分布式爬虫搭建系列 之三---scrapy框架初用
第一,scrapy框架的安装
通过命令提示符进行安装(如果没有安装的话)
pip install Scrapy
如果需要卸载的话使用命令为:
pip uninstall Scrapy
第二,scrapy框架的使用
先通过命令提示符创建项目,运行命令:
scrapy startproject crawlquote#crawlquote这是我起的项目名
其次,通过我们的神器PyCharm打开我们的项目--crawlquote(也可以将PyCharm打开我们使用虚拟环境创建的项目)
然后,打开PyCharm的Terminal,如图
然后在命令框中输入
scrapy genspider quotes quotes.toscrape.com
此时的代码目录为:
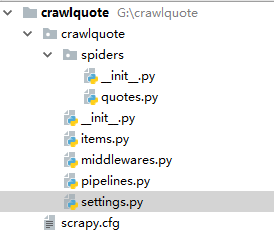
文件说明:
scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines 数据处理行为,如:一般结构化的数据持久化
settings.py 配置文件,如:递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫规则
quotes.py使我们书写的爬虫---里面是发起请求-->拿到数据---->临时存储到item.py中
运行爬虫命令为:
scrapy crawl quotes
第三,使用scrapy的基本流程
(1)明确需要爬取的数据有哪些
(2)分析页面结构知道需要爬取的内容在页面中的存在形式
(3)在item.py中定义需要爬取的数据的存储字段
(4)书写爬虫 -spider中定义(spiders中的quotes.py) --数据重新格式化化后在item.py中存储
(5)管道中--pipeline.py ----对item里面的内容在加工 , 以及定义链接数据库的管道
(6)配置文件中----settings.py中开启管道作用:ITEM_PIPELINES ,定义数据库的名称,以及链接地址
(7)中间件中----middlewares.py
根据上述的一个简单的代码演示:
1)item.py中
import scrapy class CrawlquoteItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
2)spiders--quotes(爬虫)
# -*- coding: utf- -*-
import scrapy
from crawlquote.items import CrawlquoteItem class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/'] def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
item = CrawlquoteItem()
text = quote.css('.text::text').extract_first() # 获取一个
author = quote.css('.author::text').extract_first()
tags = quote.css('.tags .tag::text').extract()
item['text'] = text
item['author'] = author
item['tags'] = tags
yield item # 将网页中的内容重新生成一个item以便于后面的认识 next = response.css('.pager .next a::attr(href)').extract_first()
url = response.urljoin(next) # urljoin翻页
yield scrapy.Request(url=url, callback=self.parse) # 递归调用
3)pipeline.py中
# -*- coding: utf- -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
from scrapy.exceptions import DropItem class TextPipeline(object):
def __init__(self):
self.limit = def process_item(self, item, spider): # 对重新生成的item进行再制作
if item['text']:
if len(item['text']) > self.limit:
item['text'] = item['text'][:self.limit].rstrip() + '...'
return item
else:
return DropItem('Missing Text') class MongoPipeline(object): # 与数据库有关的操作
def __init__(self, mongo_uri, mongo_db): # () MongoPipeline构造函数
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db @classmethod
def from_crawler(cls, crawler): # ()读取settings里面的值,类方法
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
) def open_spider(self, spider): # ()爬虫启动时需要的操作
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db] def process_item(self, item, spider): # 保存到mongodb数据库
name = item.__class__.__name__
self.db[name].insert(dict(item))
return item def close_spider(self, spider): # 关闭mongodb
self.client.close()
4)settings.py中
BOT_NAME = 'crawlquote' SPIDER_MODULES = ['crawlquote.spiders']
NEWSPIDER_MODULE = 'crawlquote.spiders' #数据库链接
MONGO_URI = 'localhost'
MONGO_DB = 'crawlquote' #项目管道开启
ITEM_PIPELINES = {
'crawlquote.pipelines.TextPipeline': ,
'crawlquote.pipelines.MongoPipeline': ,
}
5)此处还没有用的middelwares.py
总结一下:
针对某部分数据的爬取,先要在item中定义字段,然后在爬虫程序中通过选择器拿到数据并存储到item中,再然后通过pipeline的在加工+setting文件修改--存储到数据库中。此时简单爬取就实现了。
分布式爬虫搭建系列 之三---scrapy框架初用的更多相关文章
- 分布式爬虫搭建系列 之四---scrapy分布式框架
带录入SAFCDS
- 分布式爬虫搭建系列 之一------python安装及以及虚拟环境的配置及scrapy依赖库的安装
python及scrapy框架依赖库的安装步骤: 第一步,python的安装 在Windows上安装Python 首先,根据你的Windows版本(64位还是32位)从Python的官方网站下载Pyt ...
- 分布式爬虫搭建系列 之二-----神器PyCharm的安装
这里我们使用PyCharm作为开发工具,以下过程摘抄于:http://blog.csdn.net/qq_29883591/article/details/52664478 作者:陌上行走 Pytho ...
- Python爬虫进阶三之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- 5、爬虫系列之scrapy框架
一 scrapy框架简介 1 介绍 (1) 什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能 ...
- 爬虫系列之Scrapy框架
一 scrapy框架简介 1 介绍 (1) 什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能 ...
- 爬虫(九)scrapy框架简介和基础应用
概要 scrapy框架介绍 环境安装 基础使用 一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能 ...
- Python3爬虫(十七) Scrapy框架(一)
Infi-chu: http://www.cnblogs.com/Infi-chu/ 1.框架架构图: 2.各文件功能scrapy.cfg 项目的配置文件items.py 定义了Item数据结构,所有 ...
- 爬虫 (5)- Scrapy 框架简介与入门
Scrapy 框架 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页 ...
随机推荐
- mysql的bin或者sbin目录可执行文件
一. mysql服务和myql服务启动程序 1. mysqld mysqld就是mysql server,负责管理对mysql数据的访问. 当mysql server启动后,它会监听来自客户端的网络连 ...
- Workflow Builder 2.6.3 Certified on Windows 10 for EBS 12.x
By Steven Chan - EBS-Oracle on May 17, 2016 Workflow Builder 2.6.3 is now certified on Windows 10 de ...
- LeetCode OJ:Reverse Linked List (反转链表)
Reverse a singly linked list. 做II之前应该先来做1的,这个倒是很简单,基本上不用考虑什么,简单的链表反转而已: /** * Definition for singly- ...
- Lua基础---流程控制语句
Lua提供了if语句和if else语句作为流程控制语句,当然,符合C的特点,流程语句之间可以实现嵌套操作,当然流程控制也可以和循环体结合进行控制. 1.if语句 if(布尔表达式) then --[ ...
- 使用hping3/nping施行DoS攻击
DDoS攻击是常见的攻击方式,每小时大约发生28次.http://www.digitalattackmap.com提供在世界范围内的DDoS实时攻击分布图: 从DDoS攻击的地图上就可以看出国际形势: ...
- sublime 非常好用的注释工具
Sublime在进行前端开发时非常棒,当然也少不了众多的插件支持,DocBlocker是在Sublime平台上开发一款自动补全代码插件,支持JavaScript (including ES6), PH ...
- easyui1.4 汉化出问题
easyui 1.4 的textbox 验证汉化不了,需要在easyui-lang-zh_CN.js 加入 if ($.fn.textbox){ $.fn.textbox.defaults.missi ...
- wlan接收器如何共享网络
无线局域网络(Wireless Local Area Networks: WLAN)是相当便利的数据传输系统,它利用射频(Radio Frequency: RF)的技术,取代旧式碍手碍脚的双绞铜线(C ...
- vue前端开发那些事——后端接口.net core web api
红花还得绿叶陪衬.vue前端开发离不开数据,这数据正来源于请求web api.为什么采用.net core web api呢?因为考虑到跨平台部署的问题.即使眼下部署到window平台,那以后也可以部 ...
- WCF服务引用时错误: 无法导入 wsdl:portType详细信息
WCF服务发布到IIS后,在客户端或WCFTestClient添加引用的时候报错如下: 错误: 无法导入 wsdl:portType详细信息: 在运行 WSDL 导入扩展时引发异常: System.S ...