分布式爬虫搭建系列 之三---scrapy框架初用
第一,scrapy框架的安装
通过命令提示符进行安装(如果没有安装的话)
pip install Scrapy
如果需要卸载的话使用命令为:
pip uninstall Scrapy
第二,scrapy框架的使用
先通过命令提示符创建项目,运行命令:
scrapy startproject crawlquote#crawlquote这是我起的项目名
其次,通过我们的神器PyCharm打开我们的项目--crawlquote(也可以将PyCharm打开我们使用虚拟环境创建的项目)
然后,打开PyCharm的Terminal,如图
然后在命令框中输入
scrapy genspider quotes quotes.toscrape.com
此时的代码目录为:
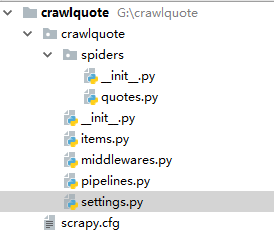
文件说明:
scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines 数据处理行为,如:一般结构化的数据持久化
settings.py 配置文件,如:递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫规则
quotes.py使我们书写的爬虫---里面是发起请求-->拿到数据---->临时存储到item.py中
运行爬虫命令为:
scrapy crawl quotes
第三,使用scrapy的基本流程
(1)明确需要爬取的数据有哪些
(2)分析页面结构知道需要爬取的内容在页面中的存在形式
(3)在item.py中定义需要爬取的数据的存储字段
(4)书写爬虫 -spider中定义(spiders中的quotes.py) --数据重新格式化化后在item.py中存储
(5)管道中--pipeline.py ----对item里面的内容在加工 , 以及定义链接数据库的管道
(6)配置文件中----settings.py中开启管道作用:ITEM_PIPELINES ,定义数据库的名称,以及链接地址
(7)中间件中----middlewares.py
根据上述的一个简单的代码演示:
1)item.py中
import scrapy class CrawlquoteItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
2)spiders--quotes(爬虫)
# -*- coding: utf- -*-
import scrapy
from crawlquote.items import CrawlquoteItem class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/'] def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
item = CrawlquoteItem()
text = quote.css('.text::text').extract_first() # 获取一个
author = quote.css('.author::text').extract_first()
tags = quote.css('.tags .tag::text').extract()
item['text'] = text
item['author'] = author
item['tags'] = tags
yield item # 将网页中的内容重新生成一个item以便于后面的认识 next = response.css('.pager .next a::attr(href)').extract_first()
url = response.urljoin(next) # urljoin翻页
yield scrapy.Request(url=url, callback=self.parse) # 递归调用
3)pipeline.py中
# -*- coding: utf- -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
from scrapy.exceptions import DropItem class TextPipeline(object):
def __init__(self):
self.limit = def process_item(self, item, spider): # 对重新生成的item进行再制作
if item['text']:
if len(item['text']) > self.limit:
item['text'] = item['text'][:self.limit].rstrip() + '...'
return item
else:
return DropItem('Missing Text') class MongoPipeline(object): # 与数据库有关的操作
def __init__(self, mongo_uri, mongo_db): # () MongoPipeline构造函数
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db @classmethod
def from_crawler(cls, crawler): # ()读取settings里面的值,类方法
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
) def open_spider(self, spider): # ()爬虫启动时需要的操作
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db] def process_item(self, item, spider): # 保存到mongodb数据库
name = item.__class__.__name__
self.db[name].insert(dict(item))
return item def close_spider(self, spider): # 关闭mongodb
self.client.close()
4)settings.py中
BOT_NAME = 'crawlquote' SPIDER_MODULES = ['crawlquote.spiders']
NEWSPIDER_MODULE = 'crawlquote.spiders' #数据库链接
MONGO_URI = 'localhost'
MONGO_DB = 'crawlquote' #项目管道开启
ITEM_PIPELINES = {
'crawlquote.pipelines.TextPipeline': ,
'crawlquote.pipelines.MongoPipeline': ,
}
5)此处还没有用的middelwares.py
总结一下:
针对某部分数据的爬取,先要在item中定义字段,然后在爬虫程序中通过选择器拿到数据并存储到item中,再然后通过pipeline的在加工+setting文件修改--存储到数据库中。此时简单爬取就实现了。
分布式爬虫搭建系列 之三---scrapy框架初用的更多相关文章
- 分布式爬虫搭建系列 之四---scrapy分布式框架
带录入SAFCDS
- 分布式爬虫搭建系列 之一------python安装及以及虚拟环境的配置及scrapy依赖库的安装
python及scrapy框架依赖库的安装步骤: 第一步,python的安装 在Windows上安装Python 首先,根据你的Windows版本(64位还是32位)从Python的官方网站下载Pyt ...
- 分布式爬虫搭建系列 之二-----神器PyCharm的安装
这里我们使用PyCharm作为开发工具,以下过程摘抄于:http://blog.csdn.net/qq_29883591/article/details/52664478 作者:陌上行走 Pytho ...
- Python爬虫进阶三之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- 5、爬虫系列之scrapy框架
一 scrapy框架简介 1 介绍 (1) 什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能 ...
- 爬虫系列之Scrapy框架
一 scrapy框架简介 1 介绍 (1) 什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能 ...
- 爬虫(九)scrapy框架简介和基础应用
概要 scrapy框架介绍 环境安装 基础使用 一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能 ...
- Python3爬虫(十七) Scrapy框架(一)
Infi-chu: http://www.cnblogs.com/Infi-chu/ 1.框架架构图: 2.各文件功能scrapy.cfg 项目的配置文件items.py 定义了Item数据结构,所有 ...
- 爬虫 (5)- Scrapy 框架简介与入门
Scrapy 框架 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页 ...
随机推荐
- LeetCode OJ:Binary Tree Maximum Path Sum(二叉树最大路径和)
Given a binary tree, find the maximum path sum. For this problem, a path is defined as any sequence ...
- NAVagationController
UINavigationController为导航控制器,在iOS里经常用到. 1.UINavigationController的结构组成 UINavigationController有Navigat ...
- L131
Fake, Low Quality Drugs Come at High CostAbout one in eight essential medicines in low- and middle-i ...
- Spring核心AOP(面向切面编程)总结
(尊重劳动成果,转载请注明出处:http://blog.csdn.net/qq_25827845/article/details/75208354冷血之心的博客) 1.AOP概念: 面向切面编程,指扩 ...
- 对结合BDD进行DDD开发的一点思考和整理
引言 二十年前的我,还在学校里抱着一台DIY机(德州486+大众主板+16M内存+3.5inch软驱+昆腾320M硬盘,当时全校最快主机没有之一),揣着一本<Undocumented DOS&g ...
- [转载] FFMPEG之AVRational TimeBase成员理解
FFMPEG的很多结构中有AVRational time_base;这样的一个成员,它是AVRational结构的 typedef struct AVRational{ int num; /// ...
- tp_link无线路由器台式机无法上网
昨天一个朋友问我为什么他买的无线路由器连到电脑上面以后不能上网,不过无线很正常,手机等无线设备都能够上网,但是家里的台式机却无法上网.估计很多朋友都遇到过这样的问题,其实问题很多简单.下面就来介绍一下 ...
- Android中Activity的LauchMode(加载模式)
1.standard模式:一个task有多个Activity,一个Activity可以被实例化多次,可以放在不同的task中. 2.singleTop模式:该Activity在栈顶,同时收到启动该Ac ...
- iOS10修改电池状态栏的方法
- 【经典】Noip动态规划
一.线性动态规划 最长严格上升子序列 #include<iostream> #include<cstdio> using namespace std; int n,ans; ] ...