让memcached分布式
memcached是应用最广的开源cache产品,它本身不提供分布式的解决方案,我猜想一方面它想尽量保持产品简单高效,另一方面cache的key-value的特性使得让memcached分布式起来比较简单。memcached的分布式主要在于客户端,通过客户端的路由处理来搭建memcached集群环境,因此在服务端,memcached集群环境实际上就是一个个memcached服务器的堆积品,环境的搭建比较简单。下面从客户端做路由和服务端集群环境搭建两方面来谈如何让memcached分布式。
客户端做路由
客户端做路由的原理非常简单,应用服务器在每次存取某key的value时,通过某种算法把key映射到某台memcached服务器nodeA上,因此这个key所有操作都在nodeA上,结构图如下所示:
存储某个key-value
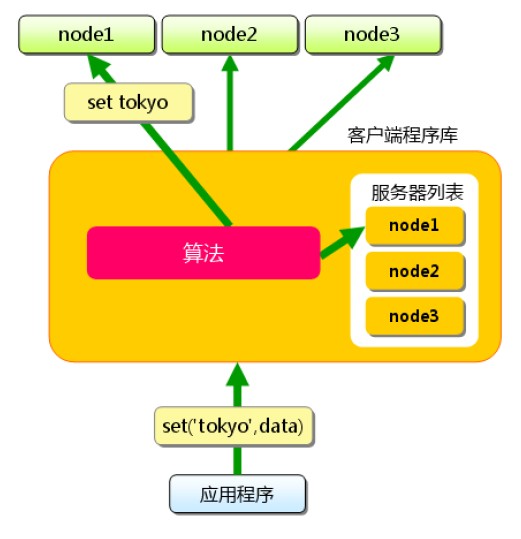
取某个key-value
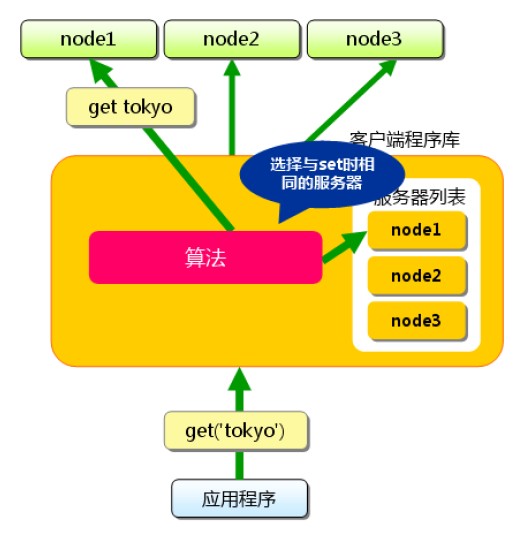
因此关键在于算法的选择,最基本的要求就是能让数据平均到所有服务器上。这自然而然让我想到了hash算法,spymemcached是一个用得比较广的java客户端,它就提供了一种简单的hash算法,实现类为ArrayModNodeLocator,从key映射到node的源码如下:
public MemcachedNode getPrimary(String k) {
return nodes[getServerForKey(k)];
}
private int getServerForKey(String key) {
int rv=(int)(hashAlg.hash(key) % nodes.length);
assert rv >= 0 : "Returned negative key for key " + key;
assert rv < nodes.length
: "Invalid server number " + rv + " for key " + key;
return rv;
}
从上面可知它是把所有node放在数组里,通过hash算法把key映射到某index,然后通过这个index在数组里取node
再则需要考虑如何容错,比如当某个node当掉了,如何自动地转到其他node上,上面的简单hash路由策略采用的方法是在数据组里顺序向下轮询node,找第一个工作正常的node即可。
最后要考虑当需要移除node或添加node的时候,如何有效地调整映射关系,这自然又让我们想到一致性hash算法,关于一致性hash算法就不多说,博文分布式设计与开发(二)------几种必须了解的分布式算法 有所涉及,这里可以看看spymemcached是如何利用这个算法来做路由的,实现类为KetamaNodeLocator,从key映射到node的源码如下:
public MemcachedNode getPrimary(final String k) {
MemcachedNode rv=getNodeForKey(hashAlg.hash(k));
assert rv != null : "Found no node for key " + k;
return rv;
}
MemcachedNode getNodeForKey(long hash) {
final MemcachedNode rv;
if(!ketamaNodes.containsKey(hash)) {
// Java 1.6 adds a ceilingKey method, but I'm still stuck in 1.5
// in a lot of places, so I'm doing this myself.
SortedMap<Long, MemcachedNode> tailMap=ketamaNodes.tailMap(hash);
if(tailMap.isEmpty()) {
hash=ketamaNodes.firstKey();
} else {
hash=tailMap.firstKey();
}
}
rv=ketamaNodes.get(hash);
return rv;
}
这段代码非常清晰,就是通过ketamaNodes这个数据结构按照一致性hash算法把node分区,每次都把映射到一个分区的key对于到负责这个分区的node上。
从上面几段代码和图示,我们大致能弄明白在客户端如何做路由来让memcached分布式,其实在大多数的项目中,以上这些简单的处理办法就足够了
memcached服务端集群
由上面可知一般的应用中memcached服务端集群不用做太多工作,部署一堆memcached服务器就可以了,大不了就是要做好监控的工作,但像facebook这样的大型互联网应用,并且又是那么依赖memcached,集群的工作就很有学问了。今年Qcom的会议上facebook就介绍了是如何通过扩展memcached来应付这么多数据量的,ppt可见Facebook的扩展Memcached实战。这个PPT比较抽象,我没看得太懂,并且facebook也只是蜻蜓点水,没透露太多的细节,但公司的资深架构师陈大峰同学做了些解析,才多多少少有点眉目。facebook所有数据的存取都基本上是在memcached上完成,后端的数据库mysql仅仅只是做持久化的作用,由于数据量巨大,做了类似与mysql的读写分离的结构,结构图如下所示:
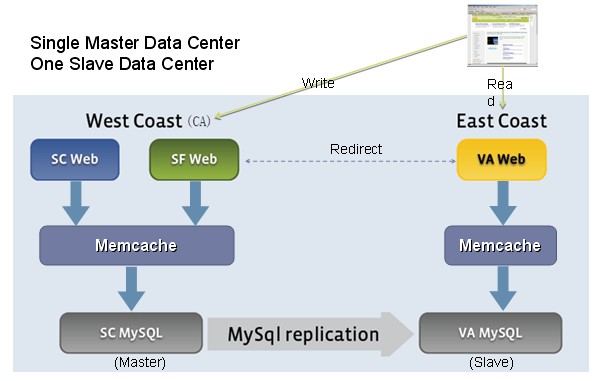
其中非常重要的一点,当West的memcached要向East同步数据的时候,它没有采取memcached之间的同步,而是走MySQL replication,如下图所示:
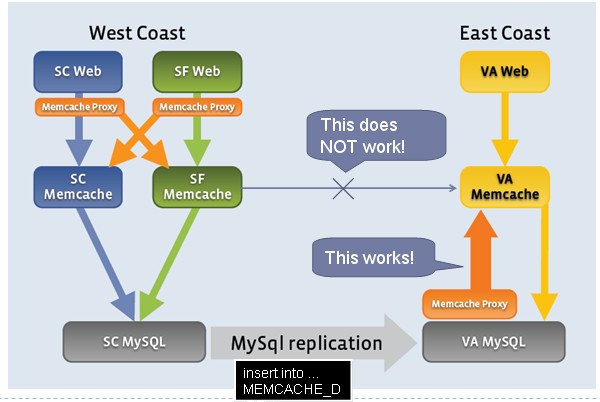
这么做的原因我没法搞得太清楚,大概是比较信赖MySQL replication的简单稳定吧,并且像sns这种应用本身就不需要即时一致性,只要最终一致就行了。
另外在数据分布上是很有讲究的,facebook上面有很多很热的数据,比如LadyGaGa发布一条消息,将会有千万的人收到这个消息,如何把LadyGaGa和普通的用户同等对待就很可能会把这个memcached节点搞垮,甚至访问冲向后面的数据库后会把数据搞垮,如下图所示:
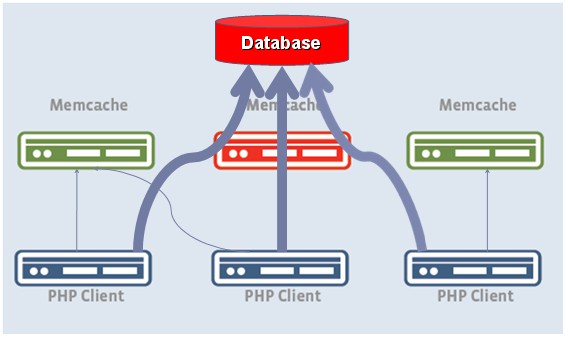
因此就需要一些策略来控制这些热点数据和热点访问,这些策略细节是什么facebook没说太清楚,一般说来可以把热点数据分布到其他节点,另外对于数据库可以加锁控制流量,只有拿到锁的访问才能直接访问数据库,没拿到的需要等候和竞争。
另外一个数据分布的难题是每个用户可能会有成百上千的好友,而这些好友的数据分布在成百上千台的memcached的节点,这样一个客户端就需要连接成千上万的memcached的节点,如下图所示:
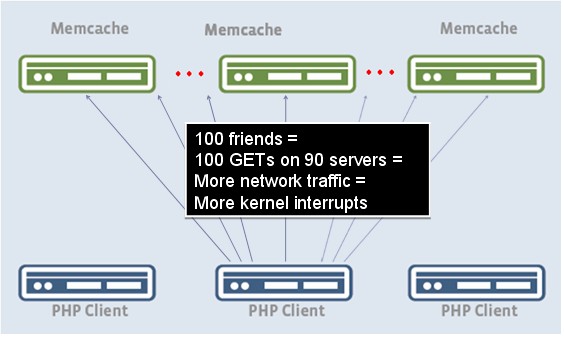
这种问题一般说来可以采取数据重组,把有关联的数据重组在一起,而不是分布在n台机器上。
以上的这些facebook的实践只能说是走马观花地看看了,从我们可以看到一个简简单单memcached也能完成这么多玩样来,可以猜想到facebook的那些天才工程师们在亿万数据压力下被逼出了多少创新的设计,这些设计不一定适用于我们,不了解情景也没办法深究里面的细节,我们要做的是围绕我们自己的应用,让memcached玩出点味道来。
让memcached分布式的更多相关文章
- memcached 分布式
memcached定义 memcached 是一套分布式的高速缓存系统,被广泛应用于应用系统的缓存层来提升应用程序的访问速度:memcache缺乏认证以及安全管制,这表明应将memcached服务器放 ...
- Memcached 分布式缓存实现原理
摘要 在高并发环境下,大量的读.写请求涌向数据库,此时磁盘IO将成为瓶颈,从而导致过高的响应延迟,因此缓存应运而生.无论是单机缓存还是分布式缓存都有其适应场景和优缺点,当今存在的缓存产品也是数不胜数, ...
- memcached分布式实现原理
摘要 在高并发环境下,大量的读.写请求涌向数据库,此时磁盘IO将成为瓶颈,从而导致过高的响应延迟,因此缓存应运而生.无论是单机缓存还是分布式缓存都有其适应场景和优缺点,当今存在的缓存产品也是数不胜数, ...
- memcached 分布式聚类算法
memcached 分布式集群,该决定必须书面开发商自己.和redis 由分布式server决定.上 memcached 有两个选项用于分布式.第一个是:模运算 另一种是:一致性hash 分布式算法. ...
- memcached分布式缓存
1.memcached分布式简介 memcached虽然称为“分布式”缓存服务器,但服务器端并没有“分布式”功能.Memcache集群主机不能够相互通信传输数据,它的“分布式”是基于客户端的程序逻辑算 ...
- 09 Memcached 分布式之取模算法的缺陷
一: Memcached 分布式之取模算法的缺陷(1)假设你有8台服务器,运行中突然down一台,则求余数的底数就7. 后果: key_0%8==0 ,key_0%7==0 =>hist(命中) ...
- Memcached 分布式缓存实现原理简介
摘要 在高并发环境下,大量的读.写请求涌向数据库,此时磁盘IO将成为瓶颈,从而导致过高的响应延迟,因此缓存应运而生.无论是单机缓存还是分布式缓存都有其适应场景和优缺点,当今存在的缓存产品也是数不胜数, ...
- Memcached分布式缓存初体验
1 Memcached简介/下载/安装 Memcached是一个高性能的不是内存对象缓存系统,用于动态Web应用以减轻数据库负载.Memcached基于一个存储键/值对的HashMap.其客户端可以使 ...
- 缓存应用--Memcached分布式缓存简介
一. 什么是Memcached Memcached 是一个高性能的分布式内存 对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象 来减少读取数据库的次数,从而提供动态. ...
随机推荐
- JSP web.xml <jsp-config>标签使用详解
<jsp-config> 包括 <taglib> 和 <jsp-property-group> 两个子元素.其中<taglib> 元素在JSP 1.2 ...
- Java_WebKit
1. http://tieba.baidu.com/p/2807579276 下载地址: http://qtjambi.org/downloads https://qt.gitorious.org/q ...
- struts2提交文件时,出现页面重置又无法返回input现象,我没有解决这个问题
查看资料得知,是因为我使用的tomcat是8的原因,调整到6就可以了.但我没有改变Tomcat的版本,不知道该怎么解决这个问题.
- MySQL5.7版本开启二进制日志是log_bin、bin-log 还是 bin_log ?
已Mac系统为例,文件:/usr/local/mysql/support-files/my-default.cnf 是mysql的默认配置文件,你可以直接修改这个文件但是不推荐,你可以在/etc/my ...
- Pycharm for mac 快捷键
cmd b 跳转到声明处(cmd加鼠标) opt + 空格 显示符号代码 (esc退出窗口 回车进入代码) cmd []光标之前/后的位置 opt + F7 find usage cmd backsp ...
- os.path.abs()与os.path.realpath()的一点区别
相同点 1. 两者都是返回绝对路径,如果参数path为空,则返回当前文件所在目录的绝对路径 当前py文件所在的目录是revise print(os.path.abspath("") ...
- 【Java】Serializable 接口
本文为大便一箩筐的原创内容,转载请注明出处,谢谢:http://www.cnblogs.com/dbylk/p/4356840.html 参考资料: http://xiebh.iteye.com/b ...
- webpack2配置
详细的配置可以参考官网:https://doc.webpack-china.org/guides/ 一开始做项目时都是直接从组里前辈搭建好的脚手架开始写代码,到后来自己写新项目时又是拷贝之前的工程作为 ...
- LeetCode OJ:Product of Array Except Self(除己之外的元素乘积)
Given an array of n integers where n > 1, nums, return an array output such that output[i] is equ ...
- 【网络】<网络是怎样连接的>笔记
[一] 浏览器 http://user:pwd@hosturl:port/dir/of/file 基本思路: 1.1 生成http请求信息 包含“对什么”“进行怎样的操作”两个方法.一般常用操作是GE ...