SQL Server中的三种物理连接操作
来源:https://msdn.microsoft.com/zh-cn/library/dn144699.aspx
简介
在SQL Server中,我们所常见的表与表之间的Inner Join,Outer Join都会被执行引擎根据所选的列,数据上是否有索引,所选数据的选择性转化为Loop Join,Merge Join,Hash Join这三种物理连接中的一种。理解这三种物理连接是理解在表连接时解决性能问题的基础,下面我来对这三种连接的原理,适用场景进行描述。
嵌套循环连接(Nested Loop Join)
循环嵌套连接是最基本的连接,正如其名所示那样,需要进行循环嵌套,嵌套循环是三种方式中唯一支持不等式连接的方式,这种连接方式的过程可以简单的用下图展示:
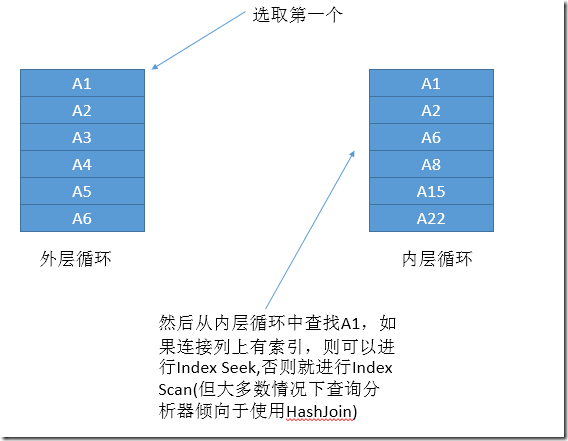
图1.循环嵌套连接的第一步
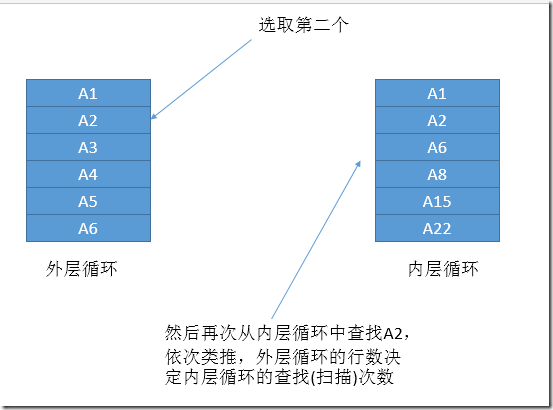
图2.循环嵌套连接的第二步
由上面两个图不难看出,循环嵌套连接查找内部循环表的次数等于外部循环的行数,当外部循环没有更多的行时,循环嵌套结束。另外,还可以看出,这种连接方式需要内部循环的表有序(也就是有索引),并且外部循环表的行数要小于内部循环的行数,否则查询分析器就更倾向于Hash Join(会在本文后面讲到)。
通过嵌套循环连接也可以看出,随着数据量的增长这种方式对性能的消耗将呈现出指数级别的增长,所以数据量到一定程度时,查询分析器往往就会采用这种方式。
下面我们通过例子来看一下循环嵌套连接,利用微软的AdventureWorks数据库:
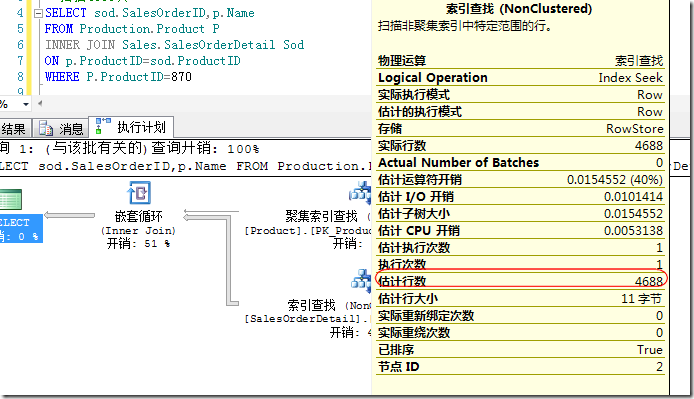
图3.一个简单的嵌套循环连接
图3中ProductID是有索引的,并且在循环的外部表中(Product表)符合ProductID=870的行有4688条,因此,对应的SalesOrderDetail表需要查找4688次。让我们在上面的查询中再考虑另外一个例子,如图4所示。
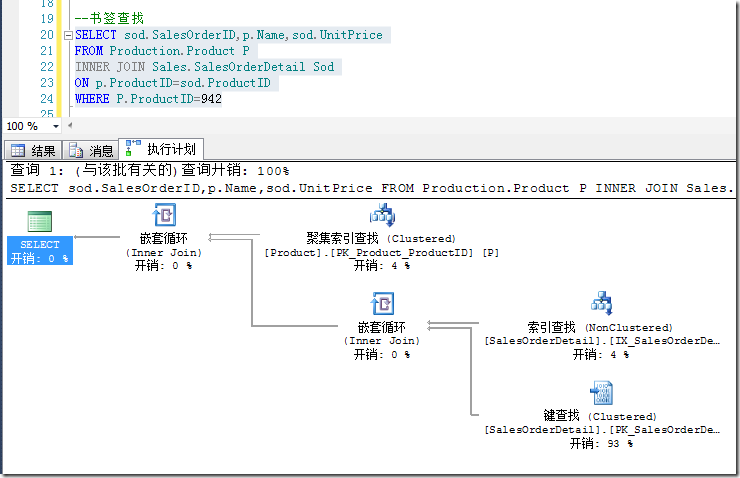
图4.额外的列带来的额外的书签查找
由图4中可以看出,由于多选择了一个UnitPrice列,导致了连接的索引无法覆盖所求查询,必须通过书签查找来进行,这也是为什么我们要养成只Select需要的列的好习惯,为了解决上面的问题,我们既可以用覆盖索引,也可以减少所需的列来避免书签查找。另外,上面符合ProductID的行仅仅只有5条,所以查询分析器会选择书签查找,假如我们将符合条件的行进行增大,查询分析器会倾向于表扫描(通常来说达到表中行数的1%以上往往就会进行table scan而不是书签查找,但这并不绝对),如图5所示。
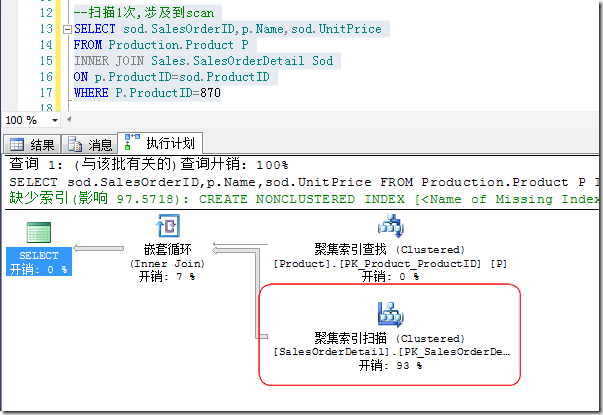
图5.查询分析器选择了表扫描
可以看出,查询分析器此时选择了表扫描来进行连接,这种方式效率要低下很多,因此好的覆盖索引和Select *都是需要注意的地方。另外,上面情况即使涉及到表扫描,依然是比较理想的情况,更糟糕的情况是使用多个不等式作为连接时,查询分析器即使知道每一个列的统计分布,但却不知道几个条件的联合分布,从而产生错误的执行计划,如图6所示。
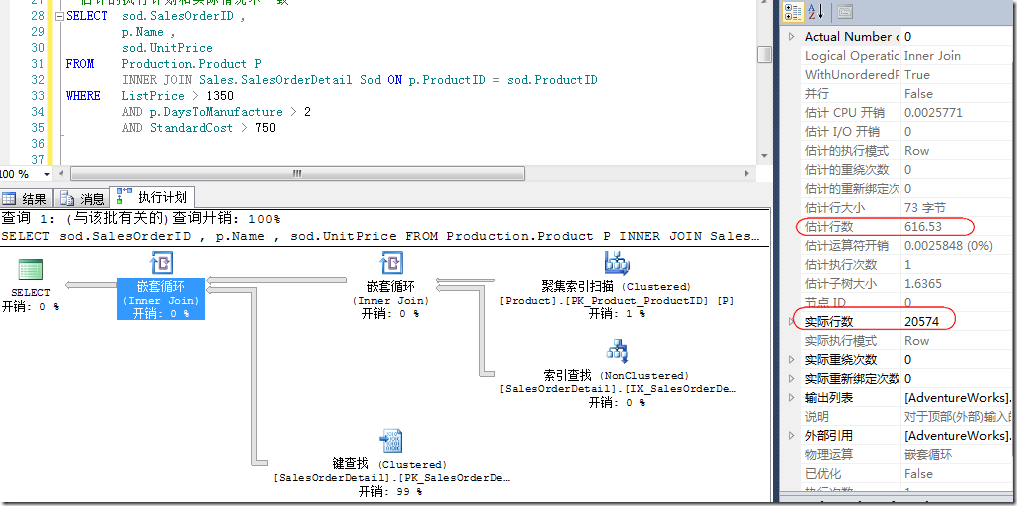
图6.由于无法预估联合分布,导致的偏差
由图6中,我们可以看出,估计的行数和实际的行数存在巨大的偏差,从而应该使用表扫描但查询分析器选择了书签查找,这种情况对性能的影响将会比表扫描更加巨大。具体大到什么程度呢?我们可以通过强制表扫描和查询分析器的默认计划进行比对,如图7所示。

图7.强制表扫描性能反而更好
合并连接(Merge Join)
谈到合并连接,我突然想起在西雅图参加SQL Pass峰会晚上酒吧排队点酒,由于我和另外一哥们站错了位置,貌似我们两个在插队一样,我赶紧说:I’m sorry,i thought here is end of line。对方无不幽默的说:”It’s OK,In SQL Server,We called it merge join”。
由上面的小故事不难看出,Merge Join其实上就是将两个有序队列进行连接,需要两端都已经有序,所以不必像Loop Join那样不断的查找循环内部的表。其次,Merge Join需要表连接条件中至少有一个等号查询分析器才会去选择Merge Join。
Merge Join的过程我们可以简单用下面图进行描述:
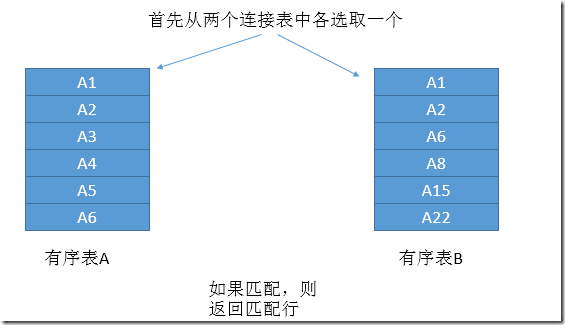
图8.Merge Join第一步
Merge Join首先从两个输入集合中各取第一行,如果匹配,则返回匹配行。加入两行不匹配,则有较小值的输入集合+1,如图9所示。
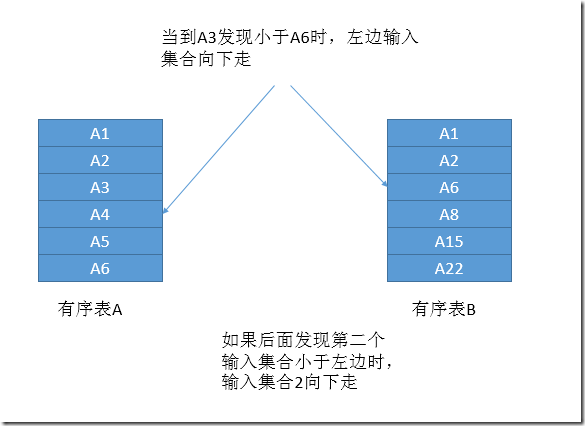
图9.更小值的输入集合向下进1
用C#代码表示Merge Join的话如代码1所示。
public class MergeJoin
{
// Assume that left and right are already sorted
public static Relation Sort(Relation left, Relation right)
{
Relation output = new Relation();
while (!left.IsPastEnd() && !right.IsPastEnd())
{
if (left.Key == right.Key)
{
output.Add(left.Key);
left.Advance();
right.Advance();
}
else if (left.Key < right.Key)
left.Advance();
else //(left.Key > right.Key)
right.Advance();
}
return output;
}
}
代码1.Merge Join的C#代码表示
因此,通常来说Merge Join如果输入两端有序,则Merge Join效率会非常高,但是如果需要使用显式Sort来保证有序实现Merge Join的话,那么Hash Join将会是效率更高的选择。但是也有一种例外,那就是查询中存在order by,group by,distinct等可能导致查询分析器不得不进行显式排序,那么对于查询分析器来说,反正都已经进行显式Sort了,何不一石二鸟的直接利用Sort后的结果进行成本更小的MERGE JOIN?在这种情况下,Merge Join将会是更好的选择。
另外,我们可以由Merge Join的原理看出,当连接条件为不等式(但不包括!=),比如说> < >=等方式时,Merge Join有着更好的效率。
下面我们来看一个简单的Merge Join,这个Merge Join是由聚集索引和非聚集索引来保证Merge Join的两端有序,如图10所示。
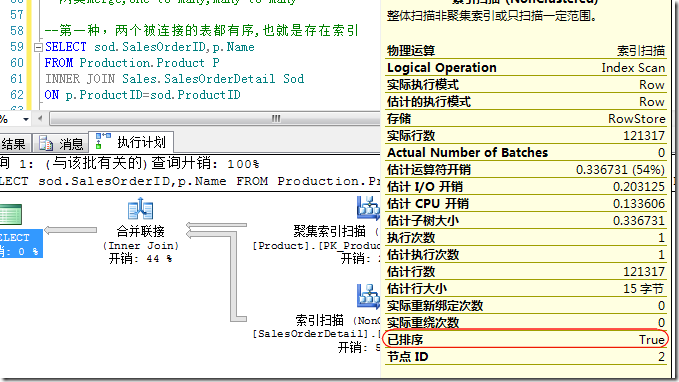
图10.由聚集索引和非聚集索引保证输入两端有序
当然,当Order By,Group By时查询分析器不得不用显式Sort,从而可以一箭双雕时,也会选择Merge Join而不是Hash Join,如图11所示。
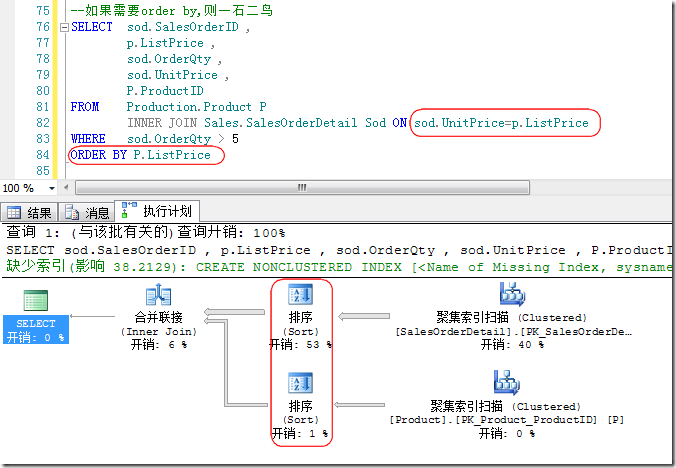
图11.一箭双雕的Merge Join
哈希匹配(Hash Join)
哈希匹配连接相对前面两种方式更加复杂一些,但是哈希匹配对于大量数据,并且无序的情况下性能均好于Merge Join和Loop Join。对于连接列没有排序的情况下(也就是没有索引),查询分析器会倾向于使用Hash Join。
哈希匹配分为两个阶段,分别为生成和探测阶段,首先是生成阶段,第一阶段生成阶段具体的过程可以如图12所示。
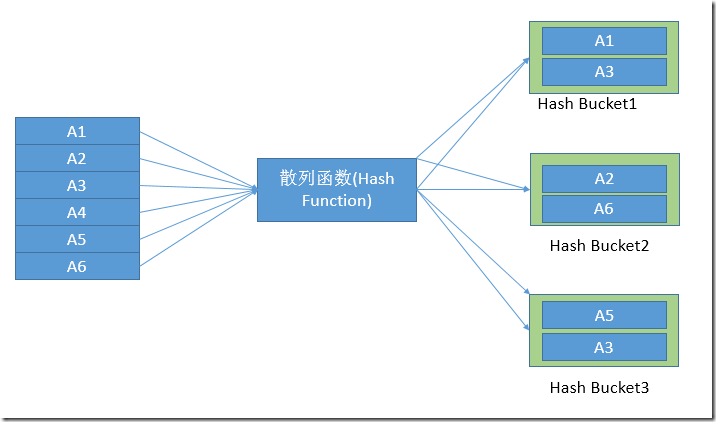
图12.哈希匹配的第一阶段
图12中,将输入源中的每一个条目经过散列函数的计算都放到不同的Hash Bucket中,其中Hash Function的选择和Hash Bucket的数量都是黑盒,微软并没有公布具体的算法,但我相信已经是非常好的算法了。另外在Hash Bucket之内的条目是无序的。通常来讲,查询优化器都会使用连接两端中比较小的哪个输入集来作为第一阶段的输入源。
接下来是探测阶段,对于另一个输入集合,同样针对每一行进行散列函数,确定其所应在的Hash Bucket,在针对这行和对应Hash Bucket中的每一行进行匹配,如果匹配则返回对应的行。
通过了解哈希匹配的原理不难看出,哈希匹配涉及到散列函数,所以对CPU的消耗会非常高,此外,在Hash Bucket中的行是无序的,所以输出结果也是无序的。图13是一个典型的哈希匹配,其中查询分析器使用了表数据量比较小的Product表作为生成,而使用数据量大的SalesOrderDetail表作为探测。
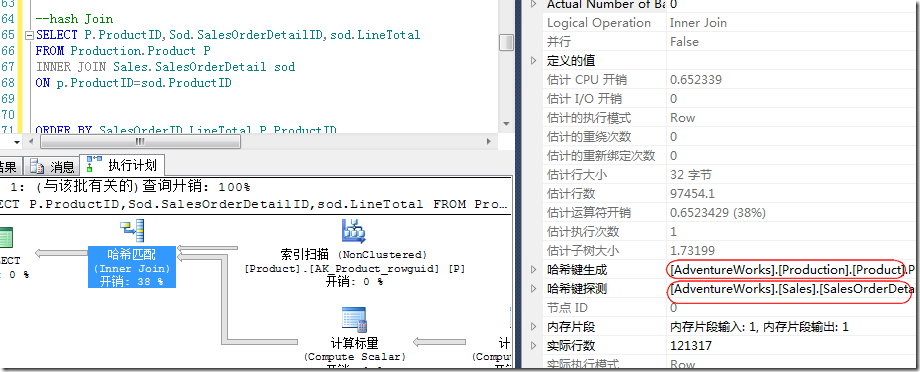
图13.一个典型的哈希匹配连接
上面的情况都是内存可以容纳下生成阶段所需的内存,如果内存吃紧,则还会涉及到Grace哈希匹配和递归哈希匹配,这就可能会用到TempDB从而吃掉大量的IO。这里就不细说了,有兴趣的同学可以移步:http://msdn.microsoft.com/zh-cn/library/aa178403(v=SQL.80).aspx。
总结
下面我们通过一个表格简单总结这几种连接方式的消耗和使用场景:
|
嵌套循环连接 |
合并连接 |
哈希连接 |
|
|
适用场景 |
外层循环小,内存循环条件列有序 |
输入两端都有序 |
数据量大,且没有索引 |
|
CPU |
低 |
低(如果没有显式排序) |
高 |
|
内存 |
低 |
低(如果没有显式排序) |
高 |
|
IO |
可能高可能低 |
低 |
可能高可能低 |
理解SQL Server这几种物理连接方式对于性能调优来说必不可少,很多时候当筛选条件多表连接多时,查询分析器就可能不是那么智能了,因此理解这几种连接方式对于定位问题变得尤为重要。此外,我们也可以通过从业务角度减少查询范围来减少低下性能连接的可能性。
参考文献:
http://msdn.microsoft.com/zh-cn/library/aa178403(v=SQL.80).aspx
http://www.dbsophic.com/SQL-Server-Articles/physical-join-operators-merge-operator.html
SQL Server中的三种物理连接操作的更多相关文章
- 浅谈SQL Server中的三种物理连接操作
简介 在SQL Server中,我们所常见的表与表之间的Inner Join,Outer Join都会被执行引擎根据所选的列,数据上是否有索引,所选数据的选择性转化为Loop Join,Merge J ...
- 浅谈SQL Server中的三种物理连接操作(HASH JOIN MERGE JOIN NESTED LOOP)
简介 在SQL Server中,我们所常见的表与表之间的Inner Join,Outer Join都会被执行引擎根据所选的列,数据上是否有索引,所选数据的选择性转化为Loop Join,Merge J ...
- 浅谈SQL Server中的三种物理连接操作(Nested Loop Join、Merge Join、Hash Join)
简介 在SQL Server中,我们所常见的表与表之间的Inner Join,Outer Join都会被执行引擎根据所选的列,数据上是否有索引,所选数据的选择性转化为Loop Join,Merge J ...
- SQL Server中的三种Join方式
1.测试数据准备 参考:Sql Server中的表访问方式Table Scan, Index Scan, Index Seek 这篇博客中的实验数据准备.这两篇博客使用了相同的实验数据. 2.SQ ...
- SQL Server 中的三种分页方式
USE tempdb GO SET NOCOUNT ON --创建表结构 IF OBJECT_ID(N'ClassB', N'U') IS NOT NULL DROP TABLE ClassB GO ...
- SQL Server 中的6种事务隔离级别简单总结
本文出处:http://www.cnblogs.com/wy123/p/7218316.html (保留出处并非什么原创作品权利,本人拙作还远远达不到,仅仅是为了链接到原文,因为后续对可能存在的一些错 ...
- SQL Server中的Image数据类型的操作
原文:SQL Server中的Image数据类型的操作 准备工作,在库Im_Test中建立一张表Im_Info,此表中有两个字段,分别为Pr_Id (INT),Pr_Info (IMAGE),用来存储 ...
- SQL SERVER中的两种常见死锁及解决思路
在sql server中,死锁都与一种锁有关,那就是排它锁(x锁).由于在同一时间对同一个数据库资源只能有一个数据库进程可以拥有排它锁.因此,一旦多个进程都需要获取某个或者同一个数据库资源的排它访问权 ...
- SQL Server数据库的三种恢复模式:简单恢复模式、完整恢复模式和大容量日志恢复模式(转载)
SQL Server数据库有三种恢复模式:简单恢复模式.完整恢复模式和大容量日志恢复模式: 1.Simple 简单恢复模式, Simple模式的旧称叫”Checkpoint with truncate ...
随机推荐
- PAT (Basic Level) Practise:1032. 挖掘机技术哪家强
[题目链接] 为了用事实说明挖掘机技术到底哪家强,PAT组织了一场挖掘机技能大赛.现请你根据比赛结果统计出技术最强的那个学校. 输入格式: 输入在第1行给出不超过105的正整数N,即参赛人数.随后N行 ...
- Map/Reduce 工作机制分析 --- 错误处理机制
前言 对于Hadoop集群来说,节点损坏是非常常见的现象. 而Hadoop一个很大的特点就是某个节点的损坏,不会影响到整个分布式任务的运行. 下面就来分析Hadoop平台是如何做到的. 硬件故障 硬件 ...
- iOS的URL处理
前两天处理iOSapp过程中(我是用swift语言写的,资料较少),被一个“字符串”搞了一晚上的时间到第二天才处理好,在此记下,望见过此文的学生有一天遇到该情况能三分钟搞定不浪费时间: 先看如下代码 ...
- jquery.cookie() 方法的使用(读取、写入、删除)
一个轻量级的cookie 插件,可以读取.写入.删除 cookie. jquery.cookie.js 的配置 首先包含jQuery的库文件,在后面包含 jquery.cookie.js 的库文件. ...
- OpenMP对于嵌套循环应该添加多少个parallel for 分类: OpenMP C/C++ Linux 2015-04-27 14:48 53人阅读 评论(0) 收藏
一个原则是:应该尽量少的使用parallelfor, 因为parallel for也需要时间开销.即: (1)如果外层循环次数远远小于内层循环次数,内层循环较多时,将parallel for加在内层循 ...
- 在Ext JS 6中添加本地化包
我在官方论坛发的帖子终于有人恢复了,也终于知道如何添加本地化包了.在Ext JS 6中,Ext JS属于经典工具包,而本地化是包含在经典工具包中,因而在app.json中,要添加本地化包,必须在cla ...
- [solr] - SolrJ增删查
使用SolrJ进行对Solr的增.删.查功能. 参考引用: http://wiki.apache.org/solr/Solrj Eclipse中新建一个项目:TestSolr 其中SorlJ的Lib包 ...
- cg资讯网址
cg教程下载: http://cgpeers.com http://cgpersia.com http://bbs.ideasr.com/forum-328-1.html http://bbs.ide ...
- Linxu 安装Scala
在安装Scala的时候遇到以下错: Exception in thread "main" java.lang.NoClassDefFoundError: scala.tools.n ...
- git 强制回退服务器上的commit
假设你有3个commit如下: commit 3 commit 2 commit 1 其中最后一次提交commit 3是错误的,那么可以执行: git reset --hard HEAD~1 你会 ...