Spark Shell启动时遇到<console>:14: error: not found: value spark import spark.implicits._ <console>:14: error: not found: value spark import spark.sql错误的解决办法(图文详解)
不多说,直接上干货!
最近,开始,进一步学习spark的最新版本。由原来经常使用的spark-1.6.1,现在来使用spark-2.2.0-bin-hadoop2.6.tgz。
前期博客
Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz)(master、slave1和slave2)(博主推荐)
这里我,使用的是spark-2.2.0-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz 的单节点来测试下。
其中,hadoop-2.6.0的单节点配置文件,我就不赘述了。
这里,我重点写下spark on yarn。我这里采取的是这模式。
spark-defaults.conf
默认,保持不修改。
spark-env.sh

export JAVA_HOME=/home/spark/app/jdk1..0_60
export SCALA_HOME=/home/spark/app/scala-2.10.
export HADOOP_HOME=/home/spark/app/hadoop-2.6.
export HADOOP_CONF_DIR=/home/spark/app/hadoop-2.6./etc/hadoop
export SPARK_MASTER_IP=192.168.80.218
export SPARK_WORKER_MERMORY=1G
slaves
sparksinglenode
问题详情
我已经是启动了hadoop进程。
然后,来执行

[spark@sparksinglenode spark-2.2.-bin-hadoop2.]$ bin/spark-shell
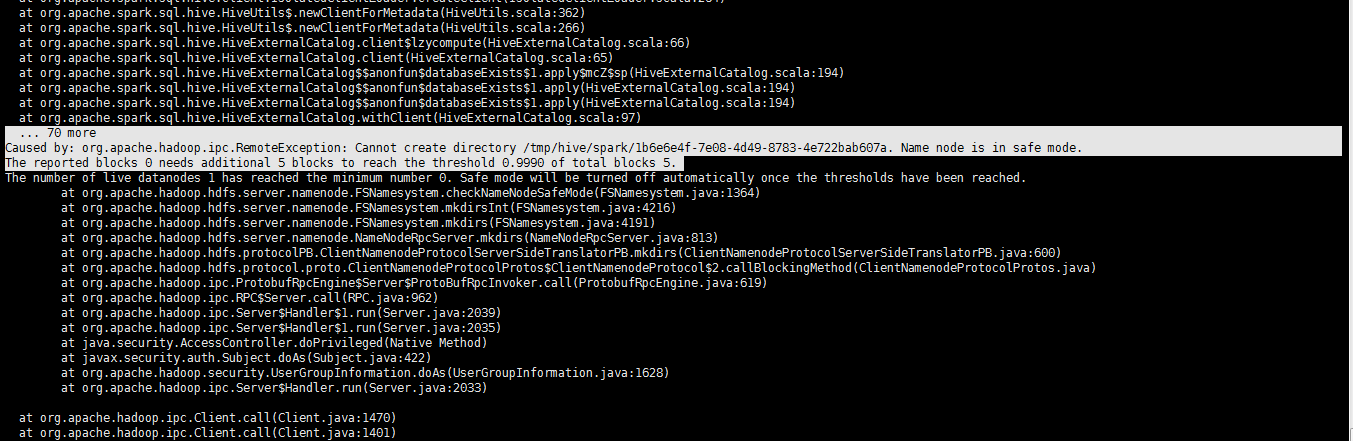
at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:)
at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:)
at org.apache.spark.sql.hive.HiveExternalCatalog.client$lzycompute(HiveExternalCatalog.scala:)
at org.apache.spark.sql.hive.HiveExternalCatalog.client(HiveExternalCatalog.scala:)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$.apply$mcZ$sp(HiveExternalCatalog.scala:)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$.apply(HiveExternalCatalog.scala:)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$.apply(HiveExternalCatalog.scala:)
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:)
... more
Caused by: org.apache.hadoop.ipc.RemoteException: Cannot create directory /tmp/hive/spark/1b6e6e4f-7e08-4d49--4e722bab607a. Name node is in safe mode.
The reported blocks needs additional blocks to reach the threshold 0.9990 of total blocks .
The number of live datanodes has reached the minimum number . Safe mode will be turned off automatically once the thresholds have been reached.
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkNameNodeSafeMode(FSNamesystem.java:)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirsInt(FSNamesystem.java:)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:)
at org.apache.hadoop.ipc.Server$Handler$.run(Server.java:)
at org.apache.hadoop.ipc.Server$Handler$.run(Server.java:)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:)
at org.apache.hadoop.hdfs.DFSClient.mkdirs(DFSClient.java:)
at org.apache.hadoop.hdfs.DistributedFileSystem$.doCall(DistributedFileSystem.java:)
at org.apache.hadoop.hdfs.DistributedFileSystem$.doCall(DistributedFileSystem.java:)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:)
at org.apache.hadoop.hdfs.DistributedFileSystem.mkdirsInternal(DistributedFileSystem.java:)
at org.apache.hadoop.hdfs.DistributedFileSystem.mkdirs(DistributedFileSystem.java:)
at org.apache.hadoop.hive.ql.session.SessionState.createPath(SessionState.java:)
at org.apache.hadoop.hive.ql.session.SessionState.createSessionDirs(SessionState.java:)
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:)
... more
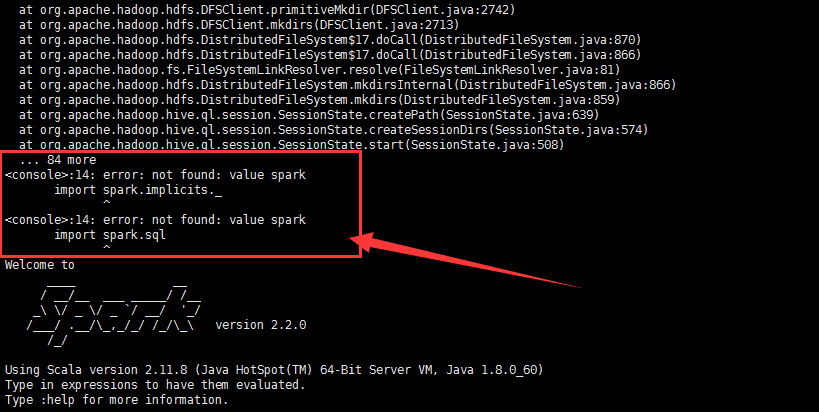
<console>:14: error: not found: value spark
import spark.implicits._
^
<console>:14: error: not found: value spark
import spark.sql
^
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.
/_/ Using Scala version 2.11. (Java HotSpot(TM) -Bit Server VM, Java 1.8.0_60)
Type in expressions to have them evaluated.
Type :help for more information. scala>
解决办法

[spark@sparksinglenode ~]$ jps
SecondaryNameNode
Jps
NameNode
ResourceManager
NodeManager
DataNode
[spark@sparksinglenode ~]$ hdfs dfsadmin -safemode leave
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Safe mode is OFF
[spark@sparksinglenode ~]$
再次执行,成功了
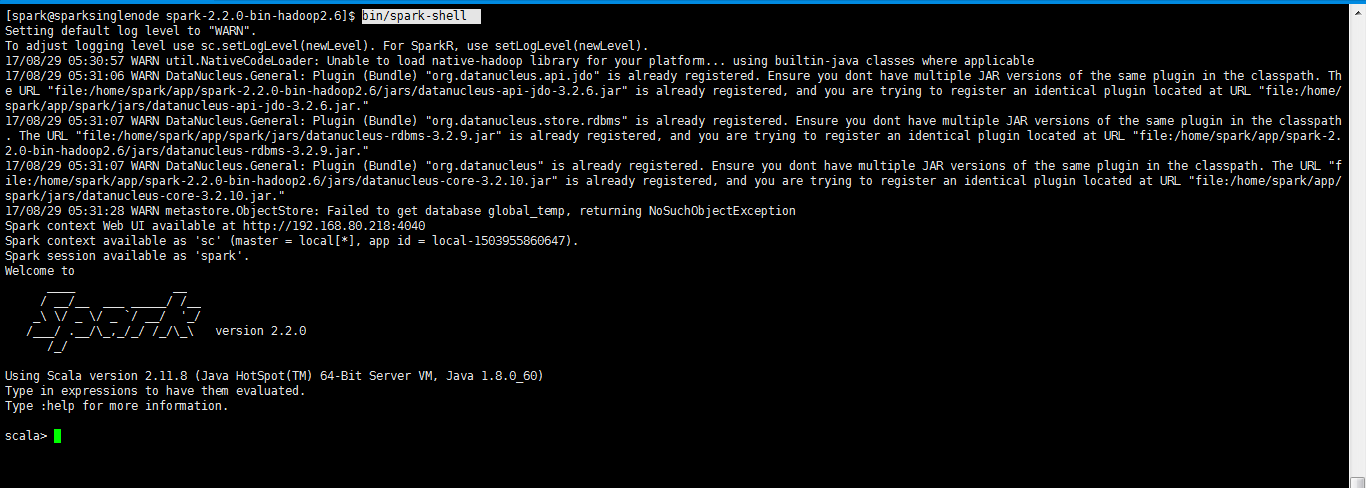
[spark@sparksinglenode spark-2.2.-bin-hadoop2.]$ bin/spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
// :: WARN DataNucleus.General: Plugin (Bundle) "org.datanucleus.api.jdo" is already registered. Ensure you dont have multiple JAR versions of the same plugin in the classpath. The URL "file:/home/spark/app/spark-2.2.0-bin-hadoop2.6/jars/datanucleus-api-jdo-3.2.6.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/home/spark/app/spark/jars/datanucleus-api-jdo-3.2.6.jar."
// :: WARN DataNucleus.General: Plugin (Bundle) "org.datanucleus.store.rdbms" is already registered. Ensure you dont have multiple JAR versions of the same plugin in the classpath. The URL "file:/home/spark/app/spark/jars/datanucleus-rdbms-3.2.9.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/home/spark/app/spark-2.2.0-bin-hadoop2.6/jars/datanucleus-rdbms-3.2.9.jar."
// :: WARN DataNucleus.General: Plugin (Bundle) "org.datanucleus" is already registered. Ensure you dont have multiple JAR versions of the same plugin in the classpath. The URL "file:/home/spark/app/spark-2.2.0-bin-hadoop2.6/jars/datanucleus-core-3.2.10.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/home/spark/app/spark/jars/datanucleus-core-3.2.10.jar."
// :: WARN metastore.ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
Spark context Web UI available at http://192.168.80.218:4040
Spark context available as 'sc' (master = local[*], app id = local-).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.
/_/ Using Scala version 2.11. (Java HotSpot(TM) -Bit Server VM, Java 1.8.0_60)
Type in expressions to have them evaluated.
Type :help for more information. scala>
或者
[spark@sparksinglenode spark-2.2.-bin-hadoop2.]$ bin/spark-shell --master yarn-client
注意,这里的--master是固定参数
Spark Shell启动时遇到<console>:14: error: not found: value spark import spark.implicits._ <console>:14: error: not found: value spark import spark.sql错误的解决办法(图文详解)的更多相关文章
- IDEA里运行代码时出现Error:scalac: error while loading JUnit4, Scala signature JUnit4 has wrong version expected: 5.0 found: 4.1 in JUnit4.class错误的解决办法(图文详解)
不多说,直接上干货! 问题详情 当出现这类错误时是由于版本不匹配造成的 Information:// : - Compilation completed with errors and warnin ...
- 关于MyEclipse启动报错:Error starting static Resources;下面伴随Failed to start component [StandardServer[8005]]; A child container failed during start.的错误提示解决办法.
最后才发现原因是Tomcat的server.xml配置文件有问题:apache-tomcat-7.0.67\conf的service.xml下边多了类似与 <Host appBase=" ...
- PHP生成页面二维码解决办法?详解
随着科技的进步,二维码应用领域越来越广泛,今天我给大家分享下如何使用PHP生成二维码,以及如何生成中间带LOGO图像的二维码. 具体工具: phpqrcode.php内库:这个文件可以到网上下载,如果 ...
- SQL SERVER 2000安装教程图文详解
注意:Windows XP不能装企业版.win2000\win2003服务器安装企业版一.硬件和操作系统要求 下表说明安装 Microsoft SQL Server 2000 或 SQL Server ...
- SQL server 2008 r2 安装图文详解
文末有官网下载地址.百度网盘下载地址和产品序列号以及密钥,中间需要用到密钥和序列号的可以到文末找选择网盘下载的下载解压后是镜像文件,还需要解压一次直接右键点击解如图所示选项,官网下载安装包的可以跳过前 ...
- Elasticsearch集群状态健康值处于red状态问题分析与解决(图文详解)
问题详情 我的es集群,开启后,都好久了,一直报red状态??? 问题分析 有两个分片数据好像丢了. 不知道你这数据怎么丢的. 确认下本地到底还有没有,本地要是确认没了,那数据就丢了,删除索引 ...
- error: not found: value sqlContext/import sqlContext.implicits._/error: not found: value sqlContext /import sqlContext.sql/Caused by: java.net.ConnectException: Connection refused
1.今天启动启动spark的spark-shell命令的时候报下面的错误,百度了很多,也没解决问题,最后想着是不是没有启动hadoop集群的问题 ,可是之前启动spark-shell命令是不用启动ha ...
- 对于maven创建spark项目的pom.xml配置文件(图文详解)
不多说,直接上干货! http://mvnrepository.com/ 这里,怎么创建,见 Spark编程环境搭建(基于Intellij IDEA的Ultimate版本)(包含Java和Scala版 ...
- 全网最详细的启动或格式化zkfc时出现java.net.NoRouteToHostException: No route to host ... Will not attempt to authenticate using SASL (unknown error)错误的解决办法(图文详解)
不多说,直接上干货! 全网最详细的启动zkfc进程时,出现INFO zookeeper.ClientCnxn: Opening socket connection to server***/192.1 ...
随机推荐
- [原创]Java源代码学习
一.一些关键字 方法声明中的native:调用本地方法,该方法一般是用C或者C++写的 变量声明中的transient:在序列化过程中会忽略该变量,即不进行序列化保存 变量声明中的volatile:编 ...
- 国外物联网平台(5):Exosite Murano
国外物联网平台(5)——Exosite Murano 马智 定位 Murano是一个基于云的IoT软件平台,提供安全.可扩展的基础设施,支持端到端的生态系统,帮助客户安全.可扩展地开发.部署和管理应用 ...
- 关于bootstrap模态框的初始化事件
转:https://blog.csdn.net/u010181136/article/details/77579823
- c#设计模式之:组合模式(Composite)
一:引言 在软件开发过程中,我们经常会遇到处理简单对象和复合对象的情况,例如对操作系统中目录的处理,因为目录客园包括单独的文件,也可以包括文件夹,文件夹又是由文件组成的,由于简单对象和复合对象在功能上 ...
- vs 2017局域网内调试
之前调试代码都是在本地启动服务,以 localhost:端口号 的形式调试,今天发现也是可以用ip地址的形式来调用接口,这种方式可以支持内网内Client端调用接口,实现调试的功能,具体方法如下 ...
- 安装Xamarin.Android几个经典介面
昨晚Microsoft MVP的身份来申请Xamarin.Android,想不到今早就有邮件回复.花上些少时间订阅与注册: 望有时间能学习到一些新技术. 下面是Insus.NET下载并安装,留下几个经 ...
- 「TJOI2015」线性代数
题目链接 戳我 \(Describe\) 题目描述 为了提高智商,\(ZJY\)开始学习线性代数.她的小伙伴菠萝给她出了这样一个问题:给定一个\(n×n\)的矩阵\(B\)和一个\(1×n\)的矩阵\ ...
- 个人JS体系整理(三)
一. 严格模式 JavaScript 严格模式(strict mode)即在严格的条件下运行.首先声明,严格模式是ES5中提出来的,准确来说就是一句指令Use strict,它的目的是指定代码在严格条 ...
- 谷歌Google浏览器去广告插件ABP插件安装与使用
---恢复内容开始--- 最新版本的 Chrome 浏览器,主版本号为 67,数字签名日期为 2018.05.30.对 Chrome 的扩展(俗称插件)安装策略进行了调整——只允许在 Chrome 应 ...
- (一)用C或C ++扩展(翻译)
用C或C ++扩展 如果你知道如何用C语言编程,那么为Python添加新的内置模块是很容易的.这种扩展模块可以做两件不能直接在Python中完成的事情:它们可以实现新的内置对象类型,以及调用C库函数和 ...