The MESI Protocol
COMPUTER ORGANIZATION AND ARCHITECTURE DESIGNING FOR PERFORMANCE NINTH EDITION
To provide cache consistency on an SMP, the data cache often supports a protocol
known as MESI. For MESI, the data cache includes two status bits per tag, so that
each line can be in one of four states:
• Modified: The line in the cache has been modified (different from main
memory) and is available only in this cache.
• Exclusive: The line in the cache is the same as that in main memory and is not
present in any other cache.
• Shared: The line in the cache is the same as that in main memory and may be
present in another cache.
• Invalid: The line in the cache does not contain valid data.
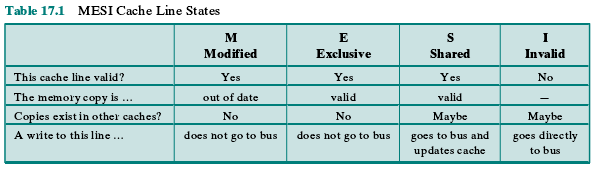
Table 17.1 summarizes the meaning of the four states. Figure 17.6 displays a
state diagram for the MESI protocol. Keep in mind that each line of the cache has
its own state bits and therefore its own realization of the state diagram. Figure 17.6a
shows the transitions that occur due to actions initiated by the processor attached
to this cache. Figure 17.6b shows the transitions that occur due to events that are
snooped on the common bus. This presentation of separate state diagrams for proces-
sor-initiated and bus-initiated actions helps to clarify the logic of the MESI protocol.

At any time a cache line is in a single state. If the next event is from the attached
processor, then the transition is dictated by Figure 17.6a and if the next event is
from the bus, the transition is dictated by Figure 17.6b. Let us look at these transi-
tions in more detail.
READ
MISS When a read miss occurs in the local cache, the processor initiates a
memory read to read the line of main memory containing the missing address. The
processor inserts a signal on the bus that alerts all other processor/cache units to
snoop the transaction. There are a number of possible outcomes:
• If one other cache has a clean (unmodified since read from memory) copy of
the line in the exclusive state, it returns a signal indicating that it shares this
line. The responding processor then transitions the state of its copy from ex-
clusive to shared, and the initiating processor reads the line from main mem-
ory and transitions the line in its cache from invalid to shared.
• If one or more caches have a clean copy of the line in the shared state, each of
them signals that it shares the line. The initiating processor reads the line and
transitions the line in its cache from invalid to shared.
• If one other cache has a modified copy of the line, then that cache blocks the
memory read and provides the line to the requesting cache over the shared
bus. The responding cache then changes its line from modified to shared.
1
The
line sent to the requesting cache is also received and processed by the memory
controller, which stores the block in memory.
• If no other cache has a copy of the line (clean or modified), then no signals are
returned. The initiating processor reads the line and transitions the line in its
cache from invalid to exclusive.
READ
HIT When a read hit occurs on a line currently in the local cache, the
processor simply reads the required item. There is no state change: The state
remains modified, shared, or exclusive.
WRITE
MISS When a write miss occurs in the local cache, the processor initiates a
memory read to read the line of main memory containing the missing address. For
this purpose, the processor issues a signal on the bus that means read-with-intent-
to-modify (RWITM). When the line is loaded, it is immediately marked modified.
With respect to other caches, two possible scenarios precede the loading of the line
of data.
First, some other cache may have a modified copy of this line (state = modify).
In this case, the alerted processor signals the initiating processor that another proc-
essor has a modified copy of the line. The initiating processor surrenders the bus
and waits. The other processor gains access to the bus, writes the modified cache
line back to main memory, and transitions the state of the cache line to invalid
(because the initiating processor is going to modify this line). Subsequently, the
initiating processor will again issue a signal to the bus of RWITM and then read
the line from main memory, modify the line in the cache, and mark the line in the
modified state.
The second scenario is that no other cache has a modified copy of the requested
line. In this case, no signal is returned, and the initiating processor proceeds to read
in the line and modify it. Meanwhile, if one or more caches have a clean copy of the
line in the shared state, each cache invalidates its copy of the line, and if one cache
has a clean copy of the line in the exclusive state, it invalidates its copy of the line.
WRITE
HIT When a write hit occurs on a line currently in the local cache, the effect
depends on the current state of that line in the local cache:
• Shared: Before performing the update, the processor must gain exclusive own-
ership of the line. The processor signals its intent on the bus. Each processor
that has a shared copy of the line in its cache transitions the sector from shared
to invalid. The initiating processor then performs the update and transitions
its copy of the line from shared to modified.
• Exclusive: The processor already has exclusive control of this line, and so it
simply performs the update and transitions its copy of the line from exclusive
to modified.
• Modified: The processor already has exclusive control of this line and has the
line marked as modified, and so it simply performs the update.
L1-L2
CACHE
CONSISTENCY We have so far described cache coherency protocols
in terms of the cooperate activity among caches connected to the same bus or
other SMP interconnection facility. Typically, these caches are L2 caches, and each
processor also has an L1 cache that does not connect directly to the bus and that
therefore cannot engage in a snoopy protocol. Thus, some scheme is needed to
maintain data integrity across both levels of cache and across all caches in the SMP
configuration.
The strategy is to extend the MESI protocol (or any cache coherence proto-
col) to the L1 caches. Thus, each line in the L1 cache includes bits to indicate the
state. In essence, the objective is the following: for any line that is present in both an
L2 cache and its corresponding L1 cache, the L1 line state should track the state of
the L2 line. A simple means of doing this is to adopt the write-through policy in the
L1 cache; in this case the write through is to the L2 cache and not to the memory.
The L1 write-through policy forces any modification to an L1 line out to the L2
cache and therefore makes it visible to other L2 caches. The use of the L1 write-
through policy requires that the L1 content must be a subset of the L2 content. This
in turn suggests that the associativity of the L2 cache should be equal to or greater
than that of the L1 associativity. The L1 write-through policy is used in the IBM
S/390 SMP.
If the L1 cache has a write-back policy, the relationship between the two caches
is more complex. There are several approaches to maintaining coherence. For
example, the approach used on the Pentium II is described in detail in [SHAN05].
The MESI Protocol的更多相关文章
- Hardware Solutions CACHE COHERENCE AND THE MESI PROTOCOL
COMPUTER ORGANIZATION AND ARCHITECTURE DESIGNING FOR PERFORMANCE NINTH EDITION Hardware-based soluti ...
- CACHE COHERENCE AND THE MESI PROTOCOL
COMPUTER ORGANIZATION AND ARCHITECTURE DESIGNING FOR PERFORMANCE NINTH EDITION In contemporary multi ...
- Software Solutions CACHE COHERENCE AND THE MESI PROTOCOL
COMPUTER ORGANIZATION AND ARCHITECTURE DESIGNING FOR PERFORMANCE NINTH EDITION Software cache cohere ...
- Game Engine Architecture 5
[Game Engine Architecture 5] 1.Memory Ordering Semantics These mysterious and vexing problems can on ...
- Method, apparatus, and system for speculative abort control mechanisms
An apparatus and method is described herein for providing robust speculative code section abort cont ...
- Method and apparatus for verification of coherence for shared cache components in a system verification environment
A method and apparatus for verification of coherence for shared cache components in a system verific ...
- Virtual address cache memory, processor and multiprocessor
An embodiment provides a virtual address cache memory including: a TLB virtual page memory configure ...
- PatentTips - Compare and exchange operation using sleep-wakeup mechanism
BACKGROUND Typically, a multithreaded processor or a multi-processor system is capable of processing ...
- Interrupt distribution scheme for a computer bus
A method of handling processor to processor interrupt requests in a multiprocessing computer bus env ...
随机推荐
- 超级详细Tcpdump 的用法
1.抓取回环网口的包:tcpdump -i lo 2.防止包截断:tcpdump -s0 3.以数字显示主机及端口:tcpdump -n 第一种是关于类型的关键字,主要包括host,net,port, ...
- python之函数
本节主要内容: 1. 上节遗留的内置函数: callable(), chr(),ord(), compile(), eval(),exec(), divmod(), isinstance() ,fil ...
- Python~删除空格,插入换行符号
f.write(rf.replace(' ','')) f.write(rf.replace('1041','\n1041')) 不能连续起作用? # -*- coding: UTF-8 -*- im ...
- maven install 构建报错
错误:Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin: 2.3 . 2 :compile ( default ...
- [jquery]折叠指定条件的表格
最近在做财务报表时候,一些表格要做特定折叠效果 这里通过2个自定义属性来对表格之间的属性作关联 date-head和date-num,输出表格时候,可以按照这2个自定义属性给某些带父子层级关系的内容指 ...
- iOS/Android 浏览器(h5)及微信中唤起本地APP
在移动互联网,链接是比较重要的传播媒质,但很多时候我们又希望用户能够回到APP中,这就要求APP可以通过浏览器或在微信中被方便地唤起. 这是一个既直观又很好的用户体验,但在实现过程中会遇到各种问题: ...
- Qt文件路径分隔符
QDir::toNativeSeparators()QDir::separator()
- [Java基础] Java中List.remove报错UnsupportedOperationException
Java中List.remove(removeRange,clear类似) 报出 UnsupportedOperationException 的错误.原来该List是一个AbstractList,不支 ...
- Keywords Search(hdu 2222)
题意:给出n个单词,一篇文章,询问有几个单词在文章中出现过. /* AC自动机的裸题. 题目标号牛的一比. */ #include<cstdio> #include<cstring& ...
- quartz.net插件类库封装(含源码)
1.前言 目录: 1.quartz.net任务调度:源码及使用文档 2.quartz.net插件类库封装 最近项目需要做一写任务作业调度的工作,最终选择了quartz.net这个插件,它提供了巨大的灵 ...