《机器学习基石》第一周 —— When Can Machine Learn?
(注:由于之前进行了吴恩达机器学习课程的学习,其中有部分内容与机器学习基石的内容重叠,所以以下该系列的笔记只记录新的知识)
《机器学习基石》课程围绕着下面这四个问题而展开:

主要内容:
一、什么时候适合用机器学习?
二、该课程所采用的一套符号表示
三、机器学习的流程
四、感知机算法
五、学习的类型
六、机器学习的无效性
七、机器学习的可行性(在无效性的前提下加一些条件限制)
一、什么时候适合用机器学习?

对于第一点:我们学习的对象必须要存在某些显式的或者潜在的规律,否则,如果学习对象都毫无规律,那么学习到的所谓的知识(经验)也就站不住脚了。
对于第二点:这些问题难以使用某些算法或者公式明确地算出结果,假如可以,那么我们就只需要学习数学和算法就足以解决问题,又何须机器学习呢?所以机器学习就是可以用来解决这些有规律但规律又相对模糊的问题。
对于第三点:只有依靠以往大量的经历所得到的经验,才是可靠的。
二、该课程所采用的一套符号表示


三、机器学习的流程
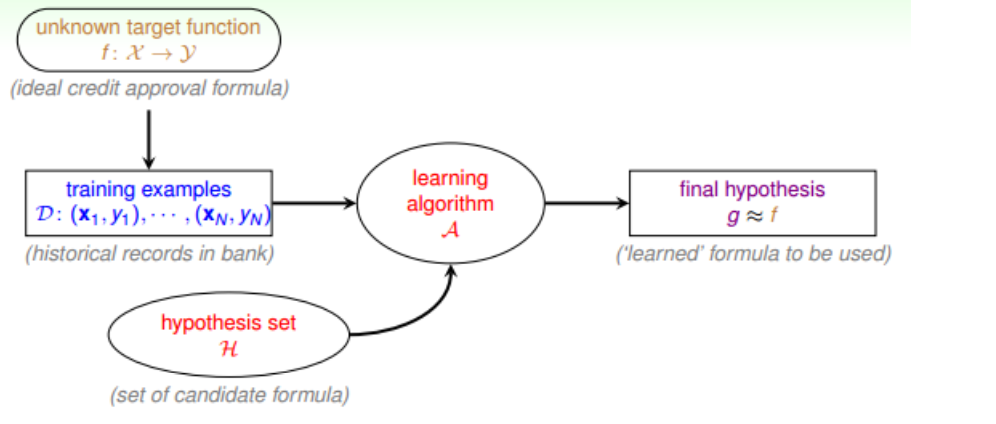
四、感知机算法
五、学习的类型
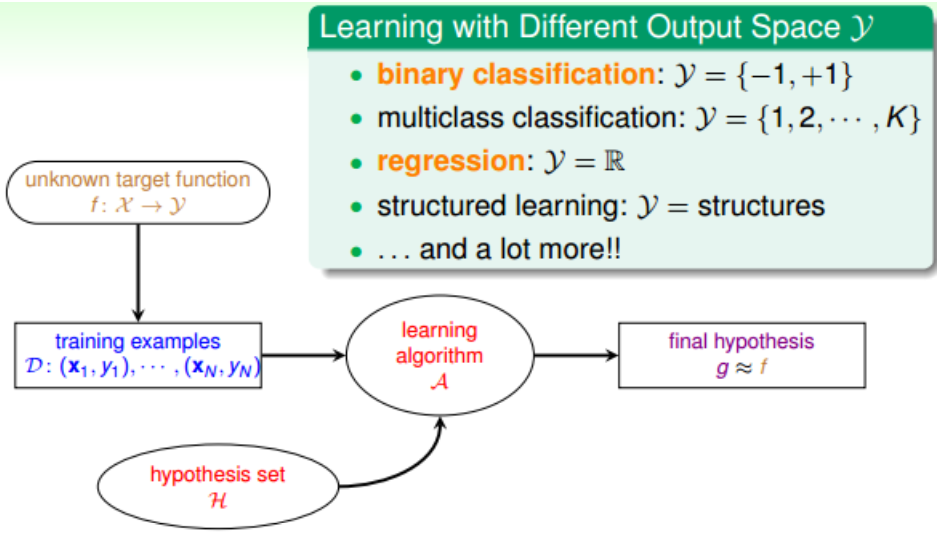
1.根据输出y的取值类型而区别,有分类、回归、结构化学习:
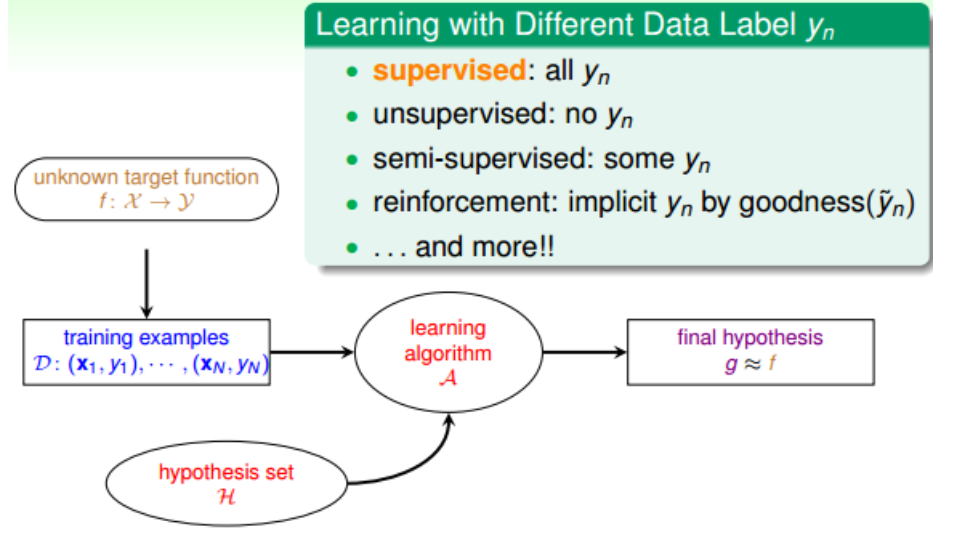
2.根据(样本)输出y的有无或者有多少而区别,有监督式学习、无监督式学习、半监督式学习、增强式学习:
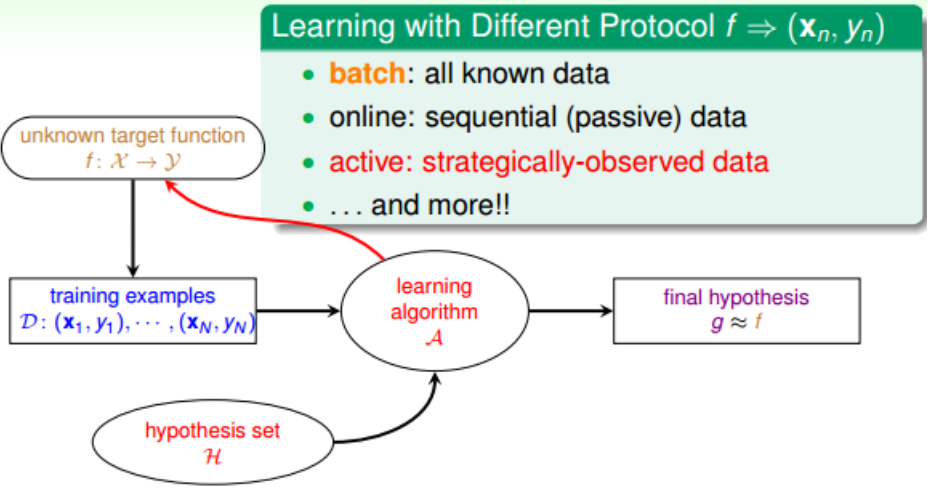
3.根据学习的协议而区别,有:batch leanring、online leanring、active learning:

4.根据输入x的类型而区别,有:concrete features、raw features、abstract feature。
concrete features:有具体的、形象化的含义,例如身高、点击次数等这些特征。
raw features:原始的、未经过处理的特征,例如图片的像素等。
abstract feature:没有现实含义的,如资料编号或者用户ID。
5.总结:

六、机器学习的无效性
所谓机器学习的无效性,按照个人的理解,就是:单凭从给出的数据集中学习到的规律无法应用于数据集之外的数据,或者说是:每个人都学习到了不同的规律,且这些规律对于数据集都是成立的,但是对于数据集之外的数据就不成立了,这就是机器学习的不可行性。但是,假如增加一些条件限制,机器学习就可行了。其中一个很重要的条件限制就是:样本大小,也就是数据集的大小N足够大。下节详情。
七、机器学习的可行性
1.证明机器学习可行性的式子就是Hoeffding's inequality,其中u是实际上类别0的比例(假设是二分类),v是数据集(样本)类别0的比例:

当N足够大时,v就近似等于u,这就说明了从样本集中学到的规律,就近似是真实的规律,这样就能将学习到的规律应用到数据集之外的数据了。
2.对上面的结论作更严谨的推导:
设u = Ein(h),v = Eout(h),其中Ein(h)为h固定时h对样本预测的错误率, Eout(h)为固定时h对测试数据(或者说所有数据)预测的错误率。
所以,如果样本集的大小N足够大,那么:

注意,当Ein(h) 约等于 Eout(h)时,并不意味着h约等于f,因为Ein(h)和 Eout(h)可能很大,这样h的预测效果就非常差了。只有保证了Ein(h)很小的情况下,才能求出最接近f的h。而各种优化算法如梯度下降、最小二乘法等,就是使得Ein(h)非常小的有力工具。
3.综上,保证机器学习可行性的条件至少有两点:
1) 样本(训练集)足够大:保证了Ein(h) 约等于 Eout(h)。
2) Ein(h)足够小:保证了Eout(h)足够小,即保证了h对所有数据的预测误差足够小。
《机器学习基石》第一周 —— When Can Machine Learn?的更多相关文章
- 机器学习基石第一讲:the learning problem
博客已经迁移至Marcovaldo's blog (http://marcovaldong.github.io/) Andrew Ng的Machine Learning比較简单,已经看完.林田轩的机器 ...
- Coursera-AndrewNg(吴恩达)机器学习笔记——第一周
一.初识机器学习 何为机器学习?A computer program is said to learn from experience E with respect to some task T an ...
- 吴恩达《深度学习》-第三门课 结构化机器学习项目(Structuring Machine Learning Projects)-第一周 机器学习(ML)策略(1)(ML strategy(1))-课程笔记
第一周 机器学习(ML)策略(1)(ML strategy(1)) 1.1 为什么是 ML 策略?(Why ML Strategy?) 希望在这门课程中,可以教给一些策略,一些分析机器学习问题的方法, ...
- 第一周 总结笔记 / 斯坦福-Machine Learning-Andrew Ng
课程主页:https://www.coursera.org/learn/machine-learning/home/welcome 收集再多的资料也没用,关键是要自己理解总结,做笔记就是一个归纳总结的 ...
- 《Machine Learning》系列学习笔记之第一周
<Machine Learning>系列学习笔记 第一周 第一部分 Introduction The definition of machine learning (1)older, in ...
- 機器學習基石(Machine Learning Foundations) 机器学习基石 课后习题链接汇总
大家好,我是Mac Jiang,非常高兴您能在百忙之中阅读我的博客!这个专题我主要讲的是Coursera-台湾大学-機器學習基石(Machine Learning Foundations)的课后习题解 ...
- 机器学习基石(台湾大学 林轩田),Lecture 1: The Learning Problem
课程的讲授从logo出发,logo由四个图案拼接而成,两个大的和两个小的.比较小的两个下一次课程就可能会解释到它们的意思,两个大的可能到课程后期才会解释到它们的意思(提示:红色代表使用机器学习危险,蓝 ...
- (转载)林轩田机器学习基石课程学习笔记1 — The Learning Problem
(转载)林轩田机器学习基石课程学习笔记1 - The Learning Problem When Can Machine Learn? Why Can Machine Learn? How Can M ...
- ML笔记_机器学习基石01
1 定义 机器学习 (Machine Learning):improving some performance measure with experience computed from data ...
随机推荐
- 操作XML-dom4j
首先是到dom4j的官网dom4j文件包,下载之后解压如下所示. 在根目录中,找到dom4j-1.6.1jar包,加入到eclipse中的lib文件下,最后build path一下,即可使用相关的方法 ...
- c++通过类名动态创建对象
转载:http://www.seacha.com/article.php/knowledge/cbase/2013/0615/2154.html 主要思想:在每次创建类的过程中,通过各自类的辅助类(所 ...
- 枚举callback还是返回列表 ?
一般都会碰到这样的一个问题,A模块需要返回一系列的object或者message,这样一般有两种处理方式: 1,枚举callback typedef (*callback_type)(obj_type ...
- Mybatis Insert 返回主键ID
<insert id="insert" useGeneratedKeys="true" keyProperty="u_Id" para ...
- 巨蟒python全栈开发linux之cento9
1.docker入门学习 查看机器中已经启动的所有的进程. ps -ef 2.docker常用命令学习 3.docker学习3 4.dockerfile与镜像 5.docker私有仓库 6.rabbi ...
- coursera 《现代操作系统》 -- 第五周 同步机制(1)
临界区块(Critical section)指的是一个访问共用资源(例如:共用设备或是共用存储器)的程序片段,而这些共用资源有无法同时被多个线程访问的特性.(不是字面意思的一个区域,是程序片段的集合) ...
- getDomain(url)-我的JavaScript函数库-mazey.js
获取链接地址中域名,如mazey.net,www.mazey.net,m.mazey.net. 参数:url 必需function getDomain(url){ var a = documen ...
- SQL Server 2008 收缩日志 清空删除大日志文件
SQL2008 的收缩日志 由于SQL2008对文件和日志管理进行了优化,所以以下语句在SQL2005中可以运行但在SQL2008中已经被取消: (SQL2005) BackupLog DNName ...
- recorder.js
(function (f) { if (typeof exports === "object" && typeof module !== "undefin ...
- Linux三种网络
Host-Only 桥接