scrapy--json(360美图)
之前开始学习scrapy,接触了AJax异步加载。一直没放到自己博客,趁现在不忙,也准备为下一个爬虫做知识储存,就分享给大家。
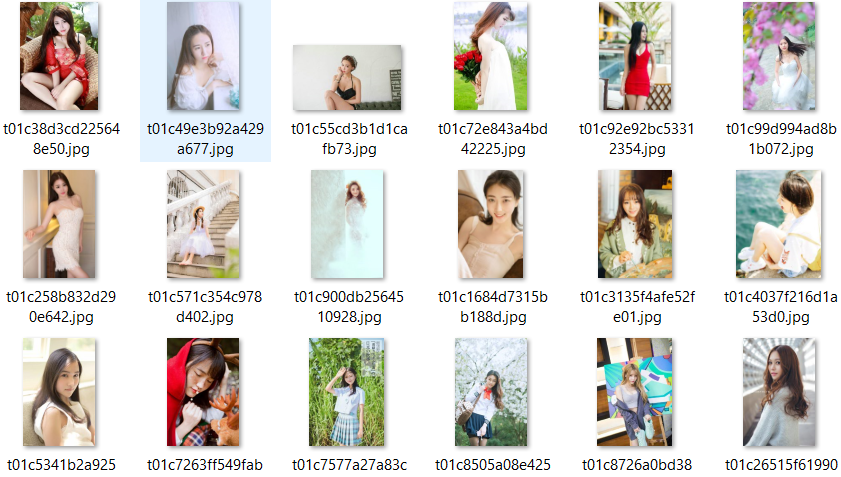
还是从爬取图片开始,先上图给大家看看成果,QAQ。
一、图片加载的方法
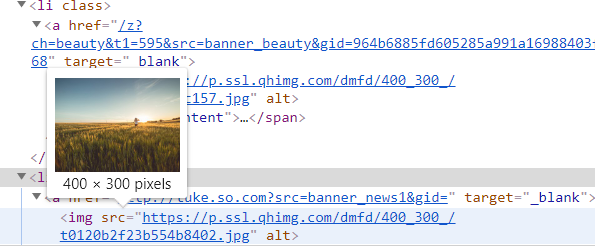
1.1:网页源码__javascript加载数据
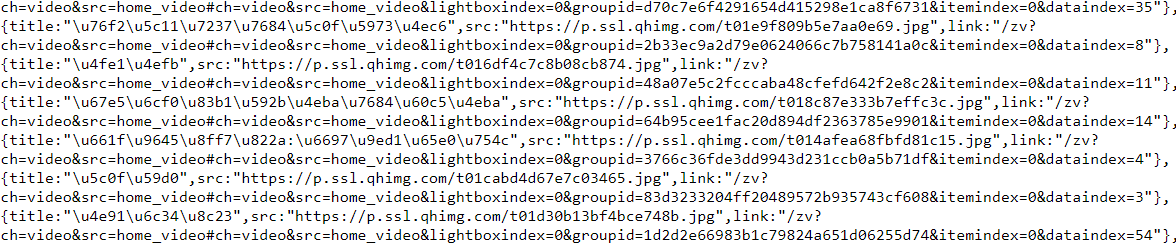
1.2:F12审查元素:滑动滑块,图片开始不断加载,
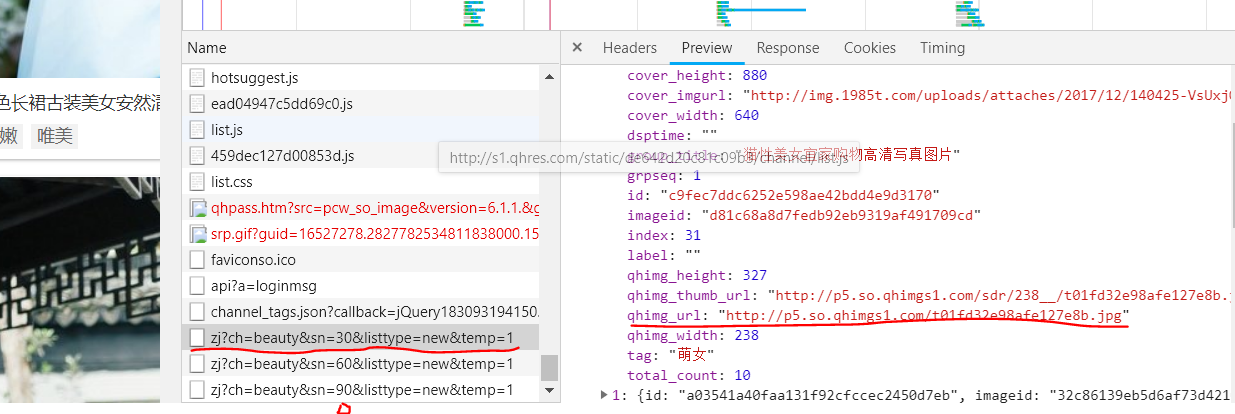
1.3:json数据:"http://image.so.com/zj?ch=beauty&sn=30&listtype=new&temp=1"

图片的URL储存在["list"]["qhimg_url"]
二、实现代码image.py.items.py,middlewares.py,settings.py,pipelines.py在我之前博客中能找到,在这里就不展示了,也可以进我的github:
# -*- coding: utf-8 -*-
import scrapy
from Tupian360.items import Tupian360Item
import json
import pdb
from Tupian360.settings import USER_AGENT
import random class ImageSpider(scrapy.Spider):
name = 'image'
allowed_domains = ['image.so.com']
pager_count = 0 headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'image.so.com',
'Origin': 'image.so.com',
'Referer': 'http://image.so.com/zj?ch=beauty&sn=%s&listtype=new&temp=1'%pager_count,
'User-Agent': USER_AGENT,
'X-Requested-With': 'XMLHttpRequest',
} old_urls = 'http://image.so.com/zj?ch=beauty&sn=%s&listtype=new&temp=1'
start_urls = [old_urls%pager_count] def parse(self, response):
tupian = Tupian360Item()
sel = json.loads(response.body.decode('utf8'))
counts = sel['count']
self.pager_count += int(counts)
new_url = self.old_urls%self.pager_count
for link in sel['list']:
tupian['image_urls'] = link['qhimg_url']
yield tupian yield scrapy.Request(new_url,callback=self.parse)
scrapy--json(360美图)的更多相关文章
- 分析AJAX抓取今日头条的街拍美图并把信息存入mongodb中
今天学习分析ajax 请求,现把学得记录, 把我们在今日头条搜索街拍美图的时候,今日头条会发起ajax请求去请求图片,所以我们在网页源码中不能找到图片的url,但是今日头条网页中有一个json 文件, ...
- thinkphp + 美图秀秀api 实现图片裁切上传,带数据库
思路: 1.数据库 创建test2 创建表img,字段id,url,addtime 2.前台页: 1>我用的是bootstrap 引入必要的js,css 2>引入美图秀秀的js 3.后台: ...
- 分析ajax请求抓取今日头条关键字美图
# 目标:抓取今日头条关键字美图 # 思路: # 一.分析目标站点 # 二.构造ajax请求,用requests请求到索引页的内容,正则+BeautifulSoup得到索引url # 三.对索引url ...
- 15-分析Ajax请求并抓取今日头条街拍美图
流程框架: 抓取索引页内容:利用requests请求目标站点,得到索引网页HTML代码,返回结果. 抓取详情页内容:解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 下载图片与保存数据库:将 ...
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- 分析Ajax请求并抓取今日头条街拍美图
项目说明 本项目以今日头条为例,通过分析Ajax请求来抓取网页数据. 有些网页请求得到的HTML代码里面并没有我们在浏览器中看到的内容.这是因为这些信息是通过Ajax加载并且通过JavaScript渲 ...
- 美图DPOS以太坊教程(Docker版)
一.前言 最近,需要接触区块链项目的主链开发,在EOS.BTC.ethereum.超级账本这几种区块链技术当中,相互对比后,最终还是以go-ethereum为解决方案. 以ethereum为基准去找解 ...
- Python Spider 抓取今日头条街拍美图
""" 抓取今日头条街拍美图 """ import os import time import requests from hashlib ...
- 小幻美图 API
『不忘初心,方得始终.』 小幻美图 API 更新:2015.03.29 目前提供的API共有10种! 必应各种今日获取API共4种! 本站收录图片获取API共4种! 网络图片尺寸修改API共1枚! 百 ...
随机推荐
- Ubuntu上的相关问题
一.解决Ubuntu中vi命令的编辑模式下不能正常使用方向键和退格键的问题 在Ubuntu中,进入vi命令的编辑模式,发现按方向键不能移动光标,而是会输出ABCD,以及退格键也不能正常删除字符.这是由 ...
- Spring课程 Spring入门篇 4-2 Spring bean装配(下)之Autowired注解说明1
课程链接: 1 解析 2 代码演练 1 解析 1.1 @Required注解 该注解适用于bean属性的set方法 1.2 @Autowired 作用: 是为了把依赖的对象,自动的注入到bean里 使 ...
- spring-cloud构架微服务(2)-全局配置二
接上篇,实际项目中,可能会遇到有些配置项,例如:邮件地址.手机号等在服务已经上线之后做了改动(就当会出现这种情况好了).然后你修改了配置信息,就得一个一个去重启对应的服务.spring-全局配置提供了 ...
- 浅谈移动优先的跨终端Web 解决方案
1.基准 我们定义测试基准和开发基准,也就是说我们定义我们在哪些浏览器上去进行调试. 左侧图主要是定义PC上的基准,其中A级项目中必须支持,B级可选,C级观察. 2.检测 主要是终端检测 这是一张架构 ...
- eclipse中Tomcat启动了 但看不到tomcat首页
症状: tomcat在eclipse里面能正常启动,而在浏览器中访问http://localhost:8080/不能访问,且报404错误.同时其他项目页面也不能访问. 关闭eclipse里面的tomc ...
- 运用Hadoop能否搭建完整的云计算平台?
Apache Hadoop 是一个用java语言实现的软件框架,在由大量计算机组成的集群中运行海量数据的分布式计算,它可以让应用程序支持上千个节点和PB级别的数据. Hadoop并不完全代表云计算,所 ...
- selenium安装及官方文档
selenium-python官方文档: https://selenium-python.readthedocs.io/ python3.5已安装的情况下,安装示意图如下 命令行输入 pip3 ins ...
- 关于vim、nvim的折腾
1 from a view of enc ·nvim必须set enc=utf8,很多基于python的插件也默认了此,这对于中文这些并不友好,然而,vim支持多字节就好的多. 因为很多项目,大家可能 ...
- 经典的hash函数
unsigned int SDBMHash(char *str){ unsigned int hash = 0; while (*str) { // equivale ...
- 【转】如何手动添加Android Dependencies包
在ADT16 之前可以在工程里面做关联,eclipse会在工程上自动添加ReferenceLibrary.新版本的ADT修改了第三方jar的导入方式,只需要在工程目录下新建libs文件夹,注意是lib ...