6-3 如何解析简单的XML文档

元素节点、元素树
>>> from xml.etree.ElementTree import parse
>>> help(parse)
Help on function parse in module xml.etree.ElementTree: parse(source, parser=None)
help(parse)
>>> f = open(r'C:\视频\python高效实践技巧笔记\6数据编码与处理相关话题\linker_log.xml')
>>>
>>> et = parse(f) #et ElementTree的对象
>>> help(et.getroot)
Help on method getroot in module xml.etree.ElementTree: getroot(self) method of xml.etree.ElementTree.ElementTree instance
help(et.getroot)
>>> root = et.getroot() #获取根节点 是一个元素对象 >>> root
<Element 'DOCUMENT' at 0x2e87f90>
#此节点的属性
>>> root.tag #查看标签
'DOCUMENT' >>> root.attrib #查看属性,是一个字典,本例中有值,无值时为空
{'gen_time': 'Fri Dec 01 16:04:26 2017 '} >>> root.text #查看节点文本,是一个回车无自符串
'\n'
>>> root.text.strip() #将节点文本对 空白字符串过滤
''
>>> root.text.strip()
''
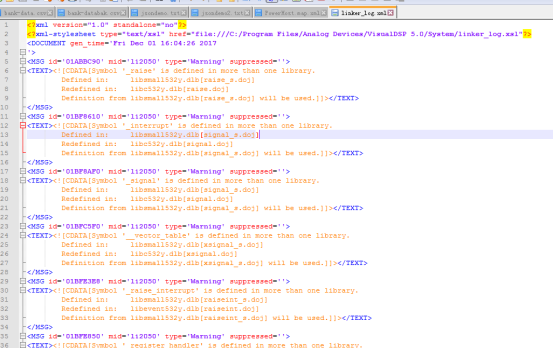
#root自身是一个可迭代对象,直接进行迭代遍历子元素
>>> for child in root:
print(child.get('id')) #child表示子元素 get()方法是获取某一属性。
输出结果
01ABBC90
01BF8610
01BF8AF0
01BFC5F0
01BFE3E8
01BFE850
01BFEAC8
01BFF128
01BFF2B0
01BFF4B8
01BFF730
01BFF960
01BFFB68
#通过find()、findall()、iterfind()只能找当前元素的直接子元素如本例中”root”只能找”MSG”而不能找”TEXT”
>>> root.find('MSG') #find()找到第一个碰到的元素
<Element 'MSG' at 0x2e87fd0>
>>> root.find('MSG')
<Element 'MSG' at 0x2e87fd0>
>>> root.findall('MSG') #find()找到所有的元素
[<Element 'MSG' at 0x2e87fd0>, <Element 'MSG' at 0x2e9f0d0>, <Element 'MSG' at 0x2e9f170>, <Element 'MSG' at 0x2e9f210>, <Element 'MSG' at 0x2e9f2b0>, <Element 'MSG' at 0x2e9f350>, <Element 'MSG' at 0x2e9f3f0>, <Element 'MSG' at 0x2e9f490>, <Element 'MSG' at 0x2e9f530>, <Element 'MSG' at 0x2e9f5d0>,
>>> root.find('TEXT') #“TEXT”是”MSG”的子元素,所以root直接find()找不到
>>>
>>> msg = root.find('MSG')
>>> msg.find('TEXT')
<Element 'TEXT' at 0x2e9f090>
#iterfind() 生成可迭代对表
>>> iterMsg = root.iterfind('MSG')
>>> for i in xrange(5):
x = iterMsg.next()
print x.get('id')
输出
01BF8610
01BF8AF0
01BFC5F0
01BFE3E8
01BFE850
>>> iterMsg = root.iterfind('MSG')
>>> i = 0
>>> for x in iterMsg:
print(x.get('id'))
i+=1
if(i ==5):
break
输出结果:
01ABBC90
01BF8610
01BF8AF0
01BFC5F0
01BFE3E8
#iter()可以迭代出所有元素的节点
>>> root.iter()
<generator object iter at 0x02ED3CD8>

#递归查找某一元素
>>> list(root.iter('TEXT'))

三、查找高级用法
1、“*”查找所有的节点
>>> root.findall('MSG/*') #查找MSG下的所有子节点,注意只能找其子节点而不能找其孙子节点

2、“.//”无论哪个层次下都能找到节点
>>> root.find('.//TEXT') #能找到
<Element 'TEXT' at 0x2e9f090>
>>> root.find('TEXT') #不能找到
>>>
3、“..”找到父层次的节点
>>> root.find('.//TEXT/..')
<Element 'MSG' at 0x2e87fd0>
4、“@”包含某一属性
>>> root.find('MSG[@name]') #没有包含name属性的
>>> root.find('MSG[@Type]') #没有包含Type属性的
>>> root.find('MSG[@type]') #存在包含type属性的,并返回
<Element 'MSG' at 0x2e87fd0>
5、属性等于特定值
>>> root.find('MSG[@id="01BFE3E8"]') #注意参数里的=号后面的字符串需要带引号
<Element 'MSG' at 0x2e9f2b0>
6、指定序号
>>> root.find("MSG[2]") #找第二个
<Element 'MSG' at 0x2e9f0d0>
>>> root.find("MSG[last()]") #找最后一个
<Element 'MSG' at 0x2ecdef0>
>>> root.find("MSG[last()-1]") #找倒数第二个
<Element 'MSG' at 0x2ecde30>
6-3 如何解析简单的XML文档的更多相关文章
- SAX解析和生成XML文档
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本人声明.否则将追究法律责任. 作者: 永恒の_☆ 地址: http://blog.csdn.net/chenghui031 ...
- 使用dom解析器对xml文档内容进行增删查改
直接添代码: XML文档名称(one.xml) <?xml version="1.0" encoding="UTF-8" standalone=" ...
- 用python批量生成简单的xml文档
最近生成训练数据时,给一批无效的背景图片生成对应的xml文档,我用python写了一个简单的批量生成xml文档的demo,遇见了意外的小问题,记录一下. 报错问题为:ImportError: No m ...
- Dom4j解析语音数据XML文档(注意ArrayList多次添加对象,会导致覆盖之前的对象)
今天做的一个用dom4j解析声音文本的xml文档时,我用ArrayList来存储每一个Item的信息,要注意ArrayList多次添加对象,会导致覆盖之前的对象:解决方案是在最后将对象添加入Array ...
- WSDL 文档-一个简单的 XML 文档
WSDL 文档是利用这些主要的元素来描述某个 web service 的: <portType>-web service 执行的操作 <message>-web service ...
- MVC模式简单的Xml文档解析加Vue渲染
前端代码: <script src="~/Js/jquery-3.3.1.min.js"></script> <script src="~/ ...
- Java DOM解析器 - 修改XML文档
这是我们需要修改的输入XML文件: 1 2 3 4 5 6 7 8 9 10 11 12 <?xml version="1.0" encoding="UTF-8&q ...
- Java DOM解析器 - 查询XML文档
这是需要我们查询的输入XML文件: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <?xml version="1.0"?> ...
- iOS网络编程笔记——XML文档解析
今天利用多余时间研究了一下XML文档解析,虽然现在移动端使用的数据格式基本为JSON格式,但是XML格式毕竟多年来一直在各种计算机语言之间使用,是一种老牌的经典的灵活的数据交换格式.所以我认为还是很有 ...
随机推荐
- maven项目解决pom.xml头部 http://maven.apache.org/xsd/maven-4.0.0.xsd报错的问题
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/qq_36611526/article/d ...
- 线程优先级队列( Queue)
Python的Queue模块中提供了同步的.线程安全的队列类,包括FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue,和优先级队列PriorityQueue.这些队列都实现 ...
- javaweb上传大文件的问题
总结一下大文件分片上传和断点续传的问题.因为文件过大(比如1G以上),必须要考虑上传过程网络中断的情况.http的网络请求中本身就已经具备了分片上传功能,当传输的文件比较大时,http协议自动会将文件 ...
- Sublime Text3的Package Control安装教程,及报错解决There Are No Packages Available For Installation
一.Package Control的安装 Sublime 有很多插件,这些插件为我们写python代码提供了非常强大的功能,这些插件需要单独安装.而安装这些插件最方便的方法就是通过Package Co ...
- sh_03_第1个函数
sh_03_第1个函数 # 注意:定义好函数之后,之表示这个函数封装了一段代码而已 # 如果不主动调用函数,函数是不会主动执行的 def say_hello(): print("hello ...
- [BZOJ4804]欧拉心算:线性筛+莫比乌斯反演
分析 关于这道题套路到不能再套路了没什么好说的,其实发这篇博客的目的只是为了贴一个线性筛的模板. 代码 #include <bits/stdc++.h> #define rin(i,a,b ...
- [CSP-S模拟测试]:电压机制(图论+树上差分)
题目描述 科学家在“无限神机”($Infinity\ Machine$)找到一个奇怪的机制,这个机制有$N$个元件,有$M$条电线连接这些元件,所有元件都是连通的.两个元件之间可能有多条电线连接.科学 ...
- 监听浏览器返回键、后退、上一页事件(popstate)操作返回键
在WebApp或浏览器中,会有点击返回.后退.上一页等按钮实现自己的关闭页面.调整到指定页面.确认离开页面或执行一些其它操作的需求.可以使用 popstate 事件进行监听返回.后退.上一页操作. 一 ...
- nodejs 文件操作
前言: nodejs 自带的文件操作的模块 fs 就是对文件的增删查改: 就像我们用的服务器,我们没有办法在运行的文件上进行一直的修改,因为他不向浏览器,刷新后我们的文件会自己修改: 如果想要更改我 ...
- Redis cluster Specification 笔记
ref: http://redis.io/topics/cluster-spec 1. 设计目标: 高性能:线性扩展:不支持合并操作:写操作安全:小概率丢弃:(对于每个key)只要有一个slave工作 ...