python web指纹获取加目录扫描加端口扫描加判断robots.txt
前言:
总结上几次的信息收集构造出来的。
0x01:
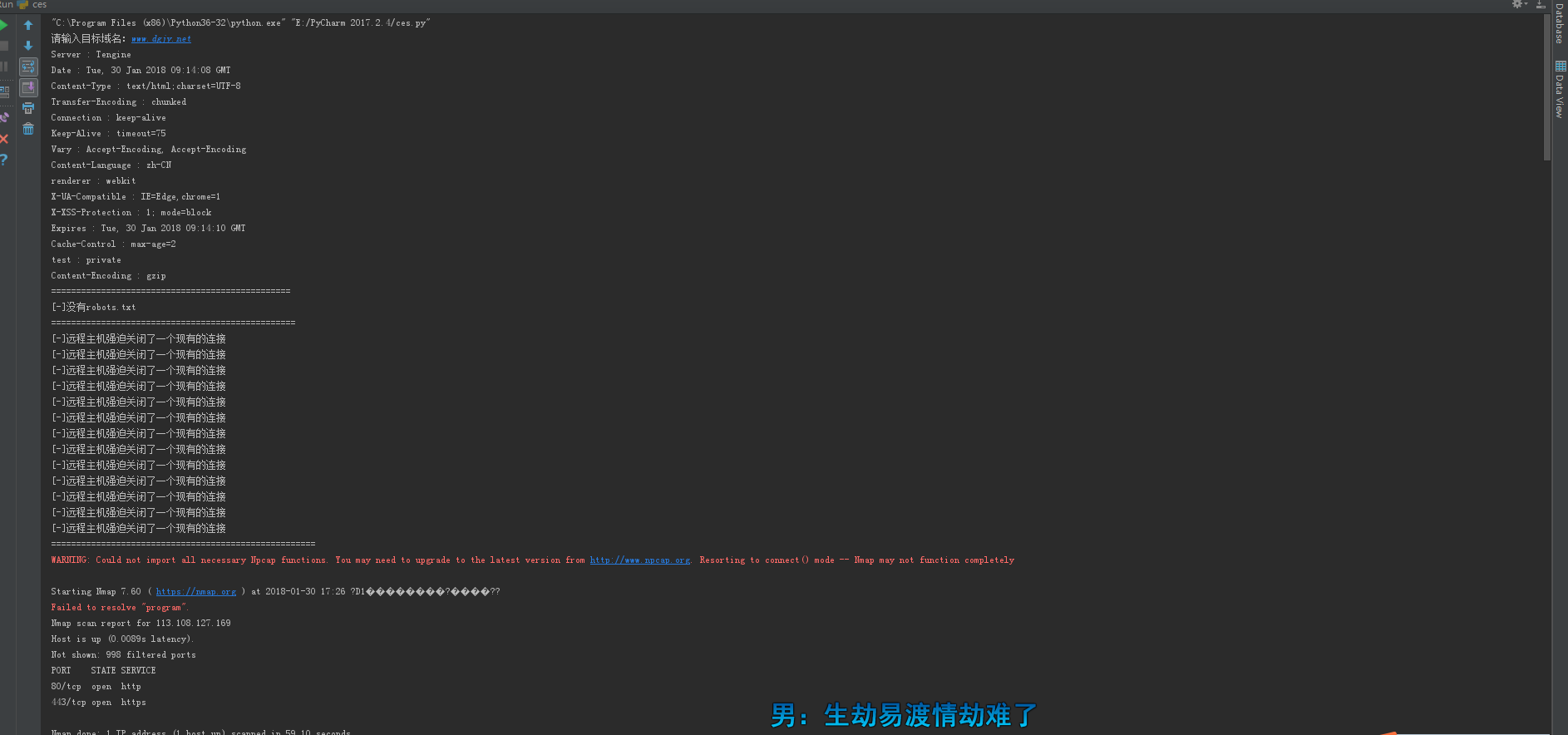
首先今行web指纹识别,然后在进行robots是否存在。后面是目录扫描
然后到使用nmap命令扫描端口。(nmap模块在windows下使用会报停止使用的鬼鬼)
0x02:
代码:
import requests
import os
import socket
from bs4 import BeautifulSoup
import time
def Webfingerprintcollection():
global lgr
lgr=input('请输入目标域名:')
url="http://{}".format(lgr)
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r=requests.get(url,headers=header)
xyt=r.headers
for key in xyt:
print(key,':',xyt[key])
Webfingerprintcollection()
print('================================================')
def robots():
urlsd="http://{}/robots.txt".format(lgr)
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
gf=requests.get(urlsd,headers=header,timeout=8)
if gf.status_code == 200:
print('robots.txt存在')
print('[+]该站存在robots.txt',urlsd)
else:
print('[-]没有robots.txt')
robots()
print("=================================================")
def Webdirectoryscanner():
dict=open('build.txt','r',encoding='utf-8').read().split('\n')
for xyt in dict:
try:
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
urljc="http://"+lgr+"{}".format(xyt)
rvc=requests.get(urljc,headers=header,timeout=8)
if rvc.status_code == 200:
print('[*]',urljc)
except:
print('[-]远程主机强迫关闭了一个现有的连接')
Webdirectoryscanner()
print("=====================================================")
s = socket.gethostbyname(lgr)
def portscanner():
o=os.system('nmap {} program'.format(s))
print(o)
portscanner()
print('======================================================')
def whois():
heads={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
urlwhois="http://site.ip138.com/{}/whois.htm".format(lgr)
rvt=requests.get(urlwhois,headers=heads)
bv=BeautifulSoup(rvt.content,"html.parser")
for line in bv.find_all('p'):
link=line.get_text()
print(link)
whois()
print('======================================================')
def IPbackupdomainname():
wu=socket.gethostbyname(lgr)
rks="http://site.ip138.com/{}/".format(wu)
rod={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
sjk=requests.get(rks,headers=rod)
liverou=BeautifulSoup(sjk.content,'html.parser')
for low in liverou.find_all('li'):
bc=low.get_text()
print(bc)
IPbackupdomainname()
print('=======================================================')
python web指纹获取加目录扫描加端口扫描加判断robots.txt的更多相关文章
- python os模块获取指定目录下的文件列表
bath_path = r"I:\ner_results\ner_results" dir_list1 = os.listdir(bath_path) for dir1 in di ...
- 使用C#winform编写渗透测试工具--Web指纹识别
使用C#winform编写渗透测试工具--web指纹识别 本篇文章主要介绍使用C#winform编写渗透测试工具--Web指纹识别.在渗透测试中,web指纹识别是信息收集关键的一步,通常是使用各种工具 ...
- 利用Python进行端口扫描
利用Python进行端口扫描 - Dahlhin - 博客园 https://www.cnblogs.com/dachenzi/p/8676104.html Python实现对一个网络段扫描及端口扫描 ...
- 网络安全:robots.txt防止向黑客泄露后台地址和隐私目录的写法
做优化的朋友都知道网站的robots的目的是让搜索引擎知道我们网站哪些目录可以收录,哪些目录禁止收录.通常情况蜘蛛访问网站时,会首先检查你的网站根目录是否有robots文件,如果有,则会根据此文件来进 ...
- ★Kali信息收集★8.Nmap :端口扫描
★Kali信息收集~ 0.Httrack 网站复制机 http://www.cnblogs.com/dunitian/p/5061954.html ★Kali信息收集~ 1.Google Hackin ...
- python获取指定目录下所有文件名os.walk和os.listdir
python获取指定目录下所有文件名os.walk和os.listdir 觉得有用的话,欢迎一起讨论相互学习~Follow Me os.walk 返回指定路径下所有文件和子文件夹中所有文件列表 其中文 ...
- 一个获取指定目录下一定格式的文件名称和文件修改时间并保存为文件的python脚本
摘自:http://blog.csdn.net/forandever/article/details/5711319 一个获取指定目录下一定格式的文件名称和文件修改时间并保存为文件的python脚本 ...
- python获取指定目录下特定格式的文件名
之前一直用windows下的bat脚本获取一个目录下的指定格式的文件名,如下所示: dir *.jpg /b/s > train.set pause 十分简单,将这个bat文件放到你想要获取文件 ...
- Python获取指定目录下所有子目录、所有文件名
需求 给出制定目录,通过Python获取指定目录下的所有子目录,所有(子目录下)文件名: 实现 import os def file_name(file_dir): for root, dirs, f ...
随机推荐
- LightOJ - 1265 概率
题意:有t头老虎,d头鹿,每天五种情况,虎虎,虎鹿,鹿鹿,鹿人,人虎,求生存的概率 题意:鹿就是来迷惑你的(结果我就陷进坑了),无论怎么选最后一定只剩下虎虎,虎人两种情况对结果有影响,那么如果有n只虎 ...
- [MYSQL]时间毫秒数转换
java中常用bigint字段保存时间,通常将时间保存为一大串数字,每次取出需要在程序里转换,有时候程序里不方便,可以使用MYSQL自带的函数FROM_UNIXTIME(unix_timestamp, ...
- 【spark】【问题】textFile找不到文件
2018/5/9 关于textFile读取文件的问题 问题描述: 今天第一次使用spark-shell来读取文件,我在本地建立了一个text.txt文件,然后用textFile读取生成rdd. 但是执 ...
- 兄弟ifream的方法调用
兄弟ifream A var ifreamId = window.frameElement && window.frameElement.id || ''; var url = 'ur ...
- python基础之迭代器协议和生成器(二)
一.什么是迭代器: 迭代是Python最强大的功能之一,是访问集合元素的一种方式. 迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束. 迭代器是一个可以记住遍历的位置的对象. 迭代器的 ...
- Android中SQLite介绍
现在的主流移动设备像Android.iPhone等都使用SQLite作为复杂数据的存储引擎,在我们为移动设备开发应用程序时,也许就要使用到SQLite来存储我们大量的数据,所以我们就需要掌握移动设备上 ...
- lzugis——Arcgis Server for JavaScript API之POI
POI(Point Of Interest),感兴趣点,其实呢,严格意义上说应该不是POI,但是单位就这样叫了,我也就这样叫了,其实现的功能大致是这样的:用过百度地图的朋友们都知道你在百度地图时,当鼠 ...
- C高级第一次作业附加
之前的作业链接:http://www.cnblogs.com/1204113692yang/p/8625650.html 过去两周学习了指针的概念.指针变量的定义.指针的基本运算.指针操作改变主调函数 ...
- I.MX6 support eMMC 5.0
/***************************************************************************** * I.MX6 support eMMC ...
- c++线程同步和通信
一.线程的创建 你也许会说我一直用CreateThread来创建线程,一直都工作得好好的,为什么要用_beginthreadex来代替CreateThread,下面让我来告诉你为什么. 回答一个 ...