函数进阶之结合tornado
一、本篇博文内容
、协程函数
、面向过程编程
、递归和二分法
二、协程函数
协程函数:就是使用了yield表达式形式的生成器
首先函数的传参有几种?
三种:
1、实参形参传参
2、闭包的形式传参
3、就是通过yield的方式传参。好处:不用重复的申请局部内存空间
yield的表达式形式的应用
def eater(name):
print("%s start to eat" %name) #pyrene
while True:
food=yield
print("%s eat %s"%(name,food)) a_g=eater("pyrene")
print(a_g)
print(next(a_g)) #因为这里执行yield的返回的结果,yield后面为空所以这里为none
print(next(a_g)) #这里执行了两步,所以结果为两个
分析:
首先这是一个生成器。
执行print(a_g)就会的到一个生成器<generator object eater at 0x00000160E546DFC0>
然后执行第一个print(next(a_g)) 得到的结果为
pyrene start to eat
None
这是因为执行的时候next把name “pyrene”传递过来给了
print("%s start to eat" %name) =pyrene start to eat
之后继续往下执行,执行到yied的时候停止,并且把yied的返回值拿到,为空
然后执行第二个print(next(a_g)) 得到的结果为
pyrene eat None
None
因为这里执行food=yield,然后往下执行,由于这里是个死循环,所以又重新回到了yield。
yield的传参
先看下面代码:
def eater(name):
print("%s start to eat" %name)
food_list=[]
while True:
food=yield food_list
food_list.append(food)
print("%s eat %s"%(name,food)) a_g=eater("pyrene") #拿到生成器
next(a_g) #等同于alex_g.send(None)
print("=========")
# a_g.send("noodles")
print(a_g.send("noodles")) 执行结果:
pyrene start to eat
=========
pyrene eat noodles
['noodles']
如果满足yield传参需要有两个阶段:
第一阶段:必须初始化,保证生成器能够暂停初始化的位置
也就是
next(a_g)
第二阶段:给yield传值
print(a_g.send("noodles"))#send会把括号中的参数传递给yield,然后赋值给food
这里解释说明:
1、先给当前暂停位置的yield传值
2、继续往下执行直到遇到下一个yield,然后返回yiled的结果
例子:
1、 下面是tornado的协程原理例子
from tornado import gen
@gen.coroutine
def fetch_coroutine(url):
http_client = AsyncHTTPClient()
response = yield http_client.fetch(url)
return response.body
具体细节我会在后续的源码解析中一步一步的分析
2、实现一个单一请求的协程
def eater(name):
print("%s start to eat" %name)
food_list=[]
while True:
food=yield food_list
food_list.append(food)
print("%s eat %s"%(name,food)) def producer():
a_g=eater("pyrene")
next(a_g)
while True:
food=input(">>").strip()
if not food:continue
print(a_g.send(food))
producer()
上面如何解决初始化的问题呢?
思路:
'''
写一个装饰器解决初始化的问题
1、首先写出装饰器的结构
def init(func):
def wrapper(*args,**kwargs):
g=func(*args,**kwargs)
return g
return wrapper
2、然后把功能加到装饰器中 '''
如下:
def init(func):
def wrapper(*args,**kwargs):
g=func(*args,**kwargs)
next(g)
return g
return wrapper @init
def eater(name):
print("%s start to eat" %name)
food_list=[]
while True:
food=yield food_list
food_list.append(food)
print("%s eat %s"%(name,food))
a_g=eater("pyrene")
print(a_g.send("noodles"))
3、多个请求的协程
import random
import time
from tornado import gen
from tornado.ioloop import IOLoop
@gen.coroutine
def get_url(url):
wait_time = random.randint(, )
yield gen.sleep(wait_time)
print('URL {} took {}s to get!'.format(url, wait_time))
raise gen.Return((url, wait_time))
@gen.coroutine
def process_once_everything_ready():
before = time.time()
coroutines = [get_url(url) for url in ['URL1', 'URL2', 'URL3']]
result = yield coroutines
after = time.time()
print(result)
print('total time: {} seconds'.format(after - before))
if __name__ == '__main__':
print("First, process results as they come in:")
IOLoop.current().run_sync(process_as_results_come_in)
面向过程编程
提到面向过程编程,可能都会想到函数,。如果是这样的话,那么就不怎么全面了
面向过程:核心就是过程两个字,过程即解决问题的步骤
看下面例子:
要求实现grep -rl "error" /dir 这样的小程序
代码实现如下:
目录结构如下:
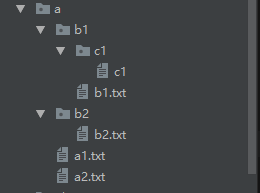
然后在
a1.txt a2.txt b1.txt文件中有包含若干个error
#第一阶段:找到所有文件的绝对路径 拿到文件和文件的父 级目录就是绝对路径
import os
def init(func):
def wrapper(*args,**kwargs):
g=func(*args,**kwargs)
next(g)
return g
return wrapper
@init
def search(target):
while True:
filepath=yield
g=os.walk(filepath)
for pardir,_,files in g:
for file in files:
abspath=r"%s\%s"%(pardir,file)
target.send(abspath)
# g=search()
# g.send(r"F:\a")
#第二阶段:打开文件
@init
def opener(target):
while True:
abspath=yield
with open(abspath,"rb") as f:
target.send((abspath,f)) # g = search(opener())
# g.send(r"F:\a")
#第三阶段:循环读出每一行的内容
@init
def cat(target):
while True:
abspath,f=yield #这里应该把文件和路径都传输过来 (abspath,f)
for line in f:
res=target.send((abspath,line))
if res:break
# g = search(opener(cat()))
# g.send(r"F:\a")
#第四阶段:过滤
@init
def grep(pattern,target):
tag=False #通过上面返回值去重操作
while True:
abspath,line=yield tag
tag=False
if pattern in line:
target.send(abspath)
tag=True
# g = search(opener(cat(grep("error"))))
# g.send(r"F:\a")
#打印该行属于的文件名
@init
def printer():
while True:
abspath=yield
print(abspath)
g = search(opener(cat(grep("error".encode("utf-8"),printer()))))
g.send(r"C:\Users\Administrator\PycharmProjects\T4\app.py")
解析:
首先分析参数:
-r 递归的去找所有的目录
-l 列出文件名,这里是列出包含error的文件名
上面是查找目录中所有的文件中包含error的文件
然后就是os模块中的walk的使用:
g=os.walk(文件路径) --》生成器
next(g)=([父目录],[子目录文件夹],[文件]) 返回一个元祖,里面有三个元素
面向过程编程的优点:程序结构清晰,可以把复杂的问题简单化,流程化
缺点:科扩展性差
应用场景:linux kernel git httpd shell脚本 还有一个很多人都不熟悉的编程语言haskell就是大名鼎鼎的面向对象编程思想
递归和二分法
递归调用:
在调用一个函数的过程中,直接或者间接的调用了函数本身。
注意,python中的递归性能低的原因是调用一次函数本身就会保存这次的状态,一直等到结束才释放
递归的两个阶段:递推、回溯
简单的例子:
def age(n):
if n==:
return
return age(n-)+2
g=age(3)
print(g)
例子2:如何把下面这个列表中的所有元素取出来?
l =[1, 2, [3, [4, 5, 6, [7, 8, [9, 10, [11, 12, 13, [14, 15,[16,[17,]],19]]]]]]]
def search(l):
for item in l:
if type(item) is list:
search(item)
else:
print(item) search(l)
二分法
当数据量很大适宜采用该方法。采用二分法查找时,数据需是排好序的。主要思想是:(设查找的数组区间为array[low, high])
二分法:就可以用递归的思想来解决
如:
l=[,,,,,,,]
def binary_search(l,num):
print(l)
if len(l)>:
mid_index=len(l)//
if num>l[mid_index]:
l=l[mid_index+:]
binary_search(l,num)
elif num<l[mid_index]:
l=l[:mid_index]
binary_search(l, num)
else:
print("find it")
else:
if l[]==num:
print("find it")
else:
print("error")
return
binary_search(l,)
函数进阶之结合tornado的更多相关文章
- 深入理解javascript函数进阶系列第一篇——高阶函数
前面的话 前面的函数系列中介绍了函数的基础用法.从本文开始,将介绍javascript函数进阶系列,本文将详细介绍高阶函数 定义 高阶函数(higher-order function)指操作函数的函数 ...
- 【python 3】 函数 进阶
函数进阶 1.函数命名空间和作用域 命名空间一共分为三种: 全局命名空间 局部命名空间 内置命名空间 *内置命名空间中存放了python解释器为我们提供的名字:input , print , str ...
- day11.1函数进阶 列表集合 字典中的函数变量,函数作为形参
函数进阶 1.函数作为变量 a=123 name="gao" nums=[1,2,3] data=nums#指向同一个内存地址 #查看内存地址篇章 def func(): prin ...
- python基础 (初识函数&函数进阶)
函数基础部分 .什么是函数? 函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段. 函数能提高应用的模块性,和代码的重复利用率. 2.定义函数 定义:def 关键词开头,空格之后接函数名 ...
- day 10 - 1 函数进阶
函数进阶 命名空间和作用域 命名空间 命名空间 有三种内置命名空间 —— python解释器 就是python解释器一启动就可以使用的名字存储在内置命名空间中 内置的名字在启动解释器的时候被加载进内存 ...
- python基础之 初识函数&函数进阶
函数基础部分 1.什么是函数? 函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段.函数能提高应用的模块性,和代码的重复利用率. 2.定义函数 定义:def 关键词开头,空格之后接函数名 ...
- python函数进阶(函数参数、返回值、递归函数)
函数进阶 目标 函数参数和返回值的作用 函数的返回值 进阶 函数的参数 进阶 递归函数 01. 函数参数和返回值的作用 函数根据 有没有参数 以及 有没有返回值,可以 相互组合,一共有 4 种 组合形 ...
- python大法好——递归、内置函数、函数进阶
1.递归(自己干自己) def fun(n): n=n/2 print(n) if(n>2) fun(n) #函数调用 fun(10) 结果是5 2 1 0 递归的执行过程:递归执行到最里面一层 ...
- 洗礼灵魂,修炼python(25)--自定义函数(6)—从匿名函数进阶话题讲解中解析“函数式编程”
匿名函数进阶 前一章已经说了匿名函数,匿名函数还可以和其他内置函数结合使用 1.map map():映射器,映射 list(map(lambda x:x*2,range(10))) #把range产生 ...
随机推荐
- Spring MVC生成XML
以下示例演示如何使用Spring Web MVC框架生成XML.首先使用Eclipse IDE,并按照以下步骤使用Spring Web Framework开发基于动态表单的Web应用程序: 创建一个名 ...
- python django -5 进阶
高级知识点包括: 静态文件处理 中间件 上传图片 Admin站点 分页 使用jquery完成ajax 管理静态文件 项目中的CSS.图片.js都是静态文件 配置静态文件 在settings 文件中定义 ...
- hadoop之WordCount源代码分析
//近期在研究hadoop.第一个想要要開始研究的必然是wordcount程序了.看了<hadoop应用开发实战解说>结合自己的理解,对wordcount的源代码进行分析. <pre ...
- onlyoffice 中文支持稳定操作方法
网上的都是抄来抄去,不如我这个简单粗暴: 1. 没装过先安装 sudo docker run -i -t -d -p 80:80 onlyoffice/documentserver2 .查看conta ...
- vim杂记
"clang-completelet g:clang_complete_copen=1let g:clang_periodic_quickfix=1let g:clang_snippets= ...
- iOS-ASIHTTPRequest框架学习
本文转载至 http://www.cnblogs.com/A-Long-Way-Chris/p/3539679.html 前段时间在公司的产品中支持了够快网盘,用于云盘存储. 在这个过程中,学习到了很 ...
- JSON Extractor/jp@gc - JSON Path Extractor 举例2
测试描述 使用json返回结果做校验 测试步骤 1.配置http请求 2.根据结果树返回的json,取值 { "status_code":200, "message&qu ...
- echarts之series,markLine、markPoint
一.标记线和标志点 markLine 标记线 标记线的添加,如最大值.最小值.平均值的标记线 symbol 标记的图形. data->type 特殊的标注类型,用于标注最大值最小值等. 可选: ...
- Time-series Storage Layer Time Series Databases 时间序列
w 关于时间序列数据库的思考-CSDN.NET http://www.csdn.net/article/2015-07-13/2825192 存储和处理时间序列数据(“Time Series Da ...
- unity坑faq
遇到的坑记录下来,大都都是听说,没有实测 1. Graphics.copyTexture,在某些机型上不支持从不同类型拷贝 2. msaa 小米mix2不支持,晓龙845 3. android4.2下 ...