爬虫(六)——存储库(一)MongoDB存储库
存储库——MongoDB
一、安装MongoDB 4.0
1、安装
(1)可以去官网下载(我是直接选择msi文件的)
https://www.mongodb.com/download-center
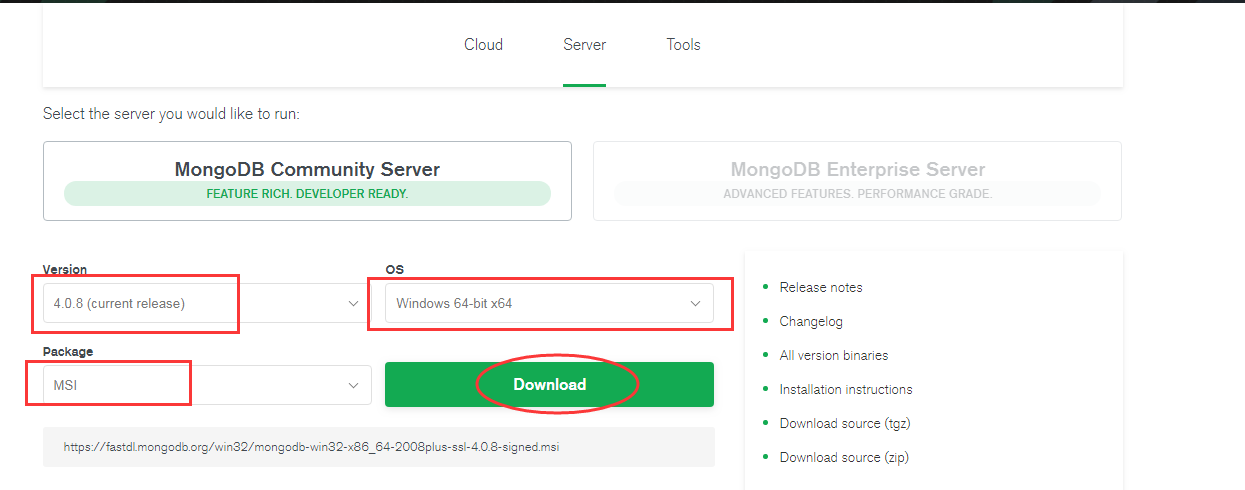
(2)运行文件,可以自定义(custom)安装,注意安装的时候一定要把勾去掉 “Install MongoDB Compass”方便操作,之后一直下一步
安装完成以后,文件目录 如下图
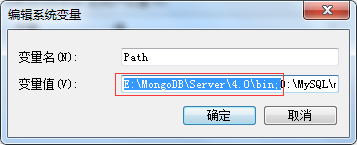
(3)添加安装MongoDB的bin目录到环境变量中
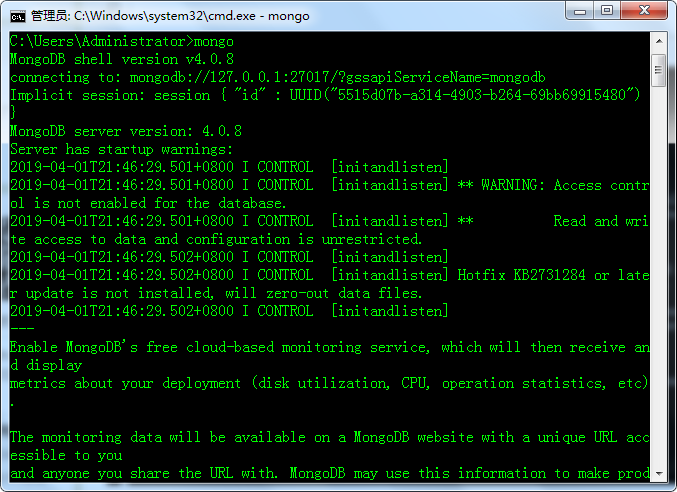
(4)测试,cmd打开控制台,然后输入mongo回车,可以进入MongoDB的shell中,输入show dbs可以看到数据库。表示装成功
2、修改数据库文件和日志保存位置设置(可不改)
MongoDB的数据保存位置和日志位置与其服务的配置文件 mongod.cfg有关,该文档可在 “安装目录\bin"下找到。里面记录了dbpath(数据库保存位置),logpath(日志文件保存位置),还有连接网络bind_ip等。
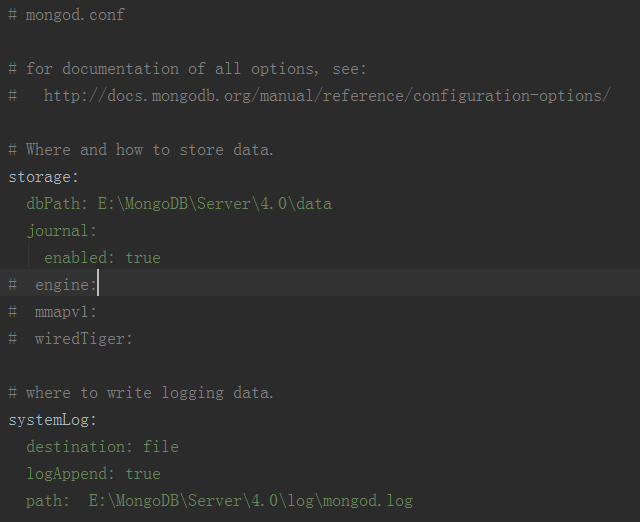
这里MongoDB安装在E盘,但是想将数据库和日志文件等保存在其他盘,所以修改dbpath和logpath成自己想要的路径就好
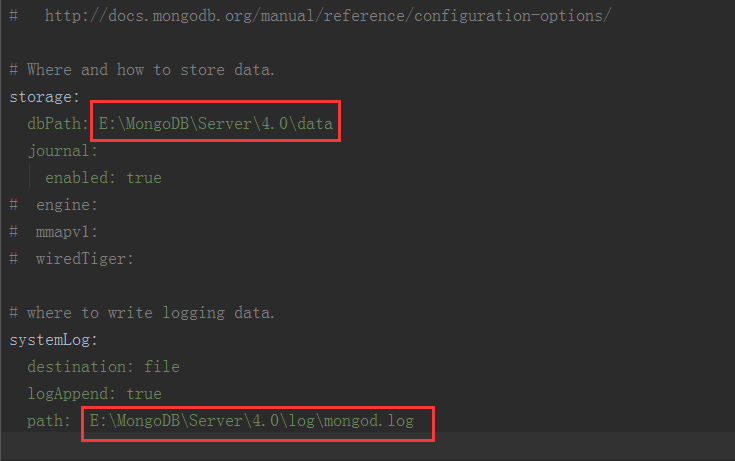
修改完以后要重启服务
net stop MongoDB
net start MongoDB
3、账户管理、远程服务
安装完成后MongoDB默认只能本机访问,并且不需要密码;下面我们添加用户并开启远程服务
(1)打开cmd输入mongo进入MongoDB;进入admin数据库(创建新的数据库)
> use admin
(2)在库中创建用户
db.createUser({
user: "root",
pwd: "123",
roles: [
{role: "root",db: "admin"}
]
})
# 亦可以一个用户对多个数据库管理
| 角色类型 | 权限级别 |
|---|---|
| 普通用户角色 | read、readWrite |
| 数据库管理员角色 | dbAdmin、dbOwner、userAdmin |
| 集群管理员角色 | clusterAdmin、clusterManager、clusterMonitor、hostManager |
| 数据库备份与恢复角色 | backup、restore |
| 所有数据库角色 | readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、dbAdminAnyDatabase |
| 超级用户角色 | root |
| 核心角色 | __system |
(3)修改允许远程连接
修改默认配置文件bin/mongod.cfg中的bingIp中的127.0.0.1为0.0.0.0,这里可以实现其他网段地址的连接;(千万不要将这句注释,否则服务可能无法启动)
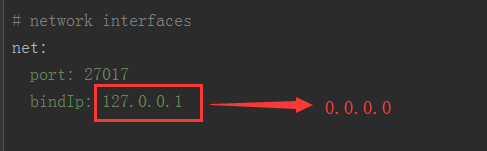
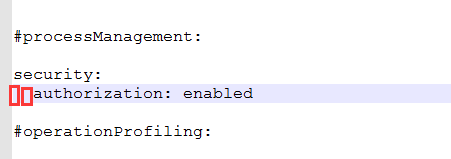
将#security:的注释去掉,然后添加authorization: enabled ,注意authorization前面要有两个空格
(4)重启数据库
net stop MongoDB
net start MongoDB
(5)测试
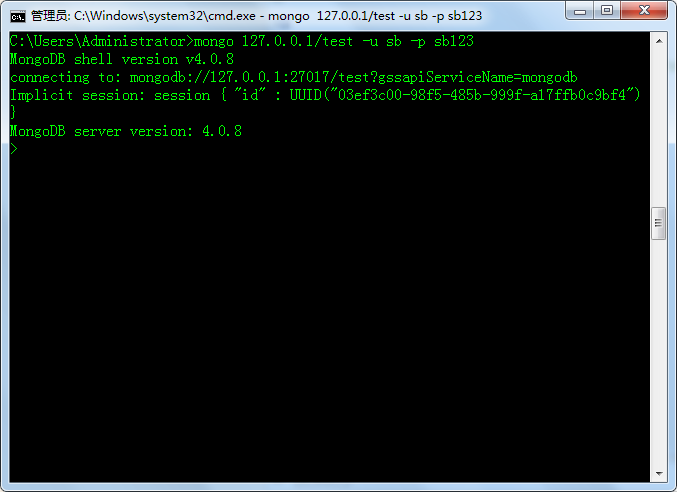
如果测试结果如下,则表示用户设置成功
# 登录方式一
mongo 127.0.0.1:27017/admin(数据库名字) -u root(用户名) -p 123(密码)
# 登录方式二
> mongo
> use test
>db.auth("sb","sb123") # 必须要用双引号
# 登录方式三
mongo --port 27017 -u "root" -p "123" --authenticationDatabase "admin"
三、MongoDB数据库操作
1、对库操作
# 1.增加数据库
use 数据库名 # 存在则切换到该数据库,不存在则新建数据库
# 2.查看数据库
show dbs
# 3.删除数据库
use test # 先切换到要删的库下
db.dropDatabase() # 删除当前库
# 帮助查看所有库相关操作-- db.help()
db.help()
2、对集合操作——类似表
use test # 先切换到数据库下
# 1.新增集合
db.user # 创建user表
# 2.查看集合
show tables
# 或者 show colletions
# 3.删除集合
db.user.drop()
# 帮助查看所有集合相关操作-- db.(集合名).help()
db.user.help()
3、对文档操作—— 类似记录
MongoDB中存储的文档必须有一个"_id"键。这个键的值可以是任意类型,默认是个ObjectId对象。
在一个集合里,每个文档都有唯一的“_id”,确保集合里每个文档都能被唯一标识。
不同集合"_id"的值可以重复,但同一集合内"_id"的值必须唯一
ObjectId是"_id"的默认类型,ObjectId采用12字节的存储空间,是一个由24个十六进制数字组成的字符串
0|1|2|3| 4|5|6| 7|8 9|10|11
时间戳 机器 PID 计数器
如果插入文档时没有"_id"键,系统会自帮你创建 一个
(1)增加文档—— insert()
use test # 先切换到数据库下
db.user.insert({'_id':1,'name':'tom'}) # id要用_id作为key
# 或者数据量较大时使用变量:
user0={
"name":"egon",
"age":10,
'hobbies':['music','read','dancing'],
'addr':{
'country':'China',
'city':'BJ'
}
}
db.test.insert(user0)
# 插入多条数据 ---- insertMany([...])
user1={
"_id":1,
"name":"alex",
"age":10,
'hobbies':['music','read','dancing'],
'addr':{
'country':'China',
'city':'weifang'
}
}
user2={
"_id":2,
"name":"wupeiqi",
"age":20,
'hobbies':['music','read','run'],
'addr':{
'country':'China',
'city':'hebei'
}
}
db.user.insertMany([user1,user2])
# save() 方法
use test
db.save({'_id':1,'name':'tom'}) # 有相同的id,则覆盖原数据;没有该id,则新增数据
db.save({'a':123}) # 不指定id,和新增数据相同
(2)查看文档—— find()
use test
# 1.查找所有
db.user.find()
# 按条件查询
#(1)比较运算
!= ---- {'$ne':3} # 不等于3
> ----- {'$gt':2} # 大于2
< ---- {'$lt':2} # 小于2
>= ---- {'$gte':4} # 大于等于
>= ---- {'$lte':4} # 小于等于
db.user.find({'_id':3})
db.user.find({'_id':{'$ne':3}}) # id不等于3
db.user.find({'name':{'$ne':'Tom'}}) # 名字不是Tom
# (2)逻辑运算 and not or
and ----- {'$and':[....]}
not ----- {'$not':...}
or ----- {'$or':[....]}
# id>=2 and id<=4
db.user.find({'_id':{"$gte":2,"$lt":4}})
# id >= 2 and age < 40;
db.user.find({"_id":{"$gte":2},"age":{"$lt":40}})
# 或者
db.user.find({
'$and':[
{"_id":{"$gte":2}},
{"age":{"$lt":40}}
]
})
# id >= 5 or name = "alex";
db.user.find({
"$or":[
{'_id':{"$gte":5}},
{"name":"alex"}
]
})
# id % 2=1 id取模2等于1
db.user.find({'_id':{"$mod":[2,1]}})
# 取反 取id为奇数
db.user.find({'_id':{
'$not':{
'$mod':[2,0]
}
}})
# (3)成员运算 in,not in
in ----- {'$in':[....]}
not in -------{'$nin':[]}
db.user.find({'name':{'$in':['ton','eton']}})
# (4)正则匹配 regexp
regexp ----- /正则表达/i
i 忽略大小写
m 多行匹配模式
x 忽略非转义的空白字符
s 单行匹配模式
db.user.find({'name':/^T.*?(g|n)/i})
# (5)查询指定字段
1 --- 表示需要
0 ---- 不需要,默认
# 只要name,age
db.user.find(
{'name':'Tom'},
{'name':1,
'age':1,
'_id':0
}
)
# (6)查询数组
既有... 又有... ----- {'$all':[...,...]}
第n个 ---- key.n
要n个 ----- {'$slice':n} # -n表示后n个
A下的B是C ----- {'A.B':C}
# 查看有dancing爱好的人
db.user.find({'hobbies':'dancing'})
# 查看既有dancing爱好又有tea爱好的人
db.user.find({
'hobbies':{
"$all":['dancing','tea']
}
})
# 查看第4个爱好为tea的人
db.user.find({"hobbies.3":'tea'})
# 查看所有人最后两个爱好
db.user.find({},{'hobbies':{"$slice":-2},"age":0,"_id":0,"name":0,"addr":0})
# 查看所有人的第2个到第3个爱好
db.user.find({},{'hobbies':{"$slice":[1,2]},"age":0,"_id":0,"name":0,"addr":0})
# (7)排序
sort()
1 ----- 升序
-1 ----- 降序
# 排序:--1代表升序,-1代表降序
db.user.find().sort({"name":1,})
db.user.find().sort({"age":-1,'_id':1})
# (8)分页
limit ----- 取几个
skip ------ 跳过几个再开始取
# 跳过两个以后,取一个
db.user.find().limit(1).skip(2)
# (9)获取数量
count()
db.user.count({'age':{'$gte':20}})
# (10)key的值为null或者没有这个key
db.t2.find({'b':null})
(3)修改文档——update()
update() 方法用于更新已存在的文档。语法格式如下:
db.collection.update(
<query>, # 查询条件,条件为空,表示所有文档
<update>,
{
upsert: <boolean>, # 默认为false,代表如果不存在update的记录不更新也不插入,设置为true代表插入
multi: <boolean>, # 默认为false,代表只更新找到的第一条记录,设为true,代表更新找到的全部记录
writeConcern: <document>
}
)
参数说明:对比update db1.t1 set name='EGON',sex='Male' where name='egon' and age=18;
# 1.覆盖式修改
db.user.update({
{'name':'tom'},
{'sex':'male','phone':'123123'}
})
# 2.局部修改 ---- {'$set':{修改的数据}}
db.user.update({
{'name':'tom'},
{'$set':{'sex':'male','phone':'123123'}}
})
# 3.批量修改
db.user.update({
{'name':'tom'},
{'$set':{'sex':'male','phone':'123123'}},
{'multi':True}
})
# 4.有则修改,无则新增
db.user.update({
{'name':'tom'},
{'$set':{'sex':'male','phone':'123123'}},
{'multi':True,
'upsert':True
}
})
# 5.嵌套数据修改 ---- “ . ”号
# 城市的国家修改,第二个爱好修改
db.user.update({
{},
{'$set':{'city.country':'China','hobbies.1':'eat'}},
{'multi':True,
'upsert':True
}
})
# 增加1 ------ {'$inc'}
db.user.update(
{},
{
"$inc":{"age":1}
},
{
"multi":true
}
)
# 添加删除数组内元素 ---- $push $pop $pull
# 1.增加爱好
db.user.update({"name":"yuanhao"},{"$push":{"hobbies":"read"}})
# 2.为名字为yuanhao的人一次添加多个爱好tea,dancing
db.user.update(
{"name":"yuanhao"},
{
"$push":{
"hobbies":{
"$each":["tea","dancing"]
}
}
}
)
# 3.删除数组元素 ---- $pop() 两头删
-1 ---- 从头开始删1个
1 ----- 从末尾开始删1一个
db.user.update(
{"name":"yuanhao"},
{"$pop":{"hobbies":1}}
)
# 4.按照条件删 ----- pull() 根据条件删
# 删除所有人的read爱好
db.user.update(
{'addr.country':"China"},
{"$pull":{"hobbies":"read"}},
{
"multi":true
}
)
(4)删除文档——deleteOne() / deleteMany()
# 1、删除多个中的第一个
db.user.deleteOne({ 'age': 8 })
# 2、删除国家为China的全部
db.user.deleteMany( {'addr.country': 'China'} )
# 3、删除全部
db.user.deleteMany({})
四、MongoDB基本数据类型
MongoDB在保留了JSON基本键/值对特性的基础上,添加了其他一些数据类型。在不同的编程语言下,这些类型的确切表示有些许差异。
# 1、null:用于表示空或不存在的字段
d={'x':null}
# 2、布尔型:true和false
d={'x':true,'y':false}
# 3、数值
d={'x':3,'y':3.1415926}
# 4、字符串
d={'x':'egon'}
# 5、日期
d={'x':new Date()}
d.x.getHours()
# 6、正则表达式
d={'pattern':/^egon.*?nb$/i}
正则写在//内,后面的i代表:
i 忽略大小写
m 多行匹配模式
x 忽略非转义的空白字符
s 单行匹配模式
# 7、数组
d={'x':[1,'a','v']}
# 8、内嵌文档
user={'name':'egon','addr':{'country':'China','city':'YT'}}
user.addr.country
# 9、对象id:是一个12字节的ID,是文档的唯一标识,不可变
d={'x':ObjectId()}
五、聚合
1、筛选—— $match
aggregate()
$match # 条件,和where,having类似
$group # 分组,和group by类似
$字段名 # 表示取该字段的值
# select * from db1.emp where id > 3 group by post having avg(salary) > 10000;
db.emp.aggregate(
{"$match":{"_id":{"$gt":3}}},
{"$group":{"_id":"$post",'avg_salary':{"$avg":"$salary"}}}, # 这个_id表示分组依据
{"$match":{"avg_salary":{"$gt":10000}}}
)
2、投射—— $project
- 将一些字段不需要的去掉,额外需要的新增
- 投射既可以在起始时使用,也可以在中间使用
{"$project":{"要保留的字段名":1,"要去掉的字段名":0,"新增的字段名":"表达式"}}
# 表达式之数学表达式
{"$add":[expr1,expr2,...,exprN]} # 相加
{"$subtract":[expr1,expr2]} # 第一个减第二个
{"$multiply":[expr1,expr2,...,exprN]} # 相乘
{"$divide":[expr1,expr2]} # 第一个表达式除以第二个表达式的商作为结果
{"$mod":[expr1,expr2]} # 第一个表达式除以第二个表达式得到的余数作为结果
# 表达式之日期表式:
{"$year":"$date"}
{"$month":"$date"}
{"$week":"$date"}
{"$dayOfMonth":"$date"}
{"$dayOfWeek":"$date"}
{"$dayOfYear":"$date"}
{"$hour":"$date"}
{"$minute":"$date"}
{"$second":"$date"}
# 获取员工的名字和工作年限
db.emp.aggregate(
{"$project":{"name":1,"hire_year":{"$year":"$hire_date"}}}
)
# 字符串表达式
{"$substr":[字符串/$值为字符串的字段名,起始位置,截取几个字节]}
{"$concat":[expr1,expr2,...,exprN]} # 指定的表达式或字符串连接在一起返回,只支持字符串拼接
{"$toLower":expr}
{"$toUpper":expr}
# 所有人的名字变大写
db.emp.aggregate(
{"$project":{'new_name':{'$toUpper':'$name'}}}
)
# 投射示例
# 获取员工的name、post、目前年龄
db.emp.aggregate(
{"$project":{
"name":1,
"post":1,
"new_age":{"$add":["$age",1]}
}
})
3、分组—— $group
{"$group":{"_id":分组字段,"新的字段名":聚合操作符}} # 这里的_id表示根据什么分组
# 分组后聚合得结果,类似于sql中聚合函数的聚合操作符:$sum、$avg、$max、$min、$first、$last
# select post,max(salary) from db1.emp group by post;
db.emp.aggregate({"$group":{"_id":"$post","max_salary":{"$max":"$salary"}}})
# 求每个部门的人数
db.emp.aggregate({"$group":{"_id":"$post","count":{"$sum":1}}})
4、排序— $sort,限制— $limit,跳过— $skip
{"$sort":{"字段名":1,"字段名":-1}} # 1升序,-1降序
{"$limit":n} # 限制,取n条数据
{"$skip":n} # 跳过多少个文档
# 取平均工资最高的前两个部门,先按平均公司排序,若工资一样再按id排序
db.emp.aggregate(
{
"$group":{"_id":"$post","平均工资":{"$avg":"$salary"}}
},
{
"$sort":{"平均工资":-1, "_id":1}
},
{
"$limit":2
}
)
六、随机取几个数据
$sample
# 随机取3个文档
db.users.aggregate(
[ { $sample: { size: 3 } } ]
)
七、可视化工具
八、python中操作MongoDB
from pymongo import MongoClient # pip3 install pymongo
# 1、链接
client=MongoClient('mongodb://root:123@localhost:27017/')
# client = MongoClient('localhost', 27017)
# 2、use 数据库,切换到库
db=client['db2'] # 等同于:client.db1
# print(db.collection_names())
# 3、查看库下所有的集合
print(db.collection_names(include_system_collections=False))
# 4、创建集合,切换到表
table_user=db['userinfo'] `# 等同于:db.user
# 5、插入文档
import datetime
user0={
"_id":1,
"name":"egon",
"birth":datetime.datetime.now(),
"age":10,
'hobbies':['music','read','dancing'],
'addr':{
'country':'China',
'city':'BJ'
}
}
user1={
"_id":2,
"name":"alex",
"birth":datetime.datetime.now(),
"age":10,
'hobbies':['music','read','dancing'],
'addr':{
'country':'China',
'city':'weifang'
}
}
# res=table_user.insert_many([user0,user1]).inserted_ids
# print(res)
# print(table_user.count())
# 6、查找
# from pprint import pprint#格式化细
# pprint(table_user.find_one())
# for item in table_user.find():
# pprint(item)
# print(table_user.find_one({"_id":{"$gte":1},"name":'egon'}))
# 7、更新
table_user.update({'_id':1},{'name':'EGON'})
# 8、传入新的文档替换旧的文档
table_user.save(
{
"_id":2,
"name":'egon_xxx'
}
)
爬虫(六)——存储库(一)MongoDB存储库的更多相关文章
- 【爬虫】把抓到数据存起来——爬虫绝配mongodb
[爬虫]把抓到数据存起来——爬虫绝配mongodb 视频地址 抓取数据的方法,前面的课程该讲的都已经讲了,爬取下来数据只是第一步,第二步就是要先存起来.我们最容易想到的就是存文件里喽,python写文 ...
- 浩瀚技术团队... 安卓智能POS移动PDA开单器 开单器 进销存系统 进销存系统
浩瀚技术团队... 智能POS移动PDA开单器 开单器 进销存系统 进销存系统 点餐 会员管理 会员管理 深度解读 手机APP移动办公到底是什么? 快速打单POS·不仅仅是快那么简单!
- 孤荷凌寒自学python第六十六天学习mongoDB的基本操作并进行简单封装5
孤荷凌寒自学python第六十六天学习mongoDB的基本操作并进行简单封装5并学习权限设置 (完整学习过程屏幕记录视频地址在文末) 今天是学习mongoDB数据库的第十二天. 今天继续学习mongo ...
- 孤荷凌寒自学python第六十三天学习mongoDB的基本操作并进行简单封装2
孤荷凌寒自学python第六十三天学习mongoDB的基本操作并进行简单封装2 (完整学习过程屏幕记录视频地址在文末) 今天是学习mongoDB数据库的第九天. 今天继续学习mongoDB的简单操作, ...
- 94、存储库之MongoDB、mysql
本篇导航: 简介 MongoDB基础知识 安装 基本数据类型 CRUD操作 其它 存储库之mysql 一.简介 MongoDB是一款强大.灵活.且易于扩展的通用型数据库1.易用性 MongoDB是 ...
- 存储库之MongoDB、mysql
本篇导航: 简介 MongoDB基础知识 安装 基本数据类型 CRUD操作 其它 存储库之mysql 一.简介 MongoDB是一款强大.灵活.且易于扩展的通用型数据库1.易用性 MongoDB是 ...
- 04 存储库之mongodb
MongoDB 一 简介 MongoDB是一款强大.灵活.且易于扩展的通用型数据库1.易用性 MongoDB是一个面向文档(document-oriented)的数据库,而不是关系型数据库.不采用 ...
- 存储库之——MongoDB
阅读目录 一 简介 二 MongoDB基础知识 三 安装 四 基本数据类型 五 CRUD操作 六 可视化工具 七 pymongo 一 简介 MongoDB是一款强大.灵活.且易于扩展的通用型数据库1. ...
- 存储库之mongodb,redis,mysql
一.简介 MongoDB是一款强大.灵活.且易于扩展的通用型数据库 MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统. 在高负载的情况下,添加更多的节点,可以保证服务器性 ...
随机推荐
- 【CF321E】+【bzoj5311】贞鱼
决策单调性 + WQS二分 我们首先列出转移式: \(f[i]=Min(f[j]+Sum[j+1 , i])\) 首先我们考虑如果让一段区间的小鱼在一起的代价怎么预处理,我们可以对于一个上三角矩阵求个 ...
- C#中ComboBox动态绑定赋值
http://www.crifan.com/csharp_combobox_data_dynamic_binding/ C#中,已有一个List,想要动态的,绑定到ComboBox中. [解决过程] ...
- 构建LNMP+memcached服务
通过PHP页面实现对memcached服务器的数据操作,实现以下目标: - 为PHP安装memcache扩展 - 创建PHP页面,并编写PHP代码,实现对memcached的数据操作 环境:部署LNM ...
- [sql 注入] 注入类型
基于整型的注入: url:http://localhost/?id=12 拼接sql:$sql = "select * from user where id = {$_GET['id']}& ...
- AOP技术介绍--(引言)
软件设计因为引入面向对象思想而逐渐变得丰富起来.“一切皆为对象”的精义,使得程序世界所要处理的逻辑简化,开发者可以用一组对象以及这些对象之间的关系将软件系统形象地表示出来.而从对象的定义,进而到模块, ...
- 未来HTML5的发展前景如何?黑客专家是这样回答的
如果你想进军IT行业,如果你准备好掌握一项新技术,那么就选择HTML5.近日,我们采访了国内知名网络黑客安全专家郭盛华,帮助您了解当今最重要的技术.在本篇文章中,黑客安全专家郭盛华回答了有关HTML5 ...
- HDU 1373 XYZZY (spfa的特殊用法)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1317 题目大意:有n个房间,编号1-n,房间之间有单向门连接.某人初始位于1号房间,且具有100点能量 ...
- hdu 1693 : Eat the Trees 【插头dp 入门】
题目链接 题意: 给出一个n*m大小的01矩阵,在其中画线连成封闭图形,其中对每一个值为1的方格,线要恰好穿入穿出共两次,对每一个值为0的方格,所画线不能经过. 参考资料: <基于连通性状态压缩 ...
- OPTIONS请求后台处理 跨域Filter
import cn.hutool.http.Method; import org.springframework.web.filter.OncePerRequestFilter; import jav ...
- Flask学习笔记02之配置文件
1. Flask默认的配置 Flask实例中包含了它的配置信息 #实例化一个Flask对象 app = Flask(__name__) # 打印默认配置信息 print(app.config) 打印结 ...