ZooKeeper集群搭建过程
ZooKeeper集群搭建过程
提纲
1、ZooKeeper简介
2、ZooKeeper的下载和安装
3、部署3个节点的ZK伪分布式集群
3.1、解压ZooKeeper安装包
3.2、为每个节点建立data目录、logs目录和myid文件
3.3、为每个节点创建配置文件
3.4、启动zk集群
3.5、客户端接入集群
4、真正分布式集群需要注意的地方
5、配置文件中的配置项的含义
6、参考资料
1、ZooKeeper简介
===================
ZooKeeper是一个开源的分布式框架,提供了协调分布式应用的基本服务。它向外部应用暴露一组通用服务——分布式同步(Distributed Synchronization)、命名服务(Naming Service)、集群维护(Group Maintenance)等,简化分布式应用协调及其管理的难度。
它是Google的Chubby一个开源的实现。它本身可以搭建成一个集群,这个zk集群用来对应用程序集群进行管理,监视应用程序集群中各个节点的状态,并根据应用程序集群中各个节点提交的反馈信息决定下一步的合理操作。
关于ZooKeeper的使用方法和原理,后续再另外介绍,现在先记录搭建和初步运行的过程。

2、ZooKeeper的下载和安装
========================
ZooKeeper的下载很简单,安装就是解压一下,也很简单。
3、部署3个节点的ZK伪分布式集群
=============================
在同一台服务器上,部署一个3个ZooKeeper节点组成的集群,这样的集群叫伪分布式集群,而如果集群中的3个节点分别部署在3个服务器上,那么这种集群就叫真正的分布式集群。
这里,记录一下搭建一个3节点的伪分布式集群的过程,真正的分布式集群的搭建过程和伪分布式的过程类似,稍有不同,我会在下面指出来的。
首先,建立一个集群安装的目录,就叫zk34(zk34是指使用ZooKeeper3.4版本),建立的集群就叫它zk34吧。
其次,在这个目录的下面解压三份ZooKeeper,形成3个节点,每一个目录中的ZooKeeper就代表一个节点。
这样就形成了如下的安装目录结构:
/home/zzl/DataTool/zk34
|----zookeeper0/
|----zookeeper1/
|----zookeeper2/
3.1 解压ZooKeeper安装包
-------------------------------------------
首先在要安装集群的目录中解压zk。
[zzl@localhost zk34]$ tar -xzf path/to/zookeeper-3.4.6.tar.gz -C .
[zzl@localhost zk34]$ ls
zookeeper-3.4.6
之后把解压的zk复制出三份来,分别命名为zookeeper0,zookeeper1,zookeeper2,这三个目录中的zk就当成是集群中的3个节点。
[zzl@localhost zk34]$ cp zookeeper-3.4.6 zookeeper0
[zzl@localhost zk34]$ cp zookeeper-3.4.6 zookeeper1
[zzl@localhost zk34]$ cp zookeeper-3.4.6 zookeeper2
这样集群中的目录结构就是下面这样的:
/home/zzl/DataTool/zk34
|----zookeeper0/
|----zookeeper1/
|----zookeeper2/
3.2 为每个节点建立data目录、logs目录和myid文件
-------------------------------------------------------------------------
在3个节点目录中分别建立data目录、logs目录和myid文件。
下面是zookeeper0上的:
新建目录data:/home/zzl/DataTool/zk34/zookeeper0/data
新建目录logs:/home/zzl/DataTool/zk34/zookeeper0/logs
新建文件myid:/home/zzl/DataTool/zk34/zookeeper0/data/myid
myid文件的内容是节点在集群中的编号,zookeeper0节点的编号就写成0,后边的zookeeper1的编号是1,zookeeper2的编号就是2。
按照同样的方法,依次在zookeeper1和zookeeper2上都建立以上目录和文件。
3.3 为每个节点创建配置文件
-----------------------------------------
新建zookeeper0的配置文件zoo.cfg:/home/zzl/DataTool/zk34/zookeeper0/conf/zoo.cfg
配置文件zoo.cfg的内容如下:
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/home/michael/opt/zookeeper/server0/zookeeper/data
dataLogDir=/home/michael/opt/zookeeper/server0/zookeeper/logs
clientPort=4180
server.0=127.0.0.1:8880:7770
server.1=127.0.0.1:8881:7771
server.2=127.0.0.1:8882:7772
配置文件中的配置项的含义参见下面的介绍。
用同样的方法,在zookeeper1和zookeeper2的相应位置创建zoo.cfg,文件内容复制zookeeper0的zoo.cfg。只不过需要改动clientport、dataDir、dataLogDir三个配置项,zookeeper1的clientport改为4181,zookeeper2的clientport改为4182,而dataDir和dataLogDir都修改为相应的目录,就好了。
经过以上的配置,zk34集群中的3个节点就全部配置好了。
3.4 启动zk集群
-----------------------------
进入zk34集群的第一个节点zookeeper0的bin目录下,启动服务:
[zzl@localhost zk34]$
[zzl@localhost zk34]$ cd zookeeper0/
[zzl@localhost zookeeper0]$ bin/zkServer.sh start
然后,按照同样的方法,依次启动zookeeper1和zookeeper2的服务。
这样zk34集群的3个节点都启动起来了。
3.5 客户端接入集群
------------------------------
进入zk34集群中任意一个节点的bin目录下,启动一个客户端,接入已经启动好的zk34集群。这里的server可以填写集群中的任何一个节点的ip,端口号是对应ip的节点的配置文件中clientport的值。
./zkCli.sh –server 127.0.0.1:4180
下面的截图是我成功之后的3个节点和客户端的图:
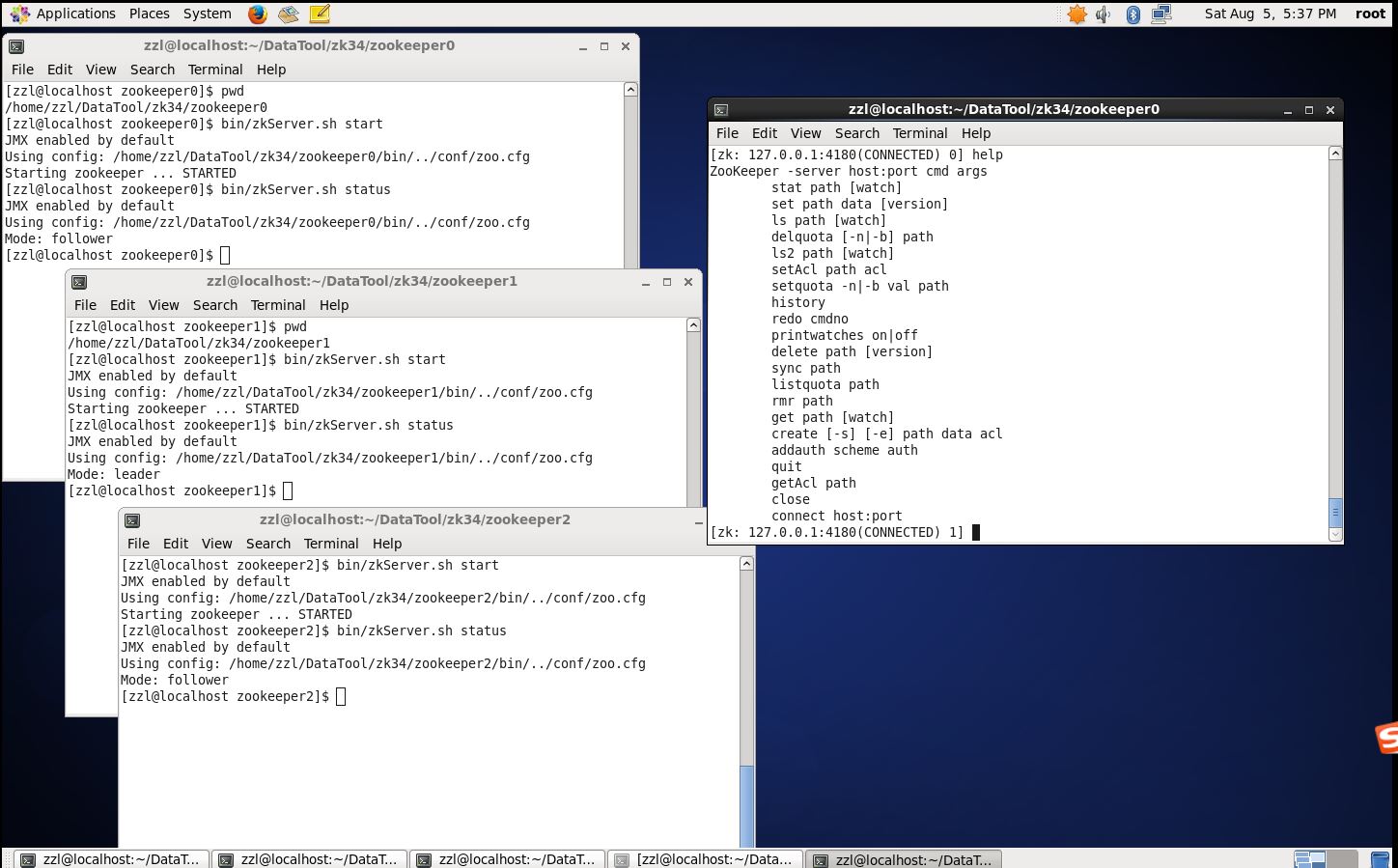
以上就是zk集群的搭建过程。
4、真正分布式集群需要注意的地方
==============================
真正的分布式集群和伪分布式集群不一样的地方在于配置文件。
1、clientport端口各个节点一样就行。
2、server.0=127.0.0.1:8880:7770中的ip要修改成对应的server的ip,后边的两个端口号不需要不同,各个节点都一样就可以了。
其他地方伪分布式和真正分布式都是一样的。
5、ZooKeeper配置文件中的配置项的含义
=================================
配置文件中配置项的含义:
- tickTime: zookeeper中使用的基本时间单位,毫秒值,比如可以设为1000,那么基本时间单位就是1000ms,也就是1s。
- initLimit: zookeeper集群中的包含多台server,其中一台为leader,集群中其余的server为follower,initLimit参数配置初始化连接时,follower和leader之间的最长心跳时间。如果该参数设置为5,就说明时间限制为5倍tickTime,即5*1000=5000ms=5s。
- syncLimit: 该参数配置leader和follower之间发送消息,请求和应答的最大时间长度。如果该参数设置为2,说明时间限制为2倍tickTime,即2000ms。
- dataDir: 数据目录. 可以是任意目录,一般是节点安装目录下data目录。
- dataLogDir: log目录, 同样可以是任意目录,一般是节点安装目录下的logs目录。如果没有设置该参数,将使用和dataDir相同的设置。
- clientPort: 监听client连接的端口号。
- server.X=A:B:C 其中X是一个数字, 表示这是第几号server,它的值和myid文件中的值对应。A是该server所在的IP地址。B是配置该server和集群中的leader交换消息所使用的端口。C配置选举leader时所使用的端口。由于配置的是伪集群模式,所以各个server的B, C参数必须不同,如果是真正分布式集群,那么B和C在各个节点上可以相同,因为即使相同由于节点处于不同的服务器也不会导致端口冲突。
6 参考资料
============
http://blog.csdn.net/poechant/article/details/6633923
ZooKeeper集群搭建过程的更多相关文章
- 分布式协调服务Zookeeper集群搭建
分布式协调服务Zookeeper集群搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.安装jdk环境 1>.操作环境 [root@node101.yinzhengjie ...
- Zookeeper集群搭建以及python操作zk
一.Zookeeper原理简介 ZooKeeper是一个开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等. Zookeeper设计目 ...
- 分布式实时日志系统(一)环境搭建之 Jstorm 集群搭建过程/Jstorm集群一键安装部署
最近公司业务数据量越来越大,以前的基于消息队列的日志系统越来越难以满足目前的业务量,表现为消息积压,日志延迟,日志存储日期过短,所以,我们开始着手要重新设计这块,业界已经有了比较成熟的流程,即基于流式 ...
- zookeeper集群搭建及Leader选举算法源码解析
第一章.zookeeper概述 一.zookeeper 简介 zookeeper 是一个开源的分布式应用程序协调服务器,是 Hadoop 的重要组件. zooKeeper 是一个分布式的,开放源码的分 ...
- zookeeper集群搭建及常用场景实现
本文完整源码地址 基于zookeeper的常用用法.分布式锁.分布式队列及leader选举实现 https://github.com/killianxu/zookeeper_example zooke ...
- zookeeper集群搭建及ZAB协议
zookeeper集群搭建非常简单,准备三台安装好zookeeper服务器,在其zoo.cfg配置中分表添加如下配置 initLimit 10 集群中的follower与leader之间完成初始化同步 ...
- java 学习笔记(三)ZooKeeper集群搭建实例,以及集成dubbo时的配置 (转)
ZooKeeper集群搭建实例,以及集成dubbo时的配置 zookeeper是什么: Zookeeper,一种分布式应用的协作服务,是Google的Chubby一个开源的实现,是Hadoop的分布式 ...
- zookeeper集群搭建记录
本文仅记录zookeeper集群搭建的过程,留待日后查看.使用. 一.硬件机器: 192.168.183.195 master-node 192.168.183.194 data-node1 192. ...
- zookeeper 集群搭建 转
通过 VMware ,我们安装了三台虚拟机,用来搭建 zookeeper 集群,虚拟机网络地址如下: hostname ipaddress ...
随机推荐
- react privateRoute
import React from 'react'; import PropTypes from 'prop-types'; import {Route,Redirect,withRouter} fr ...
- 初识Linux(五)--VI/VIM编辑器
我们操作文件,终究离不开编辑文件,对文件内容的编辑,Linux系统下,我们通常使用VI/VIM来编辑文件.VI是每个Linux都会自带的文本编辑器,VIM是VI的增强版,可能有些发行版本没有自带,可以 ...
- Android开发技巧——写一个StepView
在我们的应用开发中,有些业务流程会涉及到多个步骤,或者是多个状态的转化,因此,会需要有相关的设计来展示该业务流程.比如<停车王>应用里的添加车牌的步骤. 通常,我们会把这类控件称为&quo ...
- android自定义view系列:认识activity结构
标签: android 自定义view activity 开发中虽然我们调用Activity的setContentView(R.layout.activity_main)方法显示View视图,但是vi ...
- [置顶]
Git 配置SSH简单玩法?
> 第一步下载git点击直接下载 他会检测您的系统当前是64bit还是32bit安装过程不再啰嗦反正就是Next Next Next Finish 第二步这里你可以下载TortoiseGit点击 ...
- Django 之母板
---恢复内容开始--- 母板 <!DOCTYPE html> <html lang="en"> <head> <meta charset ...
- BZOJ - 3622:已经没有什么好害怕的了 (广义容斥)
[BZOJ3622]已经没有什么好害怕的了 Description Input Output Sample Input 4 2 5 35 15 45 40 20 10 30 Sample Output ...
- HDU - 3374:String Problem (最小表示法模板题)
Give you a string with length N, you can generate N strings by left shifts. For example let consider ...
- VMware 10安装Mac OS X 10.11和XCode7
上周把我的计算机当试验品,安装mac虚拟机.由于文件下载复制解压的时间花了很长,历时两天,记录下来(和我一样的新手不妨参考一下): 我机硬件:win7 64位 8G内存 没有8G以上就不要考虑了.我安 ...
- django中的locale()函数
就是可以将函数中的变量与其对应的值,自动包裹成字典传到静态页面 参考链接:http://www.jb51.net/article/69558.htm