java获得采集网页内容的方法小结
为了写一个java的采集程序,从网上学习到3种方法可以获取单个网页内容的方法,主要是运用到是java IO流方面的知识,对其不熟悉,因此写个小结。
import java.io.BufferedReader;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.regex.Matcher;
import java.util.regex.Pattern; public class Get_Html {
public static void main(String[] args) throws Exception {
long start= System.currentTimeMillis();
String str_url="http://www.hiphop8.com/city/guangdong/guangzhou.php";
Pattern p = Pattern.compile(">(13\\d{5}|15\\d{5}|18\\d{5}|147\\d{4})<"); //String html = get_Html_2(str_url);
//String html = get_Html_1(str_url);
String html = get_Html_3(str_url);
Matcher m = p.matcher(html); int num = 0;
while(m.find())
{
System.out.println("打印出的号码段落:"+m.group(1)+" 编号"+(++num));
}
System.out.println(num);
long end = System.currentTimeMillis();
System.out.println("花费的时间"+(end-start)+"毫秒");
}
public static String get_Html_2(String str_url) throws IOException{
URL url = new URL(str_url);
String content="";
StringBuffer page = new StringBuffer();
try {
BufferedReader in = new BufferedReader(new InputStreamReader(url
.openStream(), "utf-8"));
while((content = in.readLine()) != null){
page.append(content);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return page.toString();
} public static String get_Html_1(String str_url) throws IOException{
URL url = new URL(str_url);
HttpURLConnection conn = (HttpURLConnection)url.openConnection();
InputStreamReader input = new InputStreamReader(conn.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
return contentBuf.toString();
} /**
* 通过网站域名URL获取该网站的源码
* @param url
* @return String
* @throws Exception
*/
public static String get_Html_3(String str_url) throws Exception {
URL url = new URL(str_url);
HttpURLConnection conn = (HttpURLConnection)url.openConnection();
conn.setRequestMethod("GET");
conn.setConnectTimeout(5 * 1000); //设置连接超时
java.io.InputStream inStream = conn.getInputStream(); //通过输入流获取html二进制数据 byte[] data = readInputStream(inStream); //把二进制数据转化为byte字节数据
String htmlSource = new String(data);
return htmlSource;
} /**
* 把二进制流转化为byte字节数组
* @param inStream
* @return byte[]
* @throws Exception
*/
public static byte[] readInputStream(java.io.InputStream inStream) throws Exception {
ByteArrayOutputStream outStream = new ByteArrayOutputStream();
byte[] buffer = new byte[1204];
int len = 0;
while ((len = inStream.read(buffer)) != -1){
outStream.write(buffer,0,len);
}
inStream.close();
return outStream.toByteArray();
}
}
【分别测试6次的结果】不知道是不是获取的网页数量内容较小,采集效率差不多,不过方法2应该是最好最简便的。
//get_Html_1 967 2658 1132 1199 988 1236
//get_Html_2 2323 2244 1202 1166 1081 1011
//get_Html_3 978 1219 1527 1133 1192 1774
1、关于url .openStream()和conn.getInputStream()。
二者返回的的都是InputStrema对象,且都是通过openConnection()方法获取URLConnection对象,然后调用getInputStream()方法,所以方法2和方法1是一样的,但前者更方便。
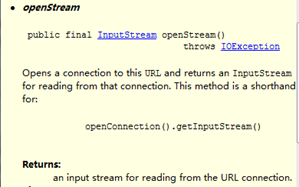
2、关于BufferedReader类。
【该类的功能】:能将 字符流 放入缓冲区(内存中的一块小区域),以便实现高效的读取。
【看构造方法】:
BufferedReader(Reader in) 创建一个使用默认大小输入缓冲区来缓冲字符输入流。
BufferedReader(Reader in, int sz) 创建一个使用指定大小输入缓冲区的缓冲字符输入流。
【常用方法】:readLine()可以快速的实现文本字符的行读取。
3、关于InputStreamReader 类
InputStreamReader 是从字节流到字符流的桥梁:它读入字节,并根据指定的编码方式,将之转换为字符流,它是Reader的子类。
而为了达到更高效率,我们经常用 BufferedReader 封装 InputStreamReader , 所以我们经常看到的用法是
BufferedReader Buf = new BufferedReader(new InputStreamReader(System.in);
这里的InputStreamReader类的功能是将字节流转换为字符流,所以以上语句实现了 :将 字节输入流 转换为 字符输入流 且放置缓冲区。
引用一张图:
4、关于 ByteArrayOutputStream类
它是OutputStream类的扩展类,其构造函数是byteArrayInputStream(byte []buf),作用是把字节数组buf 变成输入流的形式,并通过toString()或者toByteArray()方法或得想要的数据形式。方法3中的readInputStream方法可改为返回String类型,将后面的outStream.toByteArray()改为outStream.toString()方法,这样又精简了代码。
5、 关于InputStream类
InputStream与OutputStream: 是 8位字节 输入/输出流类的基类,主要用在处理二进制数据,它是按字节来处理的。文件在硬盘或在传输时都是以字节的方式进行的,包括图片等都是按字节的方式存储的,其余的字节流的处理类都是对该类的扩展,如等上面讲ByteArrayInputStream类。
由于InputStream.read()方法是每次从流里只读取读取一个字节,效率会非常低。而InputStream.read(byte[] b)或者InputStream.read(byte[] b,int off,int len)方法,一次可以读取多个字节,效率较高,所以方法3中创建了一个byte字节数组,以便一次性读取更多的字节。当read()方法读取内容为空的时候,返回-1.
另外字符输入输出流的基类 Reader/Writer,且要知道1个字符= 2字节,字符都是在内存中生成的,一个中文占两个字节,其子类包含有上面讲的的InputStreamRead类与BufferReader类。
写了几点总结,都是和java的IO流有关的,是不是应该改个标题,想想还是算了,毕竟采集程序中很重要的一部分就是IO流方面的,java在IO流方面提供了丰富的类库,边学边积累吧。
java获得采集网页内容的方法小结的更多相关文章
- 阿里Java架构师打包 FatJar 方法小结
在函数计算(Aliyun FC)中发布一个 Java 函数,往往需要将函数打包成一个 all-in-one 的 zip 包或者 jar 包.Java 中这种打包 all-in-one 的技术常称之为 ...
- JAVA核心知识点--打包 FatJar 方法小结
目录 什么是 FatJar 三种打包方法 1. 非遮蔽方法(Unshaded) 2. 遮蔽方法(Shaded) 3. 嵌套方法(Jar of Jars) 小结 参考阅读 原文地址:https://yq ...
- (转)java判断string变量是否是数字的六种方法小结
java判断string变量是否是数字的六种方法小结 (2012-10-17 17:00:17) 转载▼ 标签: it 分类: 转发 1.用JAVA自带的函数 public static boolea ...
- phpQuery轻松采集网页内容
原文地址:phpQuery轻松采集网页内容作者:陌上花开 phpQuery是一个基于PHP的服务端开源项目,它可以让PHP开发人员轻松处理DOM文档内容,比如获取某新闻网站的头条信息.更有意思的是,它 ...
- Java返回类型泛型的用法小结
Java返回类型泛型的用法小结 版权声明:本文为博主原创文章,未经博主允许不得转载. 关于Java泛型的基本用法就不多说了,主要是一个编译期的检查,也避免了我们代码中的强制转换,比较经典的用法有泛型D ...
- java设计模式-----2、工厂方法模式
再看工厂方法模式之前先看看简单工厂模式 工厂方法模式(FACTORY METHOD)同样属于一种常用的对象创建型设计模式,又称为多态工厂模式,此模式的核心精神是封装类中不变的部分,提取其中个性化善变的 ...
- 对最近java基础学习的一次小结
开头想了3分钟,不知道起什么名字好,首先内容有点泛,但也都是基础知识. 对之前所学的java基础知识做了个小结,因为我是跟着网上找的黑马的基础视频看跟着学的,10天的课程硬生生给我看了这么久,也是佛了 ...
- java爬取网页内容 简单例子(2)——附jsoup的select用法详解
[背景] 在上一篇博文java爬取网页内容 简单例子(1)——使用正则表达式 里面,介绍了如何使用正则表达式去解析网页的内容,虽然该正则表达式比较通用,但繁琐,代码量多,现实中想要想出一条简单的正则表 ...
- Sql server2005 优化查询速度50个方法小结
Sql server2005 优化查询速度50个方法小结 Sql server2005优化查询速度51法查询速度慢的原因很多,常见如下几种,大家可以参考下. I/O吞吐量小,形成了瓶颈效应. ...
随机推荐
- iptables防火墙常用命令参数
iptable添加一条规则开放22端口 iptables -A INPUT -p tcp --dport 22 -j ACCEPT iptables -A OUTPUT -p tcp --sport ...
- win10永久激活方法-备份
百度经验 > 游戏/数码 > 电脑 > 笔记本电脑 Win10专业版永久激活方法 听语音 3780404人看了这个视频 返回 暂停 重播 播放 x 1秒后即将播放下一条视 ...
- Hands-On Modeler (建模人员参与程序开发)
如果编写代码的人员认为自己没必要对模型负责,或者不知道让模型为应用程序服务,那么这个模型就和程序没有任何关联.如果开发人员没有意识到改变代码就意味着改变模型,那么他们对程序的重构不但不会增强模型的作用 ...
- Vue组件通讯黑科技
Vue组件通讯 组件可谓是 Vue框架的最有特色之一, 可以将一大块拆分为小零件最后组装起来.这样的好处易于维护.扩展和复用等. 提到 Vue的组件, 相必大家对Vue组件之间的数据流并不陌生.最常规 ...
- flex布局——回顾
flex 即为弹性布局. 任何一个容器都可以指定为flex布局. .box{display:flex} 行内元素可以使用flex布局 .box{display: inline-flex} webkit ...
- JSONP--解决ajax跨域问题
JSON和JSONP JSONP和JSON好像啊,他们之间有什么联系吗? JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式.对于JSON大家应该是很了解了吧 ...
- 『ACM C++』 PTA 天梯赛练习集L1 | 016-017
今天开了两个大会,时间都给占掉了,就刷了两道题~ 明天加油!!! ------------------------------------------------L1-016------------- ...
- chromium之revocable_store
// |RevocableStore| is a container of items that can be removed from the store. Revoke: 撤销 Revocable ...
- ASP.NET安全验证
一.为什么要用安全验证,使用安全验证有什么好处. 构造特殊的链接地址,导致文件内的数据泄露 数据库泄露 安全防范的首要策略:所有的HTTP访问都要经过IIS,所以限制IIS的安全性是关键 二.安全验证 ...
- 进一步理解 frame 和 bounds
总结一下 iOS中 frame 和 bounds之间的区别 综述 frame和bounds都是描述一块矩形区域,但是他们是有区别的 frame:可视范围,可以理解为控件的大小,把控件当作边缘很薄 ...