我的Python成长之路---第六天---Python基础(19)---2016年2月20日(晴)
shelve模块
shelve模块是pickle模块的扩展,可以通过key,value的方式访问pickle持久化保存的数据
持久化保存:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import shelvesw = shelve.open('shelve_test.pkl') # 创建shelve对象name = ['13', '14', '145', 6] # 创建一个列表dist_test = {"k1":"v1", "k2":"v2"}sw['name'] = name # 将列表持久化保存sw['dist_test'] = dist_testsw.close() # 关闭文件,必须要有sr = shelve.open('shelve_test.pkl')print(sr['name']) # 读出列表print(sr['dist_test']) # 读出字典sr.close() |
说明:
1、其实shelve模块其实就是pickle模块的一个扩展,可以直接用key来读取持久化保存的数据,而不用原生pickle一样通过持久化的顺序来一个个读取出来
2、
sw['name']里的name其实就是key也就是自定义的一个名字,读取的时候通过这个key就可以方便读取出来
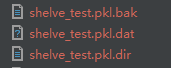
3、shelve_test.pkl并不是最终的文件名,shelve会自动生成如下三个后缀的文件
xml处理模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
我们先来,通过一张图认识一下xml文件的组成结构
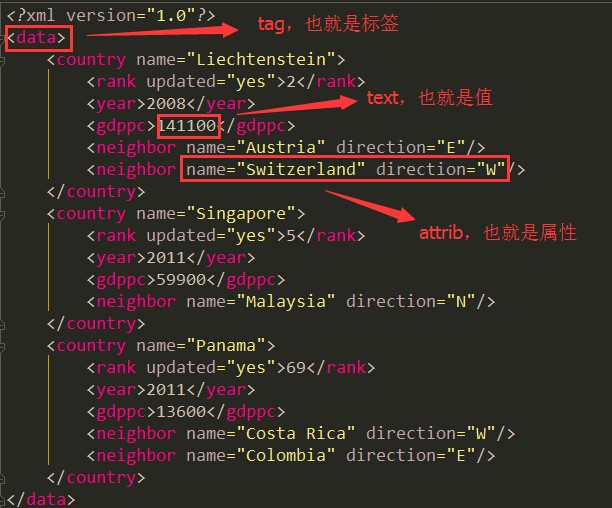
说明:
最外层的标签我们称之为跟标签、也就是root,其他标签都是子标签,也就是child
|
1
2
3
4
5
6
7
8
|
import xml.etree.ElementTree as ETtree = ET.parse('test.xml') # 读取xml文件,并以Element对象的形式保存root = tree.getroot() # 获取根for child in root: # 遍历root下的子标签 print(child.tag, child.attrib) # 打印标签名和属性 for i in child: print(i.tag, i.text, i.attrib) # 打印标签名值和属性 |
输出结果:
country {'name': 'Liechtenstein'}
rank 2 {'updated': 'yes'}
year 2008 {}
gdppc 141100 {}
neighbor None {'direction': 'E', 'name': 'Austria'}
neighbor None {'direction': 'W', 'name': 'Switzerland'}
country {'name': 'Singapore'}
rank 5 {'updated': 'yes'}
year 2011 {}
gdppc 59900 {}
neighbor None {'direction': 'N', 'name': 'Malaysia'}
country {'name': 'Panama'}
rank 69 {'updated': 'yes'}
year 2011 {}
gdppc 13600 {}
neighbor None {'direction': 'W', 'name': 'Costa Rica'}
neighbor None {'direction': 'E', 'name': 'Colombia'}
我们也可以通过标签名来获取某一类标签的内容
|
1
2
|
for node in root.iter('year'): # 仅遍历标签名为year的标签 print(node.tag, node.text, node.attrib) |
输出结果:
year 2008 {}
year 2011 {}
year 2011 {}
xml的常用操作
修改:
|
1
2
3
4
5
6
7
8
9
|
import xml.etree.ElementTree as ETtree = ET.parse('test.xml') # 读取xml文件,并以Element对象的形式保存root = tree.getroot() # 获取根for node in root.iter('year'): # 遍历year标签 node.text = str(int(node.text) + 1) # 将year标签的值+1,注意,读出来的标签的值都是字符串形式,注意数据类型转换 node.set('updated', 'yes') # 更新该标签tree.write('test_2.xml') # 将结果写到文件,可以写到源文件也可以写到新的文件中 |
删除:
|
1
2
3
4
5
6
7
8
9
10
|
import xml.etree.ElementTree as ETtree = ET.parse('test.xml') # 读取xml文件,并以Element对象的形式保存root = tree.getroot() # 获取根for country in root.findall('country'): # 遍历所有country标签 rank = int(country.find('rank').text) # 在country标签查找名为rank的纸标签 if rank > 50: # 判断如果rank标签的值大于50 root.remove(country) # 删除该标签tree.write('test_3.xml') |
说明:
iter方法用于查找的最终标签,也就是下面没子标签的标签,获取他的值和属性的
findall方法用于查找还有子标签的子标签,然后和用fandall返回的对象的find方法获取找到的标签的子标签
创建自己的xml文档
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import xml.etree.ElementTree as ETnew_xml = ET.Element("namelist") # 新建根节点,或者说xml对象name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"}) # 给新xml对象创建子标签age = ET.SubElement(name,"age",attrib={"checked":"no"}) # name标签在创建子标签age,attrib变量为属性sex = ET.SubElement(name,"sex")sex.text = '33' # 给标签赋值name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})age = ET.SubElement(name2,"age")age.text = '19'et = ET.ElementTree(new_xml) #生成文档对象et.write("test.xml", encoding="utf-8",xml_declaration=True) # 将xml对象保存到文件xml_declaration表示xml文档的声明ET.dump(new_xml) #打印生成的格式 |
ConfigParser模块
读取配置文件
|
1
2
3
4
|
import configparserconfig = configparser.ConfigParser() # 创建configparser对象config.read('example.ini') # 读取配置件print(config.sections()) # 获取所有的session |
输出结果
['dbs', 'server']
注意:
可以看到这里没有输出DEFAULT,因为在Python中DEFAULT session有特殊用途,相当于所有session的默认值,也就是当DEFAULT中定义了一个key和value,此时session中这个不存在的时候,这个key的值就是DEFAULT定义的value
例如
|
1
|
print(config['dbs']['name']) |
输出结果就是
www.qq.com
说明:
可以看到读取配置文件后的返回的对象有点类似于字典,可以通过key的方式将配置文件中的值一一取出来,甚至可以使用in关键字判断key是否存在
|
1
|
print('server' in config) |
输出结果
True
其他常用操作
读:
|
1
|
print(config.options('dbs')) # 获取某个session下的所有option,也就是key |
输出结果
['username', 'passord', 'host', 'name']
|
1
|
print(config.items('dbs')) # 获取某个session的键值列表,类似字典的items方法 |
输出结果
[('name', 'www.qq.com'), ('username', 'root'), ('passord', '123.com'), ('host', '127.0.0.1')]
|
1
|
print(config.get('dbs', 'host')) # 获取某个session下的某个option的值 |
输出结果
127.0.0.1
|
1
2
3
|
port = config.getint('server', 'port') # 获取某个session下的某个option的值,并以int的方式返回print(port)print(type(port)) |
类似的方法还有getfloat和getboolean方法,当然前提是配置文件中的值就是对应的类型,否则会报错
说明:
配置文件中yes、True、1、true等为真,也就是通过getboolean返回的是True,no、False、0、false等为假,也就是返回的是False
删除:
|
1
2
|
config.remove_option('dbs','host') # 删除optionconfig.remove_section('server') # 删除session |
我的Python成长之路---第六天---Python基础(19)---2016年2月20日(晴)的更多相关文章
- 我的Python成长之路---第六天---Python基础(18)---2016年2月20日(晴)
os模块 提供对操作系统进行调用的接口 >>> import os >>> os.getcwd() # 获取当前工作目录,类似linux的pwd命令 '/data/ ...
- 我的Python成长之路---第六天---Python基础(20)---2016年2月20日(晴)
一.面向对象基础 面向对象名词解释: 类(Class): 用来描述具有相同的属性和方法的对象的集合.它定义了该集合中每个对象所共有的属性和方法.对象是类的实例. 类变量:类变量在整个实例化的对象中是公 ...
- 【Python成长之路】Python爬虫 --requests库爬取网站乱码(\xe4\xb8\xb0\xe5\xa)的解决方法【华为云分享】
[写在前面] 在用requests库对自己的CSDN个人博客(https://blog.csdn.net/yuzipeng)进行爬取时,发现乱码报错(\xe4\xb8\xb0\xe5\xaf\x8c\ ...
- python成长之路——第六天
定义 Python 的 Class 比较特别,和我们习惯的静态语言类型定义有很大区别. 1. 使用一个名为 __init__ 的方法来完成初始化.2. 使用一个名为 __del__ 的方法来完成类似析 ...
- 【Python成长之路】python 基础篇 -- global/nonlocal关键字使用
1 课程起源 有一次在工作中编写python工具时,遇到一个 问题:从配置文件读取变量A后,无法在内存中把A的值改变成新的内容.为了解决"更新内存中变量"的这个问题,查找了一些帖子 ...
- 【Python成长之路】python 基础篇 -- 装饰器【华为云分享】
[写在前面] 有时候看到大神们的代码,偶尔会用到@来装饰函数.当时查了资料,大致了解装饰器一般用于在不改变原函数的基础上 ,对原函数功能进行修改/增强.使用场景是:日志级别设置.权限校验.性能测试等. ...
- (转)Python成长之路【第九篇】:Python基础之面向对象
一.三大编程范式 正本清源一:有人说,函数式编程就是用函数编程-->错误1 编程范式即编程的方法论,标识一种编程风格 大家学习了基本的Python语法后,大家就可以写Python代码了,然后每个 ...
- 【Python成长之路】装逼的一行代码:快速共享文件
[Python成长之路]装逼的一行代码:快速共享文件 2019-10-26 15:30:05 华为云 阅读数 335 文章标签: Python编程编程语言程序员Python开发 更多 分类专栏: 技术 ...
- 我的Python成长之路---第八天---Python基础(25)---2016年3月5日(晴)
多进程 multiprocessing模块 multiprocessing模块提供了一个Process类来代表一个进程对象 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ...
随机推荐
- C#实现 ffmpeg视频转码、播放
近来公司项目要求实现全景相机的视频截取,但是截取的视频需求转码上传.经过研究采用ffmpeg转码,奉上一个详细介绍的博文: 最简单的基于FFMPEG的转码程序 主要是转码的操作过程,能够实现了从相机获 ...
- iOS中Block介绍 基础
ios开发block的使用指南,以及深入理解block的内存管理,也适用于osx开发.讨论范围:block的使用,内存管理,内部实现.不包含的内容:gc arc下的block内存,block在c++中 ...
- sublime test3 使用技巧
sublimeText3使用技巧 常用快捷键 ctrl+d :选中光标处的文本单元,继续按ctrl+d选中相同文本单元 alt+F3 :功能和ctrl+d类似,用于批量修改相同文本 shift+↑ ↓ ...
- CodeForces 452C Magic Trick (排列组合)
#include <iostream> #include <cstdio> #include<cmath> #include<algorithm> us ...
- Java 网络编程(三) 创建和使用URL访问网络上的资源
链接地址:http://www.cnblogs.com/mengdd/archive/2013/03/09/2951877.html 创建和使用URL访问网络上的资源 URL(Uniform Reso ...
- strstr 的使用
Problem E: Automatic Editing Source file: autoedit.{c, cpp, java, pas} Input file: autoedit.in Outpu ...
- JS 获取浏览器窗口大小clientWidth、offsetWidth、scrollWidth
常用: JS 获取浏览器窗口大小 // 获取窗口宽度 if (windows.innerWidth) winWidth = windows.innerWidth; else if ((docume ...
- crt连接vitualbox中centos虚拟机
在virtalbox中安装了centos虚拟机后,在虚拟机中直接操作很是不方便,所以想用crt连接虚拟机, 1.打开virtualbox,设置-网络,网络连接2设置连接方式为“Bridged Adap ...
- win使用telnet到ubuntu下vim显示中文为乱码的解决方法~
1.几个路径: ubuntu: /etc/default/locale 相当于 centos:/etc/sysconfig/i18n vimrc的路径:① ~/.vimrc ② /etc/vi ...
- Delphi调试DLL 不能调试 不能进入调试 注意!!!
如何调试DLL,在这里就不再赘述了,但是,今天就碰到了一个特别奇怪的问题,参数设置正确,就是不能调试?? 通过上网查资料,发现了问题,注意: 1, 将Project主菜单的Project Option ...