3版本的SDK<BaiduSpeechDemo[百度语音SDK集成](基于v3.0.7.3)> ...
- Android 通过调用系统,如接口 谷歌语音、百度语音、科大讯飞语音等语音识别方法对话框
现在app在发展过程中会集成一些语音识别功能,不具有其自己的显影剂一般正在开发的语音识别引擎,所以在大多数情况下,它是选择一个成熟的语音识别引擎SDK集成到他们的app在. 平时,这种整合被分成两个, ...
- C# 10分钟完成百度语音技术(语音识别与合成)——入门篇
我们已经讲了人脸识别(入门+进阶).图片识别(入门).下面是链接: C# 10分钟完成百度人脸识别——入门篇 C# 30分钟完成百度人脸识别——进阶篇(文末附源码) C# 10分钟完成百度图片提取文字 ...
随机推荐
- “equals”和“==”
“equals”和“==” 首先对于基本类型来说,当值相同的时候,地址也是相同的,所以可以使用“==”进行比较,但是对于equals来说,equals比较的是栈中引用指向的堆中的对象.所以在比较对象的 ...
- Java中导入导出Excel -- POI技术
一.介绍: 当前B/S模式已成为应用开发的主流,而在企业办公系统中,常常有客户这样子要求:你要把我们的报表直接用Excel打开(电信系统.银行系统).或者是:我们已经习惯用Excel打印.这样在我们实 ...
- [centos6.5] 把xampp的htdocs改为其他目录
vim /opt/lampp/etc/httpd.conf DocumentRoot "/opt/lampp/htdocs" 改为 DocumentRoot "/var/ ...
- notepad++ quicktext插件安装与代码片段配置[quicktext v0.2.1]
1 下载quicktext插件0.2.1版本 http://sourceforge.net/projects/quicktext/ 2 解压 3 把QuickText.ANSI.dll和QuickTe ...
- 【HNOI2008】玩具装箱
P教授要去看奥运,但是他舍不下他的玩具,于是他决定把所有的玩具运到北京.他使用自己的压缩器进行压缩,其可以将任意物品变成一堆,再放到一种特殊的一维容器中.P教授有编号为1...N的N件玩具,第i件玩具 ...
- 使用IIFE(立即执行函数)让变量私有化
今天去看了一个GITHUB上的开源项目,在客户端JS的脚本编写的时候,代码中多次使用了IIFE. 一开始我是懵逼的,不知道这种函数的意义何在,小菜鸟嘛. 后面我去研究了一番.发现了它的主要作用就是:让 ...
- oracle 替换其中部分内容
update TABLE_NAME set field =REPLACE(field ,substr(field ,0,1) ,'P') where field is not null ;
- 为何jsp 在resin下乱码,但在tomcat下却工作良好的问题
关于JSP页面中的pageEncoding和contentType两种属性的区别: pageEncoding是jsp文件本身的编码 contentType的charset是指服 ...
- 【BZOJ 2333 】[SCOI2011]棘手的操作(离线+线段树|可并堆-左偏树)
2333: [SCOI2011]棘手的操作 Description 有N个节点,标号从1到N,这N个节点一开始相互不连通.第i个节点的初始权值为a[i],接下来有如下一些操作: U x y: 加一条边 ...
- 【kd-tree】bzoj3489 A simple rmq problem
Orz zyf教给蒟蒻做法 蒟蒻并不会这题正解……(可持久化树套树?...Orz 对于每个点,我们可以求出pre[i],nex[i],那么询问的答案就是:求max (a[i]),其中 i 满足(pre ...