搭建Elasticsearch 5.4分布式集群
多机集群中的节点可以分为master nodes和data nodes,在配置文件中使用Zen发现(Zen discovery)机制来管理不同节点。Zen发现是ES自带的默认发现机制,使用多播发现其它节点。只要启动一个新的ES节点并设置和集群相同的名称这个节点就会被加入到集群中。
Elasticsearch集群中有的节点一般有三种角色:master node、data node和client node。
- master node:master几点主要用于元数据(metadata)的处理,比如索引的新增、删除、分片分配等。
- data node:data 节点上保存了数据分片。它负责数据相关操作,比如分片的 CRUD,以及搜索和整合操作。这些操作都比较消耗 CPU、内存和 I/O 资源;
- client node:client 节点起到路由请求的作用,实际上可以看做负载均衡器。( 对于没有很多请求的业务,client node可以不加,master和data足矣)
二、基于2.X的集群配置
选取10.90.4.9这台机器做为client node,elasticsearch.yml中的配置如下:
cluster.name: ucas
node.name: node-09
node.master: true
node.data: false
network.host: 0.0.0.0
discovery.zen.ping.unicast.hosts: ["10.90.4.9"]
discovery.zen.ping.multicast.enabled: true注意端口不是9200,而是9300。也可以不写端口。
启动10.90.4.9上的es服务器,现在只是一个单机集群。
在10.90.4.8这台机器上配置好同样的ES作为master node,elasticsearch.yml中的配置如下:
cluster.name: ucas
node.name: node-08
node.master: true
node.data: true
network.host: 0.0.0.0
discovery.zen.ping.unicast.hosts: ["10.90.4.9"]
discovery.zen.ping.multicast.enabled: true10.90.4.7作为data node,配置如下:
cluster.name: ucas
node.name: node-07
node.master: false
node.data: true
network.host: 0.0.0.0
discovery.zen.ping.unicast.hosts: ["10.90.4.9"]
discovery.zen.ping.multicast.enabled: true访问http://10.90.4.9:9200/_plugin/head/
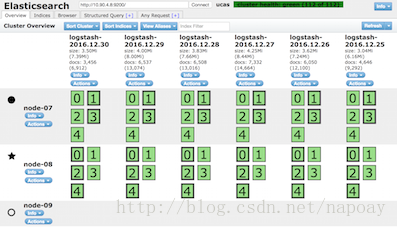
如图,node-09为client节点,不存储数据。
三、基于5.4的多机集群配置
ELasticsearch 5.4要求JDK版本最低为1.8,由于服务器上的JDK版本为1.7并且Java环境变量写在/etc/profile里面,改JDK会影响其他程序,这次基于5.4在我的mac和另外一台Ubuntu 做测试。
mac上的本机ip为192.168.1.111,设为master节点,配置如下:
cluster.name: my-application
node.name: node-111
network.host: 192.168.1.111
http.port: 9200
http.cors.enabled: true
http.cors.allow-origin: "*"
node.master: true
node.data: true
discovery.zen.ping.unicast.hosts: ["192.168.1.111"]
Ubuntu机器的ip位192.168.1.102,配置如下:
cluster.name: my-application
node.name: node-102
network.host: 192.168.1.102
http.port: 9200
http.cors.enabled: true
http.cors.allow-origin: "*"
node.master: false
node.data: true
discovery.zen.ping.unicast.hosts: ["192.168.1.111"]
先启动mac上的master,再启动Ubuntu上的slave节点,观察输出,会有一个node-102探测到master节点的提示:
2017-06-07T11:33:39,369][INFO ][o.e.c.s.ClusterService ] [node-102] detected_master {node-111}{3dQd1RRVTMiKdTckM68nPQ}{H6Zu7PAQRWewUBcllsQWTQ}{192.168.1.111}{192.168.1.111:9300}, added {{node-111}{3dQd1RRVTMiKdTckM68nPQ}{H6Zu7PAQRWewUBcllsQWTQ}{192.168.1.111}{192.168.1.111:9300},}, reason: zen-disco-receive(from master [master {node-111}{3dQd1RRVTMiKdTckM68nPQ}{H6Zu7PAQRWewUBcllsQWTQ}{192.168.1.111}{192.168.1.111:9300} committed version [8]])'- 1
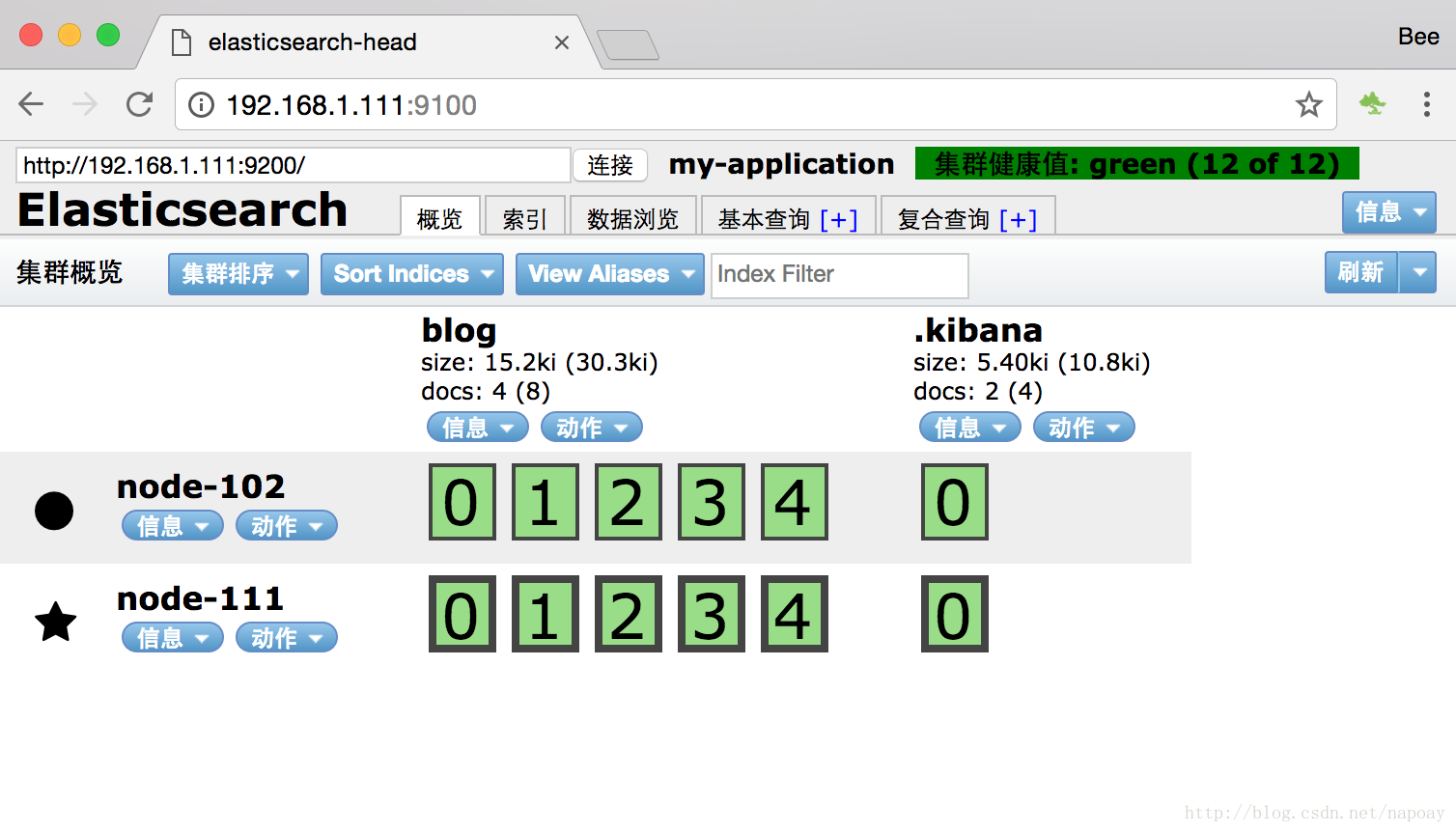
访问head,一个master一个slave组成集群,界面如下:
四、基于5.4的单机多节点集群配置
如果想要在一台机器上启动多个节点,步骤如下:
- 复制一份ELasticsearch的安装包
- 修改端口,比如一个是9200,一个是9205
- 删除data目录下的数据(如果是新解压的安装包就不必了)
搭建Elasticsearch 5.4分布式集群的更多相关文章
- 亿级Web系统搭建:单机到分布式集群
亿级Web系统搭建:单机到分布式集群 当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题.为了解决这些性能压 ...
- ElasticSearch 高可用分布式集群搭建,与PHP多线程测试
方案: 使用HAproxy:当其中一台ElasticSearch Master宕掉时,ElasticSearch集群会自动将运行正常的节点提升为Master,但HAproxy不会将失败的请求重新分发到 ...
- [转]亿级Web系统搭建:单机到分布式集群
当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题.为了解决这些性能压力带来问题,我们需要在Web系统架构层 ...
- 亿级Web系统搭建:单机到分布式集群【转】
当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题.为了解决这些性能压力带来问题,我们需要在Web系统架构层 ...
- Ganglia环境搭建并监控Hadoop分布式集群
简介 Ganglia可以监控分布式集群中硬件资源的使用情况,例如CPU,内存,网络等资源.通过Ganglia可以监控Hadoop集群在运行过程中对集群资源的调度,作为简单地运维参考. 环境搭建流程 1 ...
- 一张图讲解最少机器搭建FastDFS高可用分布式集群安装说明
很幸运参与零售云快消平台的公有云搭建及孵化项目.零售云快消平台源于零售云家电3C平台私有项目,是与公司业务强耦合的.为了适用于全场景全品类平台,集团要求项目平台化,我们抢先并承担了此任务.并由我来主 ...
- Linux Centos7 环境搭建Docker部署Zookeeper分布式集群服务实战
Zookeeper完全分布式集群服务 准备好3台服务器: [x]A-> centos-helios:192.168.19.1 [x]B-> centos-hestia:192.168.19 ...
- elasticsearch与mongodb分布式集群环境下数据同步
1.ElasticSearch是什么 ElasticSearch 是一个基于Lucene构建的开源.分布式,RESTful搜索引擎.它的服务是为具有数据库和Web前端的应用程序提供附加的组件(即可搜索 ...
- Docker中自动化搭建Hadoop2.6完全分布式集群
这一节将在<Dockerfile完成Hadoop2.6的伪分布式搭建>的基础上搭建一个完全分布式的Hadoop集群. 1. 搭建集群中需要用到的文件 [root@centos-docker ...
随机推荐
- django-orm简记
首先orm是什么? orm-------->对象关系映射 专业性解释网上一大推,随便搜搜就能了解大概.在我理解(通俗):一个类 ----- 数据库中一张表 类属性 ----- 数据表中的字段名 ...
- 原生js瀑布流
HTML部分代码............................... CSS部分代码........................... 原生js部分代码................. ...
- 使用nginx对spring boot项目进行代理
摘要:使用nginx对spring boot项目进行反向代理,并且使用轮询均衡负载策略 均衡负载与集群 集群和均衡都涉及到多个机器提供的服务的问题 不同点是,集群是互相通信.协同的的多个服务,服务之前 ...
- 解决WordPress设置错误的url网站不能访问的问题
通过WordPress后台首选项更改了网站url地址之后,网站就会出现访问不了的情况,一般来说,网站后台也登陆不上去了,我从网上寻找到了四种方法,这四种方法前三种都是需要登陆到后台的,但实际上出错后, ...
- 【c语言学习-11】
/*指针*/ #include void charPointFunction(){ //字符型数组 char *x="I like code",y[10];//使x[]初始化,使y ...
- Java源码解析——集合框架(一)——ArrayList
ArrayList源码分析 ArrayList就是动态数组,是Array的复杂版本,它提供了动态的增加和减少元素.灵活的设置数组的大小. 一.类声明 public class ArrayList< ...
- [转]App离线本地存储方案
App离线本地存储方案 原文地址:http://ask.dcloud.net.cn/article/166 HTML5+的离线本地存储有如下多种方案:HTML5标准方案:cookie.localsto ...
- Mysql基础1-基础语法-字段类型
主要: 基础 字段类型 基础 基本概念 1) 数据库分类 层次数据库,网状数据库,关系数据库 常见:SQL Server, Oracle,infomix,sybase,ibmDB2,Mysql 2)数 ...
- Centos7 搭建 hadoop3.1.1 集群教程
配置环境要求: Centos7 jdk 8 Vmware 14 pro hadoop 3.1.1 Hadoop下载 安装4台虚拟机,如图所示 克隆之后需要更改网卡选项,ip,mac地址,uuid 重启 ...
- zookeeper环境搭建(Linux)
安装zookeeper 安装jdk(此处省略) 解压tar包并配置变量环境 配置文件修改 将/usr/local/src/zookeeper-3.4.5/conf这个路径下的zoo_sample.cf ...